21. 如何评价分类模型的优劣?
(1)模型性能指标
-
准确率(Accuracy):
- 定义:正确分类的样本数与总样本数之比。
- 适用:当各类样本的数量相对均衡时。
-
精确率(Precision):
- 定义:预测为正类的样本中实际为正类的比例。
- 适用:当关注假阳性错误的成本较高时(例如垃圾邮件检测)。
-
召回率(Recall):
- 定义:实际为正类的样本中被正确预测为正类的比例。
- 适用:当关注假阴性错误的成本较高时(例如疾病检测)。
-
F1得分(F1 Score):
- 定义:精确率和召回率的调和平均数。
- 适用:当需要平衡精确率和召回率时。
-
ROC曲线(Receiver Operating Characteristic Curve)和AUC(Area Under the Curve):
- 定义:ROC曲线是以假阳性率为横轴、真正率为纵轴绘制的曲线,AUC是该曲线下的面积。
- 适用:用于评估模型在不同阈值下的表现。
-
PR曲线(Precision-Recall Curve)和AUC-PR:
- 定义:PR曲线是以召回率为横轴、精确率为纵轴绘制的曲线,AUC-PR是该曲线下的面积。
- 适用:特别适合于类别不平衡的情况。
(2)其他考虑因素
-
模型复杂度:
- 简单模型(如线性模型)易于理解和解释,但可能无法捕捉复杂的模式。
- 复杂模型(如深度神经网络)能够捕捉复杂模式,但可能难以解释和调试。
-
训练时间和推理时间:
- 训练时间:模型从数据中学习的时间。复杂模型通常需要更长的训练时间。
- 推理时间:模型进行预测的时间。在实时应用中,较短的推理时间是优点。
-
模型的可解释性:
- 可解释性:模型结果的透明度和理解度。在某些领域,如医疗和金融,可解释性是非常重要的。
-
鲁棒性和稳定性:
- 鲁棒性:模型应对噪声和异常值的能力。
- 稳定性:模型在不同的数据集或样本上的一致性表现。
(3)综合评价
-
交叉验证:
- 使用交叉验证(如k折交叉验证)可以更可靠地评估模型性能,减少过拟合的影响。
-
混淆矩阵:
- 通过混淆矩阵(Confusion Matrix)可以详细了解模型的分类错误类型,包括真阳性、真阴性、假阳性和假阴性。
-
业务目标和应用场景:
- 根据具体的业务目标和应用场景选择合适的评价指标和模型。例如,在医疗诊断中,召回率可能比准确率更重要。
(4)实际应用中的权衡
在实际应用中,通常需要在不同的评价指标之间进行权衡。例如:
- 在类别不平衡的情况下,更倾向于使用F1得分、AUC-PR等指标。
- 对于需要实时预测的应用,更关注模型的推理时间。
- 在高度监管的领域(如金融或医疗),模型的可解释性可能比纯粹的性能指标更重要。
22.如何评价回归模型的优劣 ?
-
均方误差(Mean Squared Error, MSE):
- 定义:预测值与实际值之间的平方差的平均值。
- 公式:

-
- 适用:当对较大的误差较为敏感时。
-
均方根误差(Root Mean Squared Error, RMSE):
- 定义:MSE的平方根。
- 公式:

- 适用:与MSE类似,但与原数据单位一致,更易于解释。
-
平均绝对误差(Mean Absolute Error, MAE):
- 定义:预测值与实际值之间绝对差的平均值。
- 公式:
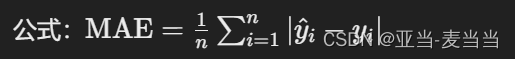
-
- 适用:当对所有误差同等看待时。
-
决定系数(R² Score):
- 定义:衡量模型解释数据变异的能力,取值范围为0到1。
- 公式:
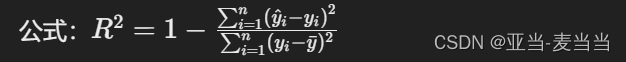
- 适用:反映模型的整体解释能力,但不适用于非线性关系或异方差性的情况。
-
调整决定系数(Adjusted R²):