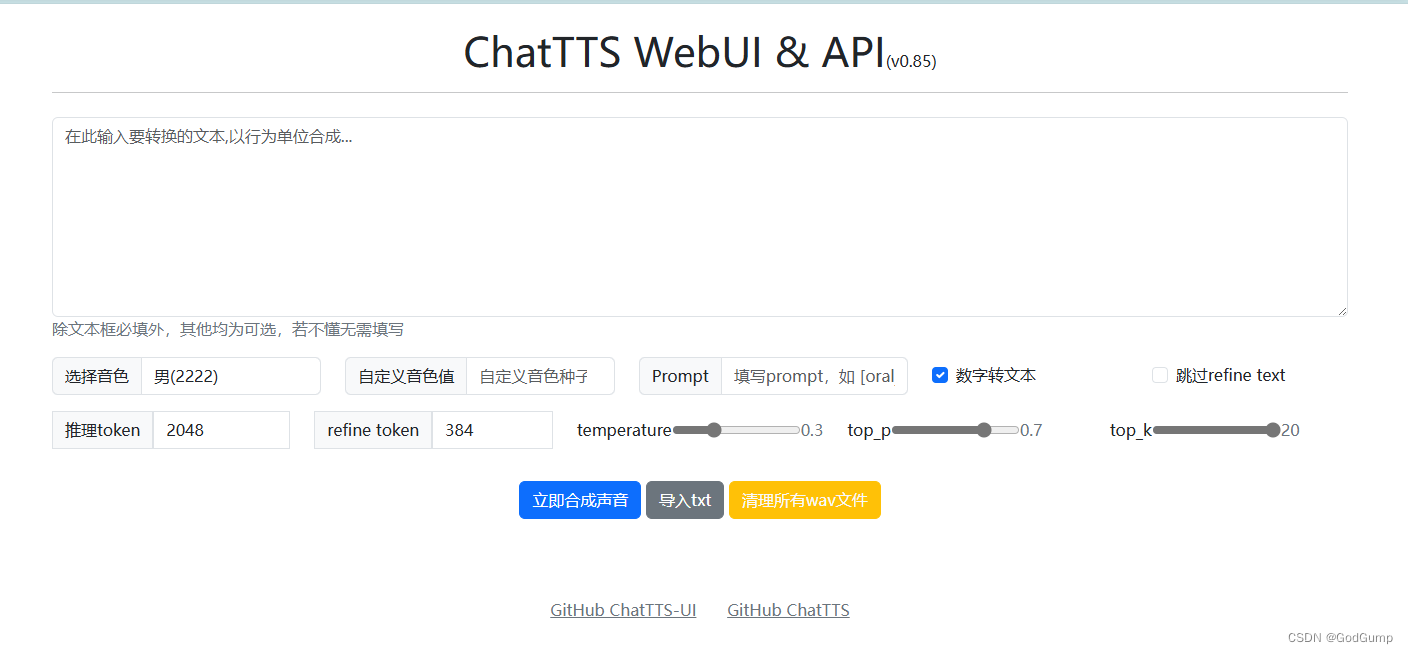
开源 150 T 数据(2023年之前所有数据)
- 开源 150 T 数据
- 生成大规模、高质量训练数据集 = 生成巨量数据 + 数据清洗和过滤 + 混合数据源 + 多级别训练和模型评估 + 探索新的训练策略
- 多级别训练和模型评估
- 探索新的训练策略
- 万卡 H100 集群训练
开源 150 T 数据
论文:https://arxiv.org/pdf/2406.11794
数据:https://arxiv.org/pdf/2406.11794
Llama 2 可能只有 GPT3.5 的 70%,甚至更低。
Llama 3 数据量从 2T 增加到 15T,智能直逼 GPT4。
在不改变模型架构的情况下,将数据量从2万亿(2T)增加到15万亿(15T),就能大力出奇迹。
作者从 CommonCrawl 收集了 150T 数据。
- CommonCrawl是一个基于Python的开源爬虫工具,用于收集全球范围内的网站数据,并将其上传到Common Crawl基金会的数据仓库中。
- 该组织成立于2007年,是一个非营利性组织,旨在为研究人员提供大规模、开放的网络数据提取、转换和分析服务。
在这篇文章中,介绍了一个通过DCLM (DataComp for Language Models) 生成大规模、高质量训练数据集的过程,并解释了如何利用这些数据来训练下一代大型语言模型。
生成大规模、高质量训练数据集 = 生成巨量数据 + 数据清洗和过滤 + 混合数据源 + 多级别训练和模型评估 + 探索新的训练策略
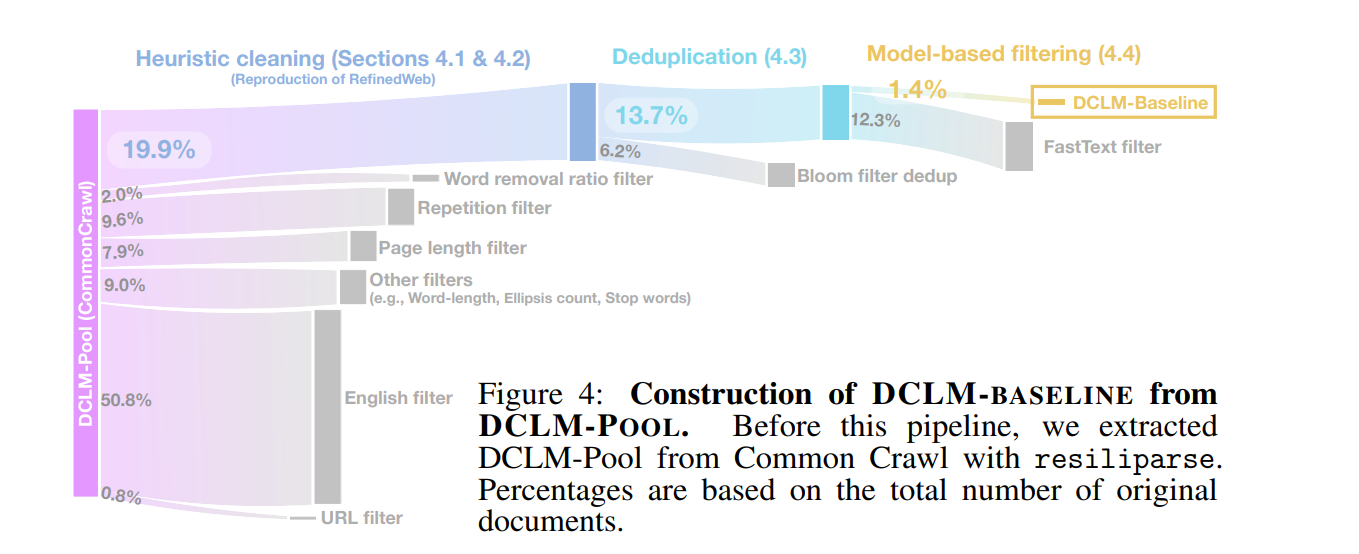
- 数据提取:首先从Common Crawl使用resiliparse工具重新提取文本。
- 启发式清洗:使用RefinedWeb的方法进行数据清洗,包括移除URL、英文过滤、页面长度过滤、重复内容过滤等。
- 去重:应用Bloom过滤器去除重复内容,此外还有传统的去重方法。
- 模型基过滤:利用FastText模型进行质量过滤,以进一步提高数据的质量。
-
子解法1:生成巨量数据
- 特征:需要大量高质量数据来训练下一代语言模型。
- 之所以用此子解法,是因为更多的数据可以提供更复杂的语言模式,有助于模型更好地泛化和理解复杂的语言结构。
- 例子:从Common Crawl中提取了240万亿的数据,形成了DCLM-POOL,这为构建高质量语言模型提供了基础。
-
子解法2:数据清洗和过滤
- 特征:大量数据中包含噪声和冗余信息。
- 之所以用此子解法,是因为清洗和过滤可以提高数据的质量,从而使训练出的模型更准确和有效。
- 例子:使用各种基于模型的过滤技术(例如fastText和PageRank过滤)来筛选出最有价值的数据。
-
子解法3:混合数据源
- 特征:不同的数据源提供了不同领域的知识和信息。
- 之所以用此子解法,是因为结合多个高质量的数据源可以进一步丰富训练数据集,增强模型的多样性和鲁棒性。
- 例子:将Common Crawl数据与专门的领域数据(如数学和编程相关的数据集)混合,以增强模型在这些特定任务上的表现。
-
子解法4:多级别训练和模型评估
- 特征:不同的训练阶段可能需要不同的数据处理和模型参数调整。
- 之所以用此子解法,是因为通过分阶段训练和评估,可以更细致地调优模型,逐步提升其性能。
- 例子:先使用基础数据训练模型,然后通过指令微调和高级任务评估来细化和验证模型性能。
-
子解法5:探索新的训练策略
- 特征:现有的训练策略可能无法充分利用大规模数据的潜力。
- 之所以用此子解法,是因为探索新的训练方法可以帮助更有效地利用巨量数据,发掘数据的潜在价值。
- 例子:采用持续预训练方法和模型汤策略,通过在多种数据分布上训练不同阶段的模型并将它们结合,以提升模型的整体性能和适应性。
多级别训练和模型评估,以及探索新的训练策略,是大规模语言模型开发中的关键环节。下面详细解释这些策略的实施和优势:
多级别训练和模型评估
多级别训练指的是在不同的训练阶段使用不同的数据处理、模型架构调整和超参数设置,以逐步优化模型的性能。
这种分阶段的方法允许研究人员细致地监控和调整模型在各个训练阶段的表现,从而更精确地针对特定任务或数据类型进行优化。
-
初级阶段:通常开始于一个基础的模型训练设置,使用大量未经过严格筛选的数据。这个阶段的目的是让模型获得足够的“世界知识”,建立起基本的语言理解能力。
-
中级阶段:随后,可能会引入更精细的数据筛选和清洗,以去除噪声和不相关的信息,专注于提高模型在特定任务(如问答、摘要等)上的表现。此阶段可能会开始尝试不同的模型架构或超参数,以找到最佳的训练配置。
-
高级阶段:在模型已经表现出较好的基本性能后,进行高级优化,如指令调优(instruction tuning),这通常涉及在特定指令或任务上训练模型以优化其响应。此阶段也可能包括模型的细微调整,如调整学习率的衰减策略或优化器的选择。
-
评估:在每个阶段结束时,通过一系列预定义的下游任务来评估模型的性能。这些任务可以是通用的语言理解测试,也可以是特定的应用场景测试,以此来量化模型的泛化能力和特定能力。
探索新的训练策略
为了更有效地利用可用的大规模数据,并提高模型的训练效率和最终性能,探索新的训练策略至关重要。
这包括但不限于:
-
持续预训练:即在模型已经训练到一定阶段后,继续在相同或修改后的数据分布上进行训练。这种方法可以帮助模型更好地适应其训练数据,进一步提高性能,尤其是在处理长文本或复杂问题时。
-
模型汤(Model Souping):这是一种集成学习技术,通过合并在不同数据子集或不同设置下训练的多个模型来提高整体性能。这种方法能够整合各个模型的优点,减少任何单一模型的偏差。
-
多任务学习:通过同时训练模型以执行多种语言处理任务,可以提高模型的泛化能力。这种策略利用了不同任务之间的共通性,有助于模型在一个任务上学到的知识迁移到其他任务上。
-
元学习和快速适应:研究如何使模型使用较少的数据或训练步骤快速适应新任务。这包括开发能够在接收到新指令时迅速调整其行为的模型。
通过实施这些多级别的训练和评估策略,并不断探索和实施新的训练技术,可以显著提升语言模型的性能和效率。这些策略不仅提升了模型的能力,也优化了训练过程,使得模型能够更好地适应多变的应用需求。



![[Redis]主从模式](https://img-blog.csdnimg.cn/direct/bc6902fb2d7446109d6e9993c6dda1f3.png)