系列文章目录
一、Hive基础架构(重点)
二、Hive数据库,表操作(重点)
三、Hadoop架构详解(hdfs)(补充)
四、Hive环境准备(操作)(补充)
文章目录
- 系列文章目录
- 前言
- 一、Hive基础架构
- 1、Hive和MapReduce的关系
- 2、Hive架构(熟悉)
- 3、MetaStore元数据管理服务
- 4、数据仓库和数据库(熟悉)
- 4.1 数据仓库和数据库的区别
- 4.2 数据仓库基础三层架构
- 4.3 ETL和ELT
- 二、Hive数据库操作
- 1、基本操作(掌握)
- 2、其他操作(了解)
- 三、Hive官网介绍(了解)
- 四、Hive表操作(掌握)
- 1、建表语法
- 2、数据类型
- 3、表分类
- 4、默认分隔符
- 5、内部表
- 6、外部表
- 7、查看和修改表
- 8、快速映射表
- 五、Hadoop(补充)
- 1、分布式和集群
- 2、Hadoop框架
- 2.1 概述
- 2.2 版本更新
- 2.3 Hadoop架构详解(掌握)
- 2.4 官方示例(体验下)
- 2.4.1 圆周率练习
- 2.4.2 词频统计
- 3、Hadoop的HDFS(掌握)
- 3.1 特点
- 3.2 架构
- 3.3 副本
- 3.4 shell命令
- 六、Hive环境准备(操作)
- 1、shell脚本执行方式
- 2、配置Hive环境变量
- 3、启动和停止Hive服务
- 4、连接Hive服务
- 5、DataGrip连接Hive服务
- 5.1 创建DataGrip项目
- 5.2 连接Hive
- 5.3 配置驱动jar包
- 6、DataGrip连接MySQL
前言
本文主要详解
一、Hive基础架构(重点)
二、Hive数据库,表操作(重点)
三、Hadoop架构详解(hdfs)(补充)
四、Hive环境准备(操作)(补充)
一、Hive基础架构
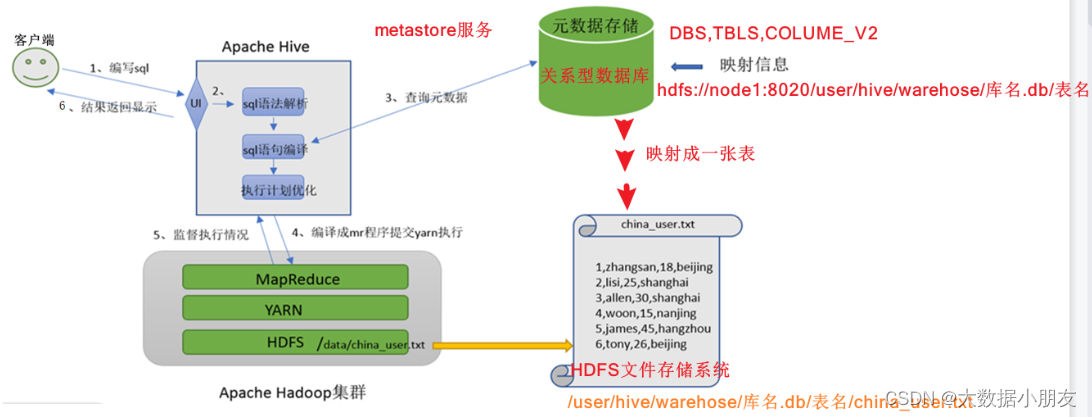
1、Hive和MapReduce的关系

1- 用户在Hive上编写数据分析的SQL语句,然后再通过Hive将SQL语句翻译成MapReduce程序代码,最后提交到Yarn集群上进行运行
2- 大家可以将Hive理解成有道词典,帮助你翻译英文
2、Hive架构(熟悉)
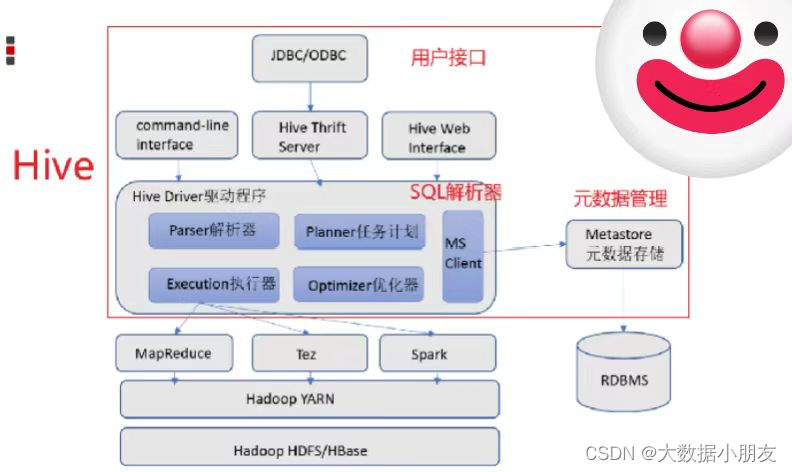
用户接口: 包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。Hive提供了 Hive Shell、 ThriftServer等服务进程向用户提供操作接口
Hiveserver2(Driver): 包括了语法、词法检查、计划编译器、优化器、执行器。核心作用是完成对HiveSQL(HQL)语句从词法、语法检查,并且进行编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce进行执行。
注意: 这部分内容不是具体的进程,而是封装在Hive所依赖的jar中通过Java代码实现。
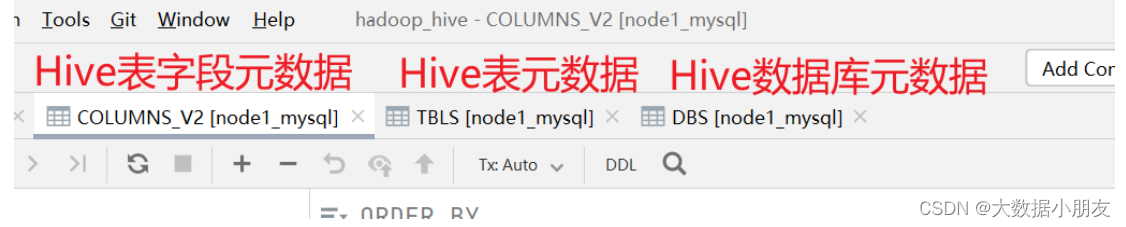
元数据信息: 包含用Hive创建的Database、table,以及表里面的字段等详细信息
元数据存储: 存储在关系型数据库(RDBMS relation database manager system)中。例如:Hive中有一个默认的关系型数据库是Derby,但是一般会改成MySQL。
Metastore: 是一个进程(服务),用来管理元数据信息。
作用: 客户端连接到Metastore中,Metastore再去关系型数据库中查找具体的元数据信息,然后将结果返回给客户端。
特点: 有了Metastore服务以后,就可以有多个客户端(工作中一般使用的就是DataGrip)同时连接。而且这些客户端都不需要知道元数据存储在什么地方,你只需要连接到Metastore服务里面就行。
3、MetaStore元数据管理服务
metastore服务配置有3种模式: 内嵌模式、本地模式、远程模式
推荐使用: 远程模式
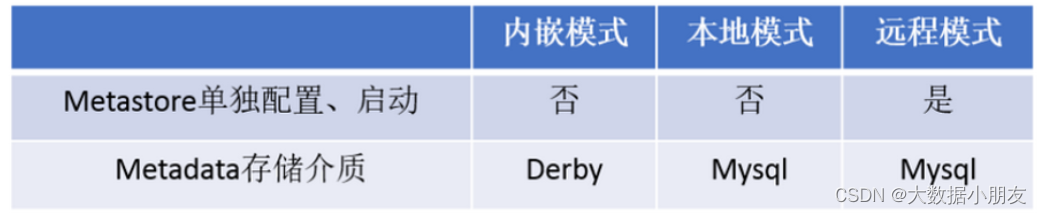
内嵌模式:
优点: 解压hive安装包 bin/hive 启动即可使用
缺点: 不适用于生产环境,derby和Metastore服务都嵌入在主Hive Server进程中,一个服务只能被一个客户端连接(如果用两个客户端以上就非常浪费资源),且元数据不能共享
本地模式:
优点: 可以单独使用外部数据库(一般是MySQL)进行元数据的管理
缺点: 相对浪费资源。指的是Metastore每次启动一次的时候都需要对应的启动Hiveserver2服务。也就是本地模式他们两个是成对出现的。这3个服务的启动顺序,MySQL->metastore->Hiveserver2
远程模式:
优点: 可以单独使用外部数据库(一般是MySQL)进行元数据的管理。Hiveserver2、metastore、MySQL这3个可以单独配置、启动、运行
缺点:
1- 这3个服务的启动顺序,MySQL->metastore->Hiveserver2
2- 这3个服务可能是分布在不同机器上运行的,可能会导致不同服务间进行数据交换速度比较慢
工作中推荐使用远程模式
4、数据仓库和数据库(熟悉)
4.1 数据仓库和数据库的区别
数据库与数据仓库的区别:实际讲的是OLTP与OLAP的区别
OLTP(On-Line Transaction Processin): 联机事务处理。数据库中可以进行数据的【增删改查】操作
OLAP(On-Line Analytical Processing): 联机分析处理。数据仓库中主要是对数据进行【查询】操作
数据仓库主要特征:
数据仓库的出现,并不是要取代数据库,主要区别如下:
1- 数据库是面向事务的设计,数据仓库是面向主题设计的。
2- 数据库是为捕获(指的是能够对数据进行增删改操作)数据而设计,数据仓库是为分析数据而设计
3- 数据库一般存储业务数据(由于用户的各种操作行为产生的数据,例如:下单、商品浏览等),数据仓库存储的一般是历史数据。
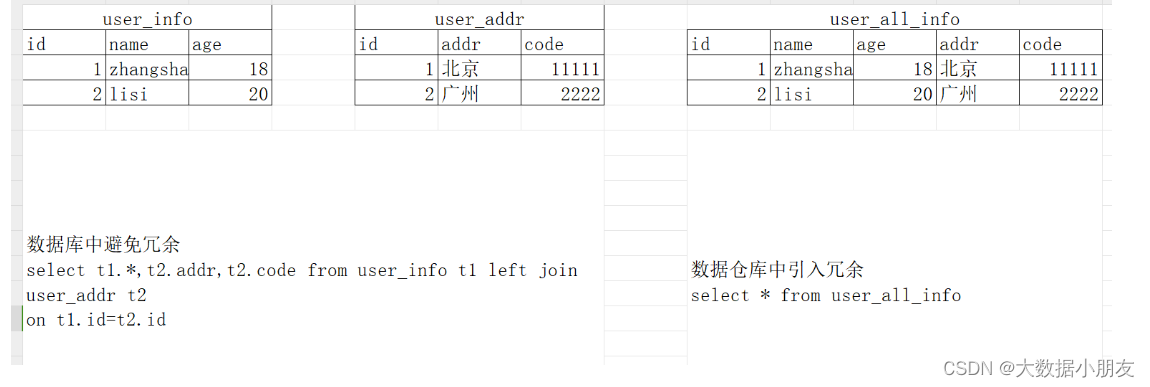
4- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。
5- 数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
4.2 数据仓库基础三层架构
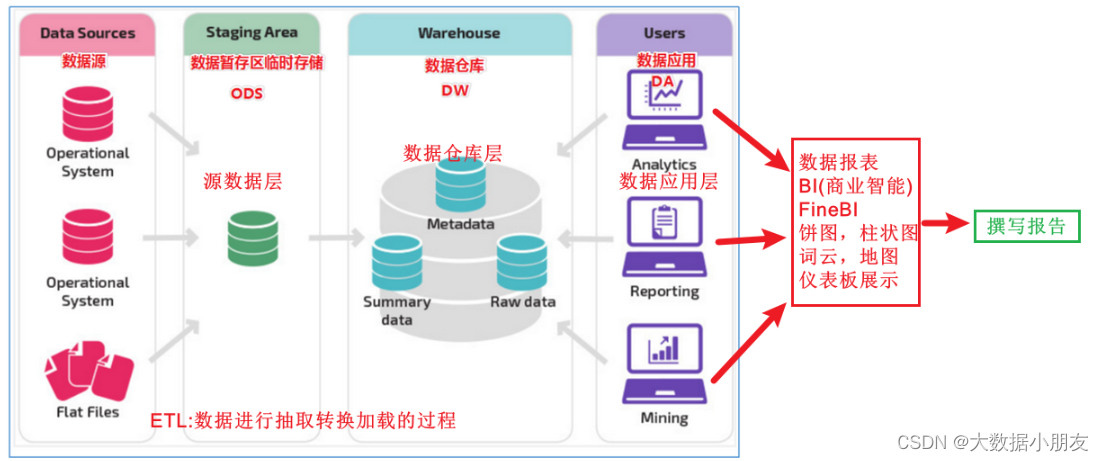
源数据层(ODS): 该层数据几乎不做任何处理操作。直接使用外部系统中的数据结构(数据库名称、表名称、表结构)。为大数据数仓中后续的其他处理提供数据支撑
数据仓库层(DW): 也称之为细节层。DW层的数据应该做到一致、准确、干净。也就是对ODS层中的数据进行ETL以及数据指标分析
数据应用层(DA或APP): 前端页面直接读取该层的数据,进行前端可视化(以看得见的图表、曲线图、柱状图、饼图)的展示
大数据前端产品示例:https://tongji.baidu.com/main/overview/demo/overview/index
4.3 ETL和ELT
广义上ETL:数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extract, 转化Transform , 装载Load)的过程。
但是在实际操作中将数据加载到仓库却产生了两种不同做法:ETL和ELT。
狭义上ETL: 先将数据从业务系统(可以理解为例如京东的订单数据)中抽取到数据仓库的ODS层中,然后执行转换操作,将数据结构化并且转换层适合后续容易处理的表结构
ELT: 将数据从业务系统中抽取并且直接加载到数据仓库的DW层的表里面。加载完以后,再根据业务需求对数据进行清洗以及指标的计算分析
二、Hive数据库操作
1、基本操作(掌握)
知识点:
创建数据库: create database [if not exists] 库名 [location '路径'];
使用数据库: use 库名;
注意: location路径默认是:
删除数据库: drop database 数据库名 [cascade];
示例:
-- Hive的数据库核心操作(掌握)
-- 创建Hive数据库
-- if not exists:如果不存在,就创建;如果存在,不会有任何的变化
-- 数据库默认放在/user/hive/warehouse HDFS目录中
create database if not exists hive1;
create database test;
-- 创建数据库的时候可以手动指定数据库存放的路径(不推荐使用,了解)
-- location指定的是HDFS路径
create database test1 location '/test1';
-- 在数据库中创建表
-- 需要先指定数据库
use hive1;
-- 建表
-- 建表实际上就是在HDFS的数据库目录下创建一个与表名同名的文件夹
create table stu(id int,name varchar(100));
-- 通过 数据库名称.表名称 也可以创建表
create table test1.stu(id int,name varchar(100));
-- 删除数据库
drop database test1;
-- 强制删除非空的数据库
-- 删除数据库的时候,同时会将HDFS上面的数据库目录删除
drop database test1 cascade;
-- 查看建库的语句
show create database hive1;
-- 查看所有数据库
show databases;
-- 查看目前正在使用的数据库
select current_database();
-- 查看指定数据库的基本信息。desc是describe单词缩写
desc database hive1;
删除数据库可能遇到的错误:
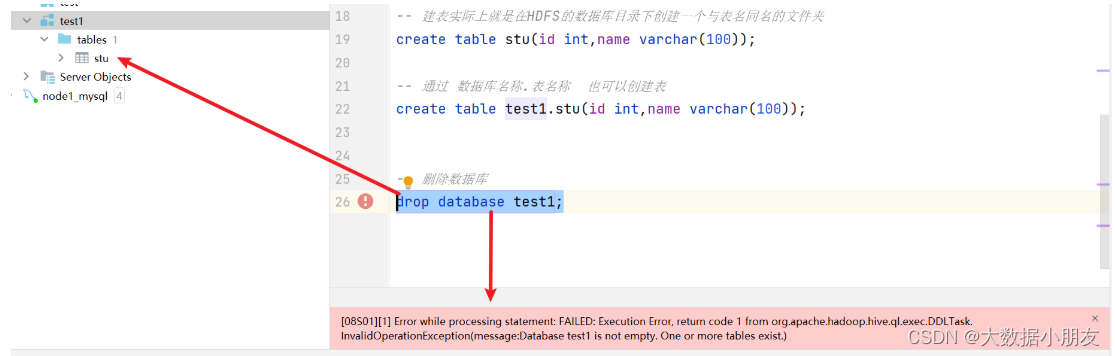
原因: 在Hive中删除数据库的时候,需要确保数据库下面没有其他的内容,否则会报错
解决办法:
1- (不推荐)先手工删除数据库中的内容,然后再删除
2- 使用cascade进行强制删除
2、其他操作(了解)
知识点:
创建数据库: create database [if not exists] 库名 [comment '注释'] [location '路径'] [with dbproperties ('k'='v')];
修改数据库路径: alter database 库名 set location 'hdfs://node1.itcast.cn:8020/路径'
修改数据库属性: alter database 库名 set dbproperties ('k'='v');
查看所有的数据库: show databases;
查看某库建库语句: show create database 库名;
查看指定数据库信息: desc database 库名;
查看指定数据库扩展信息: desc database extended 库名;
查看当前使用的数据库: select current_database();
示例:
-- Hive数据库的其他操作(了解)
-- 1- 创建数据库database,也可以使用schema进行创建数据库
create schema demo1;
-- 2- 创建数据库指定其他的信息。推荐大家将数据库默认就放在/user/hive/warehouse路径
create database demo2
comment "这是一个数据库"
location "/user/hive/warehouse/demo2.db"
with dbproperties ('name'='my name is demo2');
create database demo3
comment "it is database"
location "/user/hive/warehouse/demo3.db"
with dbproperties ('name'='my name is demo3');
-- 3- 查看建库的语句
show create database demo3;
-- 4- 查看所有数据库
show databases;
-- 5- 查看目前正在使用的数据库
select current_database();
-- 6- 查看指定数据库的基本信息。desc是describe单词缩写
desc database demo3;
-- describe database demo3;
-- 7- 查看指定数据库的扩展信息
desc database extended demo3;
-- 8- 修改数据库中数据存放的路径
-- 注意:location中的路径必须要写HDFS完整路径
-- 注意:如果修改了数据库的路径,那么只有在数据库下面创建表的时候,它才会给你创建数据库目录
-- 注释的快捷键:ctrl+/
-- 复制的快捷键:ctrl+D
-- alter database demo3 set location '/dir/demo3';
alter database demo3 set location 'hdfs://node1:8020/dir/demo3';
-- 注意:如果修改了数据库的路径,那么只有在数据库下面创建表的时候,它才会给你创建数据库目录
create table demo3.stu(id int,name varchar(100));
alter database demo3 set dbproperties ('name'='my name is demo33333');
desc database extended demo3;
修改数据库的location可能遇到的错误:
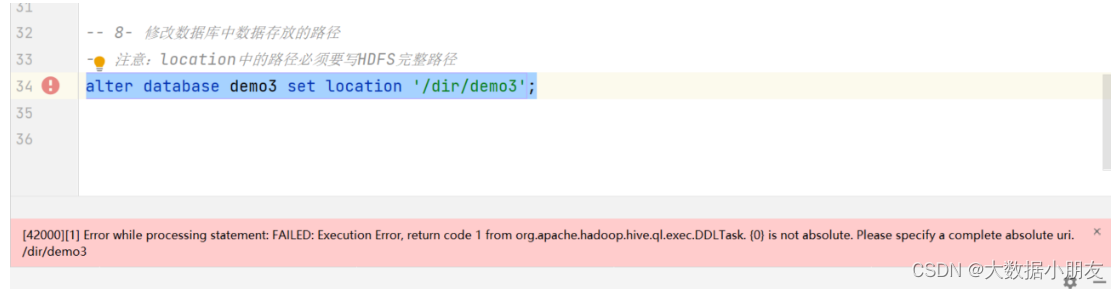
原因: location中的路径必须要写HDFS完整路径
三、Hive官网介绍(了解)
-
地址https://hive.apache.org/
-
文档
-
数据库操作
-
其他文档
四、Hive表操作(掌握)
1、建表语法
create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )
[partitioned by (分区字段名 分区字段类型)] # 分区表固定格式
[clustered by (分桶字段名) into 桶个数 buckets] # 分桶表固定格式 注意: 可以排序[sorted by (排序字段名 asc|desc)]
[row format delimited fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式
[stored as textfile] # 默认即可
[location 'hdfs://node1.itcast.cn:8020/user/hive/warehouse/库名.db/表名'] # 默认即可
; # 注意: 最后一定加分号结尾
注意:
1- 关键字顺序是从上到下从左到右,否则报错
2- 关键字不区分大小写。也就是例如create可以大写也可以小写
2、数据类型
1、基本数据类型
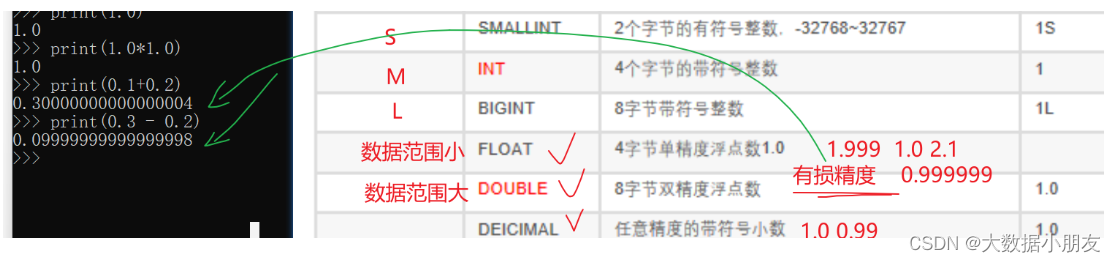
整数: int
小数: float double
字符串: string varchar(长度)
日期: date timestamp
补充: timestamp时间戳,指的是从1970-01-01 00:00:00 到现在的时间的差值。
2、复杂数据类型
集合: array
映射: map
结构体: struct
联合体: union
3、表分类
Hive中可以创建的表有好几种类型, 分别是:
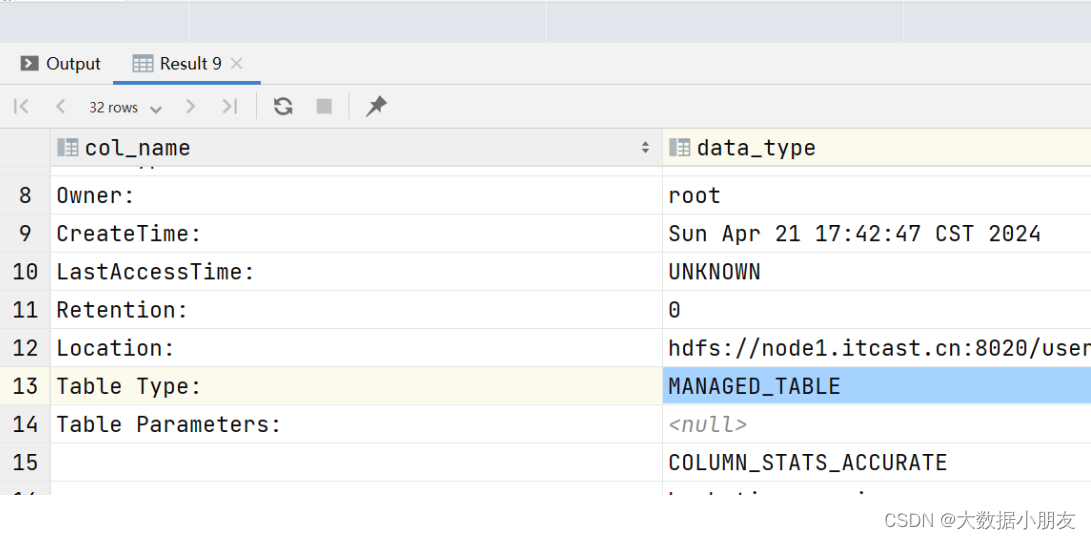
内部表(管理表): MANAGED_TABLE
分区表
分桶表
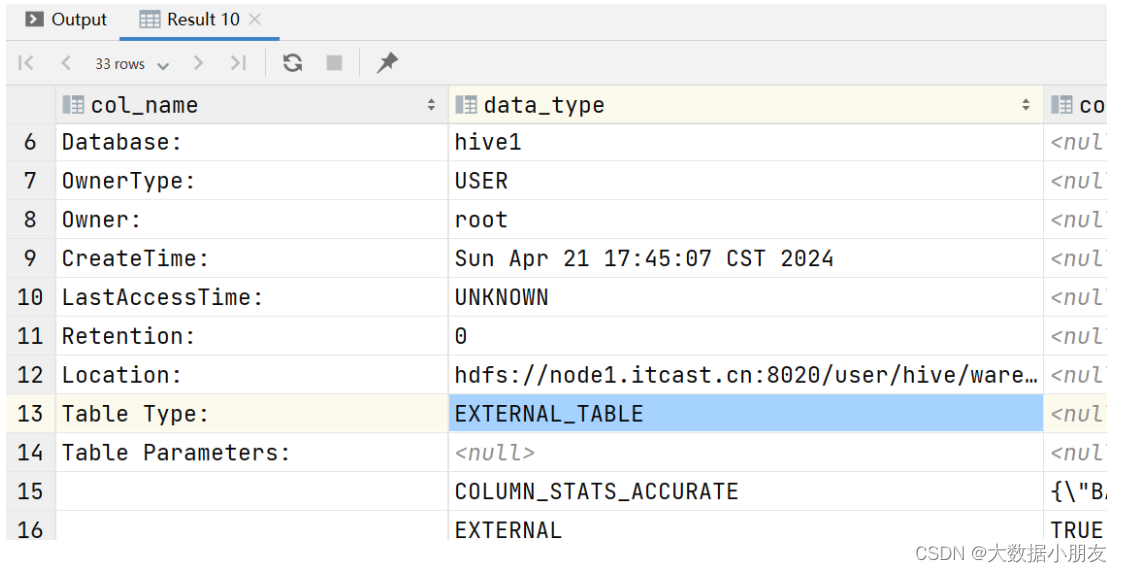
外部表(非管理表): EXTERNAL_TABLE
分区表
分桶表
default默认库存储路径: hdfs://node1:8020/user/hive/warehouse
自定义库在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db
自定义表在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db/表名称
业务数据文件在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db/表名称/业务数据文件
内部表和外部表区别?
内部表: 创建的时候没有external关键字,默认创建的就是内部表,也称之为普通表/管理表/托管表
删除内部表: 同时会删除MySQL中的元数据信息,还会删除HDFS上的业务数据
外部表: 创建的时候有external关键字,创建的就是外部表,也称之为非托管表/非管理表/关联表
删除外部表: 只会删除MySQL中的元数据信息,不会删除HDFS上的业务数据
面试题: 你在数仓中使用的是什么类型的Hive表?
说法一: 我在项目中使用的是内部表,因为这些表的数据是完全由我自己负责的,因此我对这些表以及表数据有绝对的控制权限,我能够对表进行增删改查的操作,因此用的就是内部表
说法二: 我在项目中使用的是外部表,因为这些表的数据是由其他人负责导入进来,而我没有绝对的控制权限,我只能对数据进行查询,因此使用的就是外部表
-- 创建内部表
-- 注意事项:
use hive1;
create table stu1(
id int,
name string
);
create table stu2(
id int,
name string
);
-- 创建外部表
create external table stu3(
id int,
name string
);
-- 查看表结构
desc stu1;
desc stu3;
-- 查看表格式化的信息
desc formatted stu1;
desc formatted stu3;
-- 添加数据到表里面
insert into stu1 values(1,'zhangsan');
insert into stu3 values(1,'zhangsan');
-- 删除表
drop table stu1; -- 内部表
drop table stu3; -- 外部表
删除内部表和外部表前后元数据信息的变化
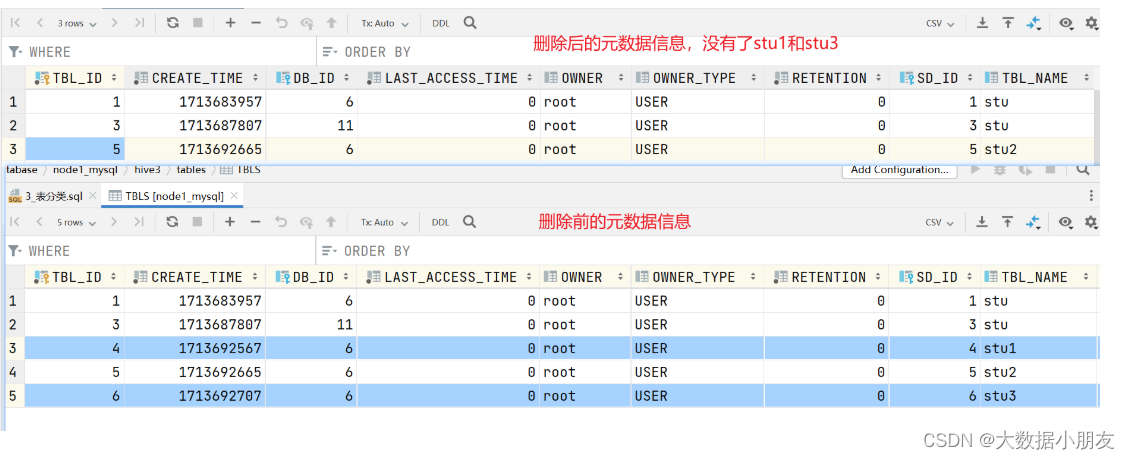
内部表信息:
外部表信息:
Hive建表的时候可能遇到的错误:
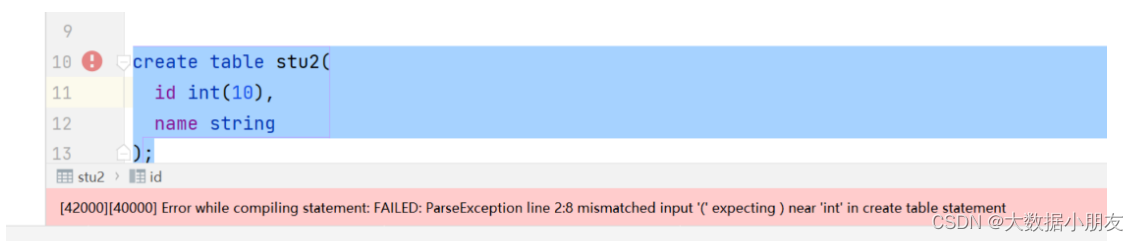
原因: 在Hive中int数据类型,不能指定长度
4、默认分隔符
知识点:
创建表的时候,如果不指定分隔符,以后表只能识别默认的分隔符,键盘不好打印,展示形式一般为:\0001,SOH,^A,□
Hive表的默认分隔符\001
示例:
-- 默认分隔符: 创建表的时候不指定就代表使用默认分隔符
-- 1.创建表
create table stu(
id int,
name string
);
-- insert方式插入数据,会自动使用默认分隔符把数据连接起来
-- 2.插入数据
insert into stu values(1,'zhangsan');
-- 3.验证数据
select * from stu;
-- 当然也可以通过在hdfs中查看,默认分隔符是\0001,其他工具中也会展示为SOH,^A,□

5、内部表
知识点:
创建普通内部表: create table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型...) [row format delimited fields terminated by '指定分隔符'];
删除内部表: drop table 内部表名; 注意: 删除mysql中元数据同时也会删除hdfs中存储数据
修改表名: alter table 旧表名 rename to 新表名;
修改表字段名称和类型: alter table 表名 change 旧字段名 新字段名 新字段类型;
修改表之添加字段(列): alter table 表名 add columns (字段名 字段类型);
修改表之替换字段(列):alter table 表名 replace columns (字段名 字段类型);
查看所有表: show tables;
查看指定表基本信息: desc 表名;
查看指定表扩展信息: desc extended 表名;
查看指定表格式信息: desc formatted 表名;
查看指定表建表语句: show create table 表名;
示例:
-- 内部表的操作
-- 创建和使用数据库
create database myhive;
use myhive;
-- 创建内部表
create table if not exists stu(
id int,
name string
);
-- 插入数据
insert into stu values(1,'张三');
-- 查询表数据
-- 下面语句被Hive进行了优化,不会变成MapReduce
select * from stu;
-- 这个会变成MapReduce
select name,count(1) from stu group by name;
-- 建表的时候指定字段间的分隔符
create table if not exists stu1(
id int,
name string
) row format delimited fields terminated by ',';
insert into stu1 values(1,'张三');
-- 创建表的其他方式
-- 创建stu2表的时候,复制stu1的表结构,并且将select的查询结果插入到stu2的表的里面去
-- 注意不会复制原表的分隔符,新表用的还是默认
create table stu2 as select * from stu1;
select * from stu2;
-- 该方式只会复制stu1表的结构,没有数据。
create table stu3 like stu1;
select * from stu3;
-- 查询表信息
-- 查看当前数据库中的所有表
show tables;
-- 查询表的基本信息
desc stu3;
-- 查看表的扩展信息
desc extended stu3;
desc formatted stu3;
-- 查看指定表的建表语句
show create table stu3;
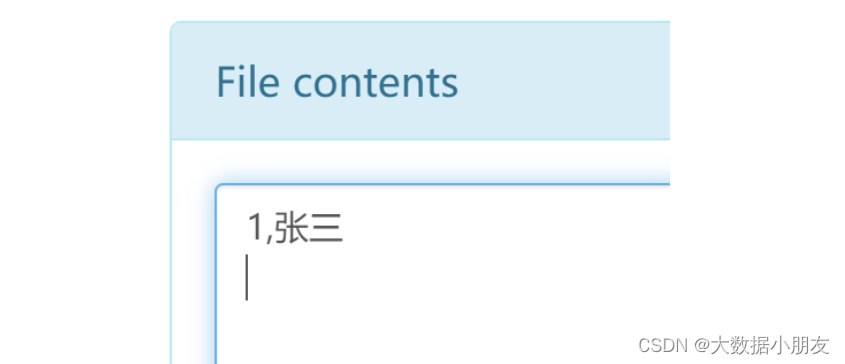
-- 删除表
drop table stu;
-- 清空表数据。需要保留表结构,但是不想要数据
select * from stu1;
truncate table stu1;
select * from stu1;
6、外部表
知识点:
创建外部表: create external table [if not exists] 外部表名(字段名 字段类型 , 字段名 字段类型 , ... )[row format delimited fields terminated by '字段分隔符'] ;
复制表: 方式1: like方式复制表结构 注意: as方式不可以使用
删除外部表: drop table 外部表名;
注意: 删除外部表效果是mysql中元数据被删除,但是存储在hdfs中的业务数据本身被保留
查看表格式化信息: desc formatted 表名; -- 外部表类型: EXTERNAL_TABLE
注意: 外部表不能使用truncate清空数据本身
示例:
-- 二.外部表的创建和删除
-- 1.外部的表创建
-- 建表方式1
create external table outer_stu1(
id int,
name string
);
-- 插入数据
insert into outer_stu1 values(1,'张三');
-- 建表方式2
create external table outer_stu2 like outer_stu1;
-- 插入数据
insert into outer_stu2 values(1,'张三');
-- 注意: 外部表不能使用create ... as 方式复制表
create external table outer_stu3 as
select * from outer_stu1; -- 报错
-- 2.演示查看外部表结构详细信息
-- 外部表类型: EXTERNAL_TABLE
desc formatted outer_stu1;
desc formatted outer_stu2;
-- 3.演示外部表的删除
-- 删除表
drop table outer_stu2;
-- 注意: 外部表不能使用truncate关键字清空数据
truncate table outer_stu1; -- 报错
-- 注意: delete和update不能使用
delete from outer_stu1; -- 报错
update outer_stu1 set name = '李四'; -- 报错
7、查看和修改表
知识点:
查看所有表: show tables;
查看建表语句: show create table 表名;
查看表信息: desc 表名;
查看表结构信息: desc 表名;
查看表格式化信息: desc formatted 表名; 注意: formatted能够展示详细信息
修改表名: alter table 旧表名 rename to 新表名
字段的添加: alter table 表名 add columns (字段名 字段类型);
字段的替换: alter table 表名 replace columns (字段名 字段类型 , ...);
字段名和字段类型同时修改: alter table 表名 change 旧字段名 新字段名 新字段类型;
注意: 字符串类型不能直接改数值类型
修改表路径: alter table 表名 set location 'hdfs中存储路径'; 注意: 建议使用默认路径
location: 建表的时候不写有默认路径/user/hive/warehouse/库名.db/表名,当然建表的时候也可以直接指定路径
修改表属性: alter table 表名 set tblproperties ('属性名'='属性值'); 注意: 经常用于内外部表切换
内外部表类型切换: 外部表属性: 'EXTERNAL'='TRUE' 内部表属性: 'EXTERNAL'='FALSE'
示例:
-- 三.表的查看/修改操作
-- 验证之前的内外部表是否存在以及是否有数据,如果没有自己创建,如果有直接使用
select * from inner_stu1 limit 1;
select * from outer_stu1 limit 1;
-- 1.表的查看操作
-- 查看所有的表
show tables;
-- 查看建表语句
show create table inner_stu1;
show create table outer_stu1;
-- 查看表基本机构
desc inner_stu1;
desc outer_stu1;
-- 查看表格式化详细信息
desc formatted inner_stu1;
desc formatted outer_stu1;
-- 2.表的修改操作
-- 修改表名
-- 注意: 外部表只会修改元数据表名,hdfs中表目录名不会改变
alter table inner_stu1 rename to inner_stu;
alter table outer_stu1 rename to outer_stu;
-- 修改表中字段
-- 添加字段
alter table inner_stu add columns(age int);
alter table outer_stu add columns(age int);
-- 替换字段
alter table inner_stu replace columns(id int,name string);
alter table outer_stu replace columns(id int,name string);
-- 修改字段
alter table inner_stu change name sname varchar(100);
alter table outer_stu change name sname varchar(100);
-- 修改表路径(实际不建议修改)
-- 注意: 修改完路径后,如果该路径不存在,不会立刻创建,以后插入数据的时候自动生成目录
alter table inner_stu set location '/inner_stu';
alter table outer_stu set location '/outer_stu';
-- 修改表属性
-- 先查看类型
desc formatted inner_stu; -- MANAGED_TABLE
desc formatted outer_stu; -- EXTERNAL_TABLE
-- 内部表改为外部表
alter table inner_stu set tblproperties ('EXTERNAL'='TRUE');
-- 外部表改为内部表
alter table outer_stu set tblproperties ('EXTERNAL'='FALSE');
-- 最后再查看类型
desc formatted inner_stu; -- EXTERNAL_TABLE
desc formatted outer_stu; -- MANAGED_TABLE
8、快速映射表
知识点:
创建表的时候指定分隔符: create [external] table 表名(字段名 字段类型)row format delimited fields terminated by 符号;
加载数据: load data [local] inpath '结构化数据文件' into table 表名;
示例:
-- 创建表
create table products(
id int,
name string,
price double,
cid string
)row format delimited
fields terminated by ',';
-- 加载数据
-- 注意: 如果从hdfs中加载文件,本质就是移动文件到对应表路径下
load data inpath '/source/products.txt' into table products;
-- 验证数据
select * from products limit 1;
五、Hadoop(补充)
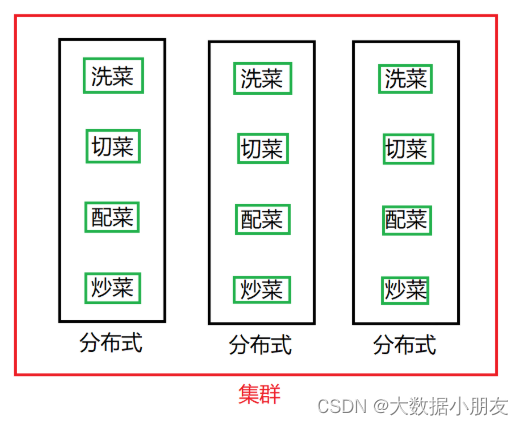
1、分布式和集群
分布式: 分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群: 集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
2、Hadoop框架
2.1 概述
Hadoop简介:是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
Hadoop起源: Doug Cutting 创建的,最早起源一个Nutch项目。
三驾马车: 谷歌的三遍论文加速了hadoop的研发
Hadoop框架意义: 作为大数据解决方案,越来越多的企业将Hadoop 技术作为进入大数据领域的必备技术。
狭义上来说:Hadoop指Apache这款开源框架,它的核心组件有:HDFS,MR,YANR
广义上来说:Hadoop通常是指一个更广泛的概念——Hadoop生态圈
Hadoop发行版本: 分为开源社区版和商业版。
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差。
商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,如: cloudera的CDH等。
2.2 版本更新
1.x版本系列: hadoop的第二代开源版本,该版本基本已被淘汰
hadoop组成: HDFS(存储)和MapReduce(计算和资源调度)
2.x版本系列: 架构产生重大变化,引入了Yarn平台等许多新特性
hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
3.x版本系列: 因为2版本的jdk1.7不更新,基于jdk1.8升级产生3版本
hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
2.3 Hadoop架构详解(掌握)
简单聊下hadoop架构?
当前版本hadoop组成: HDFS , MapReduce ,YARN
HDFS: 分布式文件存储系统,Hadoop Distributed File System,负责海量数据存储
元数据: 描述数据的数据。你的简历就是元数据,你的人就是具体的数据
NameNode: HDFS中的主节点(Master),主要负责管理集群中众多的从节点以及元数据,不负责真正数据的存储
SecondaryNameNode: 主要负责辅助NameNode进行元数据的存储。如果NameNode是CEO,那么SecondaryNameNode就是秘书。
DataNode: 主要负责真正数据的存储
YARN: 作业调度和集群资源管理的组件。负责资源调度工作
ResourceManager: 接收用户的计算任务,并且负责给任务进行资源分配
NodeManager: 负责执行主节点分配的任务,也就是给MapReduce计算程序提供资源
现实生活例子: ResourceManager对应医生,NodeManager拿药的护士
MapReduce: 分布式计算框架,负责对海量数据进行处理
如何计算: 核心思想是分而治之,Map阶段负责任务的拆解,Reduce阶段负责数据的合并计算
MR(MapReduce)程序: 可以使用Java/Python去调用方法/函数来实现具体的海量数据分析功能
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
2.4 官方示例(体验下)
在Hadoop的安装包中,官方提供了MapReduce程序的示例examples,以便快速上手体验MapReduce。该示例是使用java语言编写的,被打包成为了一个jar文件。
官方示例jar路径: /export/server/hadoop-3.3.0/share/hadoop/mapreduce
2.4.1 圆周率练习
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi x y
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数x:用于指定map阶段运行的任务次数,并发度,举例:x=10
第三个参数y:用于指定每个map任务取样的个数,举例: y=50
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
...
Job Finished in 29.04 seconds
Estimated value of Pi is 3.16000000000000000000
2.4.2 词频统计
需求:
WordCount算是大数据统计分析领域的经典需求了,相当于编程语言的HelloWorld。统计文本数据中,
相同单词出现的总次数。用SQL的角度来理解的话,相当于根据单词进行group by分组,相同的单词
分为一组,然后每个组内进行count聚合统计。
已知hdfs中word.txt文件内容如下,计算每个单词出现的次数
步骤:
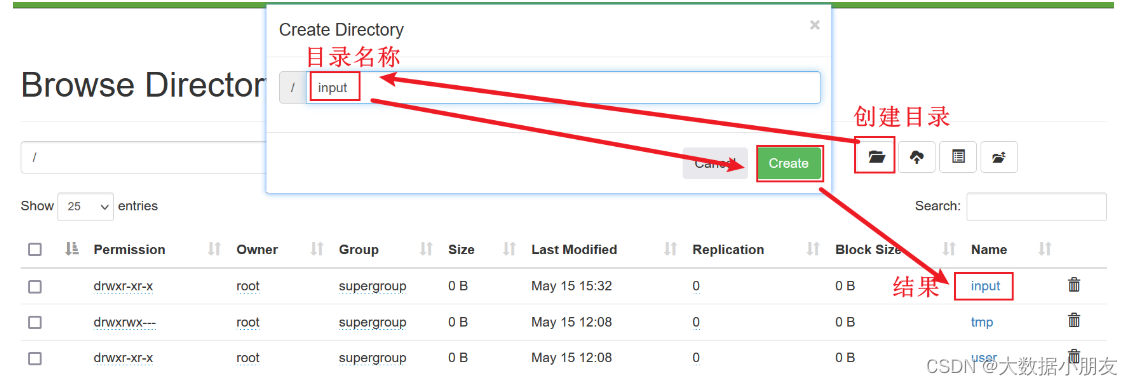
- 1.HDFS根目录中创建input目录,存储word.txt文件
可以在window本地提前创建word.txt文件存储,内容如下:
zhangsan lisi wangwu zhangsan
zhaoliu lisi wangwu zhaoliu
xiaohong xiaoming hanmeimei lilei
zhaoliu lilei hanmeimei lilei
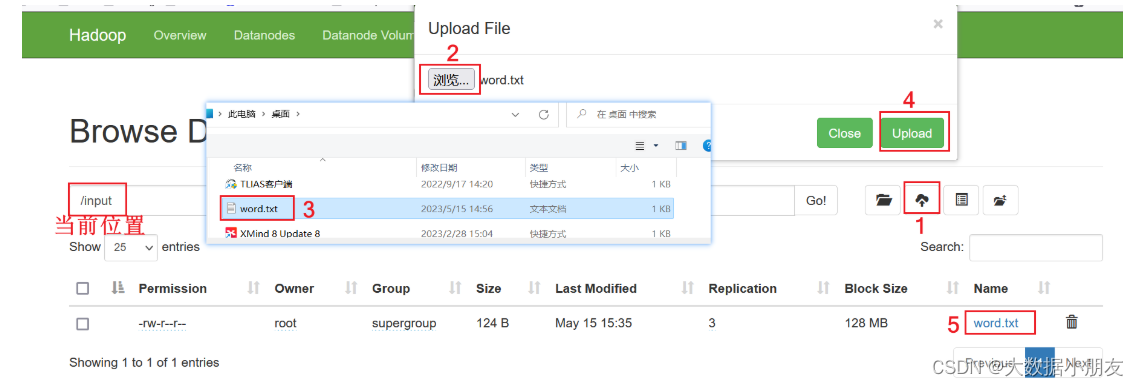
- 2.在shell命令行中执行如下命令
[root@node1 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
注意: /input 和 /output间有空格
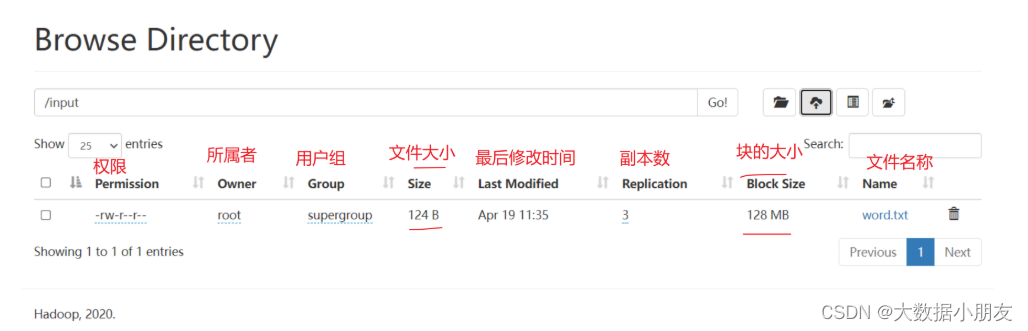
- 3.去HDFS中查看是否生成output目录
注意: output输出目录,在执行第2步命令后会自动生成,如果提前手动创建或者已经存在,就会报以下错误:
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://node1.itcast.cn:8020/output already exists
- 4.进入output目录查看part-r-00000文件,结果如下:
hanmeimei 2
lilei 3
lisi 2
wangwu 2
xiaohong 1
xiaoming 1
zhangsan 2
zhaoliu 3
3、Hadoop的HDFS(掌握)
3.1 特点
HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。
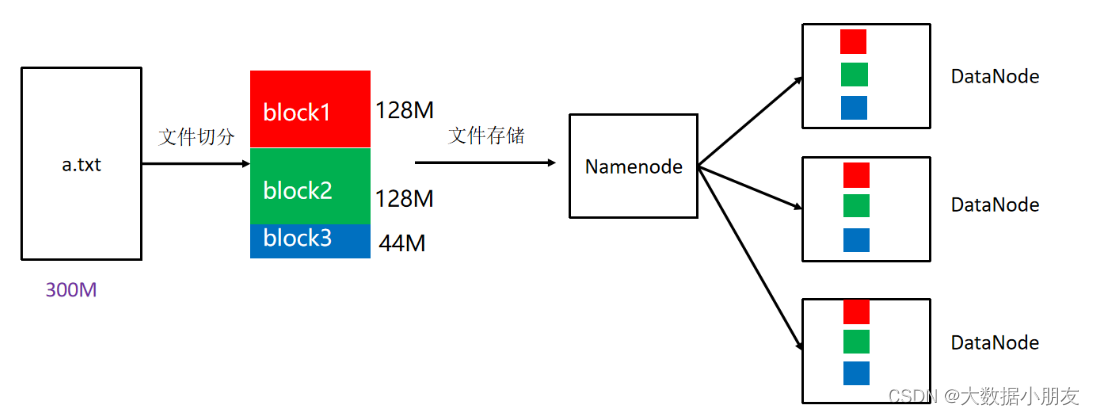
文件存储到HDFS上面可能会被进行切分,一个块的大小最大是128MB。一个块的副本数是3
3.2 架构
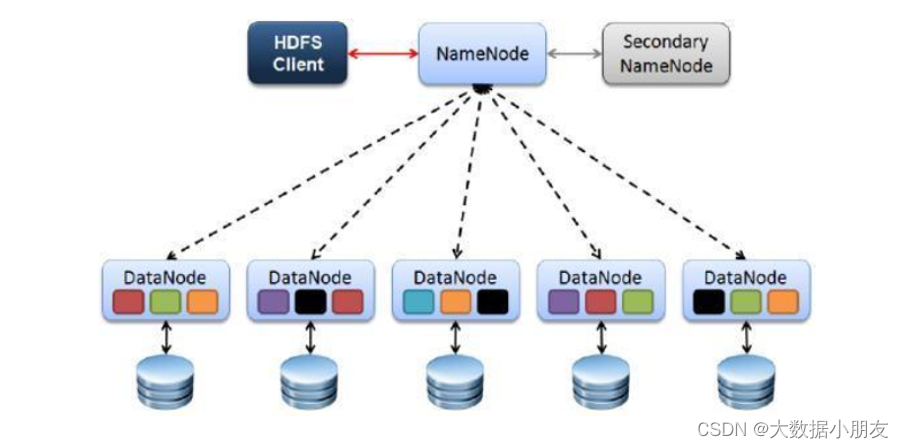
1- Client: 客户端
文件的上传和下载是由客户端发送请求给到NameNode
还要负责文件的切分;文件上传到HDFS的时候,客户端需要将文件分成一个一个的block,然后进行存储
另外还提供了一些HDFS操作命令,用来操作和访问HDFS
2- NameNode
就是Master主角色。它是一个管理者的角色
处理客户端发送过来的文件的上传/下载请求
管理HDFS元数据(文件路径、文件大小、文件的名称、文件的操作权限、文件被切分之后的block信息...)
配置3副本的策略
3- DataNode
就是Slave从角色。NameNode下达命令,DataNode执行具体的实际的操作。是真正干活的
存储实际的数据块block
负责文件的读写请求
定时向NameNode汇报block信息,心跳机制
4- SecondaryNameNode
并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。
在紧急情况下,可辅助恢复 NameNode。
3.3 副本
block: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
block: 默认是128MB。副本数是3
hdfs默认文件: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
注意:
1- HDFS的相关配置,在企业中一般使用默认
2- 但是这些参数也是可以调整。会根据数据的重要程度进行调整。如果数据的价值太低,可以调低副本数;如果数据的价值高,可以调高副本数
3.4 shell命令
***注意: 可以输入hdfs dfs查看HDFS支持的shell命令有那些
hdfs的shell命令概念: 安装好hadoop环境之后,可以执行类似于Linux的shell命令对文件的操作,如ls、mkdir、rm等,对hdfs文件系统进行操作查看,创建,删除等。
hdfs的shell命令格式1: hadoop fs -命令 参数
hdfs的shell命令格式2: hdfs dfs -命令 参数
hdfs的家目录默认: /user/root 如果在使用命令操作的时候没有加根目录/,默认访问的是此家目录/user/root
查看目录下内容: hdfs dfs -ls 目录的绝对路径。注意没有-l -a选项
创建目录: hdfs dfs -mkdir 目录的绝对路径
创建文件: hdfs dfs -touch 文件的绝对路径
移动目录/文件: hdfs dfs -mv 要移动的目录或者文件的绝对路径 目标位置绝对路径
复制目录/文件: hdfs dfs -cp 要复制的目录或者文件的绝对路径 目标位置绝对路径
删除目录/文件: hdfs dfs -rm [-r] 要删除的目录或者文件的绝对路径
查看文件的内容: hdfs dfs -cat 要查看的文件的绝对路径 注意: 除了cat还有head,tail也能查看
查看hdfs其他shell命令帮助: hdfs dfs --help
注意: hdfs有相对路径,如果操作目录或者文件的时候没有以根目录/开头,就是相对路径,默认操作的是/user/root
把本地文件内容追加到hdfs指定文件中: hdfs dfs -appendToFile 本地文件路径 hdfs文件绝对路径
注意: window中使用页面可以完成window本地和hdfs的上传下载,当然linux中使用命令也可以完成文件的上传和下载
linux本地上传文件到hdfs中: hdfs dfs -put linux本地要上传的目录或者文件路径 hdfs中目标位置绝对路径
hdfs中下载文件到liunx本地: hdfs dfs -get hdfs中要下载的目录或者文件的绝对路径 linux本地目标位置路径
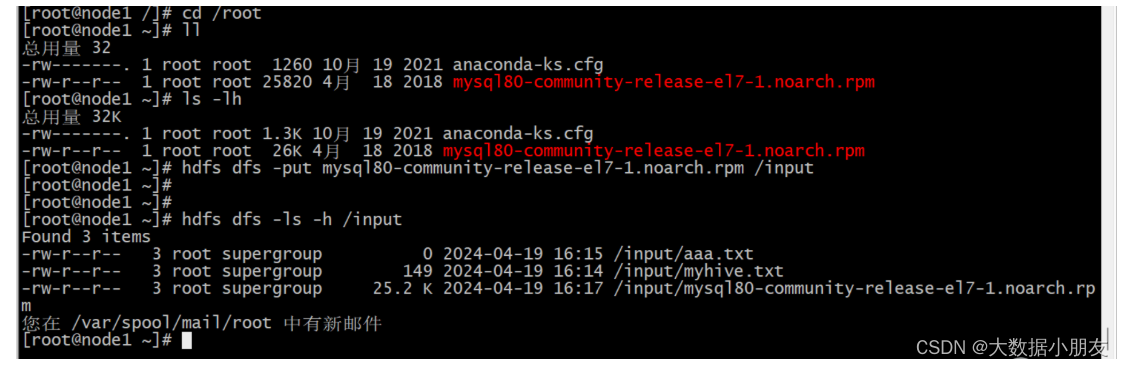
六、Hive环境准备(操作)
1、shell脚本执行方式
方式1: sh 脚本 注意: 需要进入脚本所在目录,但脚本有没有执行权限不影响执行
方式2: ./脚本 注意: 需要进入脚本所在目录,且脚本必须有执行权限
方式3: /绝对路径/脚本 注意: 不需要进入脚本所在目录,但必须有执行权限
方式4: 脚本 注意: 需要配置环境变量(大白话就是把脚本所在路径共享,任意位置都能直接访问)
2、配置Hive环境变量
步骤:
注意:下面的步骤,全部在node1上面操作
- vim编辑/etc/profile文件
[root@node1 /]# vim /etc/profile
- 输入i进入编辑模式,在/etc/profile文件末尾添加如下内容
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export PATH=
P
A
T
H
:
PATH:
PATH:HIVE_HOME/bin:$HIVE_HOME/sbin
vim小技巧:G快速定位到最后
- 保存退出,让配置生效
[root@node1 /]# source /etc/profile
- 最后建议关机拍摄下快照
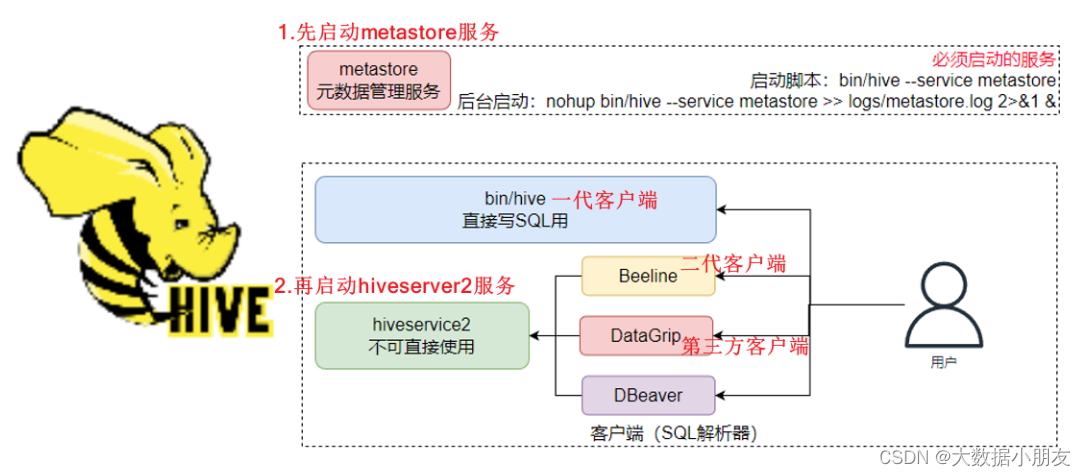
3、启动和停止Hive服务
知识点:
后台启动metastore服务: nohup hive --service metastore &
后台启动hiveserver2服务: nohup hive --service hiveserver2 &
解释:
1- nohup: 程序运行的时候,不输出日志到控制台
2- &: 让程序后台运行
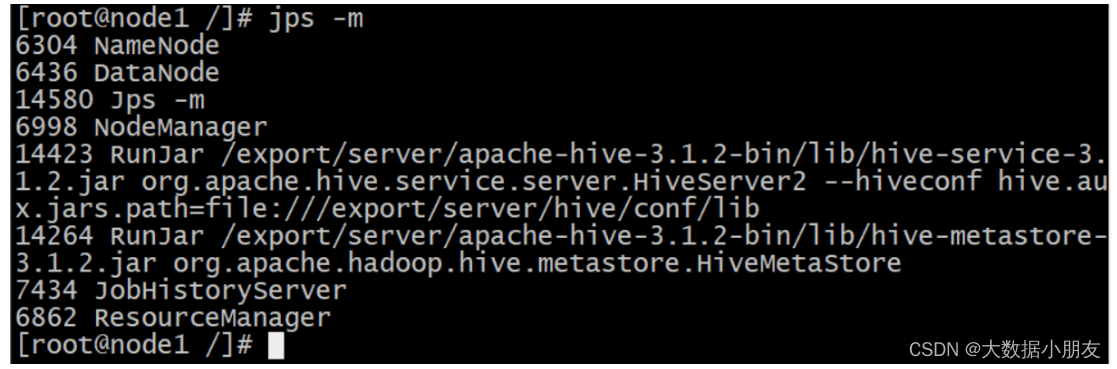
查看metastore和hiveserver2进程是否启动: jps -m
hiveserver2服务启动需要一定时间可以使用lsof查看: lsof -i:10000
注意: hiveserver2服务可能需要几十秒或者1分钟左右才能够成功启动
停止Hive服务: kill -9 进程ID
示例:
[root@node1 bin]# nohup hive --service metastore &
[1] 13490
nohup: 忽略输入并把输出追加到"nohup.out"
回车
[root@node1 bin]# nohup hive --service hiveserver2 &
[2] 13632
nohup: 忽略输入并把输出追加到"nohup.out"
回车
[root@node1 bin]# jps
...
13490 RunJar
13632 RunJar
[root@node1 bin]#
# 注意:10000端口号一般需要等待3分钟左右才会查询到
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 14423 root 522u IPv6 225303 0t0 TCP *:ndmp (LISTEN)
# 此处代表hive启动成功,今日内容完成

4、连接Hive服务
知识点:
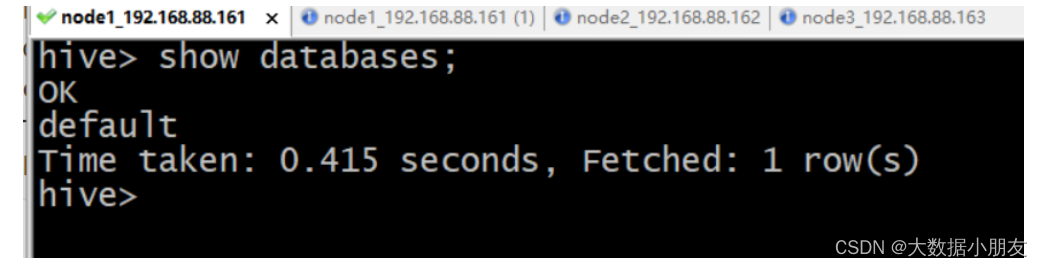
一代客户端连接命令: hive
注意: hive直接连接成功,直接可以编写sql语句
二代客户端连接命令: beeline
二代客户端远程连接命令:
注意:
一代客户端示例:
[root@node1 /]# hive
...
hive> show databases;
OK
default
Time taken: 0.5 seconds, Fetched: 1 row(s)
hive> exit;
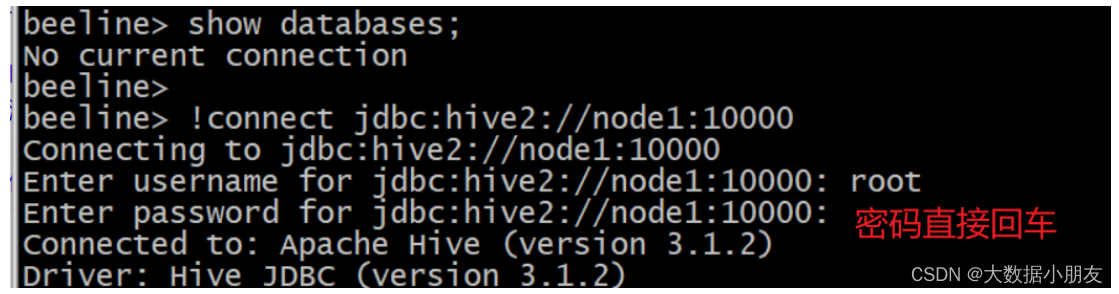
二代客户端示例:
[root@node1 /]# beeline
# 先输入!connect jdbc:hive2://node1:10000连接
beeline> !connect jdbc:hive2://node1:10000
# 再输入用户名root,密码不用输入直接回车即可
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
# 输入show databases;查看表
0: jdbc:hive2://node1:10000> show databases;
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (1.2 seconds)
5、DataGrip连接Hive服务
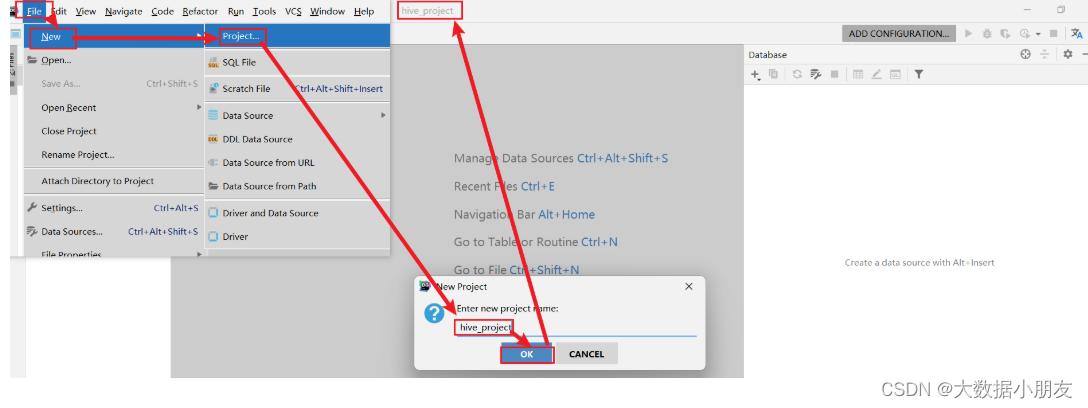
5.1 创建DataGrip项目
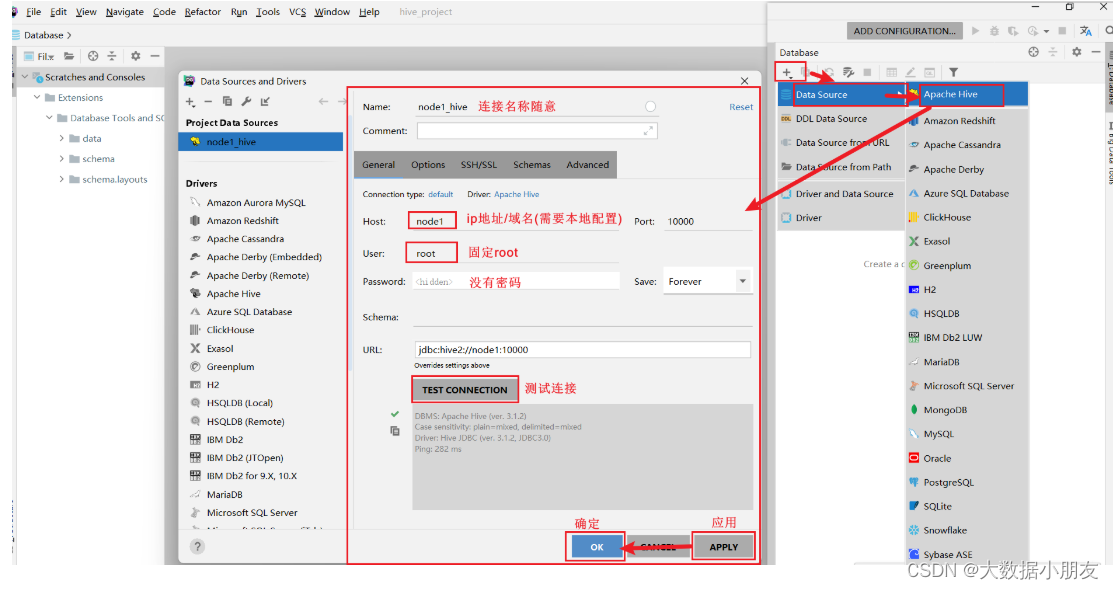
5.2 连接Hive
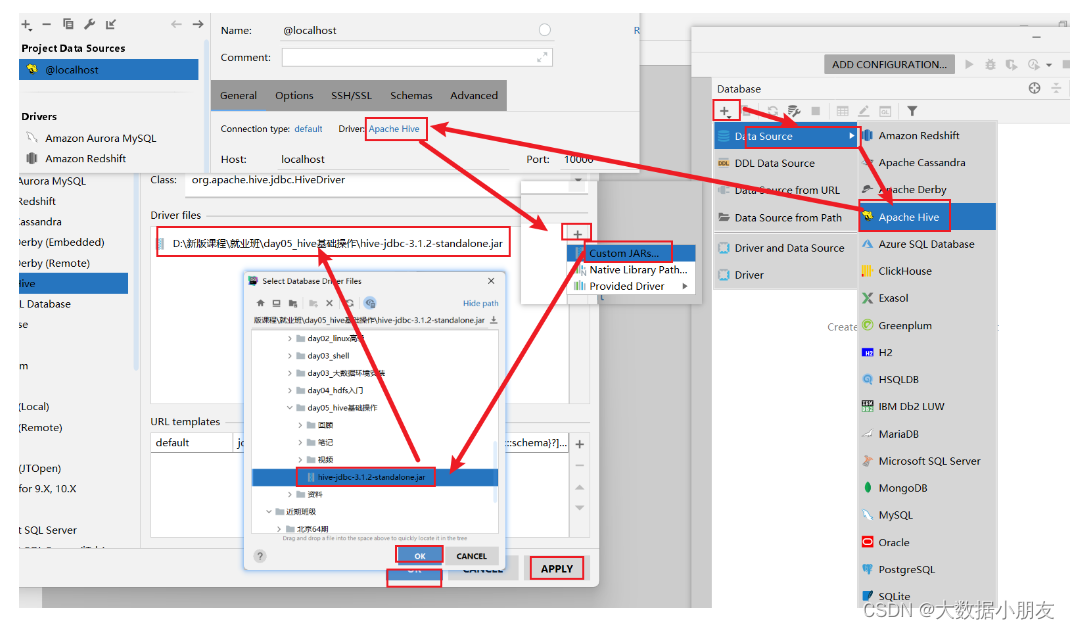
5.3 配置驱动jar包
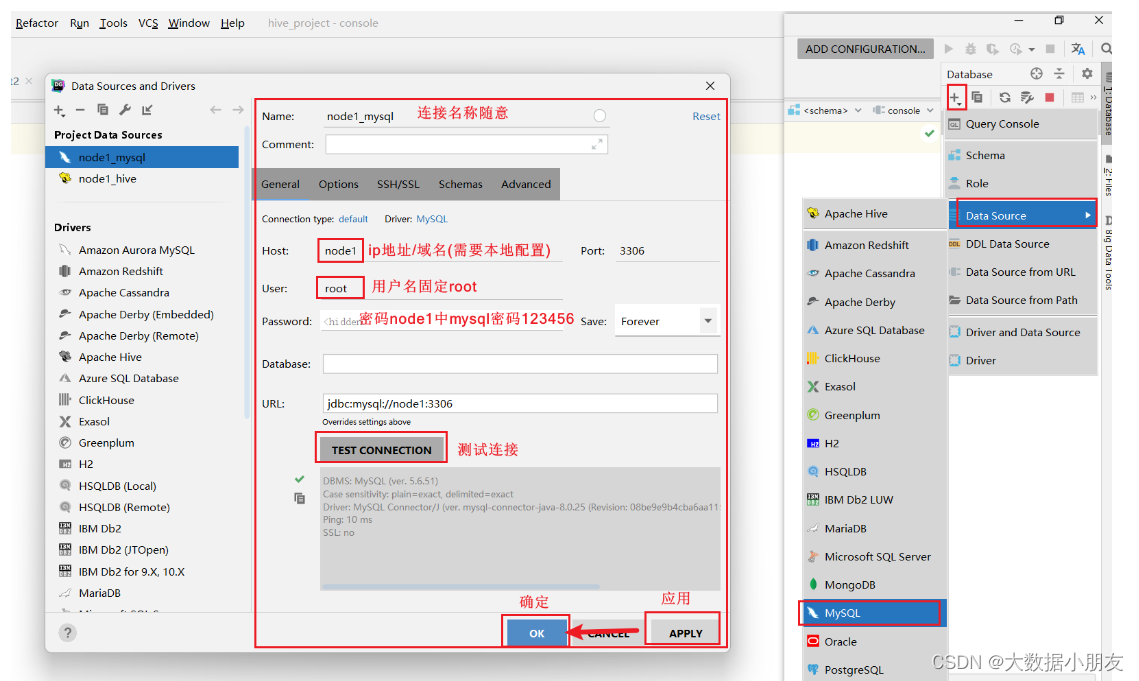
6、DataGrip连接MySQL
写作不易,觉得可以的支持一下友友们,有建议的也多多指点一下