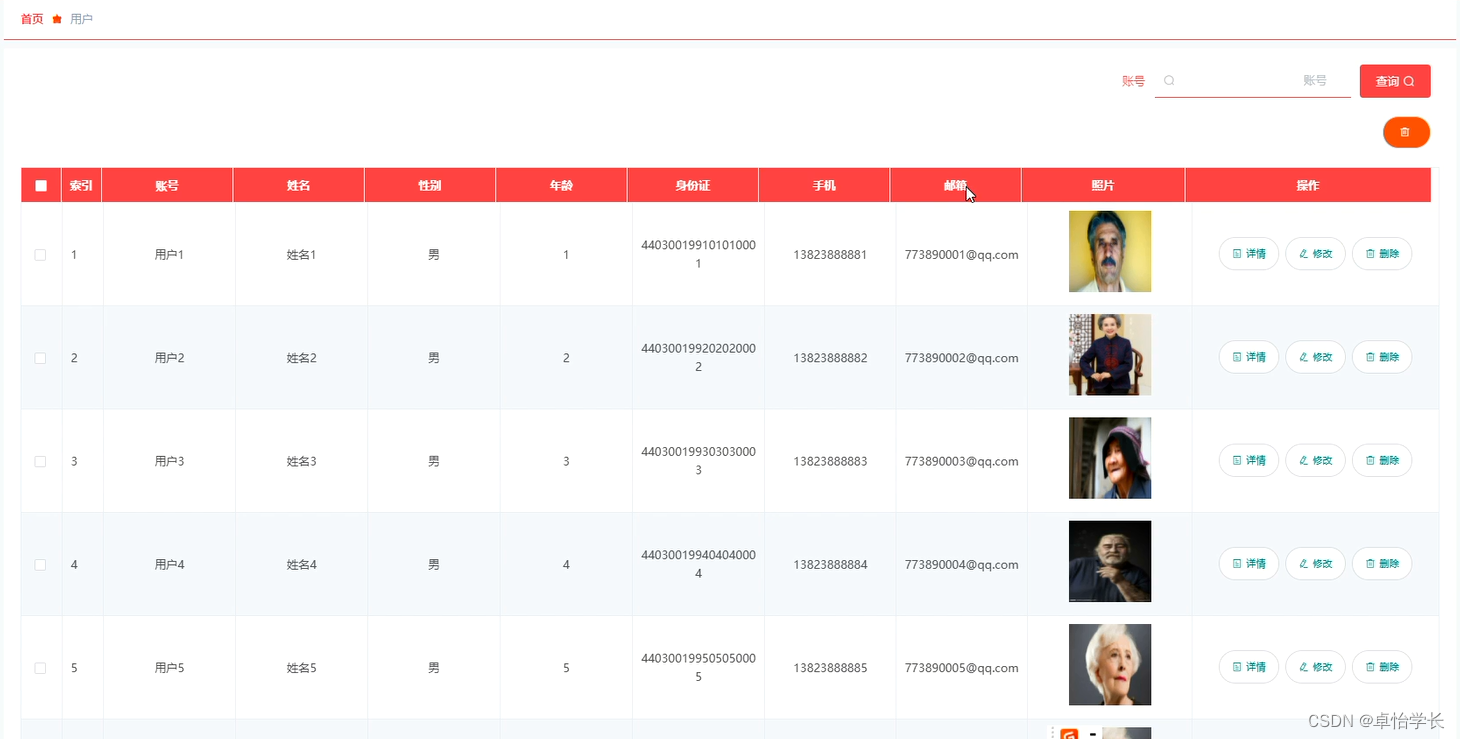
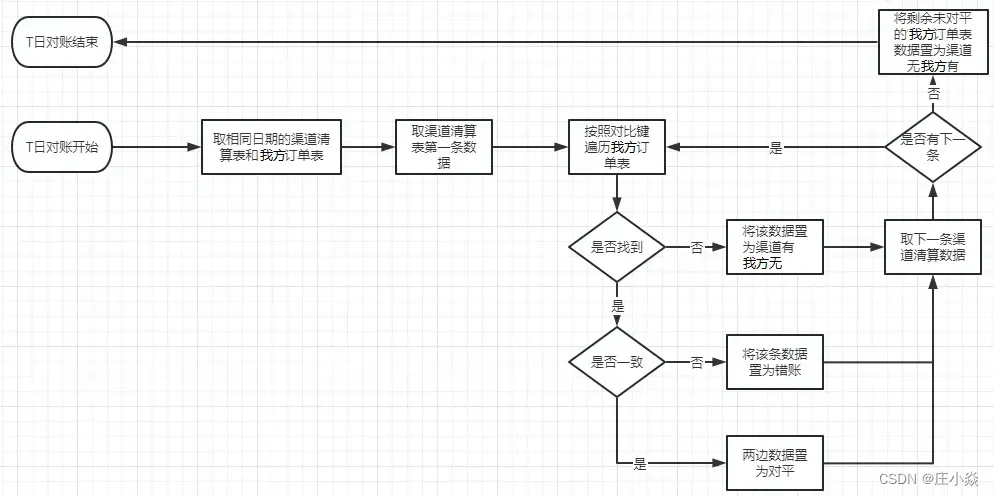
01 Raft 概述
KaiwuDB 的事务是通过使用 Raft 协议来实现数据的一致性。Raft 协议是一种经典的分布式一致性算法,它的主要特征有:
- 选举唯一的 Leader 处理读写请求并创建新的 Raftlog,其它节点作为 Follower 接收 Leader 同步的
Raftlog; - Leader 无法修改或删除自身的 Raftlog,只能对其进行增加;Follower 可删除和 Leader 有冲突的 Raftlog;
- Raftlog 严格按照顺序连续增加。即最新的 Raftlog 一定在最后,并且任意个 Raftlog 的序号一定刚好是它先前一个
Raftlog 的序号(Index)加 1; - Raftlog 被同步到超过一半的节点后就被视为已提交(Committed),已提交的 Raftlog 不会丢失。
Raft 主要工作过程:选举和日志提交
- 选举
选举是 Raft 协议工作的主要过程之一,成功且安全的选举是 Raft 开启工作的前提。在集群刚启动或 Follower 节点发现 Leader 心跳异常时,一轮选举就会被触发。每一轮选举对应一轮任期(Term),若发现当前集群没有 Leader 节点,则该节点即变为 Candidate(候选者),自身缓存的任期+1,为自己投票,而后向其它节点发送 RequestVote RPC 拉取选票。

RequestVote RPC 中携带候选者的信息,以帮助收到请求的节点决定是否投票,主要信息包括:候选者当前任期,候选者最新 Raftlog 的任期及编号。节点会检查上述信息,并判断是否投票。当出现以下情况时不投票:
-
候选者的任期不高于自己的任期;
-
候选者最新的 Raftlog 落后于自己最新的 Raftlog;
-
在当前任期自己已投过票。
除去上述情况,节点会为候选者投一票,缓存投票信息,并更新自身任期。候选者获取超过一半投票后(包括自己所投一票),则认为已当选为 Leader。之后立即开始向其它节点发送心跳,以防止选举超时出现新一轮选举。其它节点收到心跳后则停止选举,原先是候选者的节点则自动变更为 Follower,所有 Follower 检查自身的任期并和 Leader 对齐,准备接收 Leader 同步的 Raftlog。
- 日志提交
Leader 选出后需负责处理用户的写请求。每个写请求会被包装成 Raftlog,其中包含请求的命令和数据、当前任期 Term、当前 Raftlog 在所有的 Raftlog 中的位置(即 Index)、前一个 Raftlog 的 Term和 Index(即 revLogTerm 和 prevLogIndex)。通过 AppendEntries RPC 发送给 Follower 节点,Follower 回复消息通知 Leader 是否复制成功。当超过半数的节点(包括 Leader)复制成功后,这条 Raftlog 切换为已提交状态,不会再被修改或丢失。

Follower 节点收到 AppendEntries RPC 后不是无条件复制 Raftlog,它会检查自身最新 Raftlog 的 Term 和 Index 是否和最新的 Raftlog 中带来的 prevLogTerm 和 prevLogIndex 一致。如果一致则将收到的 Raftlog 追加至本地的 Raftlog,回复 Leader 结果为成功;反之,则回复失败。
如果 prevLogIndex 小于等于 Follower 的最新 Raftlog 的 Index 时,则说明 Leader 和 Follower 出现了数据冲突,需要删除 Follower 上的冲突数据,即 prevLogIndex 对应位置之后所有的 Raftlog。
Follower 回复失败说明 Follower上 的 Raftlog 有一定落后,Leader 会发送更早之前的 Raftlog,以确保 Follower 上 Raftlog 的连续性。在确认 Follower 上最新 Raftlog 的 Index 之后,Leader 再将后面 Follower 上不存在的 Raftlog 依次发送给 Follower,最终完成同步。
AppendEntries RPC 中还会携带当前已经提交的最新 Raftlog 的 Index,Follower 根据它来判断自身是否需要应用(apply)某些 Raftlog,即执行已经提交的 Raftlog 中的命令,将数据落盘。心跳是特殊的 AppendEntries RPC,其中没有 Raftlog,但包含了最新提交的 Index,通过心跳可使 Follower 更及时地落盘数据。
02 KaiwuDB 事务和 Raft
事务中可能包含多个 Request,即多次操作。其中读操作不需要进行 Raft 共识,可直接本地读取并返回结果。写操作则有预写操作,本地先写一份 MVCC 数据,并使用这个数据组装 Raftlog,而后发给 Follower 节点完成共识。
- 事务并行
KaiwuDB 中使用了 multi-raft,可提高并发程度。所有数据都按照 Range 进行分布,每个 Range 有多个副本,这些副本组成一个 Raft group,使用 Raft 协议实现数据的一致性。
- 事务流水线
KaiwuDB 事务中优化了 Raft 使用方式。按照 Raft 协议本身的定义,超过半数节点达成共识(复制完 Raftlog)后,方能进行下一步操作。而在 KaiwuDB 的事务中,每个请求不需要等待达成共识即可返回结果,并继续处理下一个请求,实现了共识和请求处理的并行,节省了等待共识花费的时间。等到事务提交时接收一个总的共识结果,最终共识达成意味着整个事务成功。

该方法本质上实现了 Raft 共识的并行。事务需要保证 A.C.I.D (原子性、一致性、隔离性、持久性)四个性质,在 KaiwuDB 事务中,Raft 协议的共识用来实现 C(一致性),Raftlog 的落盘则用于保证 A(原子性)和 D(持久性),最后的 I(隔离性)则通过下面提到的 WriteIntent 实现。
根据 Raft 协议日志提交策略,每个节点上的 Raftlog 都是按照顺序连续增加的,所以如果事务最终提交的 Raftlog 能够达成共识,那么事务中每次写操作的 Raftlog 必定也达成了共识。因此,只要确认了最终提交时的 Raft 共识,事务的一致性也就得到了保证。
- 并行提交
KaiwuDB 事务的隔离性通过预写 MVCC 数据等方法得到保证。预写操作会为事务操作的 Key 写入一个 WriteIntent,其中包含了要写入的数据,以及所属的事务信息。其它事务对相同的 Key 执行读写操作时会访问到这个 WriteIntent,进而发现已有事务持有了这个 Key,从而实现隔离性。事务提交时 WriteIntent 会转变为真正的数据并落盘,从而实现持久性,原先的 WriteIntent 则被删除。
因为有了预写数据 WriteIntent,因此事务提交可进一步优化,即事务提交后可以在共识完成之前就返回成功的结果,之后异步执行提交动作,即完成数据的落盘。此时所有的数据都已写入了 Raftlog 并落盘,实际数据不会丢失,只要依次解析 WriteIntent 完成真正数据的写入即可。

KaiwuDB 事务的状态包括 Pending(进行中),Staging(提交中),Commit(已提交),Abort(已回滚)。其中,KaiwuDB 引入了新的事务状态 Staging,用于描述事务开始提交到完成数据的实际落盘之间的状态。事务的状态会随事务信息落盘,保证宕机重启后可以根据事务的实际状态选择要执行的操作。若重启后事务的状态是 Pending,则需要回滚,释放 WriteIntent;若事务状态是 Staging,则需要完成 WriteIntent 的解析和数据写入,最终达到 Commit 状态;若事务状态是 Commit 或 Abort,则不需要进行操作。引入 Staging 细化提交过程,对描述 KaiwuDB 的事务状态和实现事务恢复都有很大的帮助。

![[JS]DOM事件](https://img-blog.csdnimg.cn/img_convert/d084a85e43239bdd0538ffca877dff82.png)