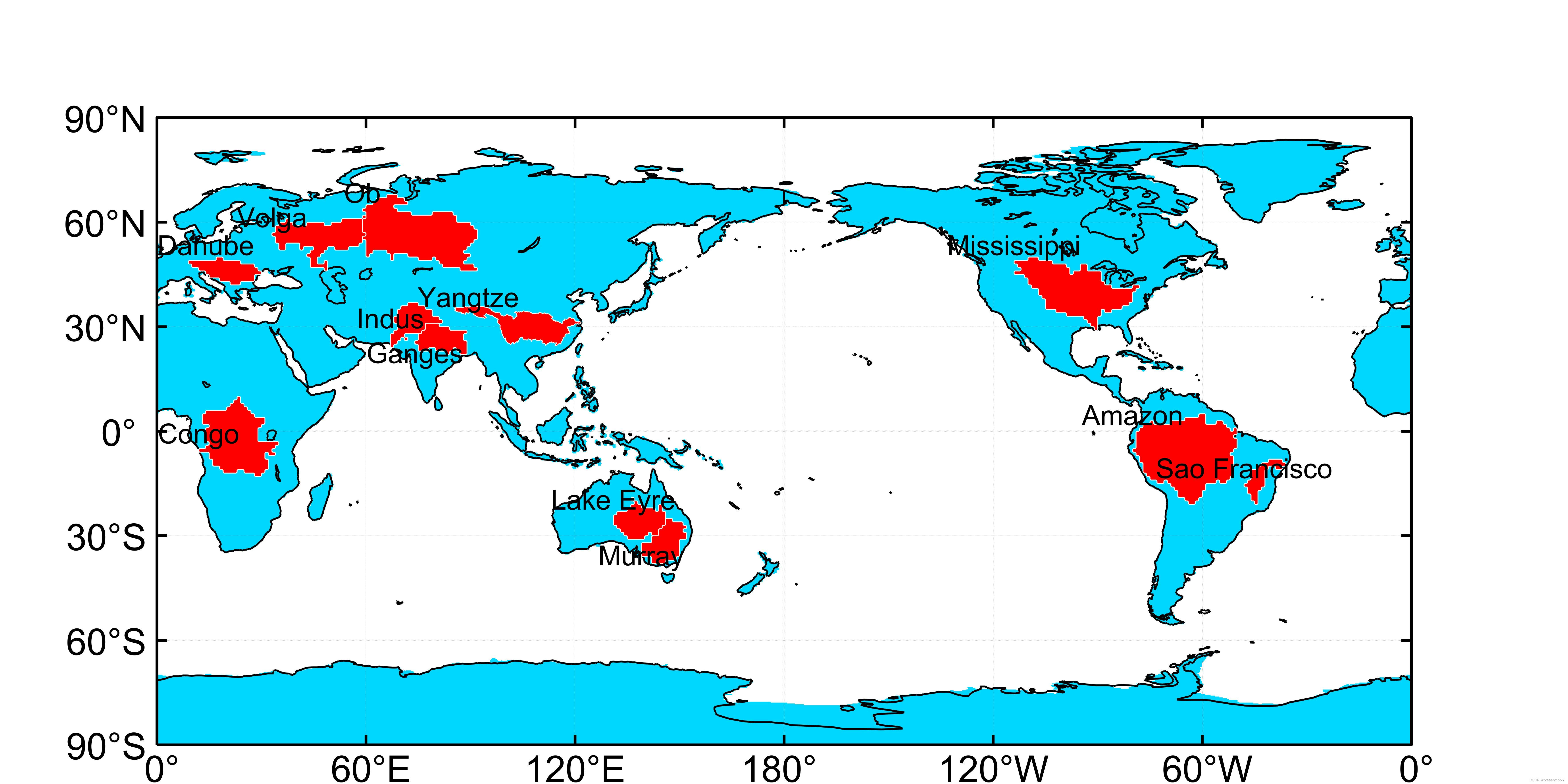
流量世界第一、长度第二的亚马逊流域(Amazon)、南美洲第四大、整条河流位于巴西的圣弗朗西斯科流域(Sao Francisco)、世界第四长、北美洲最长的密西西比流域(Mississippi)、欧洲最长的伏尔加流域(Volga)、非洲仅次于尼罗河的刚果流域(Congo)、亚洲和中国第一长、世界第三长的长江流域(Yangtze)、南亚主要河流恒河流域(Ganges),可与恒河流域相媲美的印度河流域(Indus),澳大利亚中部的季节性湖泊艾尔湖流域(Lake Eyre),澳大利亚最长、最大的默里河流域(Murray),俄罗斯联邦第三大的鄂毕河流域(Ob),以及欧洲第二长河多瑙河流域(Danube)
各大洲流域具体分布位置如下:
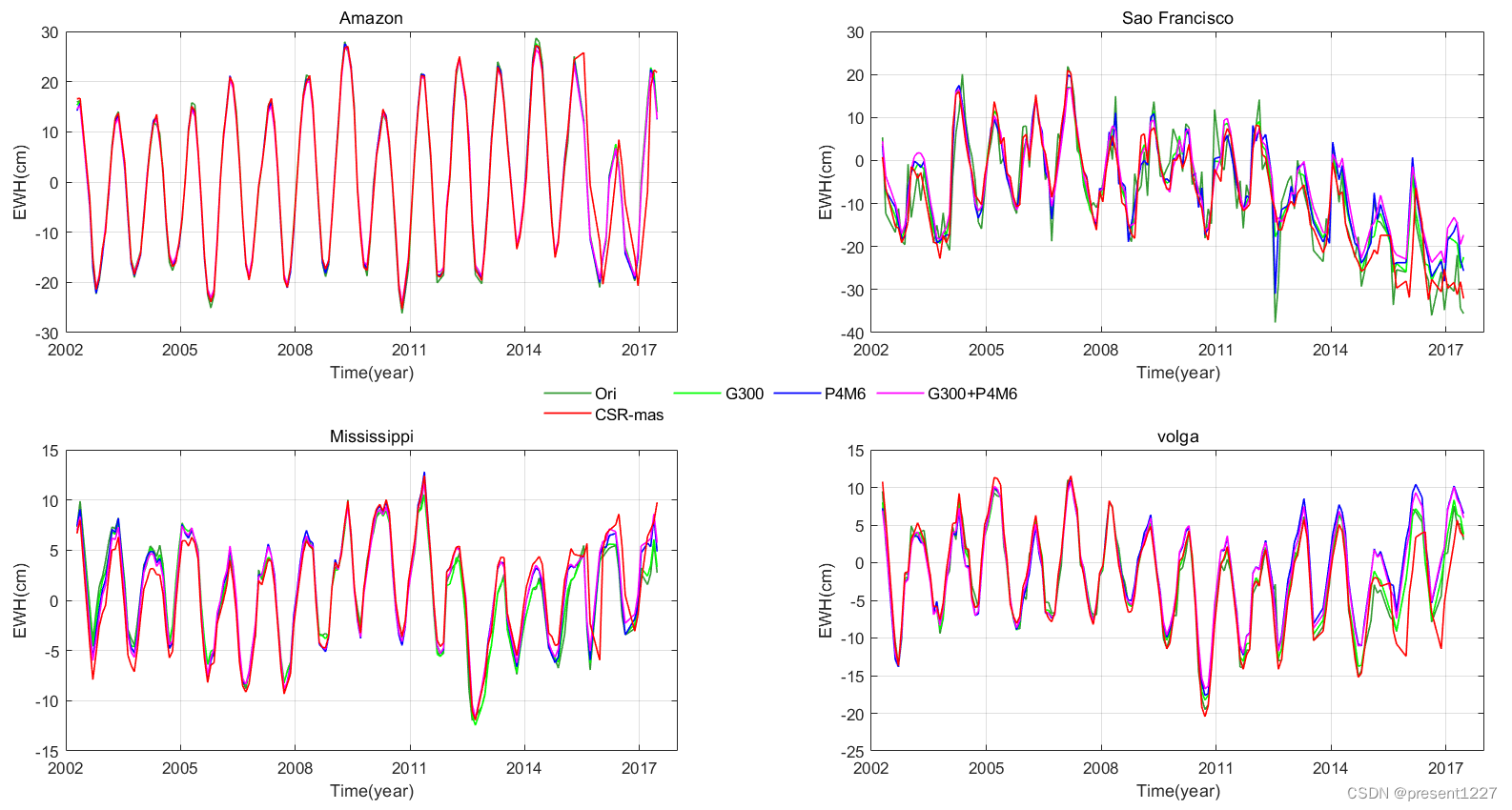
以CSR RL05球谐系数为例,生成无约束格网解(grid_CSR)、高斯300km滤波解(grid300_CSR)、去相关滤波解(gridP4M6_CSR)和组合滤波解(grid300P4M6_CSR),并以CSR mascon解(C_mas)作为参考。所有解的结果和时间指标“time.mat”变量均已放入文末百度网盘,可自行下载使用,欢迎评论或私信交流,谢谢。
clearvars -except
addpath E:\Data\result\grid
load C_mas.mat
load grid_CSR.mat;load grid300_CSR.mat;load gridP4M6_CSR.mat;load grid300P4M6_CSR.mat;
grid_mas=C_mas./100;
name{1,1}='_CSR';name{2,1}='300_CSR';
name{3,1}='P4M6_CSR';name{4,1}='300P4M6_CSR';name{5,1}='_mas';
k=size(name,1);
kk=1;
tic
for ii=1:12
switch ii
case 1
mask = 'E:\Data\Basin\Amazon.vec';rows=211;
[lon1,lat1] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 2
mask = 'E:\Data\Basin\Sao Francisco.vec';rows=87;
[lon2,lat2] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 3
mask = 'E:\Data\Basin\Mississippi.vec';rows=203;
[lon3,lat3] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 4
mask = 'E:\Data\Basin\volga.vec';rows=183;
[lon4,lat4] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 5
mask = 'E:\Data\Basin\Congo.vec';rows=181;
[lon5,lat5] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 6
mask = 'E:\Data\Basin\Yangtze.vec';rows=12191;
[lon6,lat6] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 7
mask = 'E:\Data\Basin\Ganges.vec';rows=91;
[lon7,lat7] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 8
mask = 'E:\Data\Basin\Indus.vec';rows=103;
[lon8,lat8] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 9
mask = 'E:\Data\Basin\Lake Eyre.vec';rows=107;
[lon9,lat9] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 10
mask = 'E:\Data\Basin\Murray.vec';rows=83;
[lon10,lat10] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 11
mask = 'E:\Data\Basin\Ob.vec';rows=233;
[lon11,lat11] = textread(mask,'%f %f','delimiter',',','headerlines',1);
case 12
mask = 'E:\Data\Basin\Danube.vec';rows=89;
[lon12,lat12] = textread(mask,'%f %f','delimiter',',','headerlines',1);
end
[dir_in,file_name{ii,1},file_type]=fileparts(mask);
for jj=1:k
grid_temp=eval(['grid' name{jj,1};]);
csr(:,jj) = gmt_grid2serie(100*grid_temp(:,:,1:197),mask,[],rows);
end
basin(:,kk:kk+k-1)=csr;kk=kk+k;
end
toc
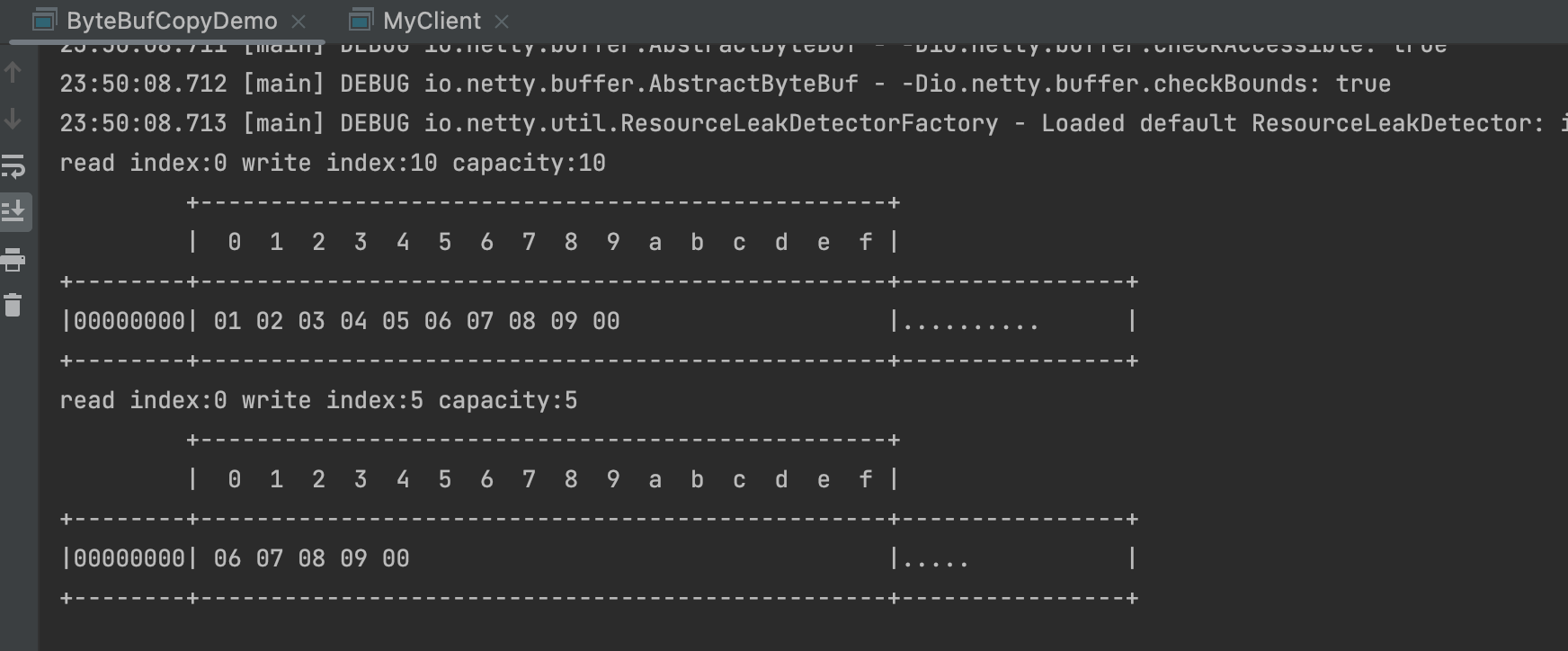
index1=1;index2=162; %%GRACE时间段的数据 GRACE-FO暂时没涉及
for Ser=1:12
for i=1:k-1
r=corrcoef(basin(index1:index2,k*(Ser-1)+i),basin(index1:index2,k*(Ser-1)+k)); R(Ser,i)=r(2,1);
RMSE(Ser,i)=sqrt(mean((basin(index1:index2,k*(Ser-1)+i)-basin(index1:index2,k*(Ser-1)+k)).^2));
end
end
close all;
th=1;
load E:\Code\GRACE_data\time.mat
figure(1)
for Ser=1:4
subplot(2,2,Ser)
plot(time(index1:index2),basin(index1:index2,k*(Ser-1)+1)','color',[0.2 0.6 0.2],'Linewidth',th);hold on;
plot(time(index1:index2),basin(index1:index2,k*(Ser-1)+2)','color',[0 1 0],'Linewidth',th);
plot(time(index1:index2),basin(index1:index2,k*(Ser-1)+3)','color',[0 0 1],'Linewidth',th);
plot(time(index1:index2),basin(index1:index2,k*(Ser-1)+4)','color',[1 0 1],'Linewidth',th);
plot(time(index1:index2),basin(index1:index2,k*(Ser-1)+5)','color',[1 0 0],'Linewidth',th);
ylabel('EWH(cm)','Fontname','Time New Roman');
title(file_name{Ser,1}(1,:),'FontName','Time New Roman','Fontsize',30);
xlabel('Time(year)','Fontname','Time New Roman');
xticks([2002 2005 2008 2011 2014,2017]);
if Ser==4
l1=legend('Ori','G300','P4M6','G300+P4M6','CSR-mas');set(l1,'box','off',"FontSize",10);
set(legend,...
'Orientation','horizontal',...
'NumColumns',4);
end
grid on;
end
链接:https://pan.baidu.com/s/1qXHvXZOG3lemffBmHfrKrQ
提取码:lrhx
![CLion2024 for Mac[po] C和C++的跨平台解代码编辑器](https://img-blog.csdnimg.cn/direct/17479a8bf98348d98d9d82f478edba5a.png)