一、定义
- 强化学习微调分类
- RM模型 数据集格式
- 训练流程
- Reward 模型训练流程(分类模型,积极为1,消极为0) AutoModelForSequenceClassification
- Reward 模型训练案例
- PPO模型训练流程
- PPO模型训练案例
二、实现
-
强化学习微调分类
RLHF:基于人类反馈对语言模型进行强化学习, 分两步:
1. RM (Reward Model)奖励模型建模,构造人类偏好排序数据集,训练奖励模型,用来建模人类偏好。
2 RL(Reinforcement Learning)强化学习,用奖励模型来训练SFT模型,生成模型使用奖励或惩罚来更新其策略,以便生成更高质量、更符合人类偏好的文本.
DPO(Direct Preference Optimization): 直接偏好优化方法,DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好。
RLHF主要是进行对齐微调, 目标是将大语言模型的行为与人类的价值观或偏好对齐。
PPO: (Proximal Policy Optimization,近端策略优化)是一种在强化学习领域广泛使用的算法. -
RM模型 数据集格式
{conversations: [0:
{from:
"human",value: "国会的转发 美国国会由众议院和参议院组成,每两年换届一次(参议员任期为6年,但参议院选举是错位的。是更常见地转发国会议员还是来自国会外部?"}],
chosen: {from: "gpt",value: "计算推文的政党边际概率,我们可以使用以下代码这表明大多数转发不是来自国会议员,而是来自国会之外。"},
rejected: {from: "gpt",value: "回答问题的第(计算转发国会议员或来自国会以外的人的边际概率"}}
其中chosen 代表是好的回答, rejected代表的是不好的回答
-
训练流程
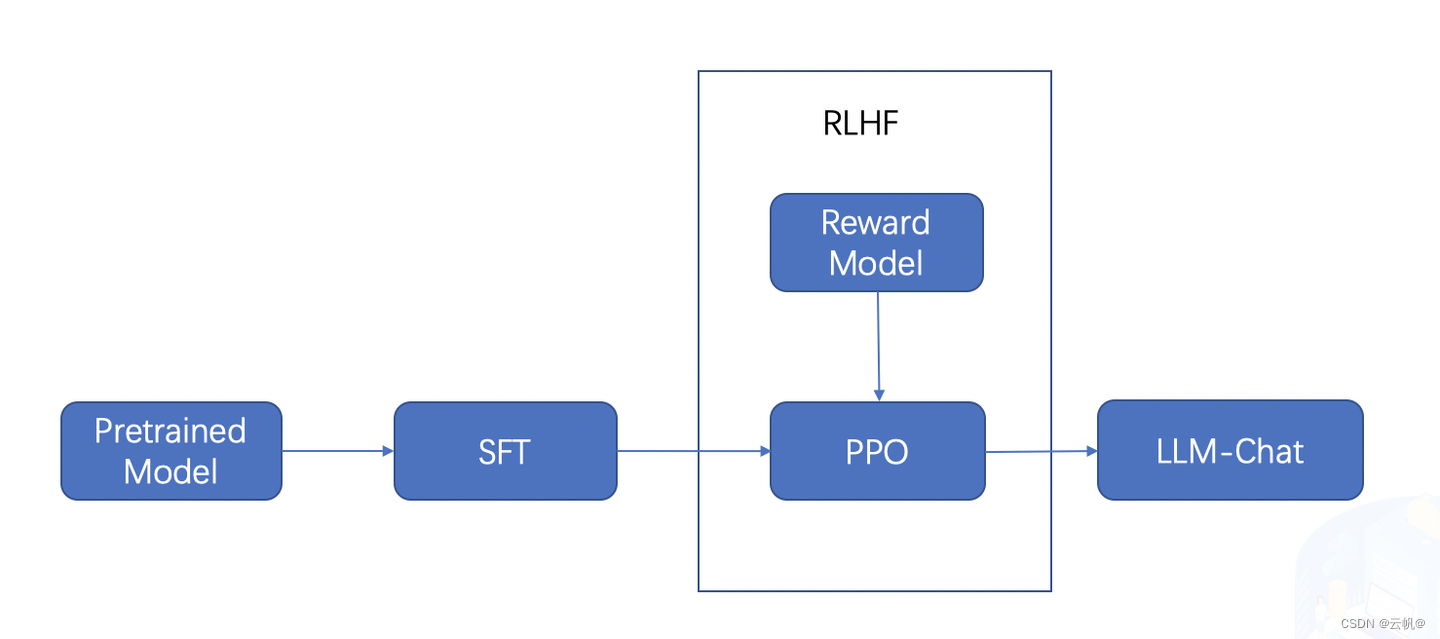
训练reward Model---->PPO模型 -
Reward 模型训练流程(激励模型为深度学习模型)
数据处理:
def preprocess_function(examples):
new_examples = {
"input_ids_chosen": [],
"attention_mask_chosen": [],
"input_ids_rejected": [],
"attention_mask_rejected": [],
}
for chosen, rejected in zip(examples["chosen"], examples["rejected"]):
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])
new_examples["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])
new_examples["input_ids_rejected"].append(tokenized_rejected["input_ids"])
new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])
return new_examples
训练求损失:AutoModelForSequenceClassification 分类模型
model = AutoModelForSequenceClassification.from_pretrained(
model_config.model_name_or_path, num_labels=1, **model_kwargs
)
def compute_loss(
self,
model: Union[PreTrainedModel, nn.Module],
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs=False,
) -> Union[torch.Tensor, Tuple[torch.Tensor, Dict[str, torch.Tensor]]]:
if not self.use_reward_data_collator:
warnings.warn(
"The current compute_loss is implemented for RewardDataCollatorWithPadding,"
" if you are using a custom data collator make sure you know what you are doing or"
" implement your own compute_loss method."
)
rewards_chosen = model(
input_ids=inputs["input_ids_chosen"],
attention_mask=inputs["attention_mask_chosen"],
return_dict=True,
)["logits"]
rewards_rejected = model(
input_ids=inputs["input_ids_rejected"],
attention_mask=inputs["attention_mask_rejected"],
return_dict=True,
)["logits"]
# calculate loss, optionally modulate with margin
if "margin" in inputs:
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected - inputs["margin"]).mean()
else:
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()
if return_outputs:
return loss, {
"rewards_chosen": rewards_chosen,
"rewards_rejected": rewards_rejected,
}
return loss
-
Reward 模型训练案例
https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py -
PPO模型训练流程

步骤:
1. 语言模型预测
2. 激活模型评估(分类模型),1 代表积极,0 代表消极
3. PPO算法优化。
数据:
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["review"])[: input_size()]
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
- 加载模型, 参考模型(参考模型可以为None)
# We then build the PPOTrainer, passing the model, the reference model, the tokenizer
ppo_trainer = PPOTrainer(ppo_config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator)
# Get response from gpt2 待训练的模型响应,参考模型响应
response_tensors, ref_response_tensors = ppo_trainer.generate(
query_tensors, return_prompt=False, generate_ref_response=True, **generation_kwargs
)
batch["response"] = tokenizer.batch_decode(response_tensors)
batch["ref_response"] = tokenizer.batch_decode(ref_response_tensors)
- 激活模型评估(分类模型),1 代表积极,0 代表消极
2. 获取激励值
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs) #激励函数
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs] #激励值
- PPO算法优化。
# 问题query 、 模型响应 、激励值
#其中上图优化模块,均在step 方法中实现。
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
step内部:
all_logprobs, logits_or_none, values, masks = self.batched_forward_pass(
self.model,
queries,
responses,
model_inputs,
response_masks=response_masks,
return_logits=full_kl_penalty,
)
with self.optional_peft_ctx():
ref_logprobs, ref_logits_or_none, _, _ = self.batched_forward_pass(
self.model if self.is_peft_model else self.ref_model,
queries,
responses,
model_inputs,
return_logits=full_kl_penalty,
)
- PPO模型训练案例
https://github.com/huggingface/trl/blob/main/examples/scripts/ppo.py