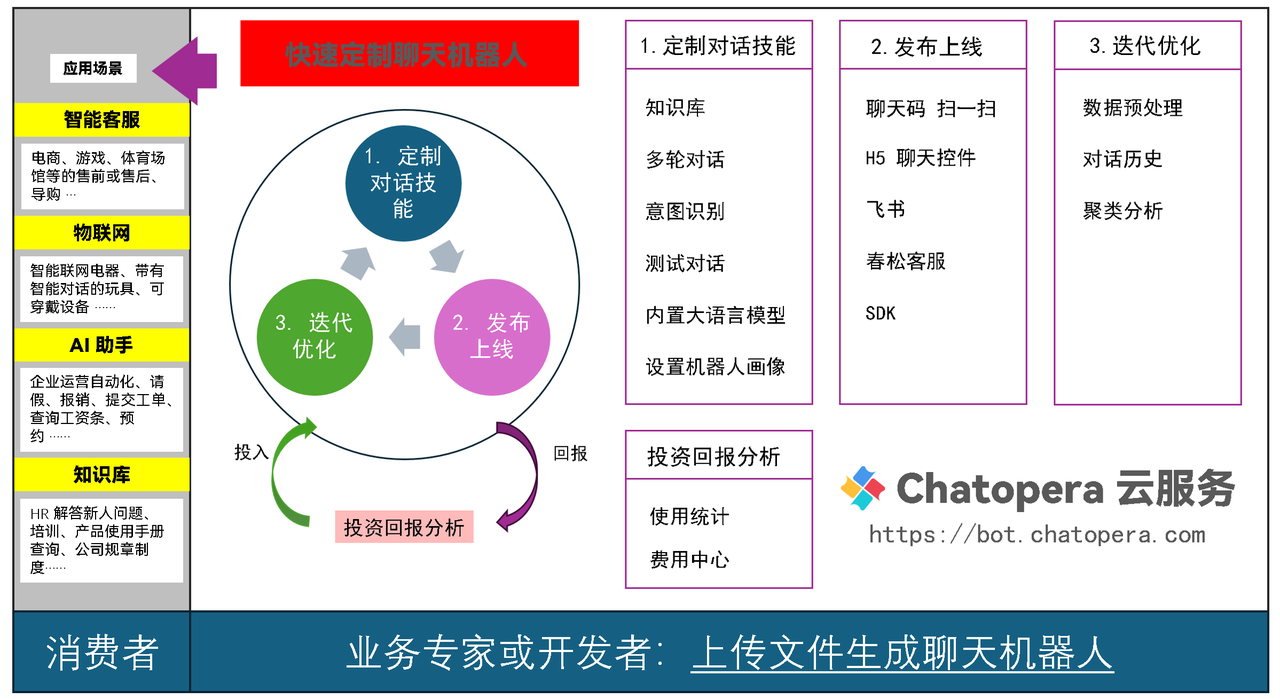
在为企业客户上线聊天机器人客服的过程中,总会遇到一个问题,这让用户和我们都感到纠结。
到底是追求让机器人能准确的回答问题,还是让机器人可以举一反三的回答问题。
- 准确的回答问题,就是不容许回答错了,但是这样机器人能解答的问题有限,在数据不够的情况下,显得机器人智障
- 举一反三的回答问题,就是让机器人尽可能的提供信息
如何返回答案
要准确,就是多用文本匹配的办法。要举一反三,就是多用语义相似度。
回答的结果,在机器人内部,会通过文本匹配相似度 x 和语义相似度 y,用一个公式归一化,比如: 0.8*x + 0.2*y
按照这个排序。或者由匹配没有得到答案,再用语义去向量数据库寻找。
总结起来,还是需要一个原则:追求准确,还是追求举一反三。
如果有不同的适用场景,那么在哪里呢?
是售后客服追求准确,售前追求举一反三?这些,其实是客户自己的责任,这个决策关系客户自己的利益。
下面,我来介绍一下,这两个方案不同的解决方案。
使用语义理解方案举一反三
对于宽松的语义理解,Chatopera 做了一个给开发者用的 SDK,Synonyms
https://github.com/chatopera/Synonyms
这样使用 SDK 的用户可以自己定义严谨程度。
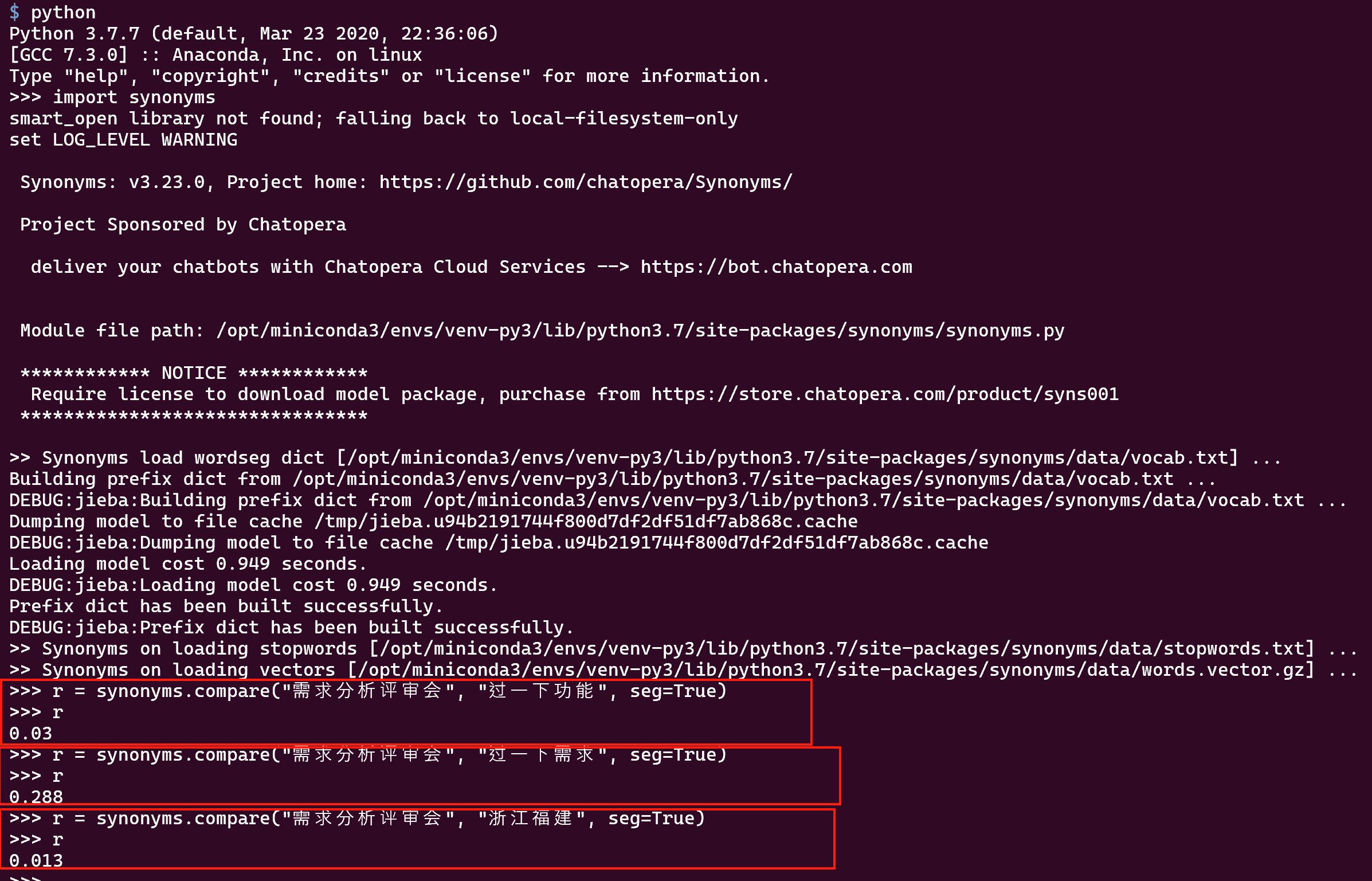
这是用 SDK 做的判断,那么可以开发者自己来计算相似度,这个有语义的效果。总之要找出一个最关联的语义答案,就不用看分值多少,而且选择分值最高的即可。
比如上文,【需求分析评审会】与下面的三个句子的相似度是:
| 句子 | Synonyms 给出的相似度 |
|---|---|
| 浙江福建 | 0.013 |
| 过一下功能 | 0.03 |
| 过一下需求 | 0.288 |
我们可以发现,功能和需求在语义上,因为更接近,而分数更高。
使用填数据方式优化
在 Chatopera 云服务知识库上,填数据有以下两个方法,这两个方法支持在机器人管理控制台实现,也支持使用 SDK 方式实现。
SDK 实现方案参考:https://github.com/chatopera/chatopera-java-sdk/tree/master/src/test/java/com/chatopera/bot/sdk
优化自定义词典
创建词典
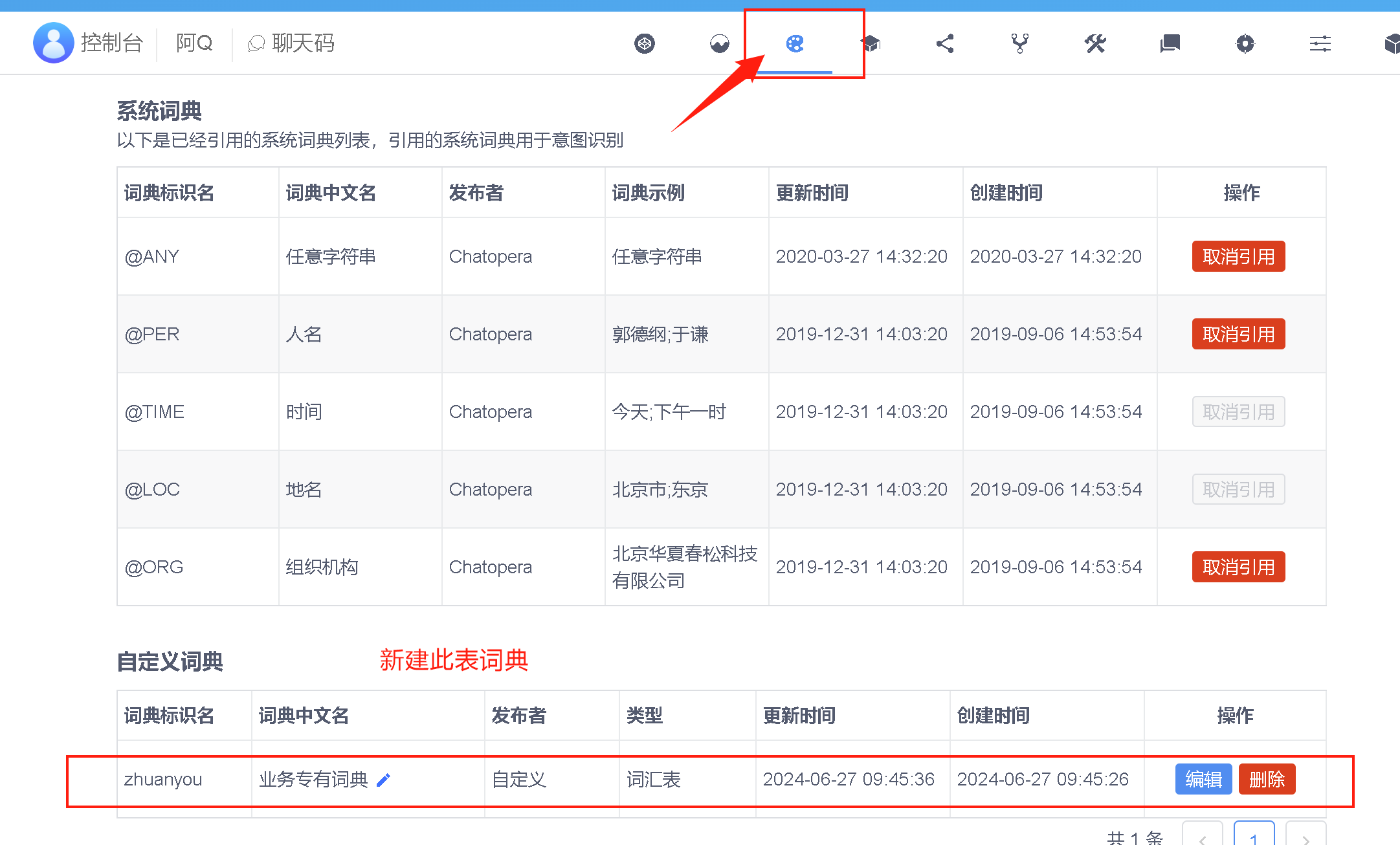
添加词条
优化相似问

关于 Chatopera
Chatopera 云服务重新定义聊天机器人,https://bot.chatopera.com 定制智能客服、知识库、AI 助手、智慧家居等智能应用,释放创新潜力。