文章目录
- @[toc]
- 零、前言
- 一、外存资源管理
- 1.1 外存空间划分
- 1.2 外存空间分配
- 1.2.1 空闲块链(慢)
- 1.2.2 空闲块表(UNIX)
- 1.2.3 字位映像图
- 1.3 进程与外存对应关系
- 二、虚拟页式存储系统
- 2.1 基本原理
- 2.2 内存页框分配策略
- 2.3 外存块的分配策略
- 2.4 页面调入时机
- 2.5 置换算法
- 2.5.1 最佳淘汰算法
- 2.5.2 先进先出
- 2.5.3 最近最少使用(LRU)
- 2.5.4 最近不用的先淘汰
- 2.5.5 最不经常使用的先淘汰(LFU)
- 2.5.6 最频繁使用算法
- 2.5.7 二次机会
- 2.5.8 时钟算法
- 2.5.9 改进的时钟算法
- 2.6 颠簸的概念
- 2.7 工作集模型(working set model)
- 2.8 页故障率反馈模型
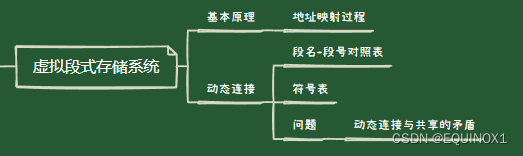
- 三、虚拟段式存储系统
- 3.1 基本原理
- 3.2 段的动态连接
- 3.2.1 为什么要有动态连接
- 3.2.2 动态连接的实现(Multics 为例)
- 3.2.3 动态连接的问题
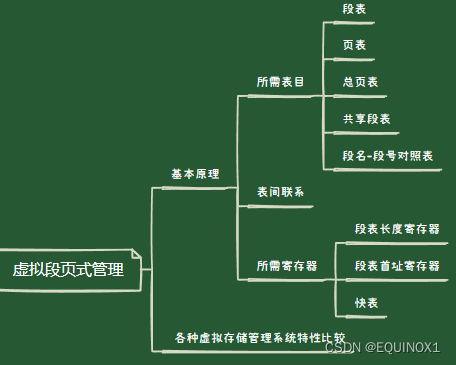
- 四、虚拟段页式管理
- 4.1 基本原理
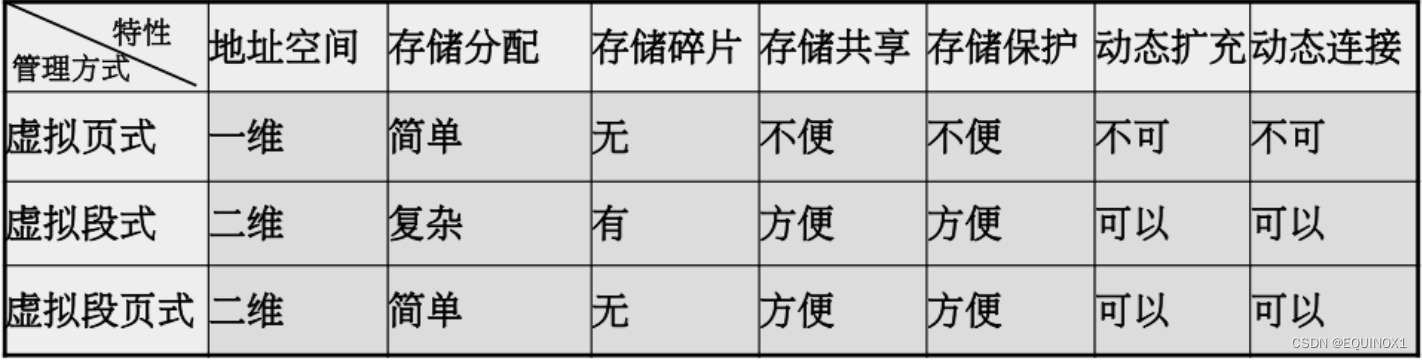
- 4.2 各种虚拟存储管理系统特性比较
文章目录
- @[toc]
- 零、前言
- 一、外存资源管理
- 1.1 外存空间划分
- 1.2 外存空间分配
- 1.2.1 空闲块链(慢)
- 1.2.2 空闲块表(UNIX)
- 1.2.3 字位映像图
- 1.3 进程与外存对应关系
- 二、虚拟页式存储系统
- 2.1 基本原理
- 2.2 内存页框分配策略
- 2.3 外存块的分配策略
- 2.4 页面调入时机
- 2.5 置换算法
- 2.5.1 最佳淘汰算法
- 2.5.2 先进先出
- 2.5.3 最近最少使用(LRU)
- 2.5.4 最近不用的先淘汰
- 2.5.5 最不经常使用的先淘汰(LFU)
- 2.5.6 最频繁使用算法
- 2.5.7 二次机会
- 2.5.8 时钟算法
- 2.5.9 改进的时钟算法
- 2.6 颠簸的概念
- 2.7 工作集模型(working set model)
- 2.8 页故障率反馈模型
- 三、虚拟段式存储系统
- 3.1 基本原理
- 3.2 段的动态连接
- 3.2.1 为什么要有动态连接
- 3.2.2 动态连接的实现(Multics 为例)
- 3.2.3 动态连接的问题
- 四、虚拟段页式管理
- 4.1 基本原理
- 4.2 各种虚拟存储管理系统特性比较
零、前言
为何要有虚拟内存的概念?
我们已经学习了段页式存储管理,以及静态动态分配的策略,似乎已经可以很好的管理操作系统的内存空间。
然而我们平时游玩一些大型游戏,特别是场景较为精细的一些游戏如2077、大表哥2等,如此庞大的场景建模渲染,以及游戏业务逻辑的运行程序,显然大多数的电脑配置,哪怕是4090Ti实际上内存是不足以一次性将整个程序全部装入内存的。
所以我们发现,我们前面的内存管理方式似乎并不能满足实际中的很多需求,那么就有了虚拟内存的概念。
这其实是基于局部性原理,对于一个程序而言,其运行的任一阶段实际上只占用了内存空间的一部分罢了,以原神为例,我们没必要在枫丹游玩的时候把其它所有国家的场景建模加载进来。
所以虚拟存储其实就是一种借助外存空间,允许一个程序在其运行过程中部分装入的技术。
大致分为:虚拟页式、虚拟段式以及虚拟段页式。
一、外存资源管理

外存空间是指磁盘等存储型设备上的存储区域,在逻辑上可分为四个主要部分:输入井、输出井、文件空间、交换空间。

1.1 外存空间划分
外存空间被看成**物理块(block)**的有序序列。
块的大小通常为静态等长, 2 i 2^i 2iB, 为一块。
块是外存分配的基本单位,也是IO传输的基本单位。
1.2 外存空间分配
1.2.1 空闲块链(慢)
空闲块链(和空闲页链相似),所有空闲块连成一条链,操作系统保存着链头链尾指针。

1.2.2 空闲块表(UNIX)
表目包含两个栏目:首空闲块号和空闲块数,适用于记录连续的空闲块。

1.2.3 字位映像图
即位图(bitset),用1位来代表一个块的状态。
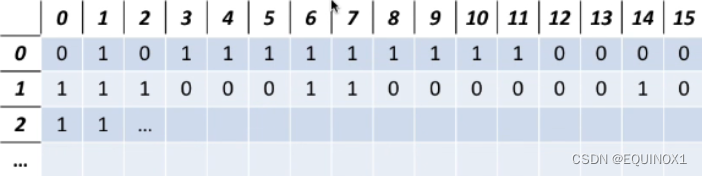
1.3 进程与外存对应关系
1、界地址存储管理外存空间分配
- 交换技术可将进程交换到外存,此时一个进程占有若干个连续的外存块
- 双对界技术:进程占据两个区域:一个保存代码一个保存数据
2、页式存储管理外存空间分配
- 页就是内存和外存进行交换的块,内存一页,外存一块
- 进程在外存储器占据若干块,这些块可以不连续
3、段式存储管理外存空间分配
一段占有若干个连续的外存块,进程多个段在外存储器可以不连续。
4、段页式存储管理外存空间分配
段内多页对应外存块可以不连续,一个进程的多段可以分散在外存储器的不同区域。
二、虚拟页式存储系统

无虚拟存储的问题
- 不能运行比内存大的程序
- 进程全部装入内存,浪费空间(进程活动具有局部性)
- 单控制流的进程需要较少部分在内存
- 多控制流的进程需要较多部分在内存
虚拟存储
- 进程部分装入内存,部分(或全部)装入外存,运行时访问在外存部分动态调入,内存不够淘汰。
想要实现的事情:
- 让内存空间和外存**“一样大”**
- 访问外存的速度“逼近”访问内存的速度
2.1 基本原理
**进程运行前:**全部装入外存,部分装入内存。
进程运行时:
- 访问页不在内存,发生缺页中断,中断处理程序
- 找到访间页在外存的地址
- 在内存找一空闲页面
- 如没有,按淘汰算法淘汰一个
- 如需要,将淘汰页面写回外存,修改页表和总页表
- 读入所需页面(切换进程)
- 重新启动被中断的指令

为实现虚拟页式管理,我们需要在页表增加一下栏目
- 外存块号,内外标志,修改标志等

2.2 内存页框分配策略
如何将内存页框分配给诸进程呢?
1、平均分配
平均分配:将内存中的所有物理页面等分给进入系统中的进程。
如:内存中的物理页面数为93,进程数为5,则每个进程分得18个物理页面剩余3个页面。
2、按进程长度比例分配
即按程序长度的比例确定分配内存物理页面数。
S为总页面数,ai为进程Pi的分配页面数:
S
=
∑
s
i
,
a
i
=
(
s
i
/
S
)
×
m
\begin{align} & S=\sum s_i , a_i = (s_i / S) \times m \end{align}
S=∑si,ai=(si/S)×m
3、按进程优先级比例分配
类似于按进程长度比例分配,我们也可以按照进程优先级比例分配
4、按进程长度和优先级别比例分配
将方法2、3结合,即将2中的si替换为进程Pi的逻辑页面数和优先级之和。
四种方法都是静态的分配策略,没有考虑页面的动态行为特性,且进程在不同的执行阶段对页面局部性也是变化的。
2.3 外存块的分配策略
1.静态分配
外存保存进程的全部页面
- 一个进程在运行之前,将其所有页面全部装入外存储器。当某一外存页面被调入内存时所占用的外存页面并不释放。
优点:
- 速度快,淘汰时如果未修改则不必写回外存
缺点:
- 牺牲一定的外存空间
2.动态分配
外存仅保持进程不在内存的页面
优点
- 节省外存
缺点
- 速度慢,淘汰时必须写回
2.4 页面调入时机
1、请调
请调(demand paging,也称请求分页),当发生缺页故障时,操作系统将其动态调入内存。
2、预调
预调(pre-paging),即一个页面访问之前就将其调入内存。
预调不一定准确,所以还是要用请调辅助。
2.5 置换算法
置换算法(replacement algorithm)又称淘汰算法、替换算法,用于确定页面的调出原则。
置换算法的设计既要考虑效果,又要考虑开销。
用途:页淘汰,段淘汰,快表淘汰。
2.5.1 最佳淘汰算法
最佳淘汰算法(OPT-optimal)本质是贪心算法,即淘汰以后不再需要的或者在最长时间以后才会用到的页面。
个人喜欢叫他预言家算法
我们无法预知未来的页面访问情况,所以这个算法是无法实现的,但是我们有必要确定一个最理想的算法是怎样的
比如下面的例子,我们访问2的时候必须要淘汰掉一页,我们发现7号页面的下次访问时间最晚,所以我们淘汰了内存块1(7号页面)

2.5.2 先进先出
老朋友了,思想就是淘汰遵循先进先出(FIFO)。每次替换都替换掉队列头部的内存块。
下面是一段FIFO算法下的示例序列:

Beladay异常:当为进程分配的物理块数增大时,缺页次数不减反增的异常现象

只有 FIFO 算法会产生 Belady异常。另外,FIFO算法虽然实现简单,但是该算法与进程实际运行时的规律不适应,因为先进入的页面也有可能最经常被访问。因此,算法性能差
2.5.3 最近最少使用(LRU)
最近最少使用算法(LRU):淘汰最近一次访问距当前时间最长的。
实现方式:用双向链表实现一个链式栈,页面每次访问都从栈底拿出放到栈顶。
示例:

OJ练习
146. LRU Cache
附个py代码
class Node:
__slots__ = 'prev', 'next', 'key', 'value'
def __init__(self, key=0, value=0):
self.key = key
self.value = value
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.dummy = Node()
self.dummy.prev = self.dummy.next = self.dummy
self.mp = dict()
# 按key获取node,同时放到链头
def get_node(self, key: int) -> Optional[Node]:
if key not in self.mp:
return None
res = self.mp[key]
self.remove(res)
self.push_front(res)
return res
# 获取值
def get(self, key: int) -> int:
node = self.get_node(key)
return node.value if node else -1
# 插入 or 更新
def put(self, key: int, value: int) -> None:
node = self.get_node(key)
if node:
node.value = value
return
self.mp[key] = node = Node(key, value)
self.push_front(node)
if len(self.mp) > self.capacity:
# LRU替换
rm = self.dummy.prev
self.remove(rm) # 替换最后一个
del self.mp[rm.key] # 从哈希表中删除key
# 删除结点,断开连接
def remove(self, rm: Node) -> None:
rm.prev.next = rm.next
rm.next.prev = rm.prev
# 链表头插
def push_front(self, x: Node) -> None:
x.prev = self.dummy
x.next = self.dummy.next
x.prev.next = x
x.next.prev = x
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
2.5.4 最近不用的先淘汰
最近不用的先淘汰(not used recently):淘汰最近一段时间未用到的。
实现:每页增加一个访问标志,访问置1,定时清0,淘汰时取标志为0的。
事实上是LRU的下位替代。

2.5.5 最不经常使用的先淘汰(LFU)
最不经常使用的先淘汰(LFU):淘汰使用次数最少的。
依据:活跃访间页面应有较大的访问次数
坏的情形:
- 前期使用多,但以后不用,难换出
- 刚调入的页面,引用少,被换出可能大
实现:记数器,调入清0,访问增1,淘汰选取最小者
OJ练习
460. LFU Cache
同样贴个py代码
class Node:
__slot__ = 'prev', 'next', 'key', 'value', 'freq'
def __init__(self, key=0, val=0):
self.key = key
self.value = val
self.freq = 1
class LFUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.mp = dict()
# 创建哨兵接口
def new_list() -> Node:
dummy = Node()
dummy.prev = dummy.next = dummy
return dummy
self.freq_to_dummy = defaultdict(new_list)
# 按key拿结点,注意调整freq
def get_node(self, key: int) -> Optional[Node]:
if key not in self.mp:
return None
res = self.mp[key]
self.remove(res)
dummy = self.freq_to_dummy[res.freq]
if dummy.prev == dummy:
del self.freq_to_dummy[res.freq]
if self.min_freq == res.freq:
self.min_freq += 1
res.freq += 1
self.push_front(self.freq_to_dummy[res.freq], res)
return res
def get(self, key: int) -> int:
node = self.get_node(key)
return node.value if node else -1
# 插入/更新结点,替换freq最低的
def put(self, key: int, value: int) -> None:
node = self.get_node(key)
if node:
node.value = value
return
if len(self.mp) == self.capacity:
dummy = self.freq_to_dummy[self.min_freq]
rm = dummy.prev
del self.mp[rm.key]
self.remove(rm)
if dummy.prev == dummy:
del self.freq_to_dummy[self.min_freq]
self.mp[key] = node = Node(key, value)
self.push_front(self.freq_to_dummy[1], node)
self.min_freq = 1
def remove(self, x: Node) -> None:
x.prev.next = x.next
x.next.prev = x.prev
def push_front(self, dummy: Node, x: Node) -> None:
x.prev = dummy
x.next = dummy.next
x.prev.next = x.next.prev = x
# Your LFUCache object will be instantiated and called as such:
# obj = LFUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
2.5.6 最频繁使用算法
最频繁使用算法(MFU):淘汰使用次数最多的。
依据:使用多的可能已经用完了。
坏的情形:程序有些成分是在整个程序运行中都使用的
2.5.7 二次机会
**二次机会(second chance)**算法:淘汰装入最久且最近未被访问的页面。
算法流程:
- 双向链表,结点额外增加标记位,1代表访问过,0代表未访问
- 从表头开始往后遍历
- 遇到标记位为1的将其置为0,然后移到链尾
- 遇到标记位为0的,将其替换为新插入的结点,然后移到链尾
- 算法结束
示例如下:

2.5.8 时钟算法
时钟(clock)算法流程:
- 将页面组织成环形,有一个指针指向当前位置。
- 每次需要淘汰页面时,从指针所指的页面开始检查。
- 如果当前页面的访问位为0,即从上次检测到目前,该页没有访问过,则将该页替换。
- 如果当前页面的访问位为1,则将其清0,并顺时针移动指针到下一个位置
- 重复上述步骤直至找到一个访问位为0的页面。
可以看出,时钟算法与二次机会算法的淘汰效果是基本相同的,差别在于二者所采用的数据结构不同,二次机会使用的是链表,需要额外存储空间,且摘链入链速度很慢。而时钟算法可直接利用页表中的引用位外加一个指针,速度快且节省空间。
2.5.9 改进的时钟算法
**时钟算法的可改进之处:**简单的时钟置换算法仅考虑到一个页面最近是否被访问过。事实上,如果被淘汰的页面没有被修改过
就不需要执行I0操作写回外存。只有被淘汰的页面被修改过时,才需要写回外存。
因此,除了考虑一个页面最近有没有被访问过之外,操作系统还应考虑页面有没有被修改过。
在其他条件都相同时,应优先淘汰没有修改过的页面,避免I/O操作。这就是改进型的时钟置换算法的思想。
修改位=0,表示页面没有被修改过;修改位=1,表示页面被修改过。
考虑访问位r,标记位m
-
r=0,m=0;最佳淘汰页面
-
r=0,m=1;淘汰前回写
-
r=1,m=0;不淘汰
-
r=1,m=1;不淘汰
算法流程:
- 将所有可能被置换的页面排成一个循环队列
- 第一轮:从当前位置开始扫描到**第一个(0,0)**的页面用于替换。本轮扫描不修改任何标志位
- 第二轮:若第一轮扫描失败,则重新扫描,查找**第一个(0,1)**的页面用于替换。本轮将所有扫描过的页面访问位设为0
- 第三轮:若第二轮扫描失败,则重新扫描,查找**第一个(0,0)**的用于替换。本轮扫描不修改任何标志位
- 第四轮:若第三轮扫描失败,则重新扫描,查找第一个(0,1)的用于替换。
- 由于第二轮已将所有帧的访问位设为0,因此经过第三轮、第四轮扫描一定会有一个页面被选中,因此改进型CLOCK置换算法选择一个淘汰页面最多会进行四轮扫描
示例:
假定某进程在内存中分得8个页框,分别保存该进程的6、3、12、8、7、9、0、1页面,现在要访问页面 15,该页不在内存中,发生缺页中断。由于没找到0,0,所以我们找了一圈后又从页8开始找10,找到页9替换,同时注意:7、8的r被置1了

2.6 颠簸的概念
颠簸(又称抖动):页面在内外存之间频繁换入换出。
主要原因:
- 分配给进程的物理页框不够
- 淘汰算法不合理
处理方法:
- 增加分配给进程的物理页框数
- 改进淘汰算法
思考题:在某些虚拟页式存储管理系统中,内存中总保持一个空闲的物理页架,这样做有什么好处?
1.在内存没有空闲页架的情况下,需要按照置换算法淘汰一个内存页架,然后读入所缺页面,缺页进程一般需要等待两次I/O传输(写外存,读外存)。
2.若内存总保持一个空闲页架,当发生页故障时,所缺页面可以被立即调入内存的这个空闲页架,缺页进程只需等待一次I/O传输时问。读入后立即淘汰个内存页面,此时可能也需执行一次I/O传输,但对缺页进程来说不需等待,因而提高了响应速度。
2.7 工作集模型(working set model)
**驻留集:**指请求分页存储管理中给进程分配的内存块的集合
**工作集(working set)**是进程在一段时间之内活跃地访问页面的集合。
WS(t,Δ)代表[t - Δ, t]内的工作集。

显然工作集大小与窗口尺寸密切相关

窗口尺寸确定:
Madnick Donovan 建议:Δ = 1万次访内
- 过小:活动页面不能全部装入,页故障率高
- 过大:内存浪费。
实现页表中增加访间位

Δ开始时,全部清 0
访问:置 1,
Δ结束时(新Δ开始时)访问标志为1的,为该期间工作集,
τ
n
+
1
=
α
w
n
+
(
1
−
α
)
τ
n
\tau_{n+1} = \alpha w_n+ (1-\alpha)\tau_n
τn+1=αwn+(1−α)τn
其中:
- w n w_n wn为第n个△周期实际工作集大小;
- τ n \tau_n τn 为第n个△周期工作集估算值;
- α通常取值为 0.5。
2.8 页故障率反馈模型
PPFB(Page Fault Feed Back)
- 页故障率 = 访问内存缺页次数 / 访间内存总次数
- **思想:**利用页故障率反馈信息,实现动态调整页框的分配。
页故障率高(达到某上界阈值):内存页面少,增加。
页故障率低(达到某下界阈值):内存页面多,减少。
三、虚拟段式存储系统
3.1 基本原理
- 虚拟段式存储管理的思想与虚拟页式存储管理相似,只是将页变为段。
- 进程运行前将主程序段装入内存,其他段装入外存储器。
- 运行时所需的段如果不在内存,将其动态调入。
- 如果内存没有足够的空间,可以采取两种方法:
- 紧凑,即将内存中的所有空闲区合并
- 淘汰,即将内存中的某段移至外存储器,
段的淘汰可以采用与页式存储管理相似的算法。虚拟段式存储管理方式的工作原理如下:
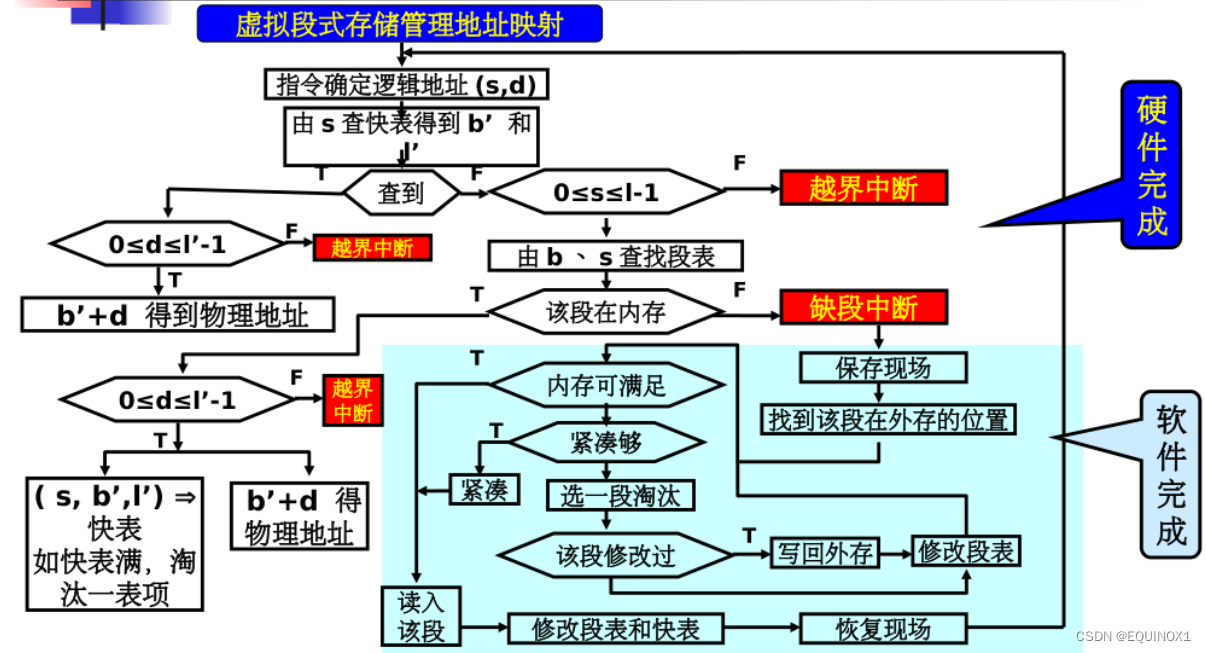
虚拟段式相比物理段式存储,段表也要进行改进:
增加:外存首址,外存首址(之前只有内存段首址寄存器),修改标志,内外标识

快表改进:
快表显然不保存外存的内容,所以不需要外存首址,内外标识

3.2 段的动态连接
3.2.1 为什么要有动态连接
静态连接:在程序运行之前将各段连接在一起,该连接是由连接装配程序完成的。
- 优点:简单
- 缺点:连接时间长,所产生的目标代码长,所连接的段在程序运行过程中不一定都能用得到。
为了克服其缺点,提出了动态连接
3.2.2 动态连接的实现(Multics 为例)
静态连接,每个程序的段的数目确定,连接装配程序为每一段分配一个段号,段名到段号的转换可以由连接装配程序完成。
而动态连接中,一个程序有多少段是不确定的,所以段名到段号的转换由操作系统完成。
动态连接实现:
段名-段号对照表:每进程一个,记录当前已连接段的表目。
符号表:每段一个,每一个符号名转换为对应的段内地址。每个段在编译(汇编)时都需要生成一个符号表。
动态连接的步骤:
编译(汇编)时:
遇到访问外段指令,采用间接寻址,指向一个间接字: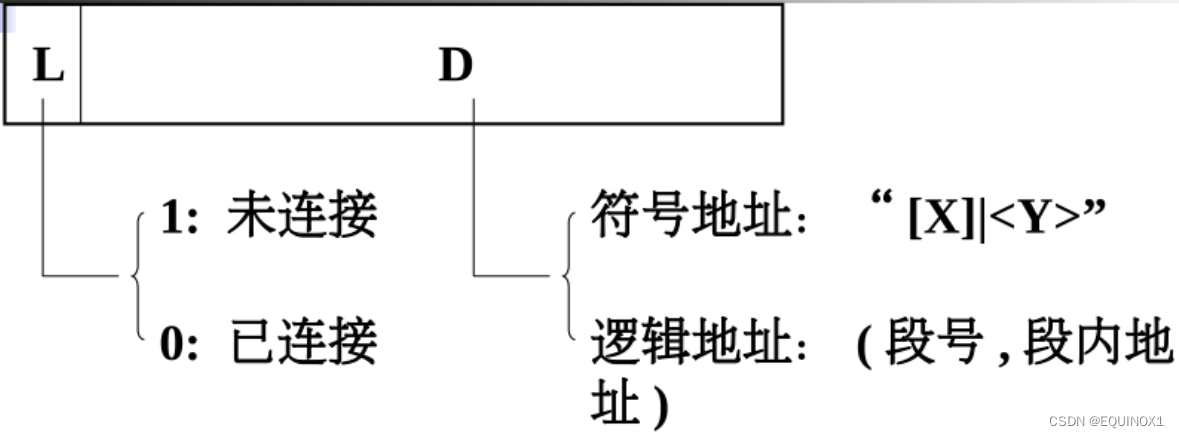
L = 1,表示需要动态连接
执行时:
遇到间接指令,且 L = 1,发生链接中断,处理程序:
(1)由D取出符号地址;
(2)由段名查段名 - 段号对照表,是否分配段号。
- 该段已经被分配段号,这说明该段以前曾经连接过,将该段号由段名-段号对照表中取出,然后由段号查找段表找到该段,继而由单元名查找该段的符号表,从中取出段内地址,然后将段号和段内地址赋给 D,0赋给L。
- 该段未分配段号,这说明该段以前未连接过。将该段由文件系统调入内存中,分配一个段号,填写段名-段号对照表,然后转步骤2。
3.2.3 动态连接的问题
动态连接与共享的矛盾
动态连接:需要修改连接字
段的共享:又要求纯代码(pure code),运行过程中不能改变自身
解决方法
共享代码分为“纯段”和“杂段”
- “纯段共享”
- “杂段私用”
四、虚拟段页式管理
思考之前为什么要对内存进行段页式存储管理:
- 结合页式存储和段式存储的优点,克服二者缺点
- 前者实现离散分配,没有碎片,但是对操作者透明;后者可以实现段长动态变化,且操作者可以编程控制,但是会有碎片
不过虚拟段页式实现复杂,需要硬件提供更多支持。
4.1 基本原理
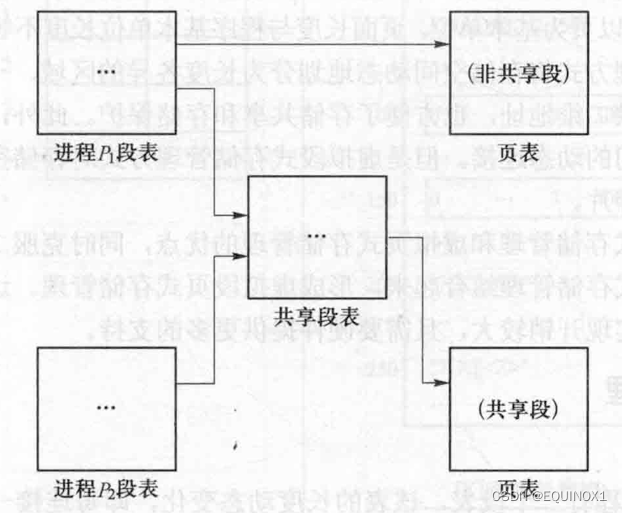
1、所需表目:
**段表:**每进程一个

**页表:**每段一个

**总页表:**即位图,内存和外存储器各有一个,其形式与非虚拟存储管理一致。
**共享段表:**整个系统有一个共享段表,记录所有共享段。

**段名-段号对照表:**每个进程有一个段名-段号对照表,其形式与非虚拟存储管理方式完全相同。
2、表间联系:
非共享段:段表指向页表
共享段:段表指向共享段表
共享段表:指向页表
3、所需寄存器
- 段表长度寄存器:整个系统有一个,保存正运行进程段表长度
- 段表首址寄存器:整个系统有一个,保存正运行进程段表首址
- 快表:每个进程有一个

4、地址映射
逻辑地址(段号,逻辑页号,页内地址)= (s,p,d);
物理地址(页框号,页内地址)=(f,d)

5、中断处理
-
连接中断
由段名查找本进程的段名-段号对照表及共享段表,经判断可以分为以下3种情形。
- 所有进程均未连接过(共享段表、段名-段号对照表均无)。查文件目录找到该段;为该段建立页表,由文件全部读入交换空间,部分读入内存,填写页表;为该段分配段号,填写段名-段号对照表;如果该段可以共享,填写共享段表,共享计数值置1;填写段表;根据段号及段内地址形成无障碍指示位的一般间接地址。
- 其它进程连接过,本进程未连接过(共享段表有,段名-段号表无)。为该段分配段号;填写段名-段号对照表,填写段表(指向共享段表),共享段表中的共享计数值加1;根据段号及段内地址形成无障碍指示位的一般间接地址。
- 本进程已经连接过(共享段表有或无,段名-段号对照表有)。根据段号及段内地址形成无障碍指示位的一般间接地址。
-
缺页中断
将对应页面调入内存,同时更新页表及页面分配表。
-
越界中断
越界中断可分为段号越界和段内页号越界这两种情形。
① 段号越界。即访问并不存在的段,地址错误,程序将被中止。
② 段内页号越界。即访问段内并不存在的页,根据段扩充标志判断该段是否可以扩充,如果可以扩充,动态增长该段,即为该段申请新页,并修改页表和段表;如果不可扩充,地址错误,程序将被中止。 -
越权中断
违反段的访问权限,程序将被中止。
4.2 各种虚拟存储管理系统特性比较