前言:Hello大家好,我是小哥谈。为了解决建筑工地、隧道、煤矿等施工场景中现有安全帽检测算法对于小目标、密集目标以及复杂环境下的检测精度低的问题,设计实现了一种基于YOLOv5的改进目标检测算法,记为YOLOv5-GBCW。首先使用Ghost卷积对骨干网络进行重构,使得模型的复杂度有了显著降低;其次使用双向特征金字塔网络(BiFPN)加强特征融合,使得算法对小目标准确率提升;引入坐标注意力(Coordinate attention)模块,能够将注意力资源分配给关键区域,从而在复杂环境中降低背景的干扰;最后提出了WIoU作为边框损失函数,采用动态非单调聚焦机制并引入对锚框特征的计算,提升预测框的准确率,同时加速模型收敛。为了验证算法的可行性,以课题组收集的安全帽数据集为基础,选用了多种经典算法进行对比,并且进行了消融实验,探究各个改进模块的提升效果。实验结果表明:在复杂环境、密集场景和小目标场景下检测能力提升显著,并且同时满足安全帽检测精度和实时性的要求,给复杂施工环境下安全帽检测提供了一种新的方法。🌈
目录
🚀1.基础概念
🚀2.网络结构
🚀3.添加步骤
🚀4.改进方法
🍀🍀步骤1:common.py文件修改
🍀🍀步骤2:yolo.py文件修改
🍀🍀步骤3:创建自定义yaml文件
🍀🍀步骤4:修改自定义yaml文件
🍀🍀步骤5:验证是否加入成功
🍀🍀步骤6:更换损失函数
🍀🍀步骤7:修改默认参数
🍀🍀步骤8:实际训练测试
🚀5.实验分析
🍀🍀5.1 评价指标
🍀🍀5.2 消融实验

🚀1.基础概念
近几年来,作为机器学习领域的热点,深度学习在目标检测、图像识别、语义分割等应用十分广泛。目前,国内外学者也将深度学习技术应用于安全帽识别领域,相较于传统方法人工提取特征,深度学习能够利用卷积神经网络提取更加高层、有效的特征,极大地提高了安全帽识别的准确率和速度。基于深度学习的目标检测技术主要可以分为两类,一类是基于候选区域的两阶段(Two-stage)检测算法,另一类是基于回归的单阶段(One-stage)检测算法。
两阶段检测算法需要先用特征提取器生成一系列候选框,并从每个候选框中提取特征,然后再使用区域分类器进行预测,两阶段算法主要包括: RCNN、Faster RCNN、SPP-Net等。而单阶段算法能够通过只提取一次特征从而完成物体的分类和位置预测,结构简单并且检测速度快,目前,安全帽检测中常用的算法包括YOLO系列算法、SSD算法、RetinaNet算法等。
本文主要以课题组近年来收集的各大工地、煤矿、隧道场景下的图片以及网络爬取的相关照片为基础,自建数据集,在YOLOv5的基础上进行改进,使其在不同施工场景中对安全帽下有着更好的检测效果。
YOLO算法作为目标检测单阶段的代表算法,自2016年由Joseph Redmon提出之后,经过有关人员的不断研究,发展出诸多版本,并在工业界和学术界有着良好的应用场景。YOLOv5由Ultralytics公司于2020年提出,相较于YOLOv4,配置更加方便,训练与推理时间进一步缩短,准确率也得到了提升。而YOLOv5本身也在不断地更新迭代,本文使用的是v6.0的版本。YOLOv5通过修改深度和宽度两个缩放参数,可以得到五个不同大小的模型,分别是:YOLOv5n、5s、5m、5l、5x,模型大小依次增大,而准确率也在逐步提升。为了便于移动端设备以及边缘设备的部署,本研究采用兼顾速度和精度的YOLOv5s作为改进的基础模型。
基于GhostNet的主干提取网络重构:
YOLOv5网络模型中包含了较多的Conv卷积模块和C3模块,从而对输入图像进行特征提取、特征融合等操作,但是由于传统的卷积中存在着大量冗余的特征图,而特征图对模型的精度至关重要,在卷积过程中包含大量的网络参数,消耗了大量的计算资源,因此引入了Ghost卷积。Ghost卷积来自GhostNet,它将深层神经网络(DNN)中的一个普通卷积层分成两部分。首先通过普通卷积生成少量特征图,然后使用一系列简单的线性操作应用于生成的特征图,从而生成Ghost特征图,这样能够高效地减少特征冗余,它 是一个运行更快,参数量更轻量化的模块。因此,本文以此为基础,使用Ghost卷积替换了YOLOv5的部分普通卷积,轻量化后的模型在保证不明显降低准确率的情况下,使得计算量和参数量大量减小,提升了网络的运行速度。
注意力机制的引入:
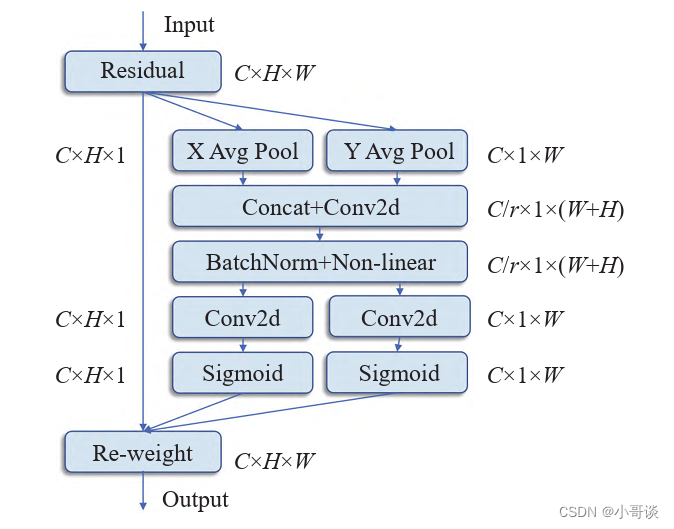
在本文检测任务中,工地、隧道施工环境复杂,在检测安全帽时容易受到复杂背景的干扰,在原YOLOv5模型算法中易被遗漏,为了提升安全帽的检测精度,所以引入注意力机制。注意力机制(Attention mechanism) 类似于人眼的视觉注意力机制,能够在繁杂的全局图像中确定关键的区域,之后对该区域投入更多的注意力资源,从而获取更多有价值的细节信息,忽视背景信息的干扰。通过这种机制,能够在计算资源有限的条件下,将算力分配给重要的任务,从而提高任务处理的效率。在目标检测任务中,注意力机制也能起到效果,能够帮模型更好地聚焦关键特征,并且削弱无关信息在特征图上的权重,从而提高识别准确率。本文引入了坐标注意力模块(Coordinate attention,CA), 注意力机制被分解为两个并行(x和y方向)的一维特征编码过程。通过这种方式,可以沿着一个方向捕获长距离的依赖关系,同时可以沿着另一个方向保留准确的位置信息,能够有效地将空间坐标信息聚集到生成的注意图中,CA注意力模块示意图如下图所示。
特征金字塔结构的改进:
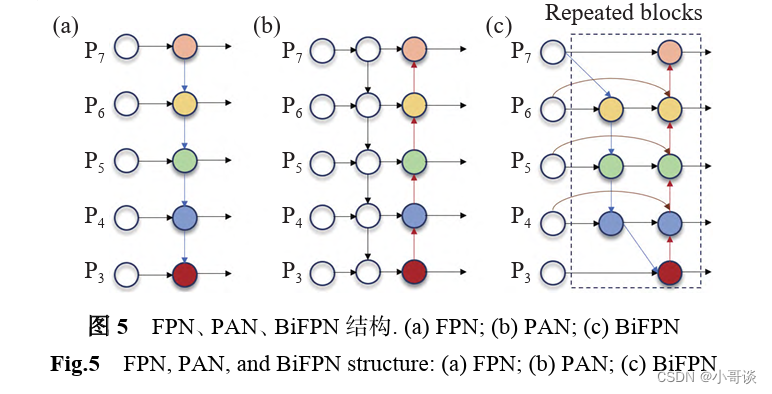
回顾一下YOLO系列的特征提取网络,YOLOv3中采用的是FPN结构,FPN是自上往下的,将高层特有的特征信息经过上采样的方法来进行特征融合,利用融合后得到的特征图进行预测,而这种结构难免会受到单项信息流的限制。而YOLOv4和v5采用的是改进后的PAN结构,在FPN层后添加了一个自下往上的特征金字塔,FPN层自上往下传达强语义的特征,而特征金字塔则自下往上传达强定位特征,可以提高预测精度。然而PAN是一个跨尺度的特征融合网络,在当它融合不同的输入特征时,只是做了一个简单的归纳,并对不同尺度的特征仍给予相同的关注。由于安全帽通常是较小尺寸,可视化信息少,难以提取到有鉴别力的特征,为了解决该问题,本研究将双向特征金字塔网络(Bi-directional feature pyramid network, BiFPN)作为新的多尺度特征提取网络,替换掉了YOLOv5原有的PAN结构。
双向特征金字塔网络如图所示,它是一种更为复杂的加权双向特征金字塔提取结构,该网络删除了PANet中只有一条输入边和输出边的低贡献结构节点,同时在同一尺度的输入节点到输出节点之间添加跃级连接,因此能够在不额外增加花销的同时融合更多的特征,并且BiFPN构建了带有自学习权重的特征融合模块,每一个模块包括双向(自顶向下和自底向上)路径的特征网络层,可以通过重复块的不断堆叠来进行更高级别的特征融合。
损失函数的改进:
原YOLOv5损失函数由定位损失函数—CIoU loss、分类损失函数以及目标置信度损失函数 —BCE loss三者构成,而目标检测中的目标定位是 一项重要的任务,优秀的边界框损失函数可以帮助算法有效地训练并获得最佳权重,从而提高算法收敛速度和精确率。因此,在训练算法时选择一个适当的损失函数对于目标定位任务至关重要。在YOLOv5模型中,使用CIoU损失函数进行边界框回归,在损失值计算过程中考虑预测框与真实框的高宽比,有效解决了不重叠情况下为边界框提供移动方向的问题。然而,由于CIoU损失函数将所有损失变量作为整体进行计算,可能导致收敛速度慢、不稳定等现象,并且还未能考虑难易样本的不平衡问题。而在本次安全帽检测中存在着如遮挡、密集目标的难分类样本,因此直接采用CIoU损失函数检测效果不佳。针对该问题,本文提出了WIoU损失函数。
🚀2.网络结构
本文的改进是基于YOLOv5-6.0版本,关于其网络结构具体如下图所示:
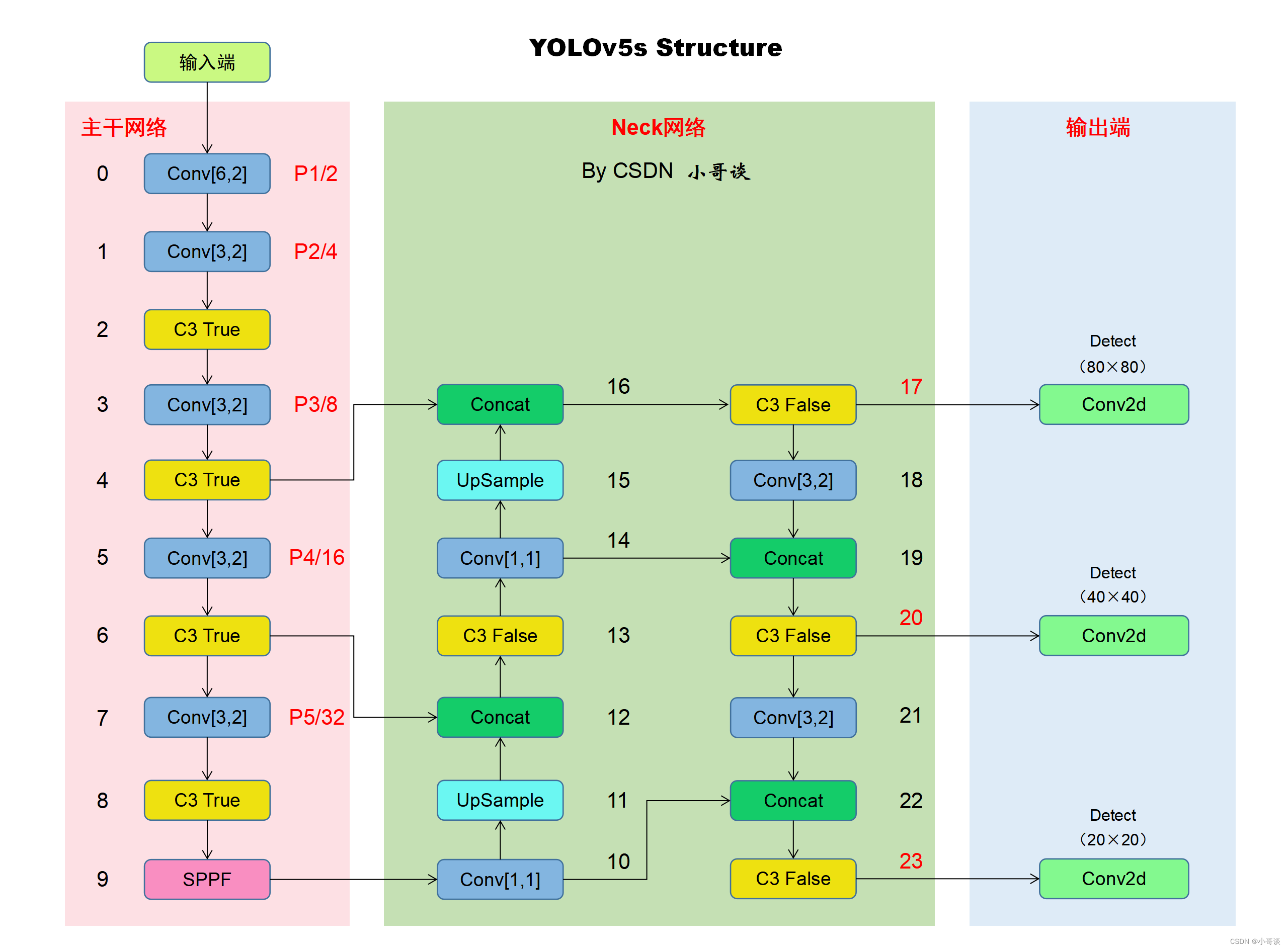
经过改进后的网络结构图如下所示:

🚀3.添加步骤
针对本文的改进,具体步骤如下所示:👇
步骤1:common.py文件修改
步骤2:yolo.py文件修改
步骤3:创建自定义yaml文件
步骤4:修改自定义yaml文件
步骤5:验证是否加入成功
步骤6:更换损失函数
步骤7:修改默认参数
步骤8:实际训练测试
🚀4.改进方法
🍀🍀步骤1:common.py文件修改
在common.py中添加CA注意力机制和BiFPN模块代码,所要添加模块的代码如下所示,将其复制粘贴到common.py文件末尾的位置。
# CA注意力机制
# By CSDN 小哥谈
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
# c*1*W
x_h = self.pool_h(x)
# c*H*1
# C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
# C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
# 更换Neck网络之BiFPN
# By CSDN 小哥谈
# 更换Neck网络之BiFPN
# 两个特征图add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个特征图add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
🍀🍀步骤2:yolo.py文件修改
在yolo.py文件中找到parse_model函数,在下图中所示位置添加CoordAtt,并且添加下列代码:
# 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])具体添加位置如下图所示:

🍀🍀步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为:yolov5s_helmet.yaml。具体如下图所示:

🍀🍀步骤4:修改自定义yaml文件
本步骤是修改yolov5s_helmet.yaml,根据改进后的网络结构图进行修改。
修改后的完整yaml文件如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# By CSDN 小哥谈
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]], # 2
[-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]], # 4
[-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]], # 6
[-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]], # 8
[-1, 1, CoordAtt, [1024]], # 9
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 BiFPN head
head:
[[-1, 1, GhostConv, [512, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 12
[[-1, 6], 1, BiFPN_Add2, [256,256]], # 13 cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, GhostConv, [256, 1, 1]], # 15
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 16
[[-1, 4], 1, BiFPN_Add2, [128,128]], # 17 cat backbone P3
[-1, 3, C3, [256, False]], # 18
[-1, 1, GhostConv, [512, 3, 2]], # 19
[[-1, 14, 6], 1, BiFPN_Add3, [256,256]], # 20
[-1, 3, C3, [512, False]], # 21
[-1, 1, GhostConv, [512, 3, 2]], # 22
[[-1, 11], 1, BiFPN_Add2, [256,256]], # 23 cat head P5
[-1, 3, C3, [1024, False]], # 24
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
🍀🍀步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_helmet.yaml。
修改1,位置位于yolo.py文件165行左右,具体如图所示:

修改2,位置位于yolo.py文件363行左右,具体如下图所示:
配置完毕之后,点击“运行”,结果如下图所示:

🍀🍀步骤6:更换损失函数
修改1,将utils/metrics.py文件中的下列代码:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU
更换成:
class WIoU_Scale:
''' monotonous: {
None: origin v1
True: monotonic FM v2
False: non-monotonic FM v3
}
momentum: The momentum of running mean'''
iou_mean = 1.
monotonous = False
_momentum = 1 - 0.5 ** (1 / 7000)
_is_train = True
def __init__(self, iou):
self.iou = iou
self._update(self)
@classmethod
def _update(cls, self):
if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \
cls._momentum * self.iou.detach().mean().item()
@classmethod
def _scaled_loss(cls, self, gamma=1.9, delta=3):
if isinstance(self.monotonous, bool):
if self.monotonous:
return (self.iou.detach() / self.iou_mean).sqrt()
else:
beta = self.iou.detach() / self.iou_mean
alpha = delta * torch.pow(gamma, beta - delta)
return beta / alpha
return 1
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, SIoU=False, EIoU=False, WIoU=False, Focal=False, alpha=1, gamma=0.5, scale=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
if scale:
self = WIoU_Scale(1 - (inter / union))
# IoU
# iou = inter / union # ori iou
iou = torch.pow(inter/(union + eps), alpha) # alpha iou
if CIoU or DIoU or GIoU or EIoU or SIoU or WIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU or EIoU or SIoU or WIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = (cw ** 2 + ch ** 2) ** alpha + eps # convex diagonal squared
rho2 = (((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4) ** alpha # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha_ciou = v / (v - iou + (1 + eps))
if Focal:
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)), torch.pow(inter/(union + eps), gamma) # Focal_CIoU
else:
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)) # CIoU
elif EIoU:
rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2
rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2
cw2 = torch.pow(cw ** 2 + eps, alpha)
ch2 = torch.pow(ch ** 2 + eps, alpha)
if Focal:
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2), torch.pow(inter/(union + eps), gamma) # Focal_EIou
else:
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIou
elif SIoU:
# SIoU Loss https://arxiv.org/pdf/2205.12740.pdf
s_cw = (b2_x1 + b2_x2 - b1_x1 - b1_x2) * 0.5 + eps
s_ch = (b2_y1 + b2_y2 - b1_y1 - b1_y2) * 0.5 + eps
sigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)
sin_alpha_1 = torch.abs(s_cw) / sigma
sin_alpha_2 = torch.abs(s_ch) / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
rho_x = (s_cw / cw) ** 2
rho_y = (s_ch / ch) ** 2
gamma = angle_cost - 2
distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)
omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)
omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
if Focal:
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha), torch.pow(inter/(union + eps), gamma) # Focal_SIou
else:
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha) # SIou
elif WIoU:
if Focal:
raise RuntimeError("WIoU do not support Focal.")
elif scale:
return getattr(WIoU_Scale, '_scaled_loss')(self), (1 - iou) * torch.exp((rho2 / c2)), iou # WIoU https://arxiv.org/abs/2301.10051
else:
return iou, torch.exp((rho2 / c2)) # WIoU v1
if Focal:
return iou - rho2 / c2, torch.pow(inter/(union + eps), gamma) # Focal_DIoU
else:
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
if Focal:
return iou - torch.pow((c_area - union) / c_area + eps, alpha), torch.pow(inter/(union + eps), gamma) # Focal_GIoU https://arxiv.org/pdf/1902.09630.pdf
else:
return iou - torch.pow((c_area - union) / c_area + eps, alpha) # GIoU https://arxiv.org/pdf/1902.09630.pdf
if Focal:
return iou, torch.pow(inter/(union + eps), gamma) # Focal_IoU
else:
return iou # IoU
修改2,将utils/loss.py文件中的红框部分注释掉。
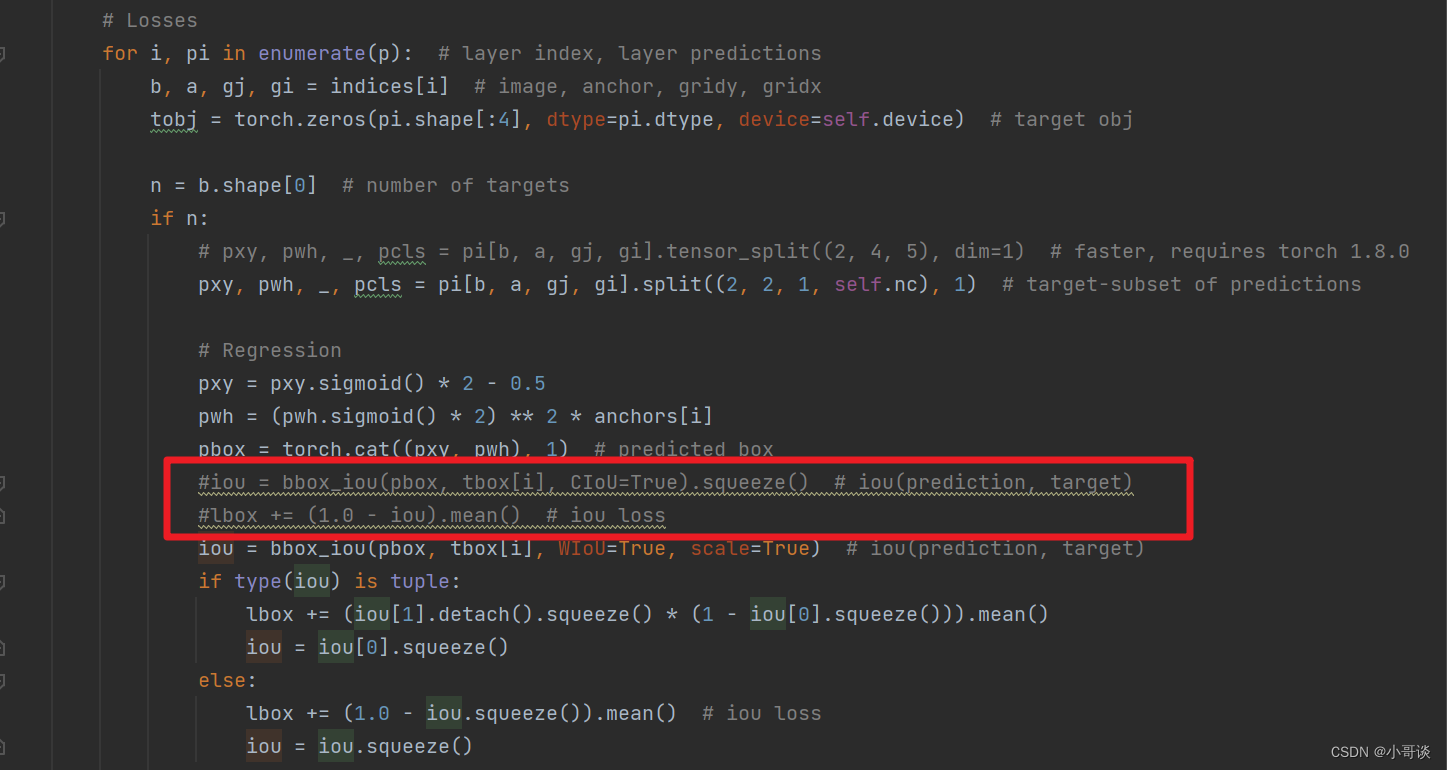
说明:上图中我已经注释掉。
然后将红框部分下面加入下列代码:
iou = bbox_iou(pbox, tbox[i], WIoU=True, scale=True) # iou(prediction, target)
if type(iou) is tuple:
lbox += (iou[1].detach().squeeze() * (1 - iou[0].squeeze())).mean()
iou = iou[0].squeeze()
else:
lbox += (1.0 - iou.squeeze()).mean() # iou loss
iou = iou.squeeze()🍀🍀步骤7:修改默认参数
修改1,设置可学习权重,将下列代码放置在train.py文件中(160行左右)
# 设置可学习权重
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
# hasattr: 测试指定的对象是否具有给定的属性,返回一个布尔值
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
g1.append(v.weight)
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)具体放置位置如下图所示:
修改2,在train.py文件中找到parse_opt函数,然后将第二行 '--cfg' 的default改为 ' models/yolov5s_helmet.yaml ',然后就可以开始进行训练了。🎈🎈🎈

🍀🍀步骤8:实际训练测试
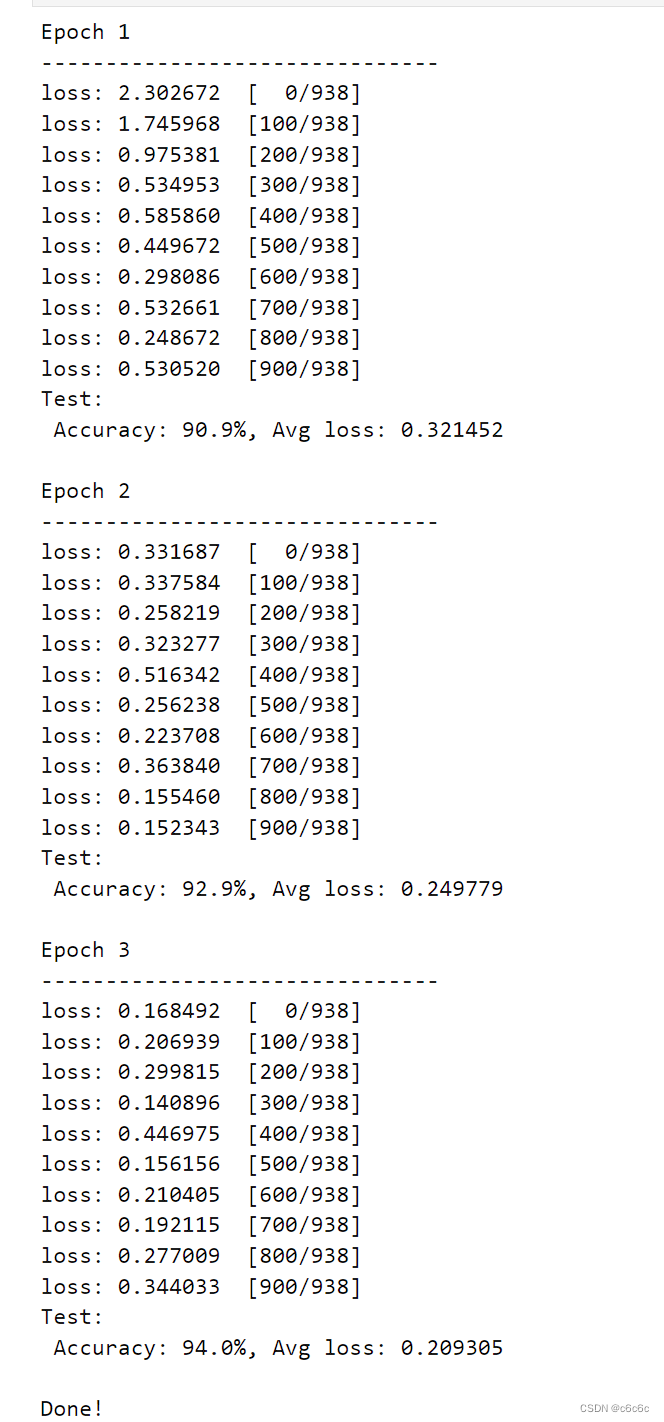
在本步骤中,parse_opt函数中的参数'--weights'采用的是yolov5s.pt,'--data'所采用的是helmet.yaml(作者提前创建的安全帽佩戴检测地址及分类信息,同学可自定义),然后设置'--epochs'为100轮。相关参数设置完毕后,点击运行train.py文件,没有发生报错,模型正常训练,具体如下图所示:👇

🚀5.实验分析
🍀🍀5.1 评价指标
目标检测任务中包括了目标分类和定位,主要可以从检测精度、检测速度和模型复杂度三方面来评估模型好坏,检测精度方面一般包含精确率(Precision)、召回率(Recall)、mAP@0.5、mAP@0.5: 0.95;检测速度方面包括每秒处理帧数(FPS);模型复杂度包括模型大小、参数量、计算量(GFLOPs)。在本文的检测分类任务中,需要识别的是已佩戴安全帽和未佩戴安全帽两种情况,可以看作二分类问题,把检测结果分为TP(真正例)、FN(假反例)、FP(假正例)、TN(真反例)四种情况。结合本次检测任务,TP表示实际佩戴安全帽被正确检测,FN表示实际佩戴安全帽却被错误识别成未佩戴,FP表示实际未佩戴安全帽却被检测成佩戴,TN表示未实际佩戴安全帽被正确检测。
精度方面,精确率表示是识别结果是正例中有多少是实际正例的比例,即查准率; 召回率表示原始样本中的实际正例有多少被预测正确的比例,即查全率。

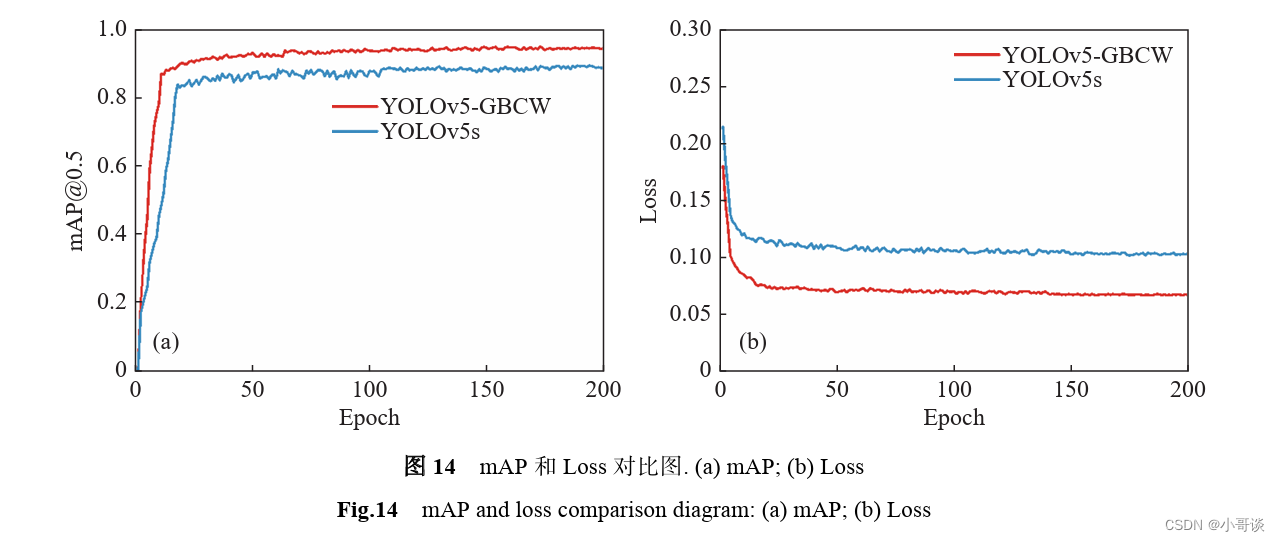
🍀🍀5.2 消融实验
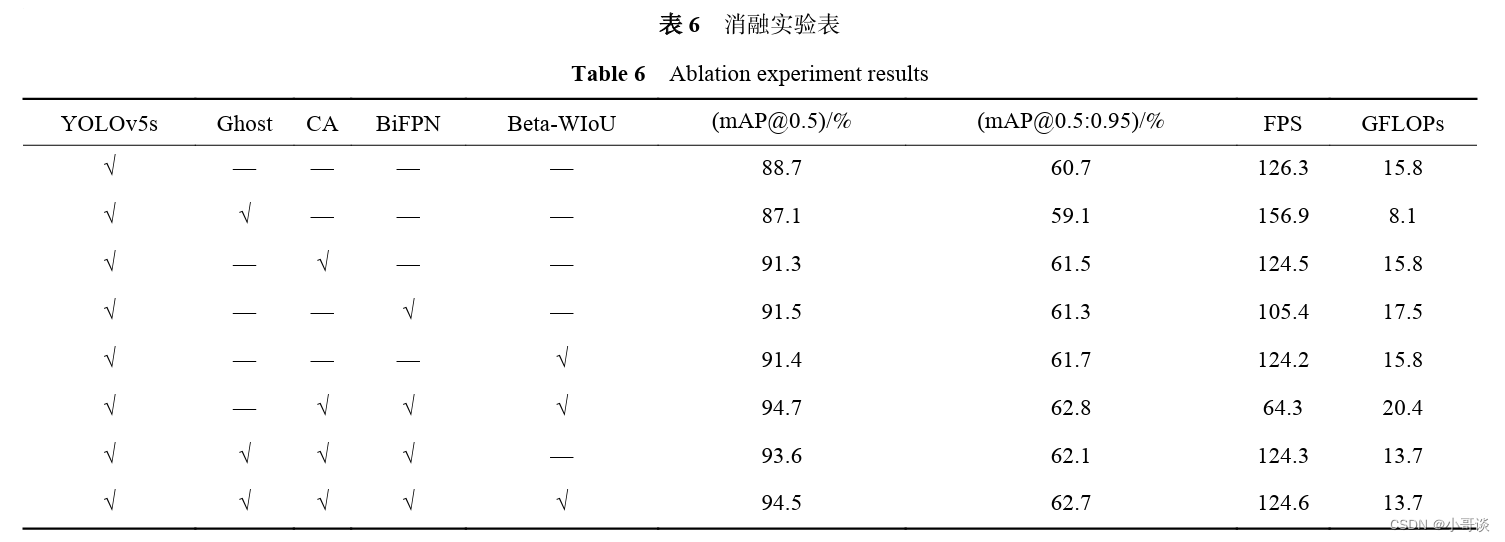
为了验证本文算法的检测性能,以及探究各个改进模块的提升效果,进行了消融实验,实验结果如表6所示,引入Ghost模块后,能够对模型进行轻量化,相比于原网络,计算量降低了44.3%,只有8.1GFLOPs,而精度只有轻微下降。而引入CA 模块后能够聚焦关键特征,mAP@0.5相对于原网络提高了2.6%,由于增加了模型的复杂性,FPS降低了1.8帧。引入BiFPN改进特征金字塔同样对精度有提升,mAP@0.5提升了2.8%,但FPS降低了10.9 帧。本文算法结合了各模块的优点,mAP@0.5达到 了94.5%,并且检测速度也达到了124.6 FPS,满足实时检测的要求。

说明:
本节课根据文章《基于改进YOLOv5的安全帽检测算法》进行代码实现,网络结构稍有修改。
作者:侯公羽、陈钦煌、杨振华、张又文、张丹阳、李昊翔
期刊:工程科学学报,第 46 卷,第 2 期:329−342,2024 年 2 月