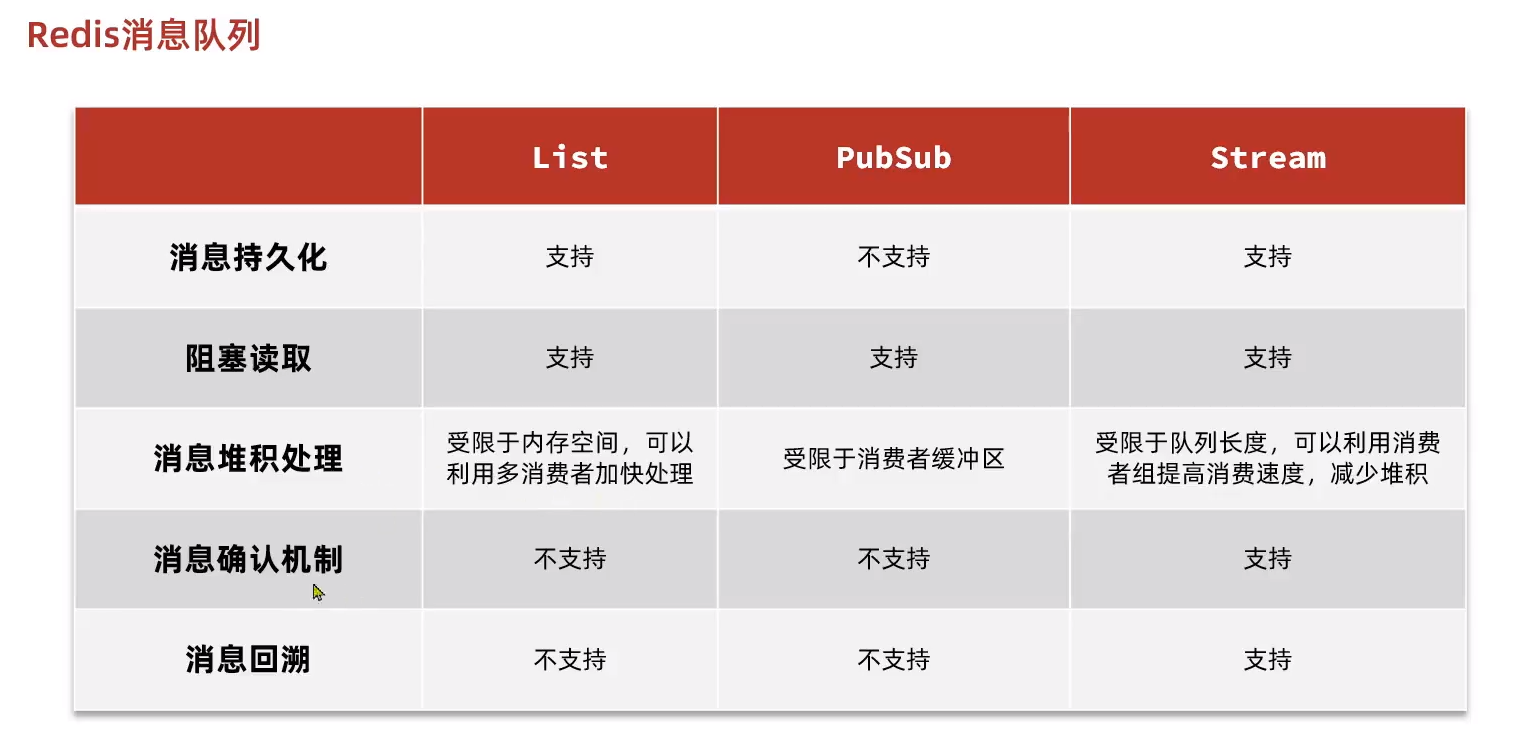
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:

- ModelZoo(模型库):ModelZoo提供可用的深度学习算法网络,也欢迎更多开发者贡献新的网络(ModelZoo地址)。
- MindSpore Extend(扩展库):昇思MindSpore的领域扩展库,支持拓展新领域场景,如GNN/深度概率编程/强化学习等,期待更多开发者来一起贡献和构建。
- MindSpore Science(科学计算):MindScience是基于昇思MindSpore融合架构打造的科学计算行业套件,包含了业界领先的数据集、基础模型、预置高精度模型和前后处理工具,加速了科学行业应用开发。
- MindExpression(全场景统一API):基于Python的前端表达与编程接口,支持两个融合(函数/OOP编程范式融合、AI+数值计算表达融合)以及两个统一(动静表达统一、单机分布式表达统一)。
- 第三方前端:支持第三方多语言前端表达,未来计划陆续提供C/C++等第三方前端的对接工作,引入更多的第三方生态。
- MindSpore Data(数据处理层):提供高效的数据处理、常用数据集加载等功能和编程接口,支持用户灵活地定义处理注册和pipeline并行优化。
- MindCompiler(AI编译器):图层的核心编译器,主要基于端云统一的MindIR实现三大功能,包括硬件无关的优化(类型推导、自动微分、表达式化简等)、硬件相关优化(自动并行、内存优化、图算融合、流水线执行等)、部署推理相关的优化(量化、剪枝等)。
- MindRT(全场景运行时):昇思MindSpore的运行时系统,包含云侧主机侧运行时系统、端侧以及更小IoT的轻量化运行时系统。
- MindSpore Insight(可视化调试调优工具):昇思MindSpore的可视化调试调优工具,能够可视化地查看训练过程、优化模型性能、调试精度问题、解释推理结果(了解更多)。
- MindSpore Armour(安全增强库):面向企业级运用时,安全与隐私保护相关增强功能,如对抗鲁棒性、模型安全测试、差分隐私训练、隐私泄露风险评估、数据漂移检测等技术(了解更多)。
执行流程
有了对昇思MindSpore总体架构的了解后,我们可以看看各个模块之间的整体配合关系,具体如图所示:

昇思MindSpore作为全场景AI框架,所支持的有端(手机与IOT设备)、边(基站与路由设备)、云(服务器)场景的不同系列硬件,包括昇腾系列产品、英伟达NVIDIA系列产品、Arm系列的高通骁龙、华为麒麟的芯片等系列产品。
左边蓝色方框的是MindSpore主体框架,主要提供神经网络在训练、验证过程中相关的基础API功能,另外还会默认提供自动微分、自动并行等功能。
蓝色方框往下是MindSpore Data模块,可以利用该模块进行数据预处理,包括数据采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调优的问题,因此有MindSpore Insight模块对loss曲线、算子执行情况、权重参数变量等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。
AI安全最简单的场景就是从攻防的视角来看,例如,攻击者在训练阶段掺入恶意数据,影响AI模型推理能力,于是MindSpore推出了MindSpore Armour模块,为MindSpore提供AI安全机制。
蓝色方框往上的内容跟算法开发相关的用户更加贴近,包括存放大量的AI算法模型库ModelZoo,提供面向不同领域的开发工具套件MindSpore DevKit,另外还有高阶拓展库MindSpore Extend,这里面值得一提的就是MindSpore Extend中的科学计算套件MindSciences,MindSpore首次探索将科学计算与深度学习结合,将数值计算与深度学习相结合,通过深度学习来支持电磁仿真、药物分子仿真等等。
神经网络模型训练完后,可以导出模型或者加载存放在MindSpore Hub中已经训练好的模型。接着有MindIR提供端云统一的IR格式,通过统一IR定义了网络的逻辑结构和算子的属性,将MindIR格式的模型文件 与硬件平台解耦,实现一次训练多次部署。因此如图所示,通过IR把模型导出到不同的模块执行推理。
设计理念
-
支持全场景统一部署
昇思MindSpore源于全产业的最佳实践,向数据科学家和算法工程师提供了统一的模型训练、推理和导出等接口,支持端、边、云等不同场景下的灵活部署,推动深度学习和科学计算等领域繁荣发展。
-
提供Python编程范式,简化AI编程
昇思MindSpore提供了Python编程范式,用户使用Python原生控制逻辑即可构建复杂的神经网络模型,AI编程变得简单。
-
提供动态图和静态图统一的编码方式
目前主流的深度学习框架的执行模式有两种,分别为静态图模式和动态图模式。静态图模式拥有较高的训练性能,但难以调试。动态图模式相较于静态图模式虽然易于调试,但难以高效执行。 昇思MindSpore提供了动态图和静态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换动态图/静态图模式,用户可拥有更轻松的开发调试及性能体验。例如:
设置
set_context(mode=PYNATIVE_MODE)可切换成动态图模式。设置
set_context(mode=GRAPH_MODE)可切换成静态图模式。 -
采用AI和科学计算融合编程,使用户聚焦于模型算法的数学原生表达
在友好支持AI模型训练推理编程的基础上,扩展支持灵活自动微分编程能力,支持对函数、控制流表达情况下的微分求导和各种如正向微分、高阶微分等高级微分能力的支持,用户可基于此实现科学计算常用的微分函数编程表达,从而支持AI和科学计算融合编程开发。
-
分布式训练原生
随着神经网络模型和数据集的规模不断增大,分布式并行训练成为了神经网络训练的常见做法,但分布式并行训练的策略选择和编写十分复杂,这严重制约着深度学习模型的训练效率,阻碍深度学习的发展。MindSpore统一了单机和分布式训练的编码方式,开发者无需编写复杂的分布式策略,在单机代码中添加少量代码即可实现分布式训练,提高神经网络训练效率,大大降低了AI开发门槛,使用户能够快速实现想要的模型。
例如设置
set_auto_parallel_context(parallel_mode=ParallelMode.AUTO_PARALLEL)便可自动建立代价模型,为用户选择一种较优的并行模式。
层次结构
昇思MindSpore向用户提供了3个不同层次的API,支撑用户进行AI应用(算法/模型)开发,从高到低分别为High-Level Python API、Medium-Level Python API以及Low-Level Python API。高阶API提供了更好的封装性,低阶API提供更好的灵活性,中阶API兼顾灵活及封装,满足不同领域和层次的开发者需求。

-
High-Level Python API
第一层为高阶API,其在中阶API的基础上又提供了训练推理的管理、混合精度训练、调试调优等高级接口,方便用户控制整网的执行流程和实现神经网络的训练推理及调优。例如用户使用Model接口,指定要训练的神经网络模型和相关的训练设置,对神经网络模型进行训练。
-
Medium-Level Python API
第二层为中阶API,其封装了低阶API,提供网络层、优化器、损失函数等模块,用户可通过中阶API灵活构建神经网络和控制执行流程,快速实现模型算法逻辑。例如用户可调用Cell接口构建神经网络模型和计算逻辑,通过使用Loss模块和Optimizer接口为神经网络模型添加损失函数和优化方式,利用Dataset模块对数据进行处理以供模型的训练和推导使用。
-
Low-Level Python API
第三层为低阶API,主要包括张量定义、基础算子、自动微分等模块,用户可使用低阶API轻松实现张量定义和求导计算。例如用户可通过Tensor接口自定义张量,使用grad接口计算函数在指定处的导数。
华为昇腾AI全栈介绍
昇腾计算,是基于昇腾系列处理器构建的全栈AI计算基础设施及应用,包括昇腾Ascend系列芯片、Atlas系列硬件、CANN芯片使能、MindSpore AI框架、ModelArts、MindX应用使能等。
华为Atlas人工智能计算解决方案,是基于昇腾系列AI处理器,通过模块、板卡、小站、服务器、集群等丰富的产品形态,打造面向“端、边、云”的全场景AI基础设施方案,涵盖数据中心解决方案、智能边缘解决方案,覆盖深度学习领域推理和训练全流程。
昇腾AI全栈如下图所示:
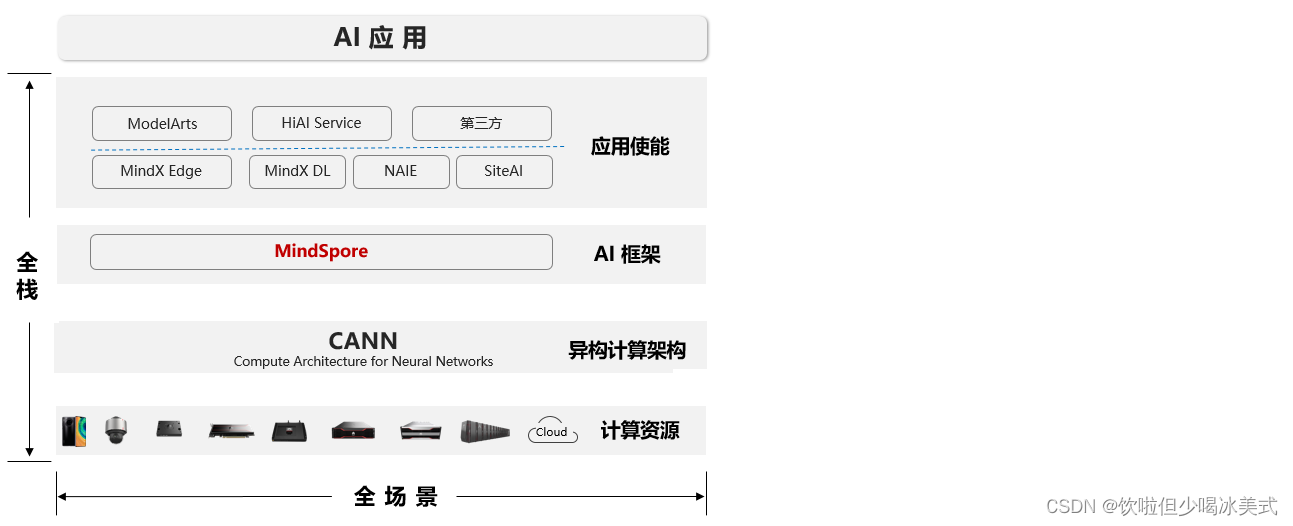
下面简单介绍每个模块的作用:
- 昇腾应用使能:华为各大产品线基于MindSpore提供的AI平台或服务能力
- MindSpore:支持端、边、云独立的和协同的统一训练和推理框架
- CANN:昇腾芯片使能、驱动层(了解更多)。
- 计算资源:昇腾系列化IP、芯片和服务器
详细信息请点击华为昇腾官网。
昇思代码如下:
mindspore: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
自动微分
当前主流深度学习框架中有两种自动微分技术:
- 操作符重载法: 通过操作符重载对编程语言中的基本操作语义进行重定义,封装其微分规则。 在程序运行时记录算子过载正向执行时网络的运行轨迹,对动态生成的数据流图应用链式法则,实现自动微分。
- 代码变换法: 该技术是从功能编程框架演进而来,以即时编译(Just-in-time Compilation,JIT)的形式对中间表达式(程序在编译过程中的表达式)进行自动差分转换,支持复杂的控制流场景、高阶函数和闭包。
PyTorch采用的是操作符重载法。相较于代码变换法,操作符重载法是在运行时生成微分计算图的, 无需考虑函数调用与控制流等情况, 开发更为简单。 但该方法不能在编译时刻做微分图的优化, 控制流也需要根据运行时的信息来展开, 很难实现性能的极限优化。
MindSpore则采用的是代码变换法。一方面,它支持自动控制流的自动微分,因此像PyTorch这样的模型构建非常方便。另一方面,MindSpore可以对神经网络进行静态编译优化,以获得更好的性能。

MindSpore自动微分的实现可以理解为程序本身的符号微分。MindSpore IR是一个函数中间表达式,它与基础代数中的复合函数具有直观的对应关系。复合函数的公式由任意可推导的基础函数组成。MindSpore IR中的每个原语操作都可以对应基础代数中的基本功能,从而可以建立更复杂的流控制。
自动并行
MindSpore自动并行的目的是构建数据并行、模型并行和混合并行相结合的训练方法。该方法能够自动选择开销最小的模型切分策略,实现自动分布并行训练。

目前MindSpore采用的是算子切分的细粒度并行策略,即图中的每个算子被切分为一个集群,完成并行操作。在此期间的切分策略可能非常复杂,但是作为一名Python开发者,您无需关注底层实现,只要顶层API计算是有效的即可。
安装
pip方式安装
MindSpore提供跨多个后端的构建选项:

使用pip命令安装,以CPU和Ubuntu-x86build版本为例:
-
请从MindSpore下载页面下载并安装whl包。
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.2.0-rc1/MindSpore/cpu/ubuntu_x86/mindspore-1.2.0rc1-cp37-cp37m-linux_x86_64.whl2、执行以下命令,验证安装结果。
import numpy as np
import mindspore.context as context
import mindspore.nn as nn
from mindspore import Tensor
from mindspore.ops import operations as P
context.set_context(mode=context.GRAPH_MODE, device_target="CPU")
class Mul(nn.Cell):
def __init__(self):
super(Mul, self).__init__()
self.mul = P.Mul()
def construct(self, x, y):
return self.mul(x, y)
x = Tensor(np.array([1.0, 2.0, 3.0]).astype(np.float32))
y = Tensor(np.array([4.0, 5.0, 6.0]).astype(np.float32))
mul = Mul()
print(mul(x, y))[ 4. 10. 18.]
使用pip方式,在不同的环境安装MindSpore,可参考以下文档。
- Ascend环境使用pip方式安装MindSpore
- GPU环境使用pip方式安装MindSpore
- CPU环境使用pip方式安装MindSpore
源码编译方式安装
使用源码编译方式,在不同的环境安装MindSpore,可参考以下文档。
- Ascend环境使用源码编译方式安装MindSpore
- GPU环境使用源码编译方式安装MindSpore
- CPU环境使用源码编译方式安装MindSpore
Docker镜像
MindSpore的Docker镜像托管在Docker Hub上。 目前容器化构建选项支持情况如下:
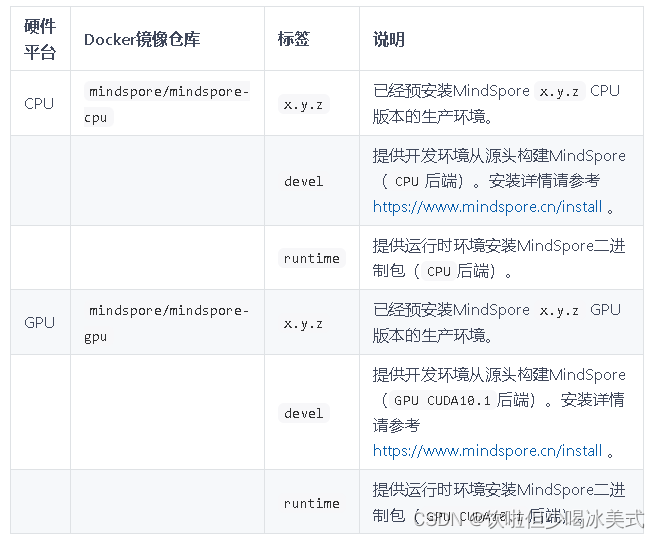
注意: 不建议从源头构建GPU devel Docker镜像后直接安装whl包。我们强烈建议您在GPU runtime Docker镜像中传输并安装whl包。
CPU
对于CPU后端,可以直接使用以下命令获取并运行最新的稳定镜像:
docker pull mindspore/mindspore-cpu:1.1.0 docker run -it mindspore/mindspore-cpu:1.1.0 /bin/bash
GPU
对于GPU后端,请确保nvidia-container-toolkit已经提前安装,以下是Ubuntu用户安装指南:
DISTRIBUTION=$(. /etc/os-release; echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$DISTRIBUTION/nvidia-docker.list | tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit nvidia-docker2 sudo systemctl restart docker
编辑文件 daemon.json:
$ vim /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
再次重启docker:
sudo systemctl daemon-reload
sudo systemctl restart docker使用以下命令获取并运行最新的稳定镜像:
docker pull mindspore/mindspore-gpu:1.1.0
docker run -it -v /dev/shm:/dev/shm --runtime=nvidia --privileged=true mindspore/mindspore-gpu:1.1.0 /bin/bash要测试Docker是否正常工作,请运行下面的Python代码并检查输出:
import numpy as np
import mindspore.context as context
from mindspore import Tensor
from mindspore.ops import functional as F
context.set_context(mode=context.PYNATIVE_MODE, device_target="GPU")
x = Tensor(np.ones([1,3,3,4]).astype(np.float32))
y = Tensor(np.ones([1,3,3,4]).astype(np.float32))
print(F.tensor_add(x, y))[[[ 2. 2. 2. 2.], [ 2. 2. 2. 2.], [ 2. 2. 2. 2.]], [[ 2. 2. 2. 2.], [ 2. 2. 2. 2.], [ 2. 2. 2. 2.]], [[ 2. 2. 2. 2.], [ 2. 2. 2. 2.], [ 2. 2. 2. 2.]]]
如果您想了解更多关于MindSpore Docker镜像的构建过程,请查看docker repo了解详细信息。





![[分布式网络通讯框架]----RPC通信原理以及protobuf的基本使用](https://img-blog.csdnimg.cn/direct/b8c3b99b3e674a86abda9d5dcdb4fca0.png)