数据库性能优化涉及各个方面,本文就总多个角度介绍一下数据库性能优化的方法
1.表设计
聚集索引
一个表只能有一个聚集索引,数据在磁盘上的排练顺序与聚集索引一致,根据业务仔细设定聚集索引,值递增的不可修改的字段才能设置聚集索引: 自增Id,递增的单号,创建日期等
应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
主键
一个表主键经常被其他表引用,也就经常出现在连接条件和Where条件中,合适的主键对于SQL性能起到了关键的作用
如果业务上已经有唯一的递增的不可修改的,关键业务字段,优先考虑使用业务字段做主键,例如订单的单号,单号符合 唯一,递增,不可修改,长度固定,关键业务,这些特性,非常适合做主键
其次考虑自增id,检索的效率最高
主键默认是聚集索引
创建时间
创建时间唯一,递增,不可修改,经常用于where条件中进行范围检索,非常适合做聚集索引
要先设置聚集索引,再设置主键,才不会被主键默认占用聚集索引
非聚集索引
就是普通的索引,可准确预估到会高频出现在where条件和连接条件中的字段可以设置索引,否则不要设置,待出现性能瓶颈后,分析sql后再设置
null与字符串默认空字符串
在where条件中出现null值判断会破坏索引的使用,所以在表设计时就尽量把列设置为not null , 空字符串可以存储’’ ,其他类型没有通用的替代方案, 例如 枚举可以用-1代表空值
外键
不要设置外键!!
不要设置外键!!
不要设置外键!!
外键只作为业务概念存在,不做数据库约束,否则会带来运维灾难
建表的例子
--表说明xxxxx
IF OBJECT_ID ('SysUser', 'U') IS NULL
BEGIN
CREATE TABLE [dbo].[SysUser]
(
[Id] BIGINT IDENTITY (1, 1) NOT NULL,
[UserCode] NVARCHAR (32) NOT NULL,
[PhoneNumber] NVARCHAR (32) NOT NULL,
[Password] NVARCHAR (128) NOT NULL,
[UserName] NVARCHAR (256) NOT NULL,
[CreationTime] DATETIME NOT NULL,
[CreatorUserId] BIGINT NULL,
[LastLoginTime] DATETIME NULL,
[LastModificationTime] DATETIME NULL,
[LastModifierUserId] BIGINT NULL,
[IsActive] BIT NOT NULL
);
--添加聚集索引,根据业务仔细设定,值递增的字段才能设置聚集索引
CREATE CLUSTERED INDEX IX_SysUser_CreationTime
ON SysUser (CreationTime);
--添加非聚集索引
CREATE NONCLUSTERED INDEX IX_SysUser_CreatorUserId
ON SysUser (CreatorUserId);
--添加默认值
ALTER TABLE SysUser ADD CONSTRAINT DF_SysUser_CreationTime DEFAULT GetDate() FOR CreationTime
--添加主键
ALTER TABLE SysUser ADD CONSTRAINT PK_SysUser PRIMARY KEY (Id);
END
GO
2.索引
- 出现性能瓶颈的时候,先考虑SQL有没有优化的空间,优化后再考虑在 where 及 order by 涉及的列上建立索引
- 索引固然可以提高相应的 select 的效率,但同时也降低了 insert 、 update 及 delete 的效率, 所以不是索引不是越多越好
- 数据量大的表,维护索引的开销也大, 建索引要慎重
- 数据量小的表用不着建索引
- 索引列存在大量重复数据时效果不明显, 此时不应该建索引, 例如sex列
3.Where
like/Or/In
引起减少引起全表扫描的动作: or、like(‘%%’)、in和not in (
用左匹配(走索引),不用右匹配,不用全匹配(不走索引):Where UserName like ‘abc%’
很多时候用exists,between替代 in 是一个好的选择:
Where num in(select num from b)
用下面的语句替换:
Where exists(select 1 from b where num=a.num)
不等于
尽量不用not 或 =! 或 <> ,将放弃索引
运算
不要在 where 子句中的“=”左边进行函数、算术运算、类型转换或其他表达式运算,否则系统将可能无法正确使用索引
函数
尽量避免在where子句中对字段进行函数操作,否则将导致全表扫描。
例如: Where substring(name,1,3) = ‘abc’
应改为Where name like ‘abc%’
计算
尽量避免在where子句中对字段进行表达式操作,否则会导致全表扫描。可以把字段从表达式中移除走,
例如: Where num/2 = 100
应改为 Where num = 100 *2
条件顺序
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
4.Join
少用左连接,多用内连接
left join 比 inner join 消耗更多的资源
连接条件的优化
遵循Where条件优化的建议
5.Select
能不能用函数
能不能用子查询
不用Select *
在查询中不要使用select *,检索不必要的列带来额外的系统开销
6.存储过程
合理使用临时表
- 避免频繁创建和删除临时表,会影响数据库性能
- 存储过程中某个复杂查询反复出现时, 可以把此查询结果先存入临时表, 提高性能
- 在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定
禁用游标,慎用循环 - 禁止使用游标,游标效率低,编写复杂,用游标不如用循环
- 然而当你需要使用循环的时候,你要考虑清楚有没有办法不使用循环而达到效果,如果一定要用,请务必考虑尽量减少循环的数据量
- 发挥数据库的优化,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效
7.其他SQL优化
- 控制嵌套调用的层数:存储过程嵌套,视图嵌套
- 尽量避免大事务操作,提高系统并发能力。当使用约束和触发器都能完成同样的功能时,优先考虑使用约束。
- 尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理
- Union和Union All :
UNION 因为会将各查询子集的记录做比较,故比起UNION ALL ,通常速度都会慢上许多。一般来说,如果使用UNION ALL能满足要求的话,务必使用UNION ALL。还有一种情况大家可能会忽略掉,就是虽然要求几个子集的并集需要过滤掉重复记录,但由于脚本的特殊性,不可能存在重复记录,这时便应该使用UNION ALL,如xx模块的某个查询程序就曾经存在这种情况,见,由于语句的特殊性,在这个脚本中几个子集的记录绝对不可能重复,故可以改用UNION ALL)
8.堵塞与死锁
数据库阻塞
第一个连接占有资源没有释放,而第二个连接需要获取这个资源。如果第一个连接没有提交或者回滚,第二个连接会一直等待下去,直到第一个连接释放该资源为止。
长期堵塞严重影响系统体验,所以对数据库操作要及时地提交或者回滚
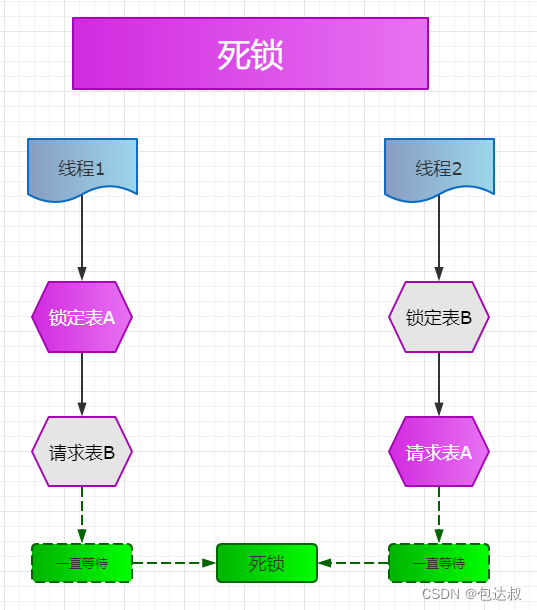
数据库死锁
第一个连接占有资源没有释放,准备获取第二个连接所占用的资源,而第二个连接占有资源没有释放, 准备获取第一个连接所占用的资源。这种互相占有对方需要获取的资源的现象叫做死锁。对于死锁,数据库处理方法:牺牲一个
死锁严重影响系统体验, 发现死锁脚本, 结合业务优化脚本
9.其他数据库性能优化
分库分表
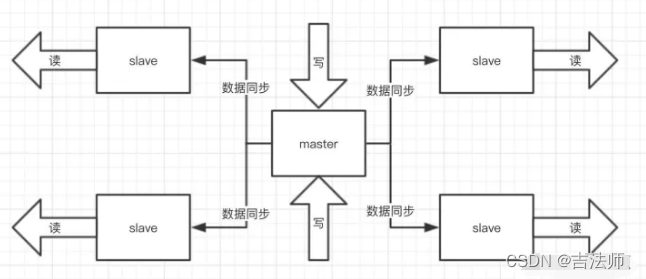
读写分离: 高可用,订阅与发布