在人类的日常交流中,模糊的代词如“他们”或“那个”常常出现,它们的意义通常依赖于上下文才能明确。这种上下文的理解对于对话助手来说至关重要,因为它们旨在提供一种自然的交流体验。然而,现有的对话助手在处理这类模糊引用时往往面临挑战。为了克服这一难题,苹果公司的研究者们提出了ReALM(Reference Resolution As Language Modeling),这是一种新型的大型语言模型(LLM),它专门针对引用解析问题进行了优化。ReALM通过将传统的多阶段流程转换为语言建模问题,不仅简化了处理流程,还在不同类型的引用解析任务上取得了显著的性能提升。
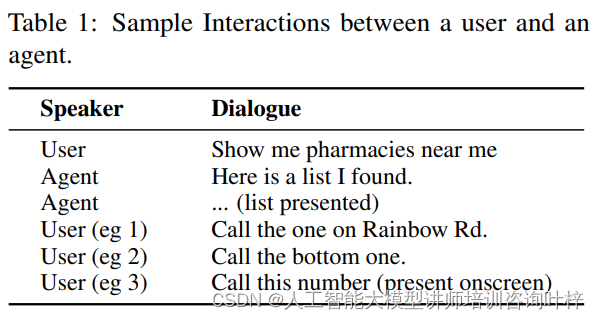
ReALM的提出,正是为了解决对话助手在理解用户屏幕上内容以及背景实体时面临的挑战。通过创新的算法,ReALM能够将屏幕上的实体及其位置编码为文本,即使没有视觉输入,也能使LLM“看到”屏幕上的内容,从而在对话中准确捕捉用户的意图。
尽管传统的引用解析系统在对话和视觉/指示引用方面已经取得了一定的进展,但它们在处理屏幕上的引用时仍然存在不足。ReALM通过将屏幕上的实体转换为文本表示,为LLM提供了丰富的上下文信息,使得模型能够更好地理解用户的查询。
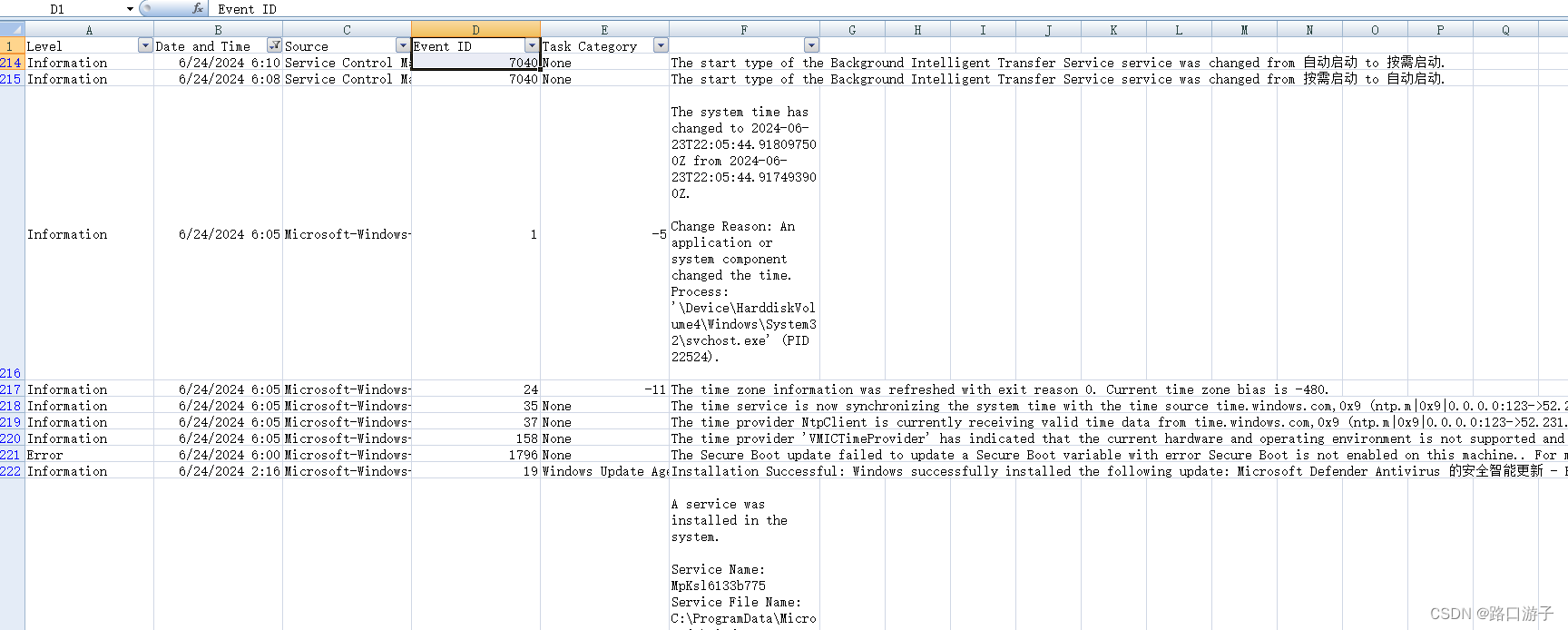
ReALM的核心任务是,基于给定的相关实体和用户想要执行的任务,提取与当前用户查询相关的实体。这些实体被分为三种类型:屏幕上的实体、对话中的实体和背景实体。屏幕上的实体可能包括用户正在查看的网页上的链接或电话号码;对话中的实体则来源于用户与虚拟助手之间的交流历史;而背景实体可能包括那些不在用户当前视野内,但与用户操作相关的信息,如后台运行的应用程序或服务。通过精确地识别和解析这些不同类型的实体,ReALM能够提供更加精准和自然的对话体验。
数据集
ReALM的数据集构建是实现其高效引用解析能力的关键。这些数据集由两部分组成:合成数据和注释者创建的数据。合成数据是通过自动化模板生成的,而注释者创建的数据则涉及到人工的参与和判断,两者共同为模型提供了丰富的学习和验证材料。
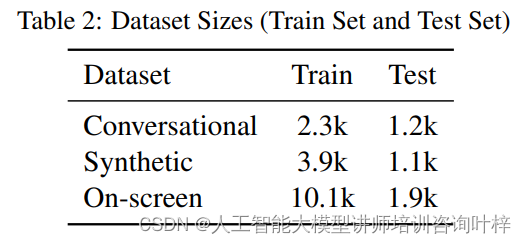
合成数据的生成过程利用了模板,这些模板定义了可能的用户查询和相关实体。模板中的占位符被动态替换为具体的实体信息,从而创造出各种可能的查询场景。这种方法在处理类型基础的引用时特别有效,因为用户查询和实体类型本身就足以解析引用,无需依赖额外的描述信息。合成数据的另一个优势在于它可以快速产生大量的训练样本,有助于模型学习并泛化到各种不同的上下文。
与合成数据相对的是注释者创建的数据,这一部分数据的生成过程需要人工对屏幕上的实体进行识别和分类。注释者会根据屏幕上显示的信息,如电话号码、电子邮件地址等,提供与之相关的用户查询。例如,如果屏幕上显示了一个商家列表,注释者可能会生成类似“请拨打列表中最后一个商家的电话号码”的查询。这种人工生成的数据有助于捕捉更自然、更多样化的语言使用模式,并确保模型能够处理真实世界中的复杂情况。
每个数据点都包含了用户查询和与之相关的实体列表,以及一个真值,即用户查询所指的正确实体或实体集。这些真值对于模型的训练至关重要,因为它们提供了反馈信号,帮助模型学习如何准确地识别和解析引用。
在收集对话数据时,注释者会根据提供的合成列表中的实体生成明确的查询。这些查询需要能够清晰地指向列表中的特定实体,例如,如果列表中包含一系列商家或闹钟,注释者需要构造出能够明确指向列表中特定商家或闹钟的查询语句。
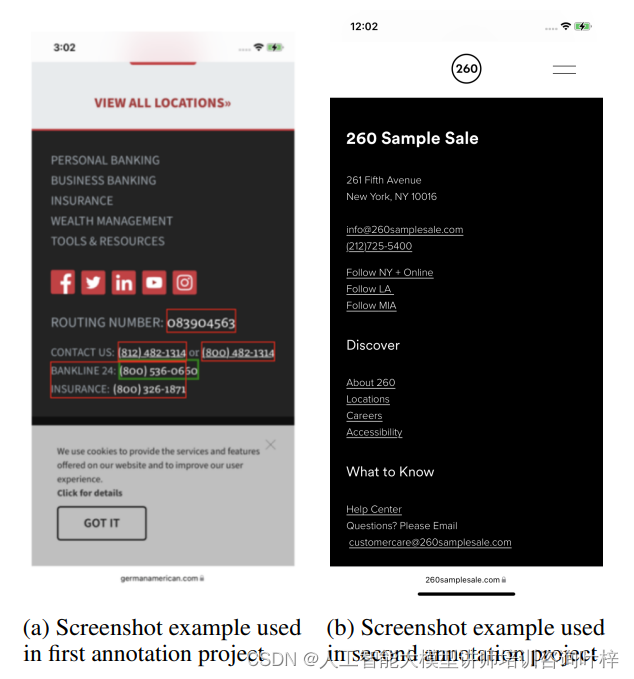
屏幕上的数据收集则更为复杂,它涉及到从网页上提取信息,并将这些信息作为实体与用户查询相关联。注释者需要根据屏幕上的截图,识别并分类信息,然后为这些信息提供独特的查询语句。在后续的注释项目中,注释者需要根据第一阶段收集的查询和对应的截图,判断查询是否自然,并且是否引用了屏幕上的某个实体,同时还需要从列表中识别出查询所指的实体,并标记出查询中引用该实体的部分。
模型
ReALM模型的竞争对手:两种基线方法,它们为ReALM的评估提供了基准。这两种方法包括基于MARRS的重新实现和基于ChatGPT的模型,它们各自代表了不同的技术和方法论。
MARRS是一种专门为引用解析任务设计的系统,由Ates等人在2023年提出。它代表了一种非LLM的方法,即它不依赖于大型语言模型来处理引用解析。MARRS的设计考虑了引用解析的特定需求,包括对不同类型的引用进行分类和解析。在ReALM的研究中,MARRS作为一个重要的参照点,帮助研究者们评估新模型相对于传统方法的优势和不足。
ChatGPT,包括其GPT-3.5和GPT-4变体,是另一种基线方法。这些模型以其强大的语言理解和生成能力而闻名,它们能够通过上下文学习来预测和生成文本。在ReALM的研究中,研究者们使用ChatGPT的这两个变体来探索大型预训练语言模型在引用解析任务上的表现。特别是,GPT-4的图像理解能力使其在处理屏幕上的引用时具有潜在的优势,因为它能够将视觉信息与文本信息结合起来进行决策。
与前两种方法不同,ReALM采用了一种基于FLAN-T5模型的微调方法。这种方法的核心在于将用户查询和相应的实体转换为适合LLM训练的句子格式。通过在特定任务上继续训练预训练模型,以提高其在该任务上的性能。ReALM没有进行广泛的超参数搜索,而是使用了默认的微调参数,这有助于简化模型训练过程并保持其通用性。
对于每个数据点,包含用户查询和相应的实体列表,ReALM将这些信息转换成适合LLM处理的句子格式。这一步骤是至关重要的,因为它允许模型以一种结构化的方式接收输入,从而更好地理解和预测相关的实体。
ReALM区分了两种类型的引用:对话引用和屏幕引用。对话引用可能基于实体类型或描述性信息,而屏幕引用则依赖于屏幕上实体的位置和属性。
-
对话引用:ReALM假设对话引用可以是类型基础的或描述性的。类型基础的引用侧重于使用用户查询和实体类型来识别相关的实体,而描述性引用则使用实体的属性来唯一确定它。
-
屏幕引用:对于屏幕引用,ReALM提出了一种新颖的算法(见算法2),该算法通过解析屏幕上的实体及其位置,生成一个纯文本表示,这个表示在视觉上能够反映出屏幕内容,同时保留实体的相对空间位置。
ReALM使用了一个创新的方法来编码屏幕上的实体。算法首先识别屏幕上所有文本框的位置,然后根据这些位置对实体进行排序,先按垂直方向(从上到下),再按水平方向(从左到右)。通过这种方式,算法能够在文本中模拟屏幕上实体的空间布局。
在准备训练数据时,实体被随机打乱,以防止模型过度拟合到特定的实体位置。这种随机化确保了模型在预测时不会依赖于实体在列表中的特定顺序。

通过这些步骤,ReALM模型不仅能够有效地解析对话中的引用,还能够理解和解析屏幕上的视觉信息,使其成为一个全面且强大的引用解析系统。这种方法的创新之处在于它将传统的文本处理任务扩展到了多模态领域,展示了LLM在理解复杂上下文方面的巨大潜力。
结果
在评估ReALM模型的性能时,研究者们通过一系列实验,展示了其在不同数据集上的表现,并与其他基线方法进行了比较。这些数据集包括对话数据集、合成数据集和屏幕数据集,以及一个针对未见过领域的测试集。
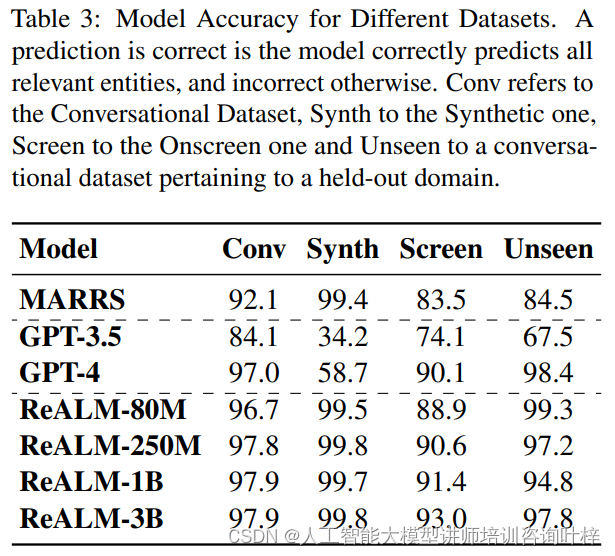
ReALM模型在所有类型的数据集上均展现出了卓越的准确性。在对话数据集上,ReALM的准确度达到了96.7%,而在合成数据集上,准确度更是高达99.5%。在屏幕数据集上,ReALM也表现出色,准确度为88.9%。此外,即使在未见过的领域测试集上,ReALM也显示出了强大的泛化能力,准确度达到了99.3%。
与之相比,MARRS模型在对话数据集上的准确度为92.1%,在合成数据集上为99.4%,在屏幕数据集上为83.5%,在未见过的领域测试集上为84.5%。这表明,尽管MARRS在某些领域表现良好,但ReALM在所有领域都显示出了更高的性能。
GPT-3.5和GPT-4作为基线模型,其表现则各有不同。GPT-3.5在对话数据集上的准确度为84.1%,在合成数据集上为34.2%,在屏幕数据集上为74.1%,在未见过的领域测试集上为67.5%。而GPT-4在对话数据集上的准确度为97.0%,在合成数据集上为58.7%,在屏幕数据集上为90.1%,在未见过的领域测试集上为98.4%。这些结果表明,尽管GPT-4在某些方面与ReALM相当接近,但在屏幕数据集上,ReALM的性能显著优于GPT-4,尤其是在纯文本域中。
研究者们还探讨了模型大小对ReALM性能的影响。他们发现,随着模型大小的增加,所有数据集上的性能都有所提升。具体来说,ReALM-80M、ReALM-250M、ReALM-1B和ReALM-3B这几种不同大小的模型,在对话、合成和屏幕数据集上的准确度分别为96.7%/99.5%/88.9%、97.8%/99.8%/90.6%、97.9%/99.7%/91.4%和97.9%/99.8%/93.0%。这表明,更大的模型能够更好地捕捉数据中的复杂模式,尤其是在处理屏幕数据集时。
ReALM在新领域和特定领域查询上的性能同样不俗。作为一个案例研究,研究者们探索了ReALM在未见过的闹钟领域的零样本性能。结果显示,所有基于LLM的方法在这一测试集上的表现都优于MARRS模型。特别是ReALM和GPT-4在这一领域的性能非常相似,这表明ReALM能够很好地泛化到新的上下文中。
此外,ReALM在处理特定领域的查询时也显示出了其优势。例如,在处理与家庭自动化设备相关的查询时,ReALM能够更准确地识别出相关的实体,而GPT-4则可能因为缺乏特定领域的知识而无法正确解析。

综上所述,ReALM模型在引用解析任务上的表现非常出色,无论是在熟悉的领域还是在未见过的新领域。其性能的提升不仅得益于模型的规模,还得益于其创新的文本编码方法,这种方法使得ReALM能够在纯文本域中有效地处理屏幕上的实体。这些结果证明了ReALM作为一种实用的引用解析系统的巨大潜力,尤其是在需要在设备上本地运行以保证性能和隐私的应用场景中。尽管ReALM在编码屏幕上实体位置方面有效,但仍存在丢失信息的问题,未来可能需要探索更复杂的编码方法。
论文链接:https://arxiv.org/abs/2403.20329






![[MYSQL] MYSQL库的操作](https://img-blog.csdnimg.cn/direct/6abcbe72570746de8e5e908ef8beeb8d.png)