文章目录
- 前言
- 一、图像分割介绍
- 1.语义分割
- 2.实例分割
- 3.全景分割
- 二、常见数据集格式
- 1.PASCAL VOC
- 2.MS COCO
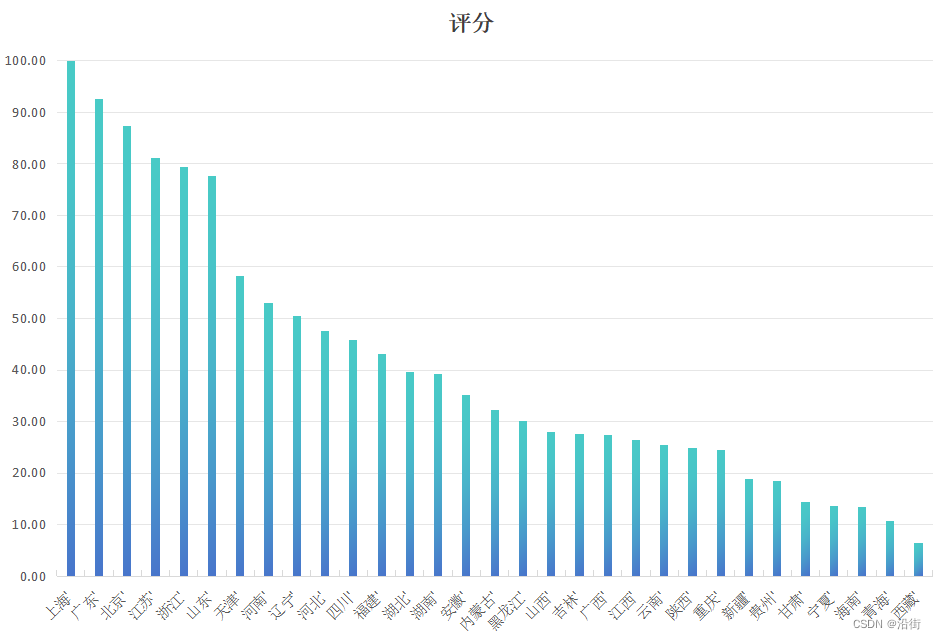
- 三、语义分割结果
- 四、语义分割常见评价指标
- 1.Pixel Accuracy
- 2.mean Accuracy
- 3.mean IoU
- 五、语义分割标注工具
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
一般在计算机视觉领域分割任务主要分为语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)、全景分割(Panoramic Segmentation)这三大类。这里主要介绍语义分割相关的内容,主要介绍语义分割的定义、常见数据集格式、语义分割评价指标和语义分割标注工具。
-
数据集(分类、目标检测、语义分割、实例分割)参考:
PASCAL VOC数据集
MS COCO数据集 -
分割标注工具参考:
Labelme(手工)
EISeg(半自动)
一、图像分割介绍
在深度学习方面图像分割可分为语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)、全景分割(Panoramic Segmentation)这三大类。
1.语义分割
语义分割(semantic segmentation)是对图像中每一个像素进行分类,其目的是将图像分割成多个不同类别信息的区域,每个区域表示一个特定的物体类别或者场景元素。
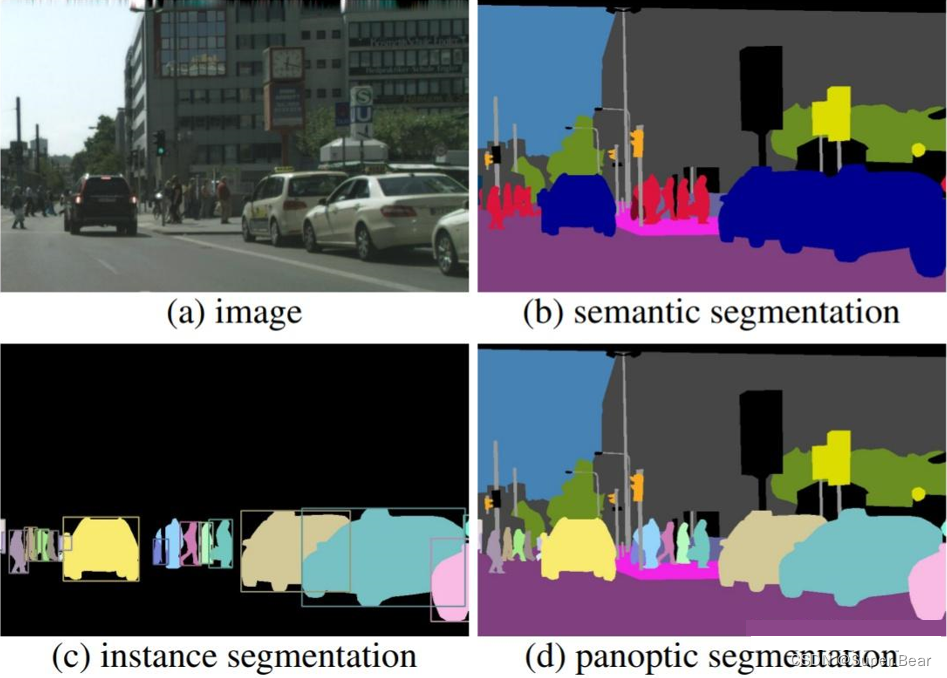
如图(b),语义分割将图像中的每一个像素分配到一个预定义的语义类别,如车,人,信号灯等。不同的类别在图像中使用不同的颜色或者标签表示。
2.实例分割
实例分割(instance segmentation)是在像素级别上识别和分割图像中的每个独立的实例或个体,是在语义分割的基础上将同类物体中的不同个体的像素区分开。它不仅区分不同的语义类别,而且对于同一类别的不同个体也进行了区分,即对图像中的每个物体实例进行单独的分割。因此,实例分割不仅在像素级别上标记不同类别,还为每个对象的每个像素分配独特的标签,使得每个对象都有自己唯一的标识。如图(c),实例分割将图中的每一辆汽车和行人进行分割,每一个对象都有自己的标签。
3.全景分割
全景分割(panoptic segmentation)是语义分割和实例分割的结合,在提供更全面的图像分割信息,不同于实例分割只对图像中的物体进行检测和分割,全景分割是对图中的所有物体包括背景都进行检测和分割。全景分割同时考虑图像中的每个像素,并将其分为两种类型:语义类别和实例对象,能够同时分类出不同类别的语义区域,并对每个对象进行个体级别的分割。如图(d),在全景分割中,图像中的每个像素不仅被标记为语义类别(汽车类和人),还会对每个实例(每辆汽车和每个人)进行独立的分割,并分配独特的标签。
通过上述对语义分割、实例分割和全景分割的描述,我们可以看出三者之间的联系与区别。它们之间的主要区别在于关注的对象和目标有所不同:语义分割主要关注图像中的大类别物体,是图像级别的分割结果,不考虑实例级别的区分;实例分割更进一步关注同一类物体中的不同个体,每个像素都属于特定的实例,即对象级别的分割;而全景分割则更进一步,将背景也纳入到关注的范围内。
二、常见数据集格式
这是主要参考如下资料:
PASCAL VOC数据集
MS COCO数据集
1.PASCAL VOC

PASCAL VOC中提供了分割数据集,数据集中的图片对应标签存储格式为PNG (如右图所示),标签图片中记录了每一个像素所属的类别信息。需要注意的是,右图所展示的图片是使用调色板实现的彩色,不同值的像素就对应不同的颜色,它本质上是一个单通道的黑白图片。
在语义分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处用的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据目标的类别索引信息进行填充,比如人对应的目标索引是15,所以目标区域的像素值用15填充。如下图所示

类别索引与名称对应关系
{
"background": 0,
"aeroplane": 1,
"bicycle": 2,
"bird": 3,
"boat": 4,
"bottle": 5,
"bus": 6,
"car": 7,
"cat": 8,
"chair": 9,
"cow": 10,
"diningtable": 11,
"dog": 12,
"horse": 13,
"motorbike": 14,
"person": 15,
"pottedplant": 16,
"sheep": 17,
"sofa": 18,
"train": 19,
"tvmonitor": 20
}
2.MS COCO
MS COCO数据集针对图像中的每一个目标都记录了多边形坐标 (polygons)。在左边部分每两个数据组成一个坐标点,依次连接就得到目标,将一幅图像中的所有目标绘制出来就得到了右下角这幅图像。

三、语义分割结果
语义分割的结果是一张单通道的图片(彩色的原因是因为加上了调色板之后的效果)

四、语义分割常见评价指标
1.Pixel Accuracy
Pixel Accuracy(像素准确率),也称为Global Accuracy(全局准确率),是指通过预测正确的像素数量和总的像素数量之间的比例来计算的,用于衡量像素级别的分类准确率,其表达式如下:
P
i
x
e
l
A
c
c
u
r
a
c
y
(
G
l
o
b
a
l
A
c
c
)
=
∑
i
n
i
i
∑
i
t
i
Pixel Accuracy(Global Acc)=\frac{\sum_{i}^{} n_{ii}}{\sum_{i}^{} t_{i}}
PixelAccuracy(GlobalAcc)=∑iti∑inii
n i j n_{ij} nij:类别i被预测成类别j的像素个数
t i = ∑ j n i j t_{i}=\sum_{j}^{} n_{ij} ti=∑jnij:目标类别i的总像素个数(真实标签),即标注数据中类别i的像素总数量
2.mean Accuracy
mean Accuracy是指类别准确率的平均值,用于消除类别不平衡的影响。其公式如下所示:
m
e
a
n
A
c
c
u
r
a
c
y
=
1
n
c
l
s
⋅
∑
i
n
i
i
t
i
mean Accuracy = \frac{1}{n_{cls}}\cdot \sum_{i}^{}\frac{n_{ii}}{t_i}
meanAccuracy=ncls1⋅i∑tinii
n i j n_{ij} nij:类别i被预测成类别j的像素个数
t i = ∑ j n i j t_{i}=\sum_{j}^{} n_{ij} ti=∑jnij:目标类别i的总像素个数(真实标签),即标注数据中类别i的像素总数量
n c l s :目标类别个数 ( 包含背景 ) n_{cls}:目标类别个数(包含背景) ncls:目标类别个数(包含背景)
3.mean IoU
mean IoU是指每个类别交并比的平均值,其公式为
M
e
a
n
I
o
U
=
1
n
c
l
s
⋅
∑
i
n
i
i
t
i
+
∑
j
n
j
i
−
n
i
i
Mean IoU = \frac{1}{n_{cls}}\cdot \sum_{i}^{}\frac{n_{ii}}{t_i +\sum_{j}^{}n_{ji} -n_{ii}}
MeanIoU=ncls1⋅i∑ti+∑jnji−niinii
n i j n_{ij} nij:类别i被预测成类别j的像素个数
t i = ∑ j n i j t_{i}=\sum_{j}^{} n_{ij} ti=∑jnij:目标类别i的总像素个数(真实标签),即标注数据中类别i的像素总数量
n c l s :目标类别个数 ( 包含背景 ) n_{cls}:目标类别个数(包含背景) ncls:目标类别个数(包含背景)
j:其他类别的索引
语义分割中的mean IoU和目标检测中的IoU原理是一样,先计算每个类别的IoU再求平均,如下图
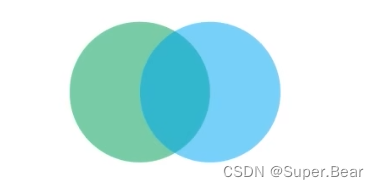
绿色表示为真实标签的分割图,蓝色表示为预测得到的分割图。
n i i n_{ii} nii:预测正确的部分,即相交部分
KaTeX parse error: Expected 'EOF', got '}' at position 6: t_{i}}̲:目标类别i的总像素个数(真实标签),即绿色圆的面积
∑ j n j i \sum_{j}^{}n_{ji} ∑jnji:预测的总像素,即蓝色原的面积
分母为并集部分,因为中间重复的部分计算两次,所以需要减掉中间预测正确的部分 n i i n_{ii} nii,以上就可以求出类别i的 IoU,之后计算所有的类别后除以总的类别数,就可以知道平均的IoU。
举例:通过构建混淆矩阵计算(Pytorch官方),以下图预测标签为例
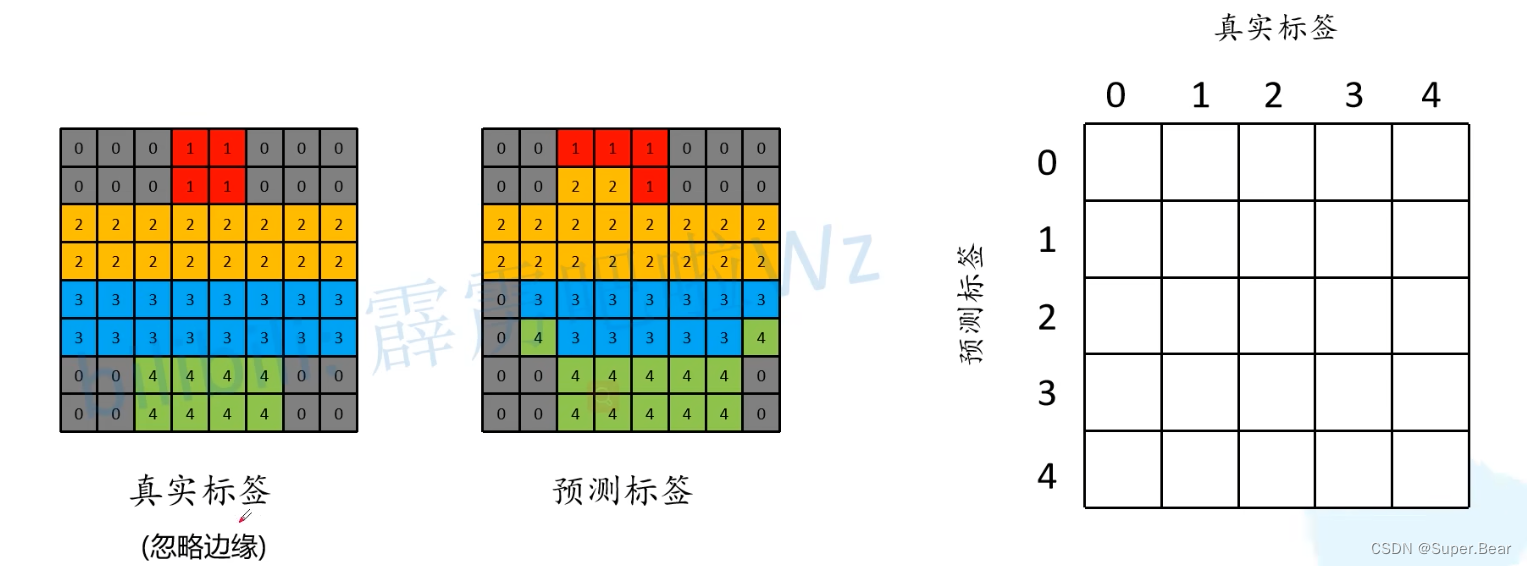
针对类别 0 :将所有真实标签中为 0 的位置都画成白色,非零的位置都设置为了灰色。同时将预测结果中所有预测为类别0(预测正确)的都画成绿色;预测错的位置用红色表示,如下图所示。
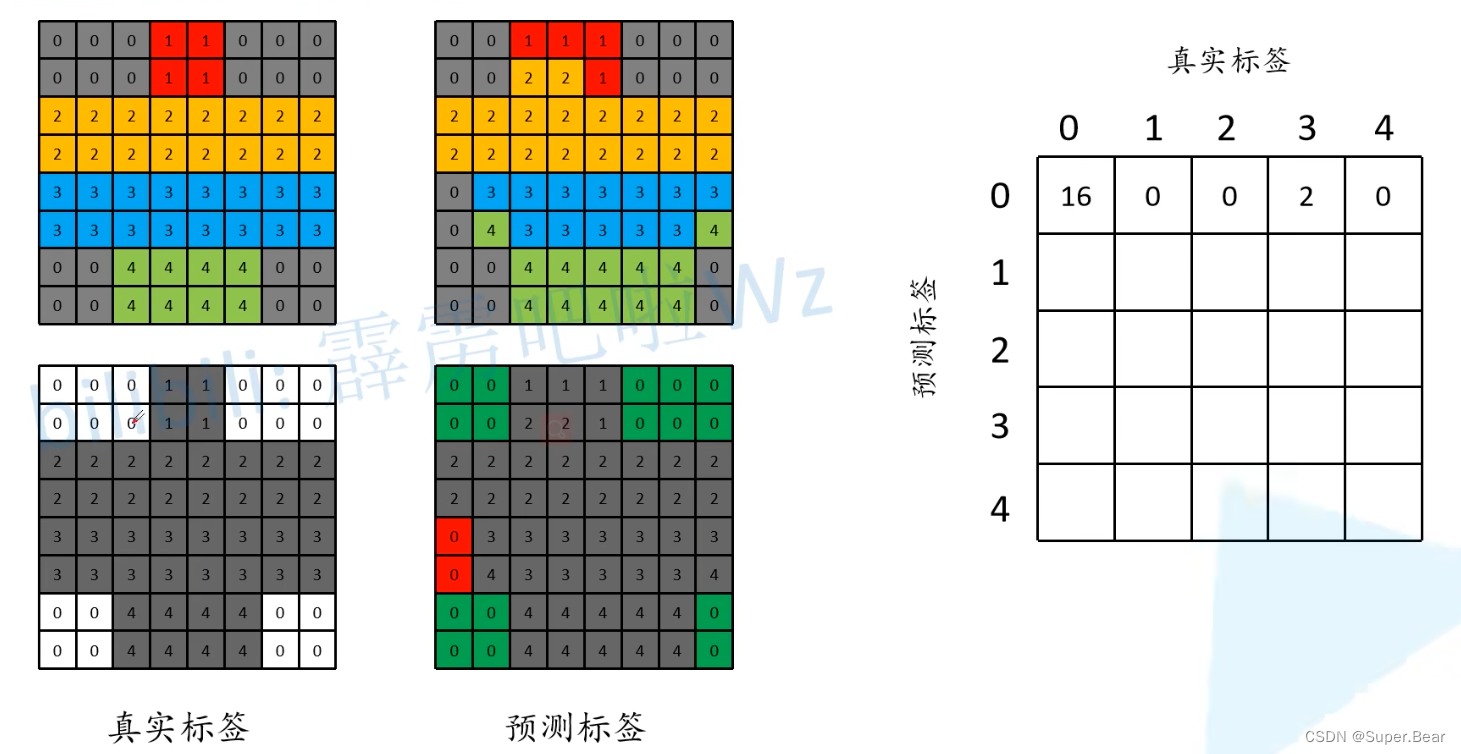
预测正确的像素值的数量即为图中绿色部分16,预测错误的数量为红色部分,其真实标签是3,所以在应该在混淆矩阵对应的位置填入16和3,如上图右边所示。依次类推,得到最终的混淆矩阵,如下图所示。
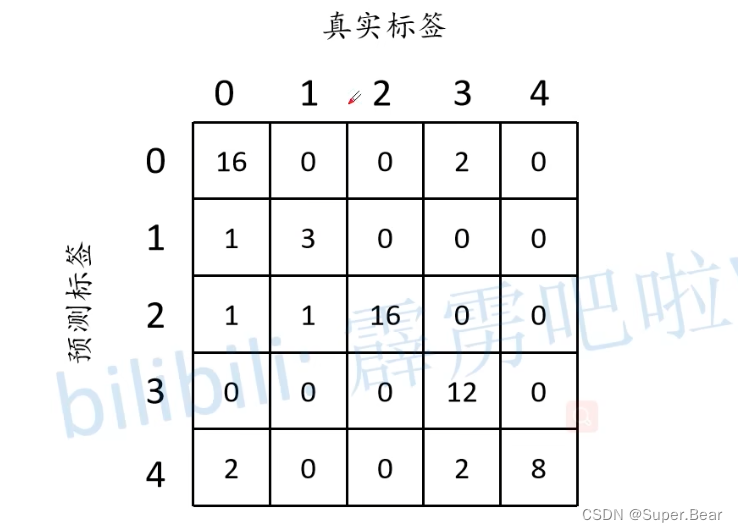
1.根据混淆矩阵得到像素准确度
G
l
o
b
a
l
A
c
c
u
r
a
c
y
=
16
+
3
+
16
+
12
+
8
64
≈
0.859
Global Accuracy = \frac{16+3+16+12+8}{64}\approx 0.859
GlobalAccuracy=6416+3+16+12+8≈0.859
2.根据每一个类别算出不同类别的Accuracy
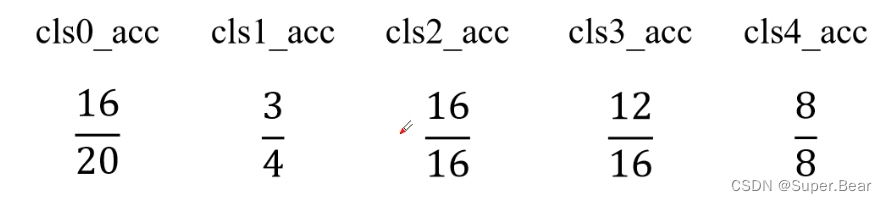
3.根据每一个类别算出不同类别的IoU

五、语义分割标注工具
分割标注工具下载:
Labelme(手工)
EISeg(半自动)
使用参考:
Labelme
EISeg
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。




![[MYSQL] MYSQL库的操作](https://img-blog.csdnimg.cn/direct/6abcbe72570746de8e5e908ef8beeb8d.png)