Linux 异步 I/O 框架 io_uring
- 前言
- Linux I/O 系统调用演进
- io_uring
- 与 Linux AIO 的不同
- 原理及核心数据结构:SQ/CQ/SQE/CQE
- 带来的好处
- 三种工作模式
- io_uring 系统调用 API
前言
io_uring 是 2019 年 Linux 5.1 内核首次引入的高性能 异步 I/O 框架,能显著加速 I/O 密集型应用的性能。但如果你的应用已经在使用 传统 Linux AIO 了,并且使用方式恰当, 那 io_uring 并不会带来太大的性能提升。
既然性能跟传统 AIO 差不多,那为什么还称 io_uring 为革命性技术呢?
- 统一了 Linux 异步 I/O 框架
- Linux AIO 只支持 direct I/O 模式的存储文件 (storage file),而且主要用在数据库这一细分领域;
- io_uring 支持存储文件和网络文件(network sockets),也支持更多的异步系统调用 (accept/openat/stat/…),而非仅限于 read/write 系统调用。
-
在设计上是真正的异步 I/O,作为对比,Linux AIO 虽然也 是异步的,但仍然可能会阻塞,某些情况下的行为也无法预测;
-
灵活性和可扩展性非常好,甚至能基于 io_uring 重写所有系统调用,而 Linux AIO 设计时就没考虑扩展性。eBPF 也算是异步框架(事件驱动),但与 io_uring 没有本质联系,二者属于不同子系统, 并且在模型上有一个本质区别:
- eBPF 对用户是透明的,只需升级内核(到合适的版本),应用程序无需任何改造;
- io_uring 提供了新的系统调用和用户空间 API,因此需要应用程序做改造。
- eBPF 作为动态跟踪工具,能够更方便地排查和观测 io_uring 等模块在执行层面的具体问题。
本文介绍 Linux 异步 I/O 的发展历史,io_uring 的原理和功能, 并给出了一些程序示例和性能压测结果。
Linux I/O 系统调用演进
- 基于 fd 的阻塞式 I/O:read()/write()
作为大家最熟悉的读写方式,Linux 内核提供了基于文件描述符的系统调用, 这些描述符指向的可能是存储文件(storage file),也可能是 network sockets:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
二者称为阻塞式系统调用(blocking system calls),因为程序调用 这些函数时会进入 sleep 状态,然后被调度出去(让出处理器),直到 I/O 操作完成:
- 如果数据在文件中,并且文件内容已经缓存在 page cache 中,调用会立即返回;
- 如果数据在另一台机器上,就需要通过网络(例如 TCP)获取,会阻塞一段时间;
- 如果数据在硬盘上,也会阻塞一段时间。
但很容易想到,随着存储设备越来越快,程序越来越复杂, 阻塞式(blocking)已经这种最简单的方式已经不适用了。
- 非阻塞式 I/O:select()/poll()/epoll()
注意:select()/poll()/epoll() 默认是阻塞的,可以设置超时参数为 0 使其为非阻塞。
阻塞式之后,出现了一些新的、非阻塞的系统调用,例如 select()、poll() 以及 epoll()。 应用程序在调用这些函数读写时不会阻塞,而是立即返回,返回的是一个 已经 ready 的文件描述符列表。
但这种方式存在一个致命缺点:只支持 network sockets 和 pipes —— epoll() 甚至连 storage files 都不支持。
-
线程池方式
对于 storage I/O,经典的解决思路是 thread pool: 主线程将 I/O 分发给 worker 线程,后者代替主线程进行阻塞式读写,主线程不会阻塞。这种方式的问题是线程上下文切换开销可能非常大,后面性能压测会看到。 -
Direct I/O(数据库软件):绕过 page cache
随后出现了更加灵活和强大的方式:数据库软件(database software) 有时 并不想使用操作系统的 page cache, 而是希望打开一个文件后,直接从设备读写这个文件(direct access to the device)。 这种方式称为直接访问(direct access)或直接 I/O(direct I/O)。
- 需要指定 O_DIRECT flag;
- 需要应用自己管理自己的缓存 —— 这正是数据库软件所希望的;
- 是 zero-copy I/O,因为应用的缓冲数据直接发送到设备,或者直接从设备读取。
#include <fcntl.h>
#include <malloc.h>
#include <iostream>
#define _GNU_SOURCE //测试宏
void rawIO() {
int fd;
size_t length;
char *buf;
length = getpagesize() * 1024*16;
cout << "page size:" << getpagesize() << endl;
fd = open("/home/out.log", O_RDWR | O_APPEND | O_DIRECT);
if (fd == -1) {
printf("%s", strerror(errno));
exit(-1);
}
buf = (char *) memalign(getpagesize(), length);
if (buf == nullptr) {
printf("%s", strerror(errno));
exit(1);
}
for (int i = 0; i < length; i++) {
buf[i] = 'a';
}
int ret = write(fd, (void *) buf, length);
if (ret == -1) {
std::cout << "write fail" << std::endl;
printf("%s \n", strerror(errno));
}
free(buf);
}
-
异步 IO(AIO)
前面提到,随着存储设备越来越快,主线程和 worker 线性之间的上下文切换开销占比越来越高。 现在市场上的一些设备,例如 Intel Optane ,延迟已经低到和上下文切换一个量级(微秒 us)。换个方式描述, 更能让我们感受到这种开销: 上下文每切换一次,我们就少一次 dispatch I/O 的机会。 -
小结
以上可以清晰地看出 Linux I/O 的演进:
- 最开始是同步(阻塞式)系统调用;
- 然后随着实际需求和具体场景,不断加入新的异步接口,还要保持与老接口的兼容和协同工作。
另外也看到,在非阻塞式读写的问题上并没有形成统一方案:
Network socket 领域:添加一个异步接口,然后去轮询(poll)请求是否完成(readiness);
Storage I/O 领域:只针对某一细分领域(数据库)在某一特定时期的需求,添加了一个定制版的异步接口。
这就是 Linux I/O 的演进历史 —— 只着眼当前,出现一个问题就引入一种设计,而并没有多少前瞻性 —— 直到 io_uring 的出现。
io_uring
io_uring 来自资深内核开发者 Jens Axboe 的想法,他在 Linux I/O stack 领域颇有研究。 从最早的 patch aio: support for IO polling 可以看出,这项工作始于一个很简单的观察:随着设备越来越快, 中断驱动(interrupt-driven)模式效率已经低于轮询模式 (polling for completions) —— 这也是高性能领域最常见的主题之一。
- io_uring 的基本逻辑与 linux-aio 是类似的:提供两个接口,一个将 I/O 请求提交到内核,一个从内核接收完成事件。
- 但随着开发深入,它逐渐变成了一个完全不同的接口:设计者开始从源头思考 如何支持完全异步的操作。
与 Linux AIO 的不同
io_uring 与 linux-aio 有着本质的不同:
-
在设计上是真正异步的(truly asynchronous)。只要 设置了合适的 flag,它在系统调用上下文中就只是将请求放入队列, 不会做其他任何额外的事情,保证了应用永远不会阻塞。
-
支持任何类型的 I/O:cached files、direct-access files 甚至 blocking sockets。
-
由于设计上就是异步的(async-by-design nature),因此无需 poll+read/write 来处理 sockets。 只需提交一个阻塞式读(blocking read),请求完成之后,就会出现在 completion ring。
灵活、可扩展:基于 io_uring 甚至能重写(re-implement)Linux 的每个系统调用。
原理及核心数据结构:SQ/CQ/SQE/CQE
每个 io_uring 实例都有两个环形队列(ring),在内核和应用程序之间共享:
- 提交队列:submission queue (SQ)
- 完成队列:completion queue (CQ)
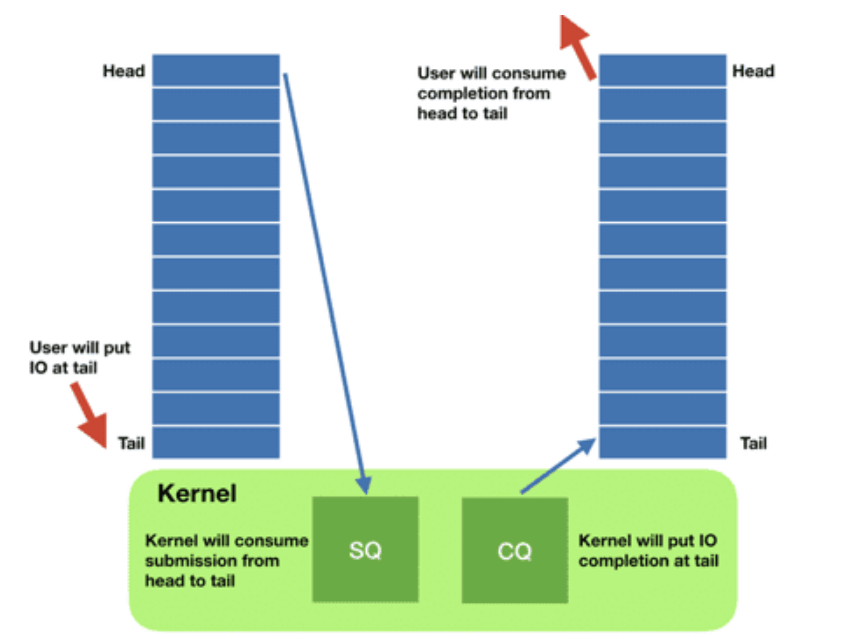
这两个队列: - 都是单生产者、单消费者,size 是 2 的幂次;
- 提供无锁接口(lock-less access interface),内部使用 内存屏障做同步(coordinated with memory barriers)。
使用方式:
- 请求
- 应用创建 SQ entries (SQE),更新 SQ tail;
- 内核消费 SQE,更新 SQ head。
- 完成
- 内核为完成的一个或多个请求创建 CQ entries (CQE),更新 CQ tail;
- 应用消费 CQE,更新 CQ head。
- 完成事件(completion events)可能以任意顺序到达,到总是与特定的 SQE 相关联的。
- 消费 CQE 过程无需切换到内核态。
带来的好处
io_uring 这种请求方式还有一个好处是:原来需要多次系统调用(读或写),现在变成批处理一次提交。
io_uring 将这种批处理能力带给了 storage I/O 系统调用之外的 其他一些系统调用,包括:read/write/send/recv/accept/openat/stat,专用的一些系统调用,例如 fallocate。
此外,io_uring 使异步 I/O 的使用场景也不再仅限于数据库应用,普通的 非数据库应用也能用。
三种工作模式
io_uring 实例可工作在三种模式:
-
中断驱动模式(interrupt driven)
默认模式。可通过 io_uring_enter() 提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。 -
轮询模式(polled)
Busy-waiting for an I/O completion,而不是通过异步 IRQ(Interrupt Request)接收通知。 -
内核轮询模式(kernel polled)
这种模式中,会创建一个内核线程(kernel thread)来执行 SQ 的轮询工作。
io_uring 系统调用 API
int io_uring_setup(unsigned int entries, struct io_uring *ring);