线性判别分析
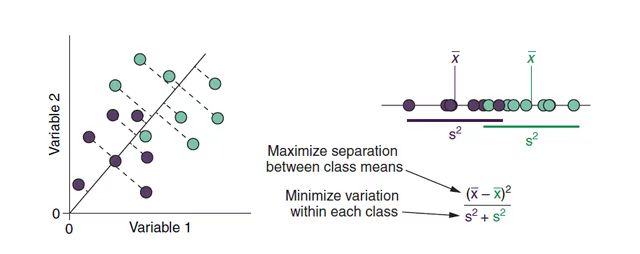
线性判别分析(Linear Discriminant Analysis,LDA)亦称 Fisher 判别分析。其基本思想是:将训练样本投影到低维超平面上,使得同类的样例尽可能近,不同类的样例尽可能远。在对新样本进行分类时,将其投影到同样的超平面上,再根据投影点的位置来确定新样本的类别。

给定的数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
D=\{(\mathbf x_1,y_1),(\mathbf x_2,y_2),\cdots,(\mathbf x_N,y_N)\}
D={(x1,y1),(x2,y2),⋯,(xN,yN)}
包含
N
N
N 个样本,
p
p
p 个特征。其中,第
i
i
i 个样本的特征向量为
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
p
)
T
\mathbf x_i=(x_{i1},x_{i2},\cdots,x_{ip})^T
xi=(xi1,xi2,⋯,xip)T 。目标变量
y
i
∈
{
c
1
,
c
2
,
⋯
,
c
K
}
y_i\in \{c_1,c_2,\cdots,c_K\}
yi∈{c1,c2,⋯,cK} 。
二分类
我们先定义
N
k
N_k
Nk为第
k
k
k 类样本的个数
∑
k
=
1
K
N
k
=
N
\sum_{k=1}^KN_k=N
k=1∑KNk=N
X
k
\mathcal X_k
Xk为第
k
k
k 类样本的特征集合
X
k
=
{
x
∣
y
=
c
k
,
(
x
,
y
)
∈
D
}
\mathcal X_k=\{\mathbf x | y=c_k,\ (\mathbf x,y)\in D \}
Xk={x∣y=ck, (x,y)∈D}
μ
k
\mu_k
μk为第
k
k
k 类样本均值向量
μ
k
=
1
N
k
∑
x
∈
X
k
x
\mu_k=\frac{1}{N_k}\sum_{\mathbf x\in \mathcal X_k}\mathbf x
μk=Nk1x∈Xk∑x
Σ
k
\Sigma_k
Σk为第
k
k
k 类样本协方差矩阵
Σ
k
=
1
N
k
∑
x
∈
X
k
(
x
−
μ
k
)
(
x
−
μ
k
)
T
\Sigma_k=\frac{1}{N_k}\sum_{\mathbf x\in \mathcal X_k}(\mathbf x-\mu_k)(\mathbf x-\mu_k)^T
Σk=Nk1x∈Xk∑(x−μk)(x−μk)T
首先从比较简单的二分类为例 y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1},若将数据投影到直线 w \mathbf w w 上,则对任意一点 x \mathbf x x,它在直线 w \mathbf w w 的投影为 w T x \mathbf w^T\mathbf x wTx 1。
- LDA需要让不同类别的数据的类别中心之间的距离尽可能的大,也就是要最大化 ∥ w T μ 0 − w T μ 1 ∥ 2 2 \|\mathbf w^T\mu_0 -\mathbf w^T\mu_1\|_2^2 ∥wTμ0−wTμ1∥22;
- 同时希望同一种类别数据的投影点尽可能的接近,也就是要同类样本投影点的方差最小化 w T Σ 0 w + w T Σ 1 w \mathbf w^T\Sigma_0\mathbf w+\mathbf w^T\Sigma_1\mathbf w wTΣ0w+wTΣ1w。
综上所述,我们的优化目标为:
max
w
∥
w
T
μ
0
−
w
T
μ
1
∥
2
2
w
T
Σ
0
w
+
w
T
Σ
1
w
\max_{\mathbf w}\frac{\|\mathbf w^T\mu_0 -\mathbf w^T\mu_1\|_2^2}{\mathbf w^T\Sigma_0\mathbf w+\mathbf w^T\Sigma_1\mathbf w}
wmaxwTΣ0w+wTΣ1w∥wTμ0−wTμ1∥22
目标函数
J
(
w
)
=
∥
w
T
μ
0
−
w
T
μ
1
∥
2
2
w
T
Σ
0
w
+
w
T
Σ
1
w
=
w
T
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
T
w
T
(
Σ
0
+
Σ
1
)
w
\begin{aligned} J(\mathbf w)&=\frac{\|\mathbf w^T\mu_0 -\mathbf w^T\mu_1\|_2^2}{\mathbf w^T\Sigma_0\mathbf w+\mathbf w^T\Sigma_1\mathbf w} \\ &=\frac{\mathbf w^T(\mu_0 -\mu_1)(\mu_0 -\mu_1)^T\mathbf w^T}{\mathbf w^T(\Sigma_0+\Sigma_1)\mathbf w } \end{aligned}
J(w)=wTΣ0w+wTΣ1w∥wTμ0−wTμ1∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)TwT
其中,
S
w
S_w
Sw为类内散度矩阵(within-class scatter matrix)
S
w
=
Σ
0
+
Σ
1
S_w=\Sigma_0+\Sigma_1
Sw=Σ0+Σ1
S b S_b Sb为类间散度矩阵(between-class scaltter matrix)
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b=(\mu_0-\mu_1)(\mu_0-\mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T
目标函数重写为
J
(
w
)
=
w
T
S
b
w
w
T
S
w
w
J(\mathbf w)=\frac{\mathbf w^TS_b\mathbf w}{\mathbf w^TS_w\mathbf w}
J(w)=wTSwwwTSbw
上式就是广义瑞利商。要取得最大值,只需对目标函数求导并等于0,可得到等式
S
b
w
(
w
T
S
w
w
)
=
S
w
w
(
w
T
S
b
w
)
S_b\mathbf w(\mathbf w^TS_w\mathbf w)=S_w\mathbf w(\mathbf w^TS_b\mathbf w)
Sbw(wTSww)=Sww(wTSbw)
重新代入目标函数可知
S
w
−
1
S
b
w
=
λ
w
S_w^{-1}S_b\mathbf w=\lambda\mathbf w
Sw−1Sbw=λw
这是一个特征值分解问题,我们目标函数的最大化就对应了矩阵
S
w
−
1
S
b
S_w^{-1}S_b
Sw−1Sb 的最大特征值,而投影方向就是这个特征值对应的特征向量。
多分类
可以将 LDA 推广到多分类任务中,目标变量 y i ∈ { c 1 , c 2 , ⋯ , c K } y_i\in \{c_1,c_2,\cdots,c_K\} yi∈{c1,c2,⋯,cK} 。
定义类内散度矩阵(within-class scatter matrix)
S
w
=
∑
k
=
1
K
Σ
k
S_w=\sum_{k=1}^K\Sigma_k
Sw=k=1∑KΣk
类间散度矩阵(between-class scaltter matrix)
S b = ∑ k = 1 K N k ( μ k − μ ) ( μ k − μ ) T S_b=\sum_{k=1}^KN_k(\mu_k-\mu)(\mu_k-\mu)^T Sb=k=1∑KNk(μk−μ)(μk−μ)T
其中
μ
\mu
μ 为所有样本均值向量
μ
=
1
N
∑
i
=
1
N
x
\mu=\frac{1}{N}\sum_{i=1}^N\mathbf x
μ=N1i=1∑Nx
常见的最大化目标函数为
J
(
W
)
=
tr
(
W
T
S
b
W
)
tr
(
W
T
S
w
W
)
J(W)=\frac{\text{tr}(W^TS_bW)}{\text{tr}(W^TS_wW)}
J(W)=tr(WTSwW)tr(WTSbW)
对目标函数求导并等于0,可得到等式
tr
(
W
T
S
w
W
)
S
b
W
=
tr
(
W
T
S
b
W
)
S
w
W
\text{tr}(W^TS_wW)S_bW=\text{tr}(W^TS_bW)S_wW
tr(WTSwW)SbW=tr(WTSbW)SwW
重新代入目标函数可知
S
b
W
=
λ
S
w
W
S_bW=\lambda S_wW
SbW=λSwW
W
W
W 的闭式解则是
S
w
−
1
S
b
S_w^{-1}S_b
Sw−1Sb 的
K
一
1
K 一 1
K一1 个最大广义特征值所对应的特征向量组成的矩阵。
由于 W W W是一个利用了样本的类别得到的投影矩阵,则多分类 LDA 将样本投影到 K − 1 K-1 K−1 维空间, K − 1 K-1 K−1 通常远小子数据原有的特征数。于是,可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息,因此 LDA也常被视为一种经典的监督降维技术。
二次判别分析
下面来介绍以概率的角度来实现线性判别分析的方法。我们的目的就是求在输入为
x
\mathbf x
x 的情况下分类为
c
k
c_k
ck 的概率最大的分类:
y
^
=
arg
max
c
k
P
(
y
=
c
k
∣
x
)
\hat y=\arg\max_{c_k} \mathbb P(y=c_k|\mathbf x)
y^=argckmaxP(y=ck∣x)
利用贝叶斯定理,类别
c
k
c_k
ck 的条件概率为
P
(
y
=
c
k
∣
x
)
=
P
(
x
∣
y
=
c
k
)
P
(
y
=
c
k
)
P
(
x
)
\mathbb P(y=c_k|\mathbf x)=\frac{\mathbb P(\mathbf x|y=c_k)\mathbb P(y=c_k)}{\mathbb P(\mathbf x)}
P(y=ck∣x)=P(x)P(x∣y=ck)P(y=ck)
假设我们的每个类别服从高斯分布
P
(
x
∣
y
=
c
k
)
=
1
(
2
π
)
p
det
Σ
k
exp
(
−
1
2
(
x
−
μ
k
)
T
Σ
k
−
1
(
x
−
μ
k
)
)
\mathbb P(\mathbf x|y=c_k)=\frac{1}{\sqrt{(2\pi)^p\det\Sigma_k}}\exp\left(-\frac{1}{2}(\mathbf x-\mathbf\mu_k)^T\Sigma^{-1}_k(\mathbf x-\mathbf\mu_k)\right)
P(x∣y=ck)=(2π)pdetΣk1exp(−21(x−μk)TΣk−1(x−μk))
其中,协方差矩阵 Σ k \Sigma_k Σk 为对称阵。
决策边界:为方便计算,我们取对数条件概率进行比较。对任意两个类别 c s c_s cs和 c t c_t ct,取
δ ( x ) = ln P ( y = c s ∣ x ) − ln P ( y = c t ∣ x ) \delta(\mathbf x)=\ln\mathbb P(y=c_s|\mathbf x)-\ln\mathbb P(y=c_t|\mathbf x) δ(x)=lnP(y=cs∣x)−lnP(y=ct∣x)
输出比较结果
y ^ s t = { c s , if δ ≤ 0 c t , otherwise \hat y_{st}=\begin{cases} c_s, &\text{if }\delta\leq0 \\ c_t, &\text{otherwise} \end{cases} y^st={cs,ct,if δ≤0otherwise
决策边界为
δ
(
x
)
=
0
\delta(\mathbf x)=0
δ(x)=0,即
ln
P
(
y
=
c
s
∣
x
)
=
ln
P
(
y
=
c
t
∣
x
)
\ln\mathbb P(y=c_s|\mathbf x)=\ln\mathbb P(y=c_t|\mathbf x)
lnP(y=cs∣x)=lnP(y=ct∣x)
我们先来化简下对数概率
ln
P
(
y
=
c
k
∣
x
)
=
ln
P
(
x
∣
y
=
c
k
)
+
ln
P
(
y
=
c
k
)
−
ln
P
(
x
)
=
−
1
2
(
x
−
μ
k
)
T
Σ
k
−
1
(
x
−
μ
k
)
−
1
2
ln
(
det
Σ
k
−
1
)
+
ln
P
(
y
=
c
k
)
+
const
=
−
1
2
x
T
Σ
k
−
1
x
+
μ
k
T
Σ
k
−
1
x
−
1
2
μ
k
T
Σ
k
−
1
μ
k
+
ln
P
(
y
=
c
k
)
−
1
2
ln
(
det
Σ
k
−
1
)
+
const
=
x
T
A
k
x
+
w
k
T
x
+
b
k
+
const
\begin{aligned} \ln\mathbb P(y=c_k|\mathbf x)&=\ln\mathbb P(\mathbf x|y=c_k)+\ln\mathbb P(y=c_k)-\ln\mathbb P(\mathbf x) \\ &=-\frac{1}{2}(\mathbf x-\mathbf \mu_k)^T\Sigma^{-1}_k(\mathbf x-\mathbf \mu_k)-\frac{1}{2}\ln(\det\Sigma^{-1}_k) +\ln\mathbb P(y=c_k)+\text{const}\\ &=-\frac{1}{2}\mathbf x^T\Sigma^{-1}_k\mathbf x+\mathbf \mu_k^T\Sigma^{-1}_k\mathbf x-\frac{1}{2}\mu_k^T\Sigma^{-1}_k\mu_k+\ln\mathbb P(y=c_k)-\frac{1}{2}\ln(\det\Sigma^{-1}_k) +\text{const}\\ &=\mathbf x^TA_k\mathbf x+\mathbf w_k^T\mathbf x+b_k+\text{const} \end{aligned}
lnP(y=ck∣x)=lnP(x∣y=ck)+lnP(y=ck)−lnP(x)=−21(x−μk)TΣk−1(x−μk)−21ln(detΣk−1)+lnP(y=ck)+const=−21xTΣk−1x+μkTΣk−1x−21μkTΣk−1μk+lnP(y=ck)−21ln(detΣk−1)+const=xTAkx+wkTx+bk+const
其中
A
k
=
−
1
2
Σ
k
−
1
,
w
k
T
=
μ
k
T
Σ
k
−
1
,
b
k
=
−
1
2
μ
k
T
Σ
k
−
1
μ
k
+
ln
P
(
y
=
c
k
)
−
1
2
ln
(
det
Σ
k
−
1
)
A_k=-\frac{1}{2}\Sigma^{-1}_k,\quad\mathbf w_k^T =\mu_k^T\Sigma^{-1}_k,\quad b_k =-\frac{1}{2}\mu_k^T\Sigma^{-1}_k\mu_k+\ln\mathbb P(y=c_k)-\frac{1}{2}\ln(\det\Sigma^{-1}_k)
Ak=−21Σk−1,wkT=μkTΣk−1,bk=−21μkTΣk−1μk+lnP(y=ck)−21ln(detΣk−1)
可以看到,上式是一个关于 x \mathbf x x 的二次函数
- 当类别的协方差矩阵不同时,生成的决策边界也是二次型的,称为二次判别分析(Quadratic Discriminant Analysis, QDA)
- 当类别的协方差矩阵相同时,决策边界将会消除二次项,变成关于 x \mathbf x x 的线性函数,于是得到了线性判别分析。
实际应用中我们不知道高斯分布的参数,我们需要用我们的训练数据去估计它们。LDA使用估计协方差矩阵的加权平均值作为公共协方差矩阵,其中权重是类别中的样本量:
Σ
^
=
∑
k
=
1
K
N
k
Σ
k
N
\hat\Sigma=\frac{\sum_{k=1}^KN_k\Sigma_k}{N}
Σ^=N∑k=1KNkΣk
如果 LDA中的协方差矩阵是单位阵
Σ
=
I
\Sigma=I
Σ=I并且先验概率相等,则LDA只需对比与类中心的欧几里得距离
ln
P
(
y
=
c
k
∣
x
)
∝
−
1
2
(
x
−
μ
k
)
T
(
x
−
μ
k
)
=
−
1
2
∥
x
−
μ
k
∥
2
2
\ln\mathbb P(y=c_k|\mathbf x)\propto -\frac{1}{2}(\mathbf x-\mathbf \mu_k)^T(\mathbf x-\mathbf \mu_k)=-\frac{1}{2}\|\mathbf x-\mathbf \mu_k\|_2^2
lnP(y=ck∣x)∝−21(x−μk)T(x−μk)=−21∥x−μk∥22
如果 LDA中的协方差矩阵非单位阵并且先验概率相等,则为马氏距离
ln
P
(
y
=
c
k
∣
x
)
∝
−
1
2
(
x
−
μ
k
)
T
Σ
k
−
1
(
x
−
μ
k
)
\ln\mathbb P(y=c_k|\mathbf x)\propto -\frac{1}{2}(\mathbf x-\mathbf \mu_k)^T\Sigma^{-1}_k(\mathbf x-\mathbf \mu_k)
lnP(y=ck∣x)∝−21(x−μk)TΣk−1(x−μk)
超平面几何知识 ↩︎