物联网应用常常需要收集大量的数据,用以支持智能控制、业务分析和设备监控等功能。然而,应用逻辑的更新或硬件的调整可能会导致数据采集项频繁变化,这是时序数据库(Time Series Database,TSDB)面临的一大挑战。
为了适应这种动态变化,TDengine 提供了一种无需预先定义表结构的 Schemaless 写入模式。这种模式允许开发者直接通过写入接口送入数据,系统会自动建立对应的数据存储结构。在数据结构需要调整时,Schemaless 模式也能自动添加新的数据列,确保所有数据都能被准确记录。如果大家想要详细了解 Schemaless 写入的主要处理逻辑、映射规则与变更处理等机制,可以进入 TDengine 官网技术文档直接查看(Schemaless 写入 | TDengine 文档 | 涛思数据)。
TDengine 对 Schemaless 写入功能进行了深入优化,以提高其灵活性和效率。本文将介绍其中部分优化措施的详细过程和技术方法,帮助开发者更好地理解和利用这一功能,从而提升应用性能。同时,我们也希望这些分享能帮助开发人员在性能优化方面迈向新的高度。
性能优化流程
分析性能瓶颈在哪里?
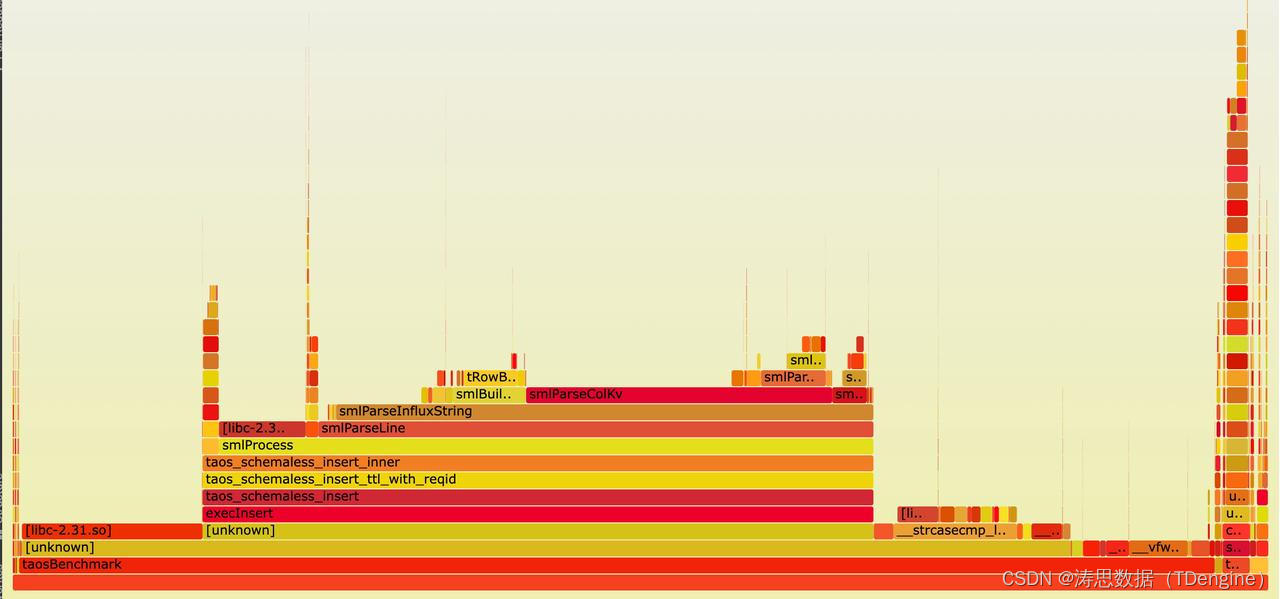
通过分析下文中数据写入的火焰图,我们会发现 parser 部分和 insert 部分占用的耗时都很高,并且主要集中在 parseSmlKey, parseSmlValue, addChildTableDataPointsIntoSql, taos_query_a, buildDataPointSchema 几个函数中。
物联网应用常常需要收集大量的数据,用以支持智能控制、业务分析和设备监控等功能。然而,应用逻辑的更新或硬件的调整可能会导致数据采集项频繁变化,这是时序数据库(Time Series Database,TSDB)面临的一大挑战。
为了适应这种动态变化,TDengine 提供了一种无需预先定义表结构的 Schemaless 写入模式。这种模式允许开发者直接通过写入接口送入数据,系统会自动建立对应的数据存储结构。在数据结构需要调整时,Schemaless 模式也能自动添加新的数据列,确保所有数据都能被准确记录。如果大家想要详细了解 Schemaless 写入的主要处理逻辑、映射规则与变更处理等机制,可以进入 TDengine 官网技术文档直接查看(Schemaless 写入 | TDengine 文档 | 涛思数据)。
TDengine 对 Schemaless 写入功能进行了深入优化,以提高其灵活性和效率。本文将介绍其中部分优化措施的详细过程和技术方法,帮助开发者更好地理解和利用这一功能,从而提升应用性能。同时,我们也希望这些分享能帮助开发人员在性能优化方面迈向新的高度。
性能优化流程
分析性能瓶颈在哪里?
通过分析下文中数据写入的火焰图,我们会发现 parser 部分和 insert 部分占用的耗时都很高,并且主要集中在 parseSmlKey, parseSmlValue, addChildTableDataPointsIntoSql, taos_query_a, buildDataPointSchema 几个函数中。
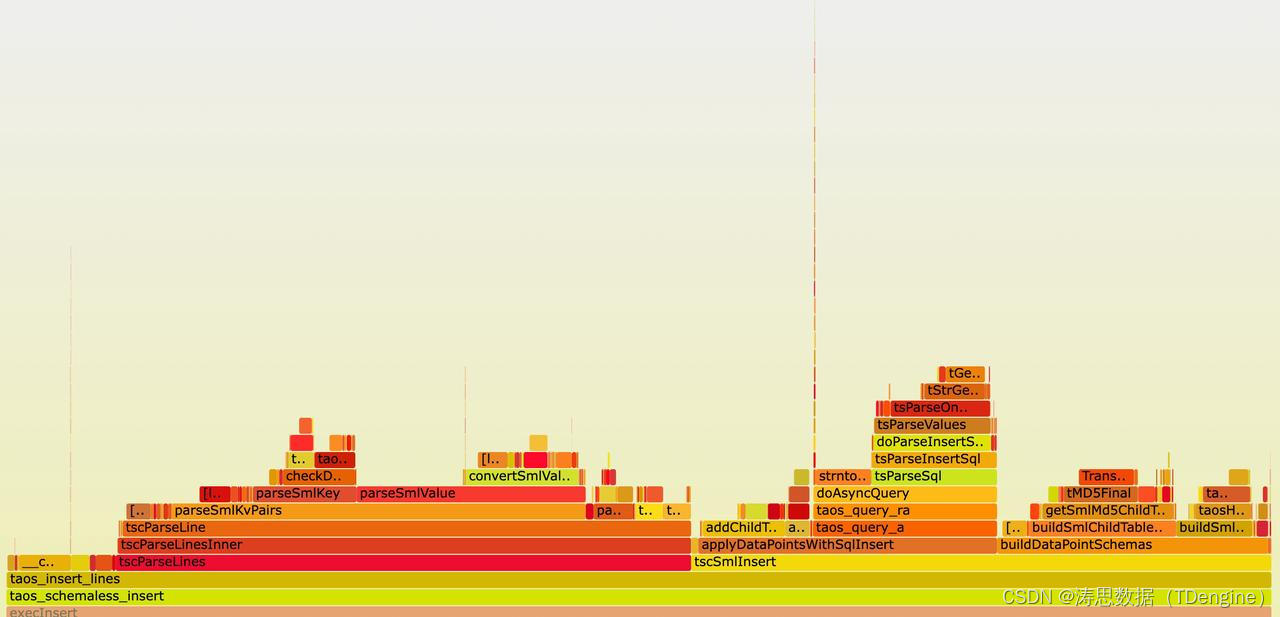
性能瓶颈如何解决?
针对上面火焰图分析的情景,对于每个函数,我们有两种方法来优化——要么去掉要么缩短。
如何去掉?能否去掉?
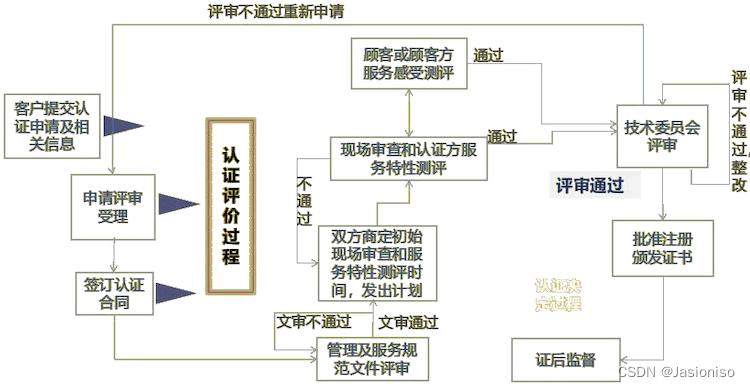
首先我们需要先详细了解现有的解析处理框架。下图是现有框架的处理流程图:

从图中我们能够发现存在一些不合理的地方,如下:
-
行协议解析析(Parser)
在处理数据时,系统会遍历每条记录,提取出测量值(measure)、标签(tag)以及列(col)的键值对,并将这些信息存储于定制的结构体中。此外,系统还会对每条记录中的标签键进行排序,并依照既定规则生成对应的子表名称。然而,此流程中对标签的解析、排序及子表名称生成的重复执行,增加了处理时间和计算复杂度。
-
schema 处理
在获取测量值(measure)的架构元数据(schema meta)之后,系统会对该测量值下的每一条数据执行以下操作:遍历其标签(tag)和列(col),并检查现有架构是否需要更新,更新操作可能包含 create stable, add col, add tag, modify col, modify tag。
-
insert 数据
当数据量小于 10 条时,系统将逐条构造 SQL 语句,并通过调用taos_query函数逐一插入数据。对于超过 10 条的数据集,系统将构建stmt结构体,并利用stmt接口批量插入数据。
-
一些关键的代码如下图。(主要函数为 tscParseLine/parseSmlKvPairs/tscSmlInsert/buildDataPointSchemas/modifyDBSchemas/applyDataPointsWithSqlInsert 等)
-

-
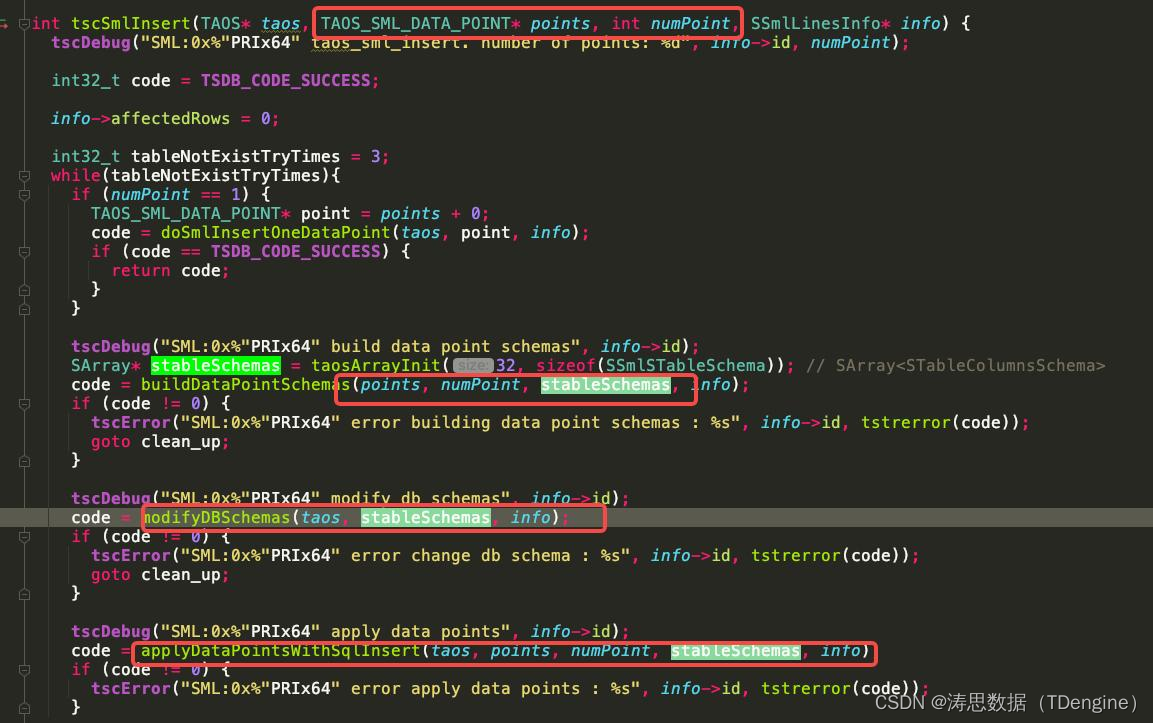
详细代码请见如下链接:
-
https://github.com/taosdata/TDengine/blob/2.6/src/client/src/tscParseLineProtocol.c
-
https://github.com/taosdata/TDengine/blob/2.6/src/client/src/tscParseOpenTSDB.c
针对以上问题,我们首先可以从架构上面进行大的优化。

主要包括如下几个方面:
-
行协议解析
-
分析数据可以看出,相同的标签(tag)前缀通常保持一致,所以可以对数据的标签字符串进行预分组,将具有相同前缀的标签归入同一组。在每个分组内,只需对标签进行一次解析,减少重复解析的操作。
-
检查数据的顺序,如果顺序相同,则可以直接按照顺序进行数据绑定,避免使用哈希查找,从而减少计算量和提高处理速度。
-
-
schema 处理
-
提前在解析时判断是否需要变更架构(schema),检查是否存在列的增加或列长度的变更。如果需要变更,再走修改架构(modify schema)的逻辑。
-
-
insert 数据
-
数据构造直接在解析每行时实现,直接将数据绑定到最终的
STableDataCxt结构中。这种做法可以避免在后续阶段再次进行数据绑定和二次拷贝。 -
改进数据写入方法,采用直接构造
BuildRow的方式,避免使用 SQL 或stmt接口而产生二次解析。
-
-
一些关键的代码如下图。(主要函数为smlParseInfluxString/smlParseTagKv/smlParseColKv/smlParseLineBottom/smlModifyDBSchemas/smlInsertData)
-
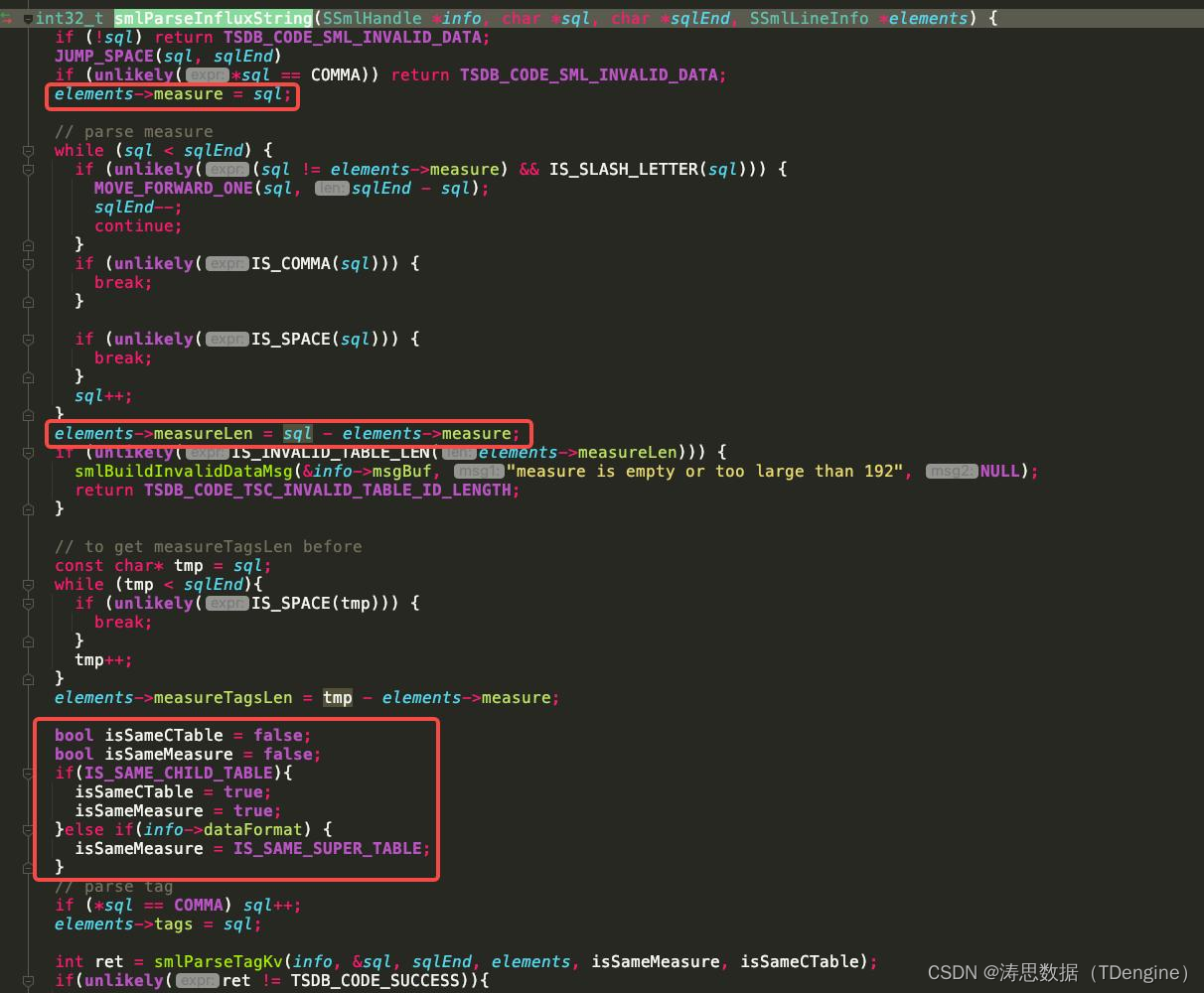
-
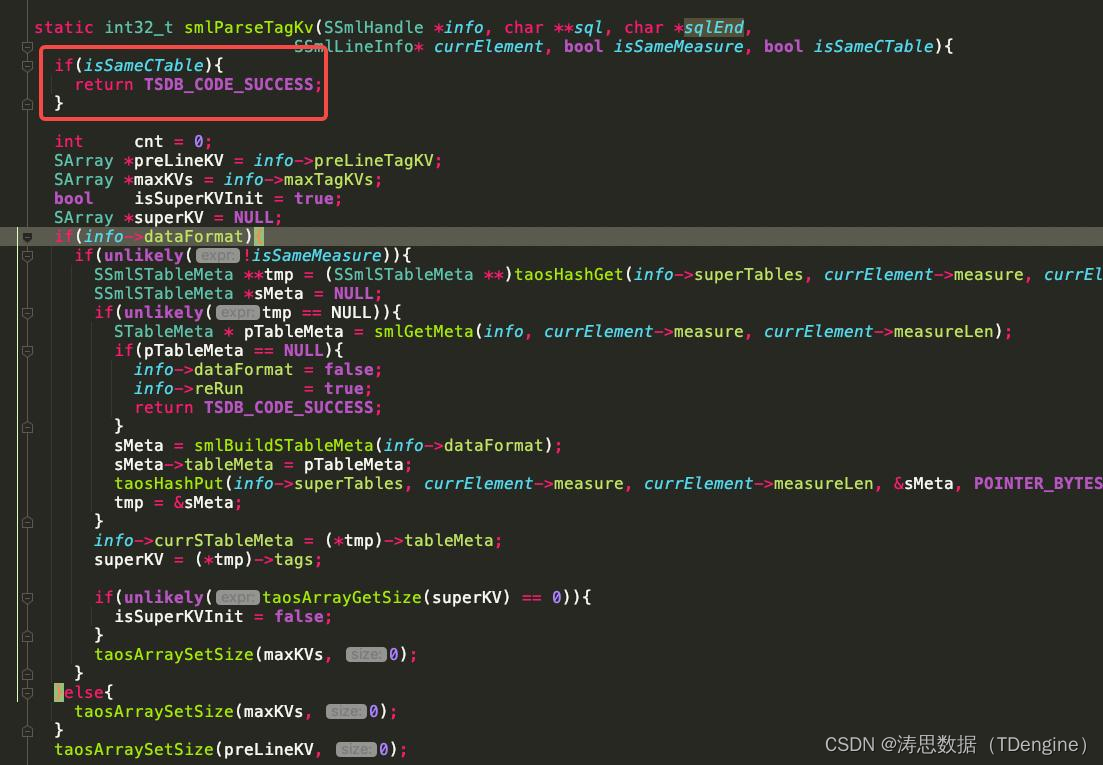
详细代码见如下链接:
-
https://github.com/taosdata/TDengine/blob/3.0/source/client/src/clientSml.c
-
https://github.com/taosdata/TDengine/blob/3.0/source/client/src/clientSmlLine.c
-
https://github.com/taosdata/TDengine/blob/3.0/source/client/src/clientSmlTelnet.c
-
https://github.com/taosdata/TDengine/blob/3.0/source/client/src/clientSmlJson.c
在架构优化过程中,我们还发现内存使用也可以进行优化。
在数据解析过程中,将数据转换为无架构(schemaless)格式时,对测量值(measure)、标签(tag)和列(col)进行了大量的内存分配和拷贝操作。这些操作虽然常见,但并非必要,存在优化空间:
-
在解析数据时,不直接进行数据的拷贝和内存分配。而是记录下每个数据项在原始数据中的指针位置和长度。
-
在数据需要最终写入数据库前,再根据这些记录的位置和长度信息,从原始数据中直接拷贝相关数据。
如下:
st,t1=3,t2=4,t3=t3 c1=3i64,c3="passit",c2=false,c4=4 1626006833639000000
1)t1/t2/t3/c1/c3/c2 全部 calloc,拷贝到新的内存
typedef struct { char* key; uint8_t type; uint16_t length; char* value; uint32_t fieldSchemaIdx; } TAOS_SML_KV;

2)直接指针记录位置,避免内存分配拷贝
typedef struct { char *measure; char *tags; char *cols; char *timestamp; char *measureTag; int32_t measureLen; int32_t measureTagsLen; int32_t tagsLen; int32_t colsLen; int32_t timestampLen; SArray colArray; } SSmlLineInfo;
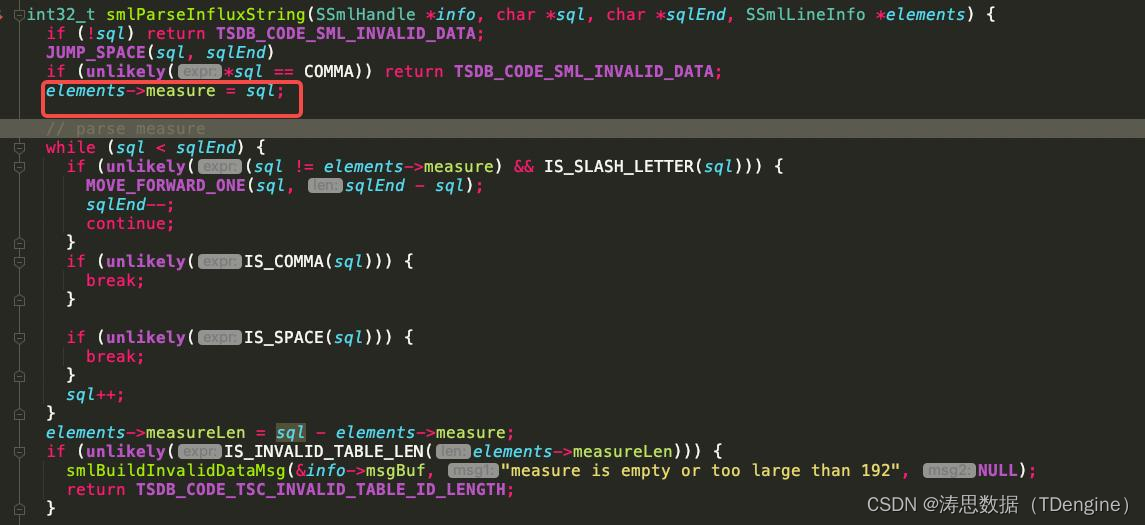
如何缩短?
-
时间精度转换优化
直接寻址代替条件判断,注意溢出的处理。
if(fromPrecision == ){} else if( fromPrecision == ){} else {} int64_t smlToMilli[3] = {3600000LL, 60000LL, 1000LL}; int64_t unit = smlToMilli[fromPrecision - TSDB_TIME_PRECISION_HOURS]; if (unit > INT64_MAX / tsInt64) { return -1; } tsInt64 *= unit;
-
Json 解析优化
因为写入的 Json 数据格式基本固定,所以可以提前计算出各个元素(metric, timestamp, value, tags)的偏移位置,直接偏移到相应位置处理。
[ { "metric": "meter_current", "timestamp" : 1346846400, "value": 18, "tags": { "location": "上海", "id": "d1001" } }, {} ]
-
判断逻辑优化
每次判断最大限度的减少信息熵,将概率最大的 if 条件放在前面判断。(i64 / u64 / i8 / u8 / true / L"" )
if( str equals "i64"){} else if( str equals "i32"){} else if( str equals "u8"){} ··· if(str[0] equals "i"){} else if(str[0] equals "u"){} ...
其他优化
-
likely / unlikely
根据代码执行的概率,指导编译器优化指令流水线的加载顺序。
if(unlikely(len == 0 || (len == 1 && data[0] == '0'))){ return taosGetTimestampNs()/smlFactorNS[toPrecision]; }
-
程序日志频繁打印,也会导致性能下降。我们在测试中发现,每批的统计信息打印会导致耗时占用上升 10% 左右。
性能优化对比
| 版本 | sql | line协议 | telnet协议 | json协议 |
| 2.6(4ec22e8) | 4543622 | 1458304 | 2161855 | 1272000 |
| ver-3.0.0.0 | 1638498 | 1650033 | 1945982 | 800000 |
| 3.0(f6793d5) | 3740774 | 3602947 | 4328447 | 5520000 |
速度单位为 records/second
在 TDengine 3.0 版本与 2.6 版本的对比中,可以看到,line 协议性能提升了 2.5 倍,telnet 提升了 2 倍,而 json 的提升接近 5 倍。
性能分析工具
火焰图
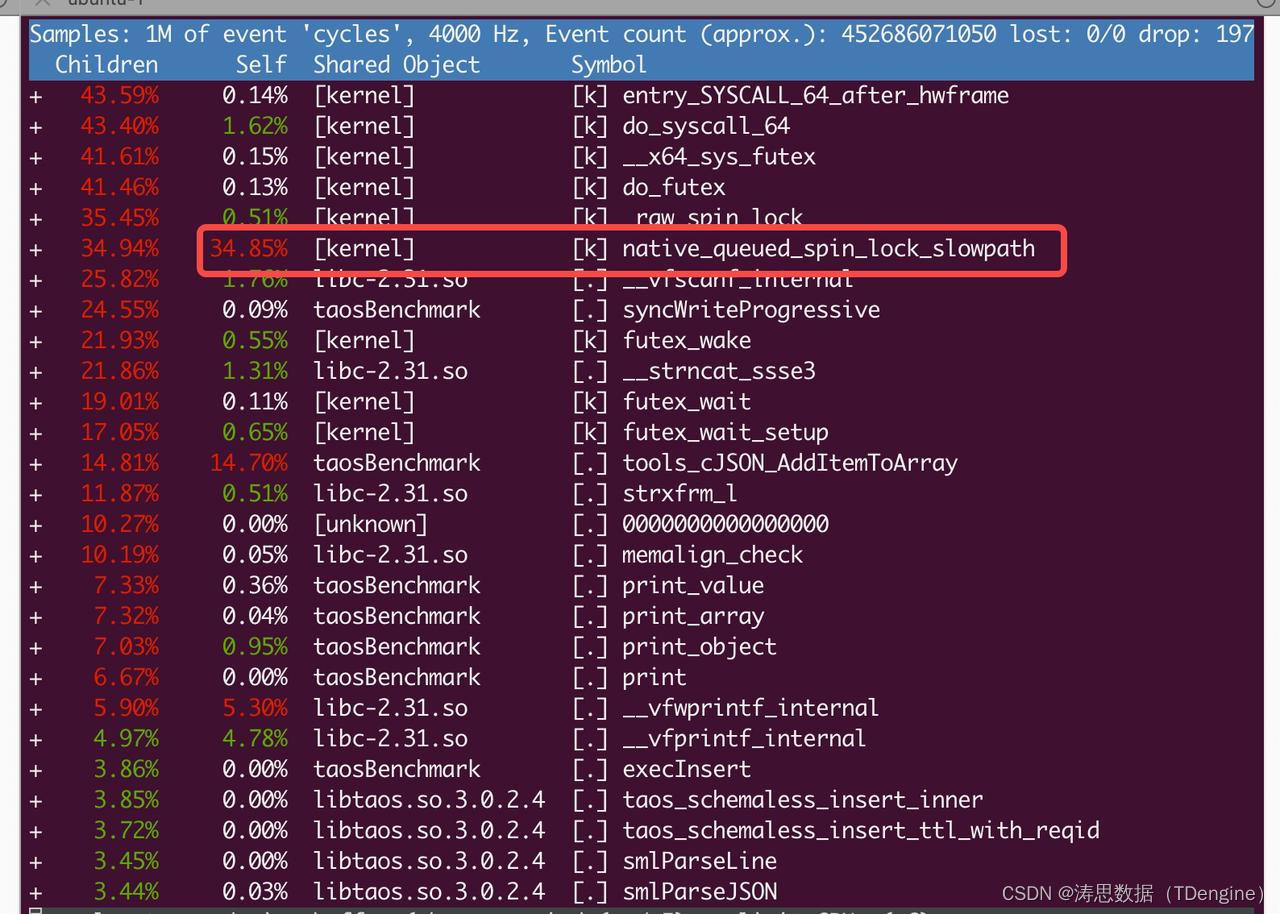
perf 工具
通过 perf top -p 111290 -g 分析,可以看到 CPU 占用率很高
结语
我们在进行性能优化前,首先需全面了解系统的流程和架构,确保对其有深刻认识。性能优化应着重关注以下三个方面:
-
架构评估:优秀的性能建立在合理且高效的架构之上。首先检查架构设计的合理性和效率,这是提升性能的基础。
-
识别并解决性能瓶颈:在良好的架构基础上,应优先解决主要的性能瓶颈,逐步优化次要问题,以实现持续的性能提升。
-
性能分析方法:利用火焰图分析各函数的调用耗时(宽度),对于一些看不到调用栈的地方可以添加日志打印每步骤的耗时,以精确地识别和分析性能瓶颈。
通过综合考虑 CPU、存储、网络、编译器及硬件等多个方面,并结合程序本身的特点,大家就可以实现有效的性能优化了。最后,希望本篇文章能够帮助到有需要的开发者,也欢迎大家体验 TDengine 的 Schemaless 写入性能。