目录
1.提取依赖包
2.所有节点安装chrony服务
2.1集群角色规划
2.2 所有节点安装chrony服务
2.3添加hosts文件解析(服务端)
2.4修改时间服务器
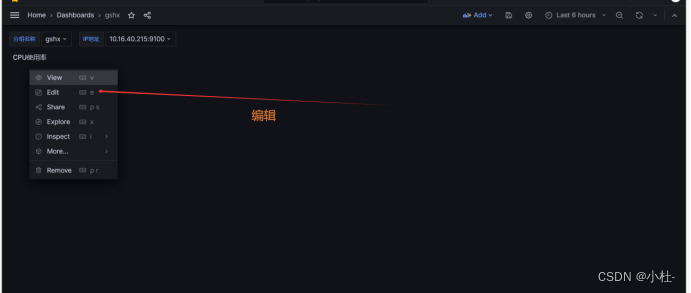
编辑
2.5重启chrony服务,使得配置生效
2.6修改客户端配置(注意是客户端其他节点)
2.6.1添加housts解析
2.6.2指定时间服务器
2.6.3重启chrony服务,使得配置生效
2.6.4 测试时间服务器是否生效
2.6.5 重启服务
3.二进制部署prometheus-server
3.1创建工作目录
3.2解压软件包到指定路径
3.3 创建符号链接
3.4启动prometheus
3.4.1以相对路径启动
3.4.2以绝对路径启动
3.4.3 以环境变量的方式启动
3.5 访问prometheus的WebUI
3.6将prometheus服务设置为开机自启动
3.7将服务设置开机自启动
3.7.1使用systemctl进行重载
3.7.2使用API请求重载(要求启动服务时开启"--web.enable-lifecycle "参数)
4.部署node-exporter(所有节点安装)
4.1 解压软件包到指定路径
4.2 启动node-exporter服务
5.Prometheus配置监控node-expoter
5.1重新加载配置文件
5.2访问Prometheus的WebUI
6.安装grafana
6.1内网部署需要很多依赖包(依次导入)
6.2 启动grafana
6.3访问grafana的WebUI
6.4配置grafana的数据源为prometheus
6.4.1进入管理员界面
6.4.2添加数据源
6.4.3选择数据源为prometheus
6.4.4配置prometheus数据源
6.4.5保存配置
7.部署grafana并导入node-exporter模板(内网略过)
7.1 进入到dashboard页面
7.2 进入导入模板页面
7.3选择相应的模板ID
8.grafana自定义dashboard案例
8.1创建dashboard
8.1.1新建dashboard
8.1.3创建可视化库
8.1.4效果图
8.2grafana的变量设置
8.2.1 进入设置页面
编辑
8.2.3引用instance标签的值
8.2.5引用instance标签的值
8.2.6引用instance标签的值
8.3Prom QL语句
9.Prom QL语句
9.1CPU核数
9.2CPU使用率
9.3内存总量
9.4内存使用率
9.5网络
9.6系统运行时间
9.7最大分区/data使用率
9.8系统负载(1m)
9.9过去5分钟内的网络上行速率,即每秒发送的字节数
10.0 过去5分钟内每个实例的下行速率
10.1磁盘IO读写时间
10.2磁盘每秒的I/O操作耗费时间(%)
10.3TCP 连接情况
10.4磁盘读写速率(IOPS)
10.5磁盘读写容量大小
10.6 上行速率大于0,表示没有延迟
10.大概效果图 根据自己审美来
10.16.40.215
编辑
10.16.36.204
1.提取依赖包
链接:https://pan.baidu.com/s/17bHDhmQvMHA3sg4s1OG0Sg
提取码:0124
--来自百度网盘超级会员V3的分享
2.所有节点安装chrony服务
2.1集群角色规划
根据自己服务器规划
| 主机名 | IP地址 | CPU | 内存 | 磁盘 | 角色 |
| 10.16.36.204 | 20G+ | Prometheus server+grafana | |||
| 10.16.40.215 | 20G+ | Prometheus server | |||
| 可多节点我这里简单用两个 | 也可以用于单节点部署grafana 之后采集Prometheus server |
2.2 所有节点安装chrony服务
执行命令
rpm -ivh libseccomp-2.3.1-4.el7.x86_64.rpm chrony-3.4-1.el7.x86_64.rpm

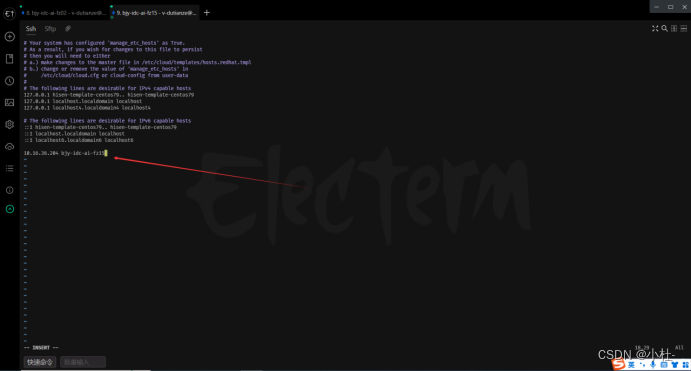
2.3添加hosts文件解析(服务端)
vim /etc/hosts
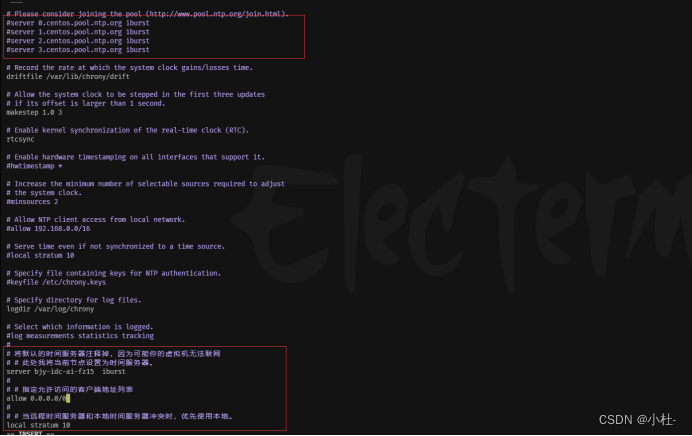
2.4修改时间服务器
vim /etc/chrony.conf
2.5重启chrony服务,使得配置生效
systemctl restart chronyd
2.6修改客户端配置(注意是客户端其他节点)
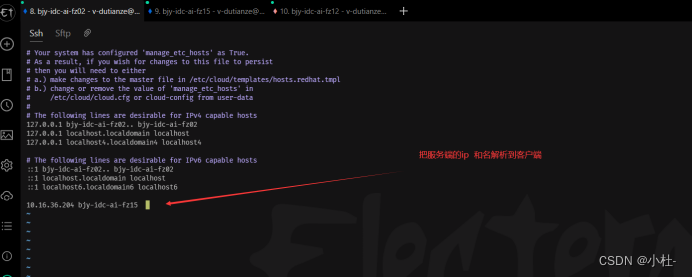
2.6.1添加housts解析
vim /etc/hosts
2.6.2指定时间服务器
vim /etc/chrony.conf
根据自己本机的修改
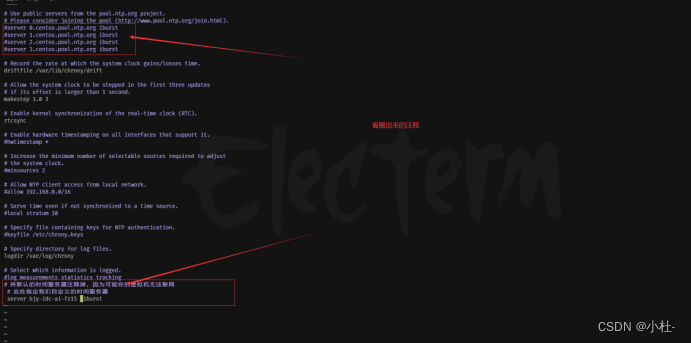
2.6.3重启chrony服务,使得配置生效
systemctl restart chronyd
2.6.4 测试时间服务器是否生效
修改时间
date -s "2020-10-01 08:30:00"
2.6.5 重启服务
systemctl restart chronyd
date -R
3.二进制部署prometheus-server
3.1创建工作目录
mkdir -pv /gshx/{softwares,data,logs}
3.2解压软件包到指定路径
tar xf prometheus-2.37.8.linux-amd64.tar.gz -C /gshx/softwares/
3.3 创建符号链接
cd /gshx/softwares/ && ln -sv prometheus-2.37.8.linux-amd64 prometheus
3.4启动prometheus
3.4.1以相对路径启动
cd /gshx/softwares/prometheus && ./prometheus
3.4.2以绝对路径启动
/gshx/softwares/prometheus/prometheus --config.file=/oldboyedu/softwares/prometheus/prometheus.yml 以环境变量的方式启动
3.4.3 以环境变量的方式启动
cat > /etc/profile.d/prometheus.sh <<EOF
#!/bin/bash
export PROMETHEUS_HOME=/gshx/softwares/prometheus
EOF
ln -sv /gshx/softwares/prometheus/prometheus /usr/local/bin/
prometheus --config.file=${PROMETHEUS_HOME}/prometheus.yml3.5 访问prometheus的WebUI
http://10.16.36.204:9090/graph
IP根据自己的改
3.6将prometheus服务设置为开机自启动
编写启动脚本
/etc/systemd/system/prometheus-server.service
[Unit]
Description=gshx Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Restart=on-failure
ExecStart=/gshx/softwares/prometheus/prometheus \
--config.file=/gshx/softwares/prometheus/prometheus.yml \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target3.7将服务设置开机自启动
systemctl enable --now prometheus-server
ss -ntl
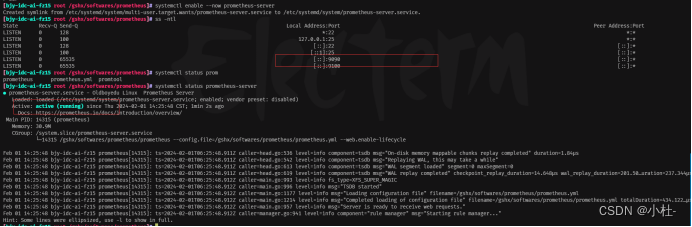
3.7.1使用systemctl进行重载
systemctl reload prometheus-server
3.7.2使用API请求重载(要求启动服务时开启"--web.enable-lifecycle "参数)
curl -X POST http://10.16.36.204:9090/-/reload
4.部署node-exporter(所有节点安装)
4.1 解压软件包到指定路径
tar xf node_exporter-1.6.1.linux-amd64.tar.gz -C /gshx/softwares/
4.2 启动node-exporter服务
cd /gshx/softwares/node_exporter-1.6.1.linux-amd64/ && ./node_exporter
vim /lib/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
After=network-online.target
[Service]
User= prometheus
Type=simple
WorkingDirectory=/gshx/softwares/node_exporter-1.6.1.linux-amd64/
ExecStart=/gshx/softwares/node_exporter-1.6.1.linux-amd64/node_exporter \
--collector.filesystem.fs-types-exclude=tmpfs|proc|rpc_pipefs|rootfs|nfs4 \
--collector.diskstats.device-exclude=dm.*|sr\d+|loop\d+ \
--collector.netclass.ignored-devices=br.*|docker.*|veth.*|lo.*|tap.*|virbr.*|cni.*|fw.*|vlan.*|vmbr.* \
--collector.netdev.device-exclude=br.*|veth.*|docker.*|lo.*|tap.*|virbr.*|cni.*|fw.*|vlan.*|vmbr.* \
--collector.filesystem.mount-points-exclude=.*docker.* \
--no-collector.arp \
--web.listen-address=0.0.0.0:9100 \
--log.level=debug
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
RestartSec=20
CPUQuota=100%
MemoryLimit=512M
[Install]
WantedBy=multi-user.targetsystemctl enable --now node_exporter # 启动并开机自启
5.Prometheus配置监控node-expoter
vim /gshx/softwares/prometheus/prometheus.yml
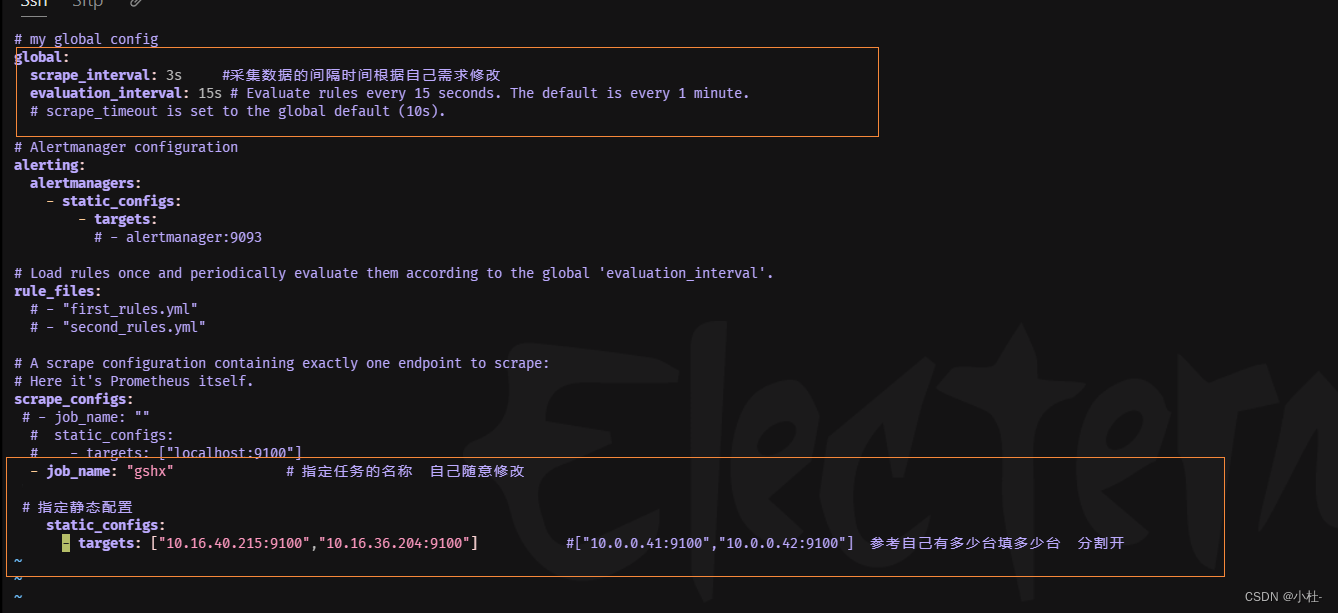
5.1重新加载配置文件
curl -X POST http://10.16.36.204:9090/-/reload
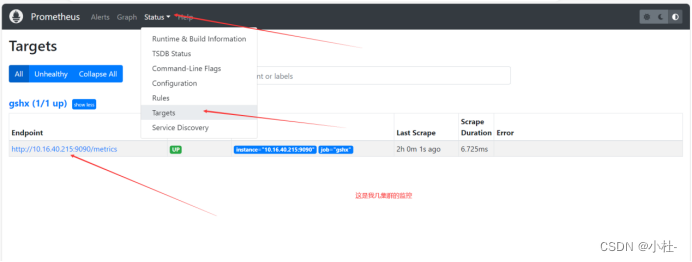
5.2访问Prometheus的WebUI
http://10.16.36.204:9090/targets
6.安装grafana
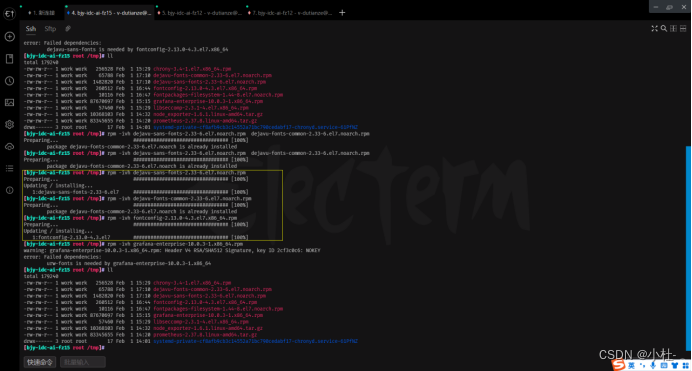
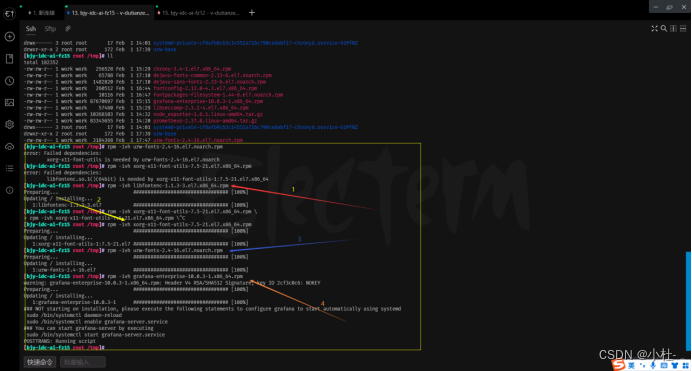
6.1内网部署需要很多依赖包(依次导入)
就按圈内的操作其他不要管,自己的测试
rpm -ivh 包名
6.2 启动grafana
systemctl enable --now grafana-server
ss –ntl
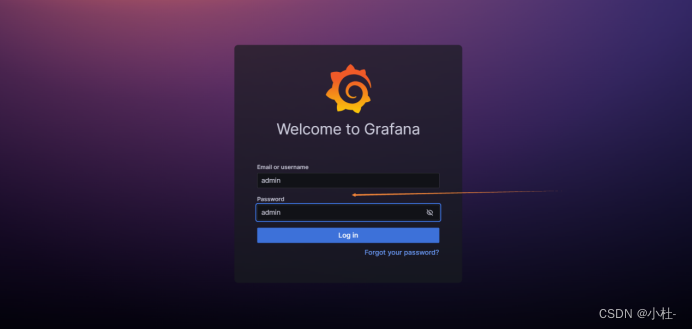
6.3访问grafana的WebUI
http://10.16.36.204:3000/
6.4配置grafana的数据源为prometheus
6.4.1进入管理员界面
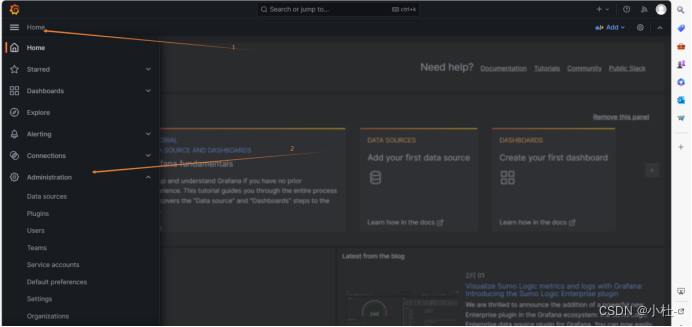
6.4.2添加数据源
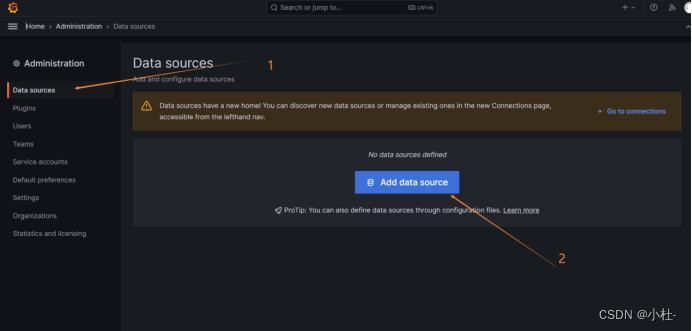
6.4.3选择数据源为prometheus
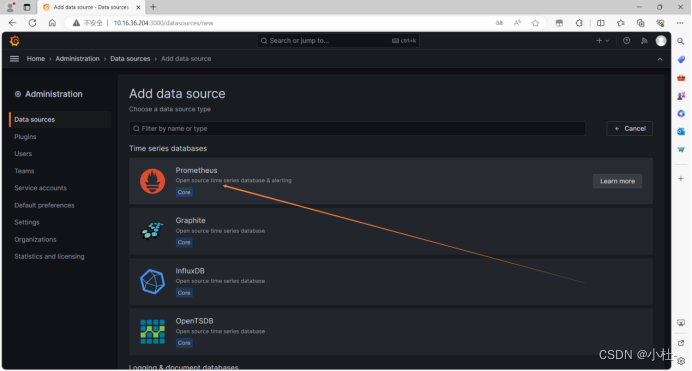
6.4.4配置prometheus数据源
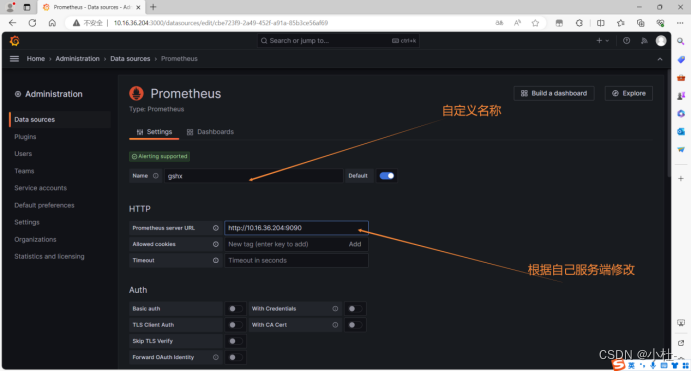
6.4.5保存配置
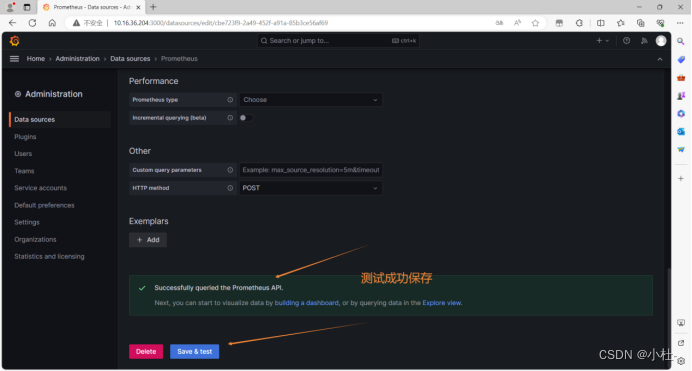
7.部署grafana并导入node-exporter模板(内网略过)
7.1 进入到dashboard页面
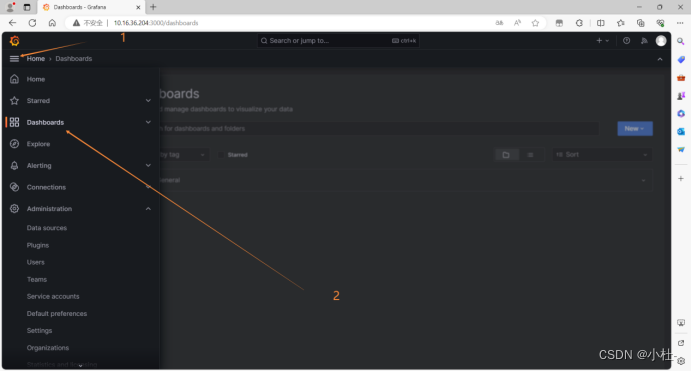
7.2 进入导入模板页面
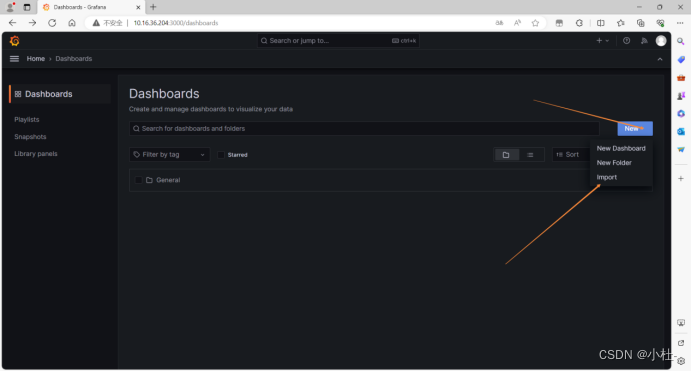
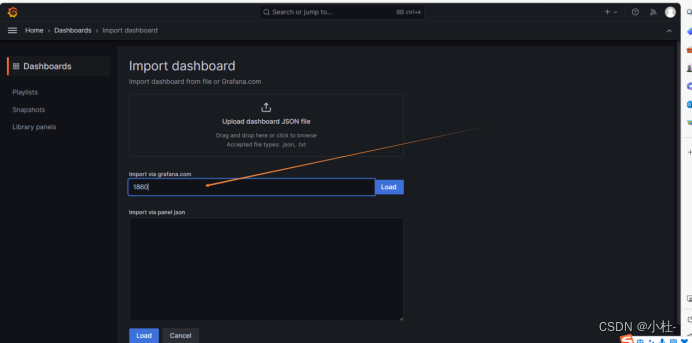
7.3选择相应的模板ID
(外网可以选择模板ID,1860)(内网选择自定义以下步骤)
8.grafana自定义dashboard案例
8.1创建dashboard
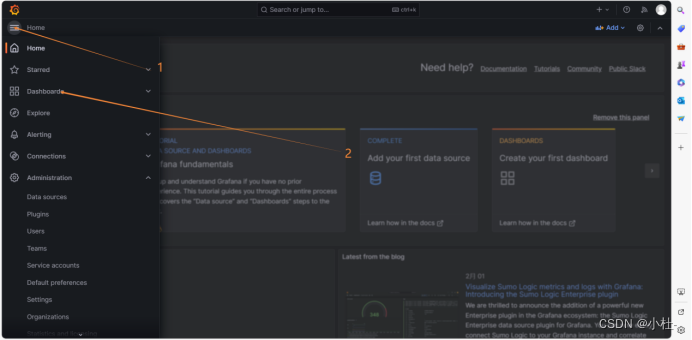
8.1.1新建dashboard
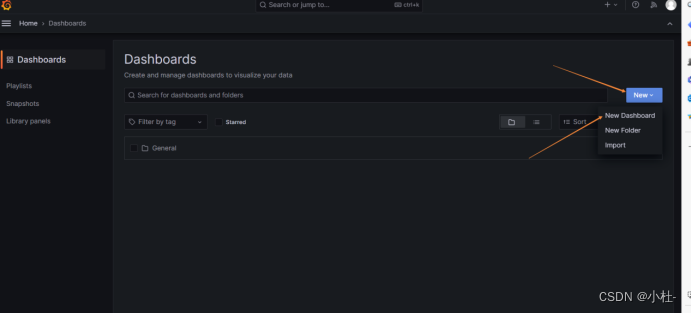
8.1.2选择要创建的资源
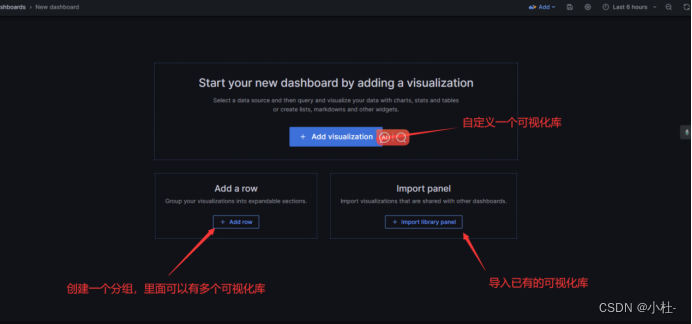
8.1.3创建可视化库


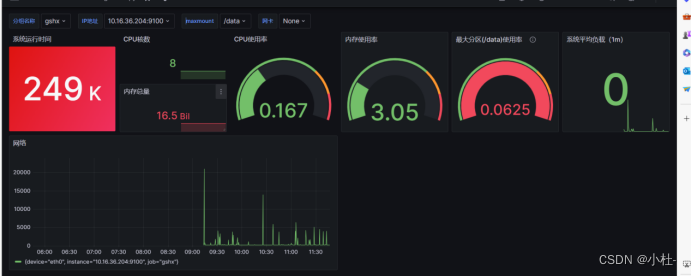
8.1.4效果图
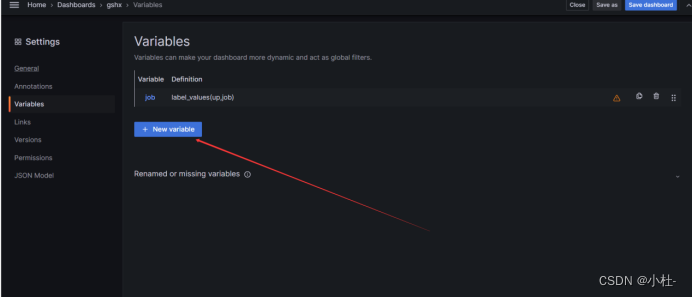
8.2grafana的变量设置
8.2.1 进入设置页面
 8.2.2进入变量的配置页面
8.2.2进入变量的配置页面

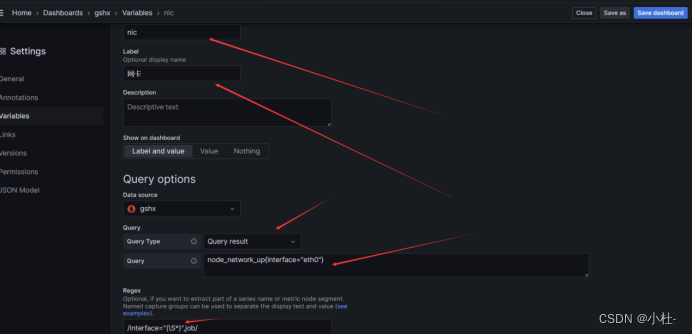
8.2.3引用instance标签的值
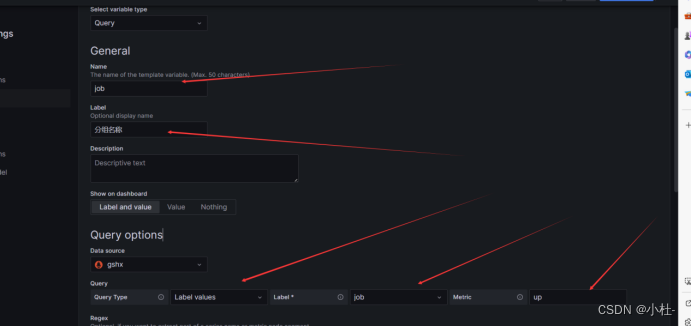
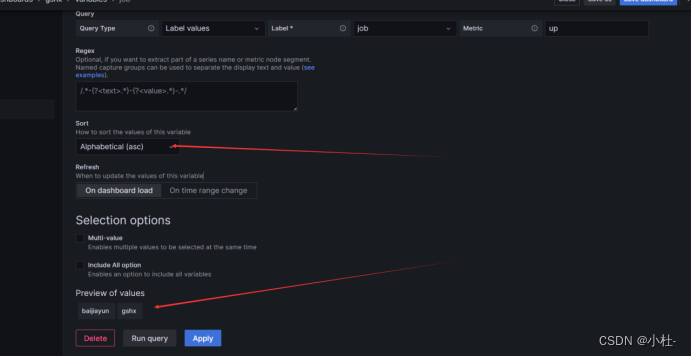 8.2.4引用instance标签的值
8.2.4引用instance标签的值
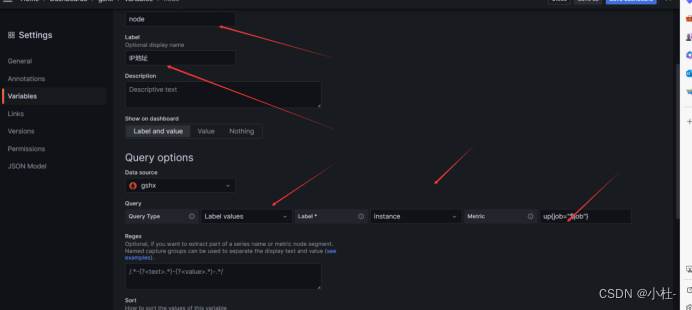
up{job="$job"}
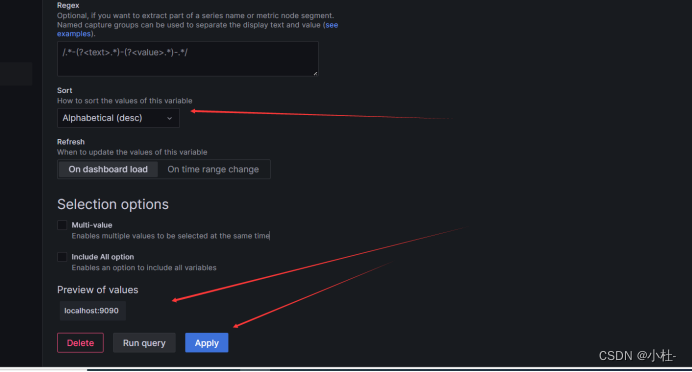
8.2.5引用instance标签的值
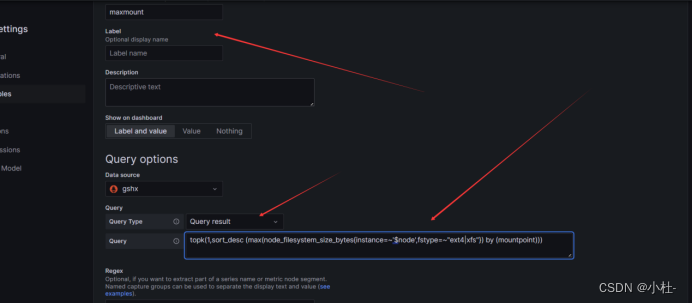
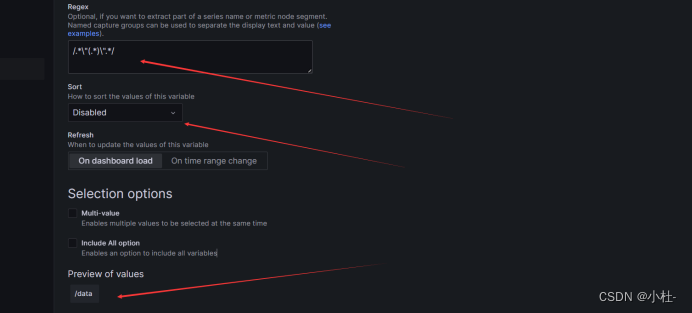
maxmount
topk(1,sort_desc (max(node_filesystem_size_bytes{instance=~'$node',fstype=~"ext4|xfs"}) by (mountpoint)))
/.*\"(.*)\".*/8.2.6引用instance标签的值
8.3Prom QL语句
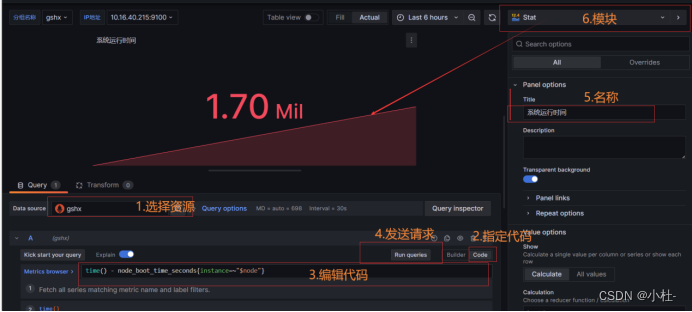
9.Prom QL语句
9.1CPU核数
count(count(node_cpu_seconds_total{instance=~"$node", mode='system'}) by (cpu))9.2CPU使用率
100 - (avg(irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[1m])) * 100)9.3内存总量
node_memory_MemTotal_bytes{instance=~"$node"}9.4内存使用率
((node_memory_MemTotal_bytes{instance=~"$node"} - node_memory_MemFree_bytes{instance=~"$node"} - node_memory_Buffers_bytes{instance=~"$node"} - node_memory_Cached_bytes{instance=~"$node"}) / (node_memory_MemTotal_bytes{instance=~"$node"} )) * 1009.5网络
irate(node_network_transmit_bytes_total{instance=~"$node"}[1m])9.6系统运行时间
time() - node_boot_time_seconds{instance=~"$node"}9.7最大分区/data使用率
100 - ((node_filesystem_avail_bytes{instance=~"$node",mountpoint="$maxmount",fstype=~"ext4|xfs"} * 100) / node_filesystem_size_bytes {instance=~"$node",mountpoint="$maxmount",fstype=~"ext4|xfs"})9.8系统负载(1m)
node_load1{instance="$node"}9.9过去5分钟内的网络上行速率,即每秒发送的字节数
sum(irate(node_network_receive_bytes_total{job=~"$job", instance=~'$node'}[5m])) by (instance)10.0 过去5分钟内每个实例的下行速率
sum(irate(node_network_receive_bytes_total{job=~"$job", instance=~'$node'}[5m])) by (instance)10.1磁盘IO读写时间
irate(node_disk_io_time_seconds_total{instance=~"$node"}[1m])10.2磁盘每秒的I/O操作耗费时间(%)
irate(node_disk_io_time_seconds_total{instance=~"$node"}[1m])10.3TCP 连接情况
node_netstat_Tcp_CurrEstab{instance=~'$node'}10.4磁盘读写速率(IOPS)
irate(node_disk_reads_completed_total{instance=~"$node"}[1m])10.5磁盘读写容量大小
irate(node_disk_read_bytes_total{instance=~"$node"}[1m])10.6 上行速率大于0,表示没有延迟
irate(node_network_receive_bytes_total{job=~"$job", instance=~'$node'}[5m]) > 010.大概效果图 根据自己审美来
10.16.40.215

10.16.36.204