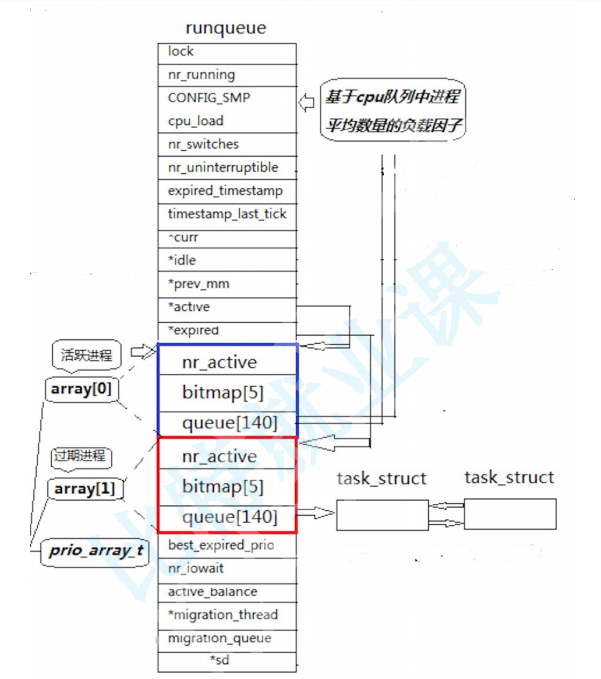
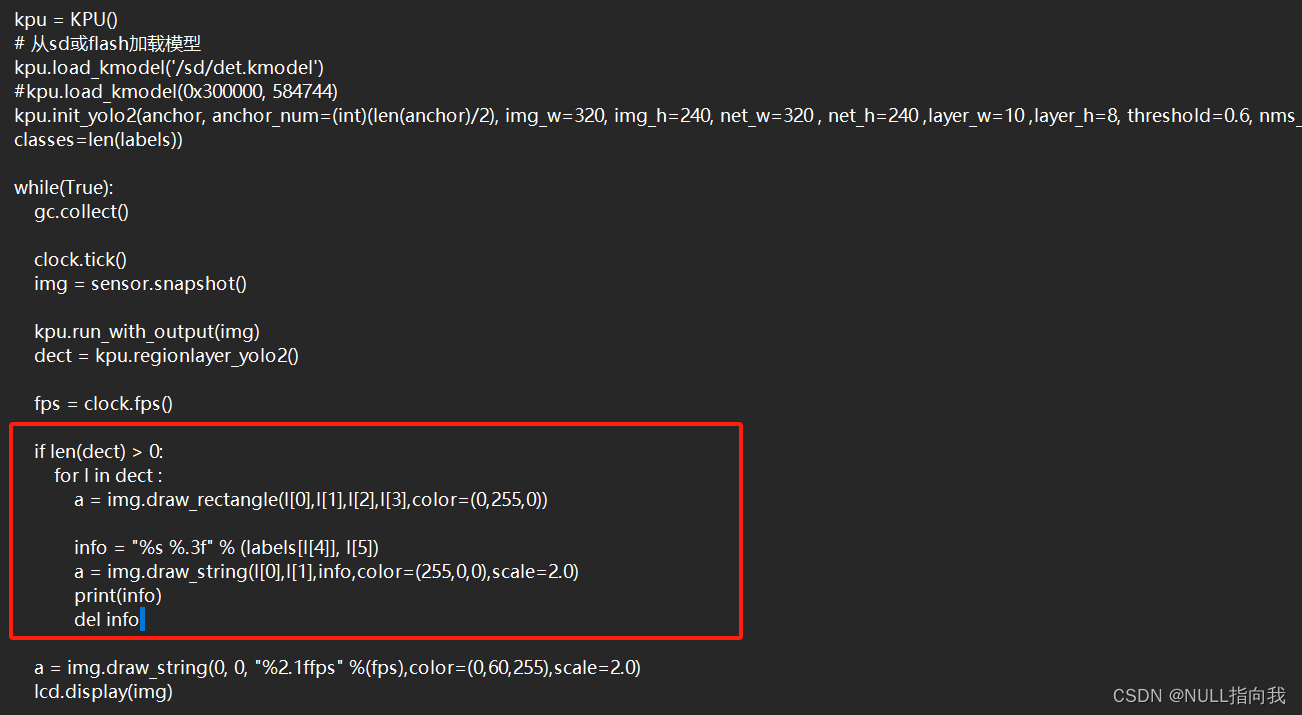
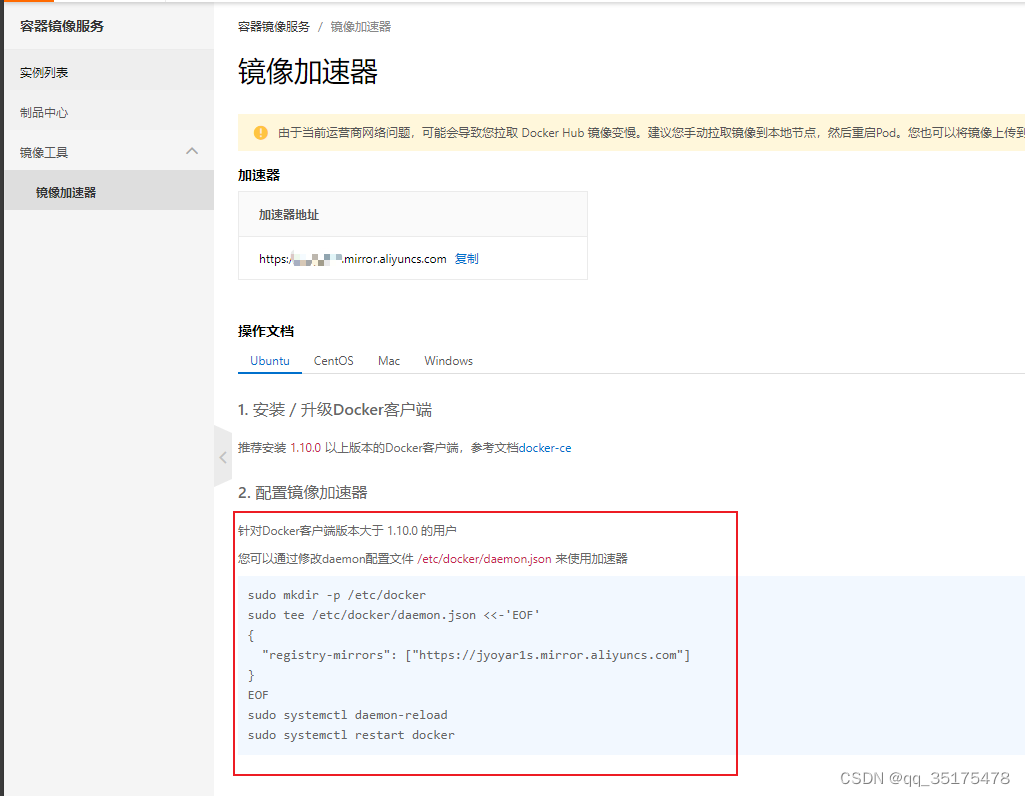
安装环境
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install transformers
代码
question = "What are the email address, town and county of the customers who are of the least common gender?"
schema = """CREATE TABLE Products (
product_id number,
parent_product_id number,
product_name text,
product_price number,
product_color text,
product_size text,
product_description text);
CREATE TABLE Customers (
customer_id number,
gender_code text,
customer_first_name text,
customer_middle_initial text,
customer_last_name text,
email_address text,
login_name text,
login_password text,
phone_number text,
address_line_1 text,
town_city text,
county text,
country text);
CREATE TABLE Customer_Payment_Methods (
customer_id number,
payment_method_code text);
CREATE TABLE Invoices (
invoice_number number,
invoice_status_code text,
invoice_date time);
CREATE TABLE Orders (
order_id number,
customer_id number,
order_status_code text,
date_order_placed time);
CREATE TABLE Order_Items (
order_item_id number,
product_id number,
order_id number,
order_item_status_code text);
CREATE TABLE Shipments (
shipment_id number,
order_id number,
invoice_number number,
shipment_tracking_number text,
shipment_date time);
CREATE TABLE Shipment_Items (
shipment_id number,
order_item_id number);
"""
prompt = f"""<schema>{schema}</schema>
<question>{question}</question>
<sql>"""
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
model = AutoModelForCausalLM.from_pretrained("PipableAI/pip-sql-1.3b")
tokenizer = AutoTokenizer.from_pretrained("PipableAI/pip-sql-1.3b")
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True).split('<sql>')[1].split('</sql>')[0])
输出的sql