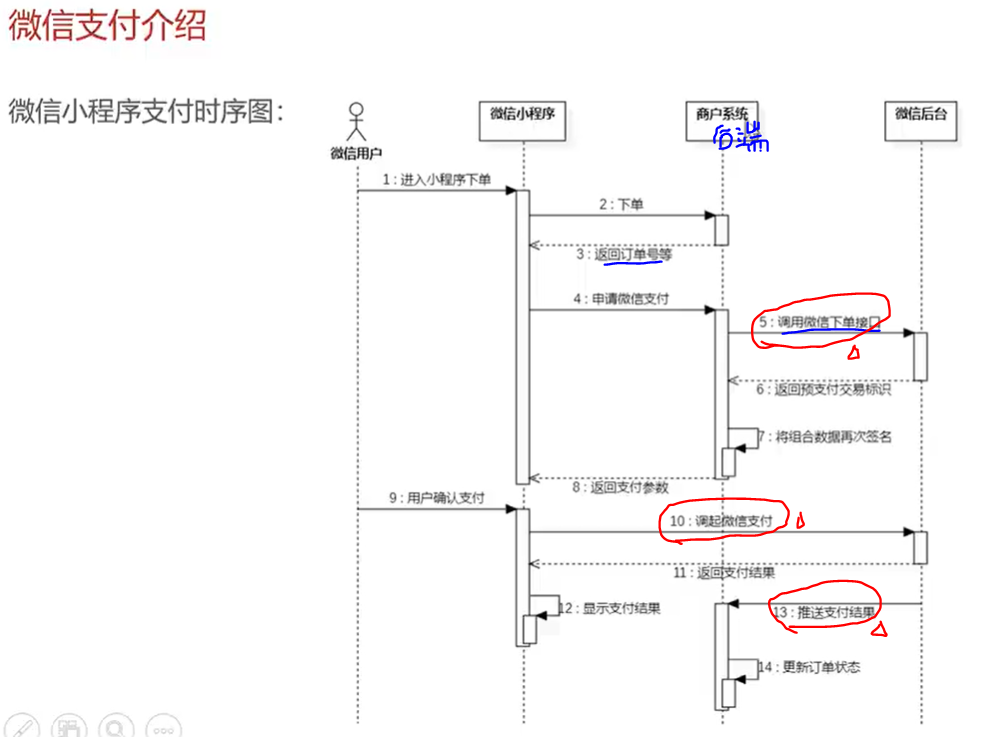
图神经网络实战(15)——SEAL链接预测算法
- 0. 前言
- 1. SEAL 框架
- 1.1 基本原理
- 1.2 算法流程
- 2. 实现 SEAL 框架
- 2.1 数据预处理
- 2.2 模型构建与训练
- 小结
- 系列链接
0. 前言
我们已经学习了基于节点嵌入的链接预测算法,这种方法通过学习相关的节点嵌入来计算链接可能性。接下来,我们介绍另一类方法,通过查看目标节点周围的局部邻域执行链接预测任务,这类技术称为基于子图的算法,由 SEAL 广泛使用,可以说 SEAL 表示用于链接预测的子图、嵌入和属性 (Subgraphs, Embeddings, and Attributes for Link prediction) 的缩写,但并不完全准确。在本节中,我们将介绍 SEAL 框架,并使用 PyTorch Geometric 实现该框架。
1. SEAL 框架
1.1 基本原理
SEAL 由 Zhang 和 Chen 于 2018 年提出,是一个学习图结构特征以进行链接预测的框架。它将目标节点
(
x
,
y
)
(x,y)
(x,y) 和它们的 k 跳 (k-hop) 邻居所形成的子图定义为封闭子图 (enclosing subgraph)。每个封闭子图(而非整个图)都被用作预测链接可能性的输入。从另一个角度来看,SEAL 自动学习了一种用于链接预测的局部启发式方法。
1.2 算法流程
SEAL 框架包括三个步骤:
- 封闭子图提取 (
Enclosing subgraph extraction),包括提取一组真实链接和一组虚假链接(负抽样)来形成训练数据 - 节点信息矩阵构建 (
Node information matrix construction),包括节点标记、节点嵌入和节点特征三个部分 - 图神经网络 (Graph Neural Networks, GNN) 训练 (
GNN training),将节点信息矩阵作为输入,并输出链接的可能性
这些步骤可以用下图进行总结:

封闭子图提取是一个简单的过程,列出目标节点及其 k 跳邻居,以提取它们的边和特征。k 值越大,SEAL 所能学习到的启发式算法的质量就越高,但同时也会创建更大、计算开销更大的子图。
节点信息构建的第一个部分是节点标记 (node labeling)。这一过程为每个节点分配一个特定的编号,如果没有进行标记,GNN 就无法区分目标节点和上下文节点(目标节点的邻居)。它还融合了距离,用来描述节点的相对位置和结构重要性。
在实践中,目标节点
x
x
x 和
y
y
y 必须共享一个唯一的标签,以确定它们是目标节点。对于上下文节点
i
i
i 和
j
j
j,如果它们与目标节点的距离相同,则必须共享相同的标签——
d
(
i
,
x
)
=
d
(
j
,
x
)
d(i, x) = d(j, x)
d(i,x)=d(j,x) 和
d
(
i
,
y
)
=
d
(
j
,
y
)
d(i, y) = d(j, y)
d(i,y)=d(j,y)。我们称这种距离为双半径 (double radius),表示为
(
d
(
i
,
x
)
,
d
(
i
,
y
)
)
(d(i, x), d(i, y))
(d(i,x),d(i,y))。
SEAL 中使用双半径节点标记 (Double-Radius Node Labeling, DRNL) 算法,其工作原理如下:
- 首先,将标签
1分配给节点 x x x 和 y y y - 将标签
2分配给半径为(1,1)的节点 - 将标签
3分配给半径为(1,2)或(2,1)的节点 - 将标签
4分配给半径为(1,3)或(3,1)的节点,以此类推
DRNL 函数的数学表达式如下:
f
(
i
)
=
1
+
m
i
n
(
d
(
i
,
x
)
,
d
(
i
,
y
)
)
+
(
d
/
2
)
[
(
d
/
2
)
+
(
d
%
2
)
−
1
]
f(i)=1+min(d(i,x),d(i,y))+(d/2)[(d/2)+(d\%2)-1]
f(i)=1+min(d(i,x),d(i,y))+(d/2)[(d/2)+(d%2)−1]
其中,
d
=
d
(
i
,
x
)
+
d
(
i
,
y
)
d= d(i, x) + d(i, y)
d=d(i,x)+d(i,y),
(
d
/
2
)
(d/2)
(d/2) 和
(
d
%
2
)
(d\%2)
(d%2) 分别是
d
d
d 除以
2
2
2 的整数商和余数。最后,对这些节点标签进行独热编码 (one-hot encode)。
节点信息矩阵构建过程中的其它两个部分比较容易获得。节点嵌入是可选的,可以使用其他算法(如 Node2Vec )计算。然后,将它们与节点特征和独热编码标签连接起来,构建最终的节点信息矩阵 (node information matrix)。
最后,训练 GNN,利用封闭子图的信息和邻接矩阵来预测链接。为此,SEAL 使用了深度图卷积神经网络 (Deep Graph Convolutional Neural Network, DGCNN),该架构执行以下三个步骤:
- 使用数个图卷积网络 (Graph Convolutional Network, GCN) 层计算节点嵌入,然后将其串联起来,类似于图同构网络 (Graph Isomorphism Network, GIN)
- 使用全局排序池化层按照一致的顺序排列这些嵌入,然后再将它们深入到卷积层,而卷积层不具备置换不变性
- 使用传统的卷积层和全连接层应用于排序后图表示,并输出链接概率
DGCNN 模型使用二进制交叉熵损失进行训练,输出的概率介于 0 和 1 之间
2. 实现 SEAL 框架
SEAL 框架需要进行大量的预处理,以提取并标注封闭子图。接下来,我们使用 PyTorch Geometric 来实现 SEAL 框架。
2.1 数据预处理
(1) 首先,导入所有必要的库:
import numpy as np
from sklearn.metrics import roc_auc_score, average_precision_score
from scipy.sparse.csgraph import shortest_path
import torch.nn.functional as F
from torch.nn import Conv1d, MaxPool1d, Linear, Dropout, BCEWithLogitsLoss
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import RandomLinkSplit
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
from torch_geometric.nn import GCNConv, aggr
from torch_geometric.utils import k_hop_subgraph, to_scipy_sparse_matrix
(2) 加载 Cora 数据集,并应用链接级随机拆分:
transform = RandomLinkSplit(num_val=0.05, num_test=0.1, is_undirected=True, split_labels=True)
dataset = Planetoid('.', name='Cora', transform=transform)
train_data, val_data, test_data = dataset[0]
(3) 链接级随机拆分会在数据对象中创建新字段,用于存储每条正样本边(真实的边)和负样本边(虚假的边)的标签和索引:
print(train_data)
# Data(x=[2708, 1433], edge_index=[2, 8976], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708], pos_edge_label=[4488], pos_edge_label_index=[2, 4488], neg_edge_label=[4488], neg_edge_label_index=[2, 4488])
(4) 创建函数 seal_processing() 处理拆分后的数据集,并获得带有独热编码节点标签和节点特征的封闭子图,使用列表 data_list 存储这些子图:
def seal_processing(dataset, edge_label_index, y):
data_list = []
对于数据集中的每一对节点(源和目的节点),提取 k 跳邻居(本节中 k = 2):
for src, dst in edge_label_index.t().tolist():
sub_nodes, sub_edge_index, mapping, _ = k_hop_subgraph([src, dst], 2, dataset.edge_index, relabel_nodes=True)
src, dst = mapping.tolist()
使用双半径节点标记 (Double-Radius Node Labeling, DRNL) 函数计算距离。首先,从子图中删除目标节点:
mask1 = (sub_edge_index[0] != src) | (sub_edge_index[1] != dst)
mask2 = (sub_edge_index[0] != dst) | (sub_edge_index[1] != src)
sub_edge_index = sub_edge_index[:, mask1 & mask2]
根据上一个子图计算源节点和目标节点的邻接矩阵:
src, dst = (dst, src) if src > dst else (src, dst)
adj = to_scipy_sparse_matrix(sub_edge_index, num_nodes=sub_nodes.size(0)).tocsr()
idx = list(range(src)) + list(range(src + 1, adj.shape[0]))
adj_wo_src = adj[idx, :][:, idx]
idx = list(range(dst)) + list(range(dst + 1, adj.shape[0]))
adj_wo_dst = adj[idx, :][:, idx]
计算每个节点与源节点/目标节点之间的距离:
# Calculate the distance between every node and the source target node
d_src = shortest_path(adj_wo_dst, directed=False, unweighted=True, indices=src)
d_src = np.insert(d_src, dst, 0, axis=0)
d_src = torch.from_numpy(d_src)
# Calculate the distance between every node and the destination target node
d_dst = shortest_path(adj_wo_src, directed=False, unweighted=True, indices=dst-1)
d_dst = np.insert(d_dst, src, 0, axis=0)
d_dst = torch.from_numpy(d_dst)
计算子图中每个节点的节点标签 z z z:
dist = d_src + d_dst
z = 1 + torch.min(d_src, d_dst) + dist // 2 * (dist // 2 + dist % 2 - 1)
z[src], z[dst], z[torch.isnan(z)] = 1., 1., 0.
z = z.to(torch.long)
在本节中,并未使用节点嵌入,但仍将特征和独热编码标签串联起来,以构建节点信息矩阵:
node_labels = F.one_hot(z, num_classes=200).to(torch.float)
node_emb = dataset.x[sub_nodes]
node_x = torch.cat([node_emb, node_labels], dim=1)
创建一个 Data 对象并将其附加到列表 data_list 中,作为函数的最终输出:
data = Data(x=node_x, z=z, edge_index=sub_edge_index, y=y)
data_list.append(data)
return data_list
(5) 调用 deal_processing 提取每个数据集的封闭子图。将正样本和负样本分开,以获得正确的预测标签:
train_pos_data_list = seal_processing(train_data, train_data.pos_edge_label_index, 1)
train_neg_data_list = seal_processing(train_data, train_data.neg_edge_label_index, 0)
val_pos_data_list = seal_processing(val_data, val_data.pos_edge_label_index, 1)
val_neg_data_list = seal_processing(val_data, val_data.neg_edge_label_index, 0)
test_pos_data_list = seal_processing(test_data, test_data.pos_edge_label_index, 1)
test_neg_data_list = seal_processing(test_data, test_data.neg_edge_label_index, 0)
(6) 合并正负数据列表,重建训练、验证和测试数据集:
train_dataset = train_pos_data_list + train_neg_data_list
val_dataset = val_pos_data_list + val_neg_data_list
test_dataset = test_pos_data_list + test_neg_data_list
(7) 创建数据加载器,使用批数据训练 GNN:
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
test_loader = DataLoader(test_dataset, batch_size=32)
2.2 模型构建与训练
(1) 定义 DGCNN 类,其中参数 k 表示每个子图的节点数:
class DGCNN(torch.nn.Module):
def __init__(self, dim_in, k=30):
super().__init__()
创建四个 GCN 层,设定隐藏维度为 32:
self.gcn1 = GCNConv(dim_in, 32)
self.gcn2 = GCNConv(32, 32)
self.gcn3 = GCNConv(32, 32)
self.gcn4 = GCNConv(32, 1)
实例化全局排序池化层 (深度图卷积神经网络 (Deep Graph Convolutional Neural Network, DGCNN) 架构的核心):
self.global_pool = aggr.SortAggregation(k=k)
全局排序池化层提供的节点排序使我们能够使用传统的卷积层:
self.conv1 = Conv1d(1, 16, 97, 97)
self.conv2 = Conv1d(16, 32, 5, 1)
self.maxpool = MaxPool1d(2, 2)
最后,实例化多层感知机 (Multilayer Perceptron, MLP) 用于获取预测:
self.linear1 = Linear(352, 128)
self.dropout = Dropout(0.5)
self.linear2 = Linear(128, 1)
在 forward() 方法中,计算每个 GCN 的节点嵌入,并将结果串联起来:
def forward(self, x, edge_index, batch):
# 1. Graph Convolutional Layers
h1 = self.gcn1(x, edge_index).tanh()
h2 = self.gcn2(h1, edge_index).tanh()
h3 = self.gcn3(h2, edge_index).tanh()
h4 = self.gcn4(h3, edge_index).tanh()
h = torch.cat([h1, h2, h3, h4], dim=-1)
对串联结果依次应用全局排序池化、卷积层和全连接层:
# 2. Global sort pooling
h = self.global_pool(h, batch)
# 3. Traditional convolutional and dense layers
h = h.view(h.size(0), 1, h.size(-1))
h = self.conv1(h).relu()
h = self.maxpool(h)
h = self.conv2(h).relu()
h = h.view(h.size(0), -1)
h = self.linear1(h).relu()
h = self.dropout(h)
h = self.linear2(h).sigmoid()
return h
(2) 将模型实例化,并使用 Adam 优化器和二进制交叉熵损失对其进行训练:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = DGCNN(train_dataset[0].num_features).to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.0001)
criterion = BCEWithLogitsLoss()
(3) 创建 train() 函数用于批训练:
def train():
model.train()
total_loss = 0
for data in train_loader:
data = data.to(device)
optimizer.zero_grad()
out = model(data.x, data.edge_index, data.batch)
loss = criterion(out.view(-1), data.y.to(torch.float))
loss.backward()
optimizer.step()
total_loss += float(loss) * data.num_graphs
return total_loss / len(train_dataset)
(4) 在 test() 函数中,计算 ROC AUC 分数和平均精度,以比较 SEAL 和变分图自编码器 (Variational Graph Autoencoder, VGAE) 的性能:
@torch.no_grad()
def test(loader):
model.eval()
y_pred, y_true = [], []
for data in loader:
data = data.to(device)
out = model(data.x, data.edge_index, data.batch)
y_pred.append(out.view(-1).cpu())
y_true.append(data.y.view(-1).cpu().to(torch.float))
auc = roc_auc_score(torch.cat(y_true), torch.cat(y_pred))
ap = average_precision_score(torch.cat(y_true), torch.cat(y_pred))
return auc, ap
(5) 对 DGCNN 进行 31 个 epoch 的训练:
for epoch in range(31):
loss = train()
val_auc, val_ap = test(val_loader)
print(f'Epoch {epoch:>2} | Loss: {loss:.4f} | Val AUC: {val_auc:.4f} | Val AP: {val_ap:.4f}')

(6) 最后,在测试数据集上对其进行测试:
test_auc, test_ap = test(test_loader)
print(f'Test AUC: {test_auc:.4f} | Test AP {test_ap:.4f}')
# Test AUC: 0.7899 | Test AP 0.8174
可以看到,使用 SEAL 框架得到的结果与使用 VGAE 得到的结果(AUC 为 0.8727,AP 为 0.8620) 相似。从理论上讲,基于子图的方法(如 SEAL )比基于节点的方法(如 VGAE )更具表达能力,基于子图的方法通过明确考虑目标节点周围的整个邻域来捕捉更多信息。通过 k 参数增加所考虑的邻域数量,可以进一步提高 SEAL 的准确性。
小结
链接预测是指利用图数据中已知的节点和边的信息,来推断图中未知的连接关系或者未来可能出现的连接关系,在机器学习和数据挖掘等领域具有广泛的应用。本节中介绍了用于链接预测的 SEAL 框架,其侧重于子图表示,每个链接周围的邻域作为预测链接概率的输入。并使用边级随机分割和负采样在 Cora 数据集上实现了 SEAL 模型执行链接预测任务。
系列链接
图神经网络实战(1)——图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战(2)——图论基础
图神经网络实战(3)——基于DeepWalk创建节点表示
图神经网络实战(4)——基于Node2Vec改进嵌入质量
图神经网络实战(5)——常用图数据集
图神经网络实战(6)——使用PyTorch构建图神经网络
图神经网络实战(7)——图卷积网络(Graph Convolutional Network, GCN)详解与实现
图神经网络实战(8)——图注意力网络(Graph Attention Networks, GAT)
图神经网络实战(9)——GraphSAGE详解与实现
图神经网络实战(10)——归纳学习
图神经网络实战(11)——Weisfeiler-Leman测试
图神经网络实战(12)——图同构网络(Graph Isomorphism Network, GIN)
图神经网络实战(13)——经典链接预测算法
图神经网络实战(14)——基于节点嵌入预测链接



![[C++][设计模式][抽象工厂]详细讲解](https://img-blog.csdnimg.cn/direct/2a30ef7b5c264a949fa95ff925719992.png)