目录
-
- 1.深度学习硬件:CPU和GPU
-
- CPU内存结构
- 提升CPU利用率
- 提升GPU利用率
- CPU与GPU牌子
- CPU/GPU高性能计算编程
- 2.深度学习硬件:TPU和其他
-
- DSP
- FPGA
- AI ASIC
- 总结
- 3.单机多卡并行:多GPU
-
- 数据并行VS模型并行
- 总结
- 4.多GPU训练代码实现
-
- 数据同步
- 数据分发
- 训练
- 多GPU的简洁实现
- 5.分布式训练
1.深度学习硬件:CPU和GPU
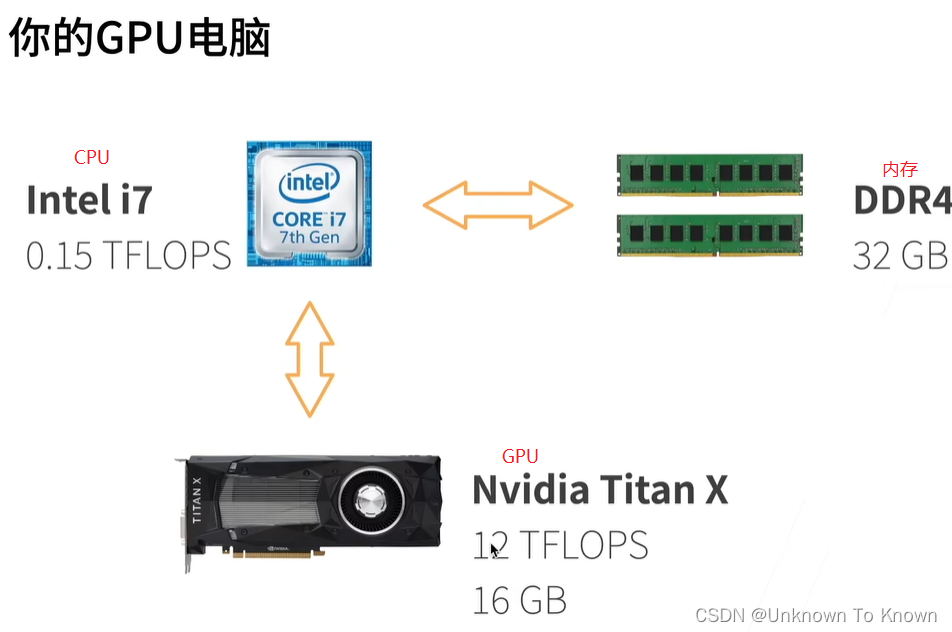
CPU内存结构
CPU内存结构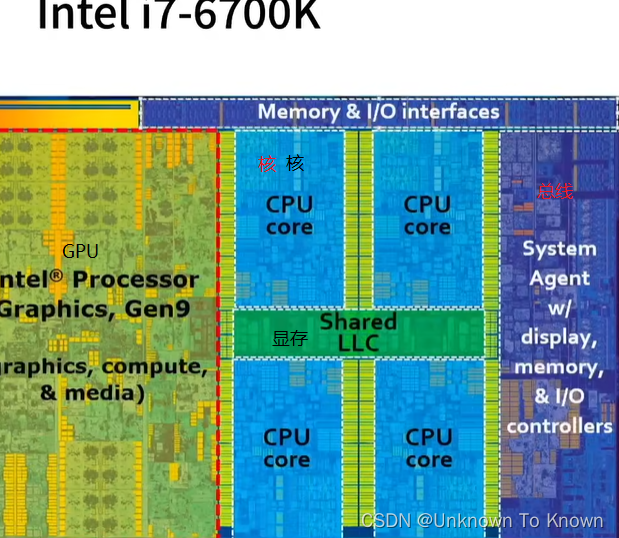
提升CPU利用率
- 在计算a + b之前,需要准备数据
- 主内存 —>L3(显存)—>L2(核)—>L1—>寄存器
- L1访问延时:0.5ms
- L2访问延时:7ns(14 * L1)
- 主内存访问延时:100ns(200 * L1)
- 提升空间和时间的内存本地性
- 时间:重用数据使得保持它们在缓存里
- 空间:按序读写数据使得可以预读取
- 主内存 —>L3(显存)—>L2(核)—>L1—>寄存器


提升GPU利用率
- 并行
- 使用数千个线程