同学们,今天我们来聊聊坐标注意力。
坐标注意力是一种非常高效的注意力机制,它通过将位置信息嵌入到通道注意力中,轻轻松松就能提高轻量级网络的性能。
这一机制的核心在于其创新的结构和对位置信息的精确捕捉能力,允许模型在强调特定通道的同时维持对空间位置的敏感度。且由于简单灵活,它还可以轻松嵌入到各种移动网络中,并在各种计算机视觉任务中取得很好的性能。
因此如果我们想在不增加太多计算成本的情况下提升模型表现,坐标注意力是个非常好的选择。当然,为方便有需求的同学们实践,我已经整理好的12个最新的坐标注意力创新方案分享给大家:
论文原文以及开源代码需要的同学看文末
Expression Recognition Based on Multi-Regional Coordinate Attention Residuals
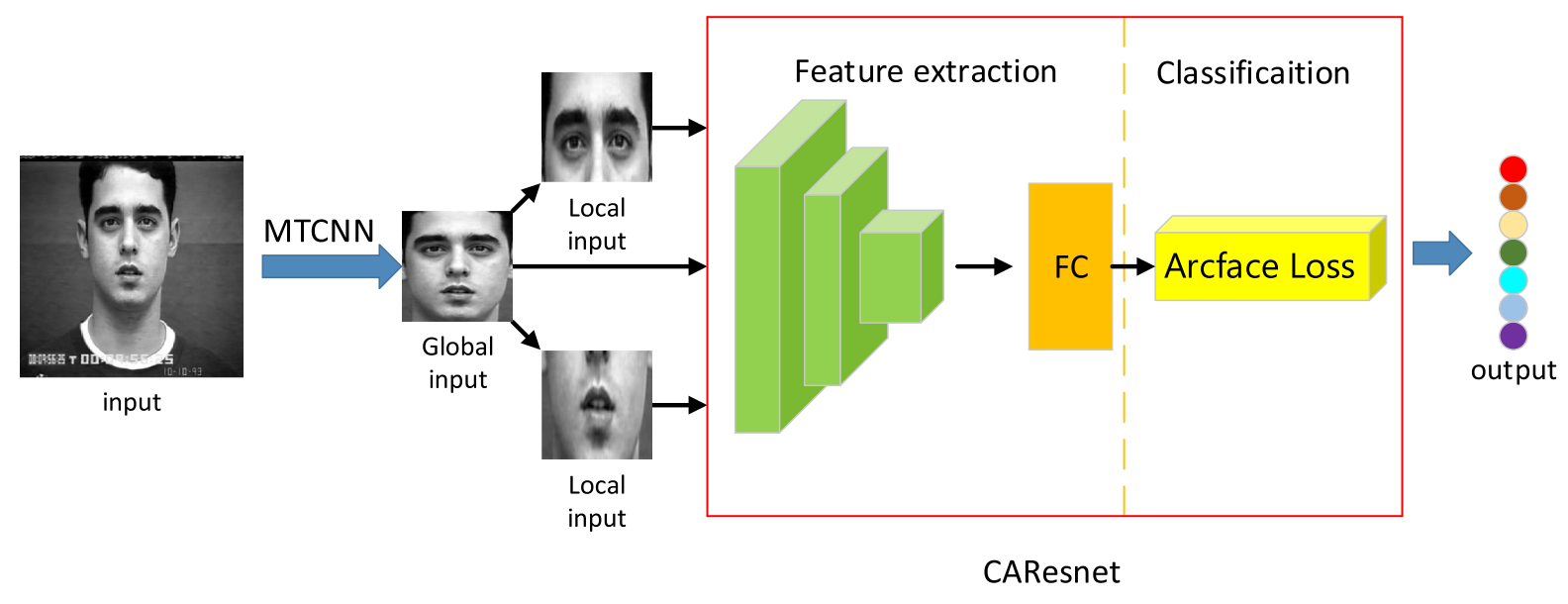
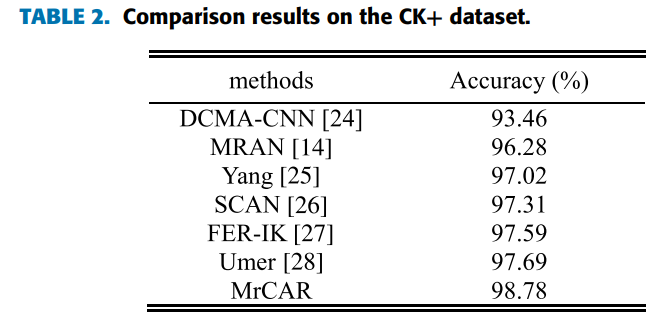
方法:本文介绍了一种基于多区域坐标注意力残差的面部表情识别模型(MrCAR),通过多区域输入、坐标注意力残差网络和Arcface Loss分类器,提高了面部表情的识别准确率。
创新点:
-
提出了多区域输入方法,通过MTCNN进行面部检测和对齐处理,并进一步裁剪眼睛和嘴巴部分,以获得多区域图片。通过多区域输入,更容易获取局部细节和全局特征,减少复杂环境噪声的影响,突出面部特征。
-
在特征提取模块中引入了坐标注意力残差网络,通过添加CA-Net和多尺度卷积,提取关键特征,并提高了模型对表情细微变化的区分能力和关键特征的利用率。
-
使用Arcface Loss作为分类器,同时增强类内紧密度和类间差异,从而减少模型对负面表情的错误分类。
Large coordinate kernel attention network for lightweight image super-resolution
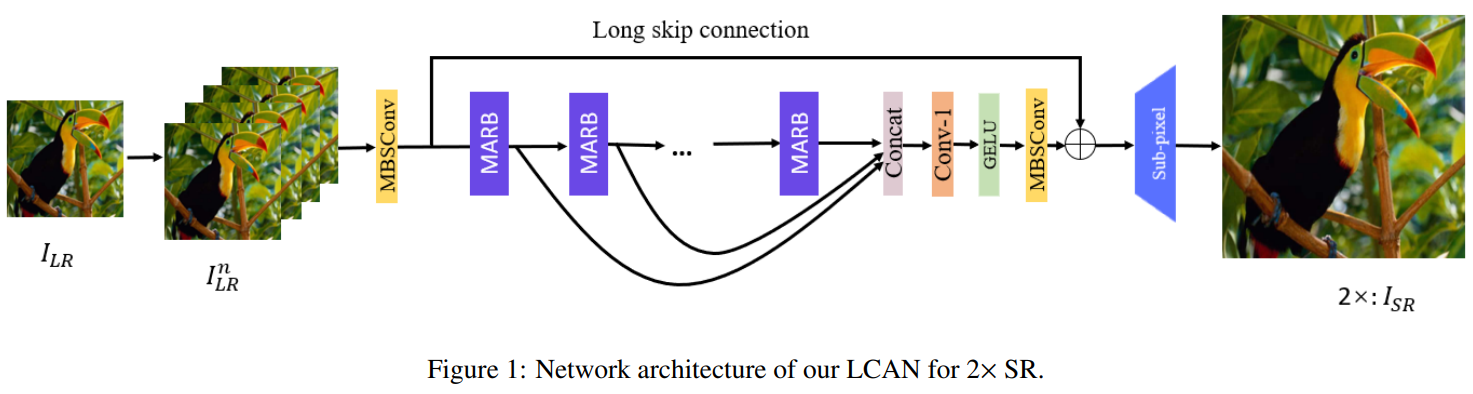
方法:本论文的研究目标是设计一种高效的单图像超分辨率网络,通过引入多尺度蓝图可分离卷积(MBSConv)和局部坐标核注意力(LCKA)来提高模型的性能和效率,填补现有轻量级超分辨率方法在多尺度信息提取方面的研究空白。
创新点:
-
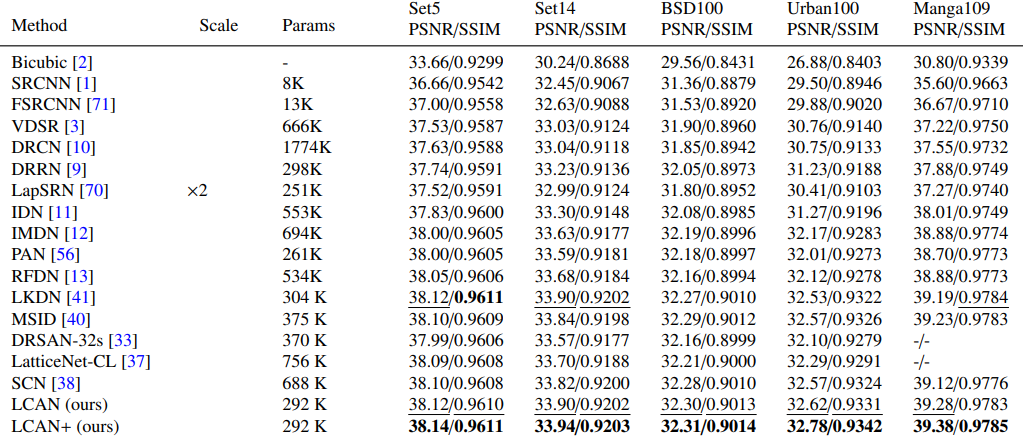
提出了大型坐标核注意力网络(LCAN),这是一种非常轻量级的SR模型,可以从低分辨率输入中恢复出高性能图像。LCAN比之前的轻量级SR网络更轻量级,同时实现了更优越的重建性能。
-
提出了大型坐标核注意力(LCKA)模块,该模块将LKA的2D卷积核分解为水平和垂直1D卷积核,从而实现了局部信息和远距离依赖的邻近直接交互。
YOLOv5s-CA: A Modified YOLOv5s Network with Coordinate Attention for Underwater Target Detection
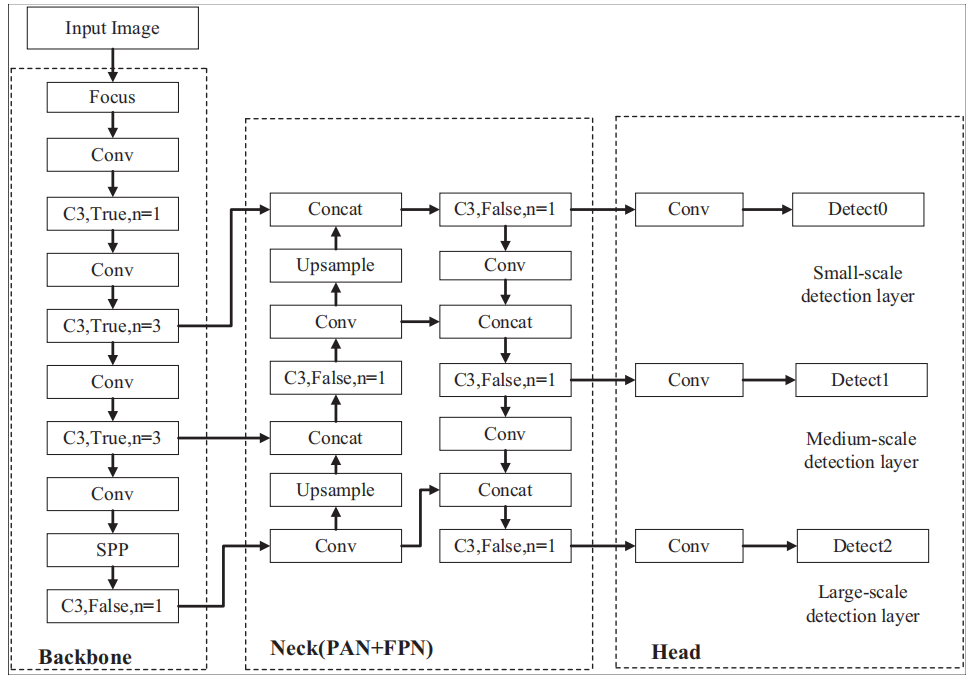
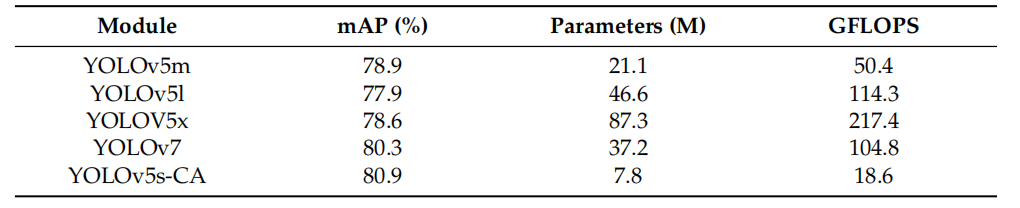
方法:研究通过对YOLOv5s模型进行改进,提出了YOLOv5s-CA模型,该模型添加了多个瓶颈层以提高浅层特征提取能力,并嵌入了CA注意力模块和SE注意力模块以提高模型对感兴趣区域的关注。
创新点:
-
对YOLOv5s模型进行了改进:引入了CA和SE模块,命名为YOLOv5s-CA,以提高水下目标检测的准确性。
-
修改了骨干网络:在YOLOv5s模型的合适位置嵌入了SE注意力模块,使模型能够根据卷积输入自适应调整通道权重,从而适应不同复杂特征图上的每个目标的特征提取。
A New Semantic Segmentation Method for Remote Sensing Images Integrating Coordinate Attention and SPD-Conv
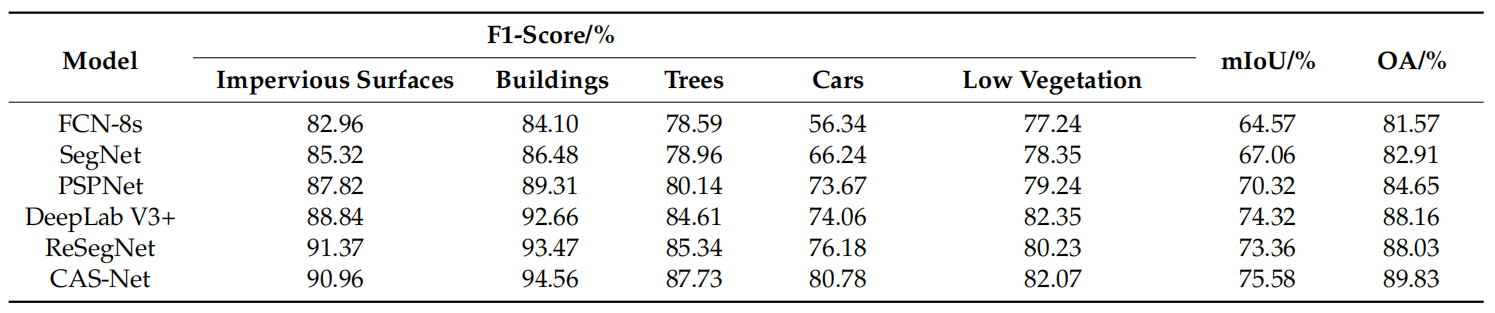
方法:本文提出了一种新的遥感图像语义分割模型CAS-Net,该模型通过在特征提取网络中将逐步卷积替换为SPD-Conv卷积,并在网络中添加了池化层,以避免细节信息的丢失,从而有效改善了小目标的分割效果。模型还引入了坐标注意机制,将其应用于空洞空间金字塔池化(ASPP)模块中,从而提高了遥感图像中分类对象的识别能力和目标定位精度。
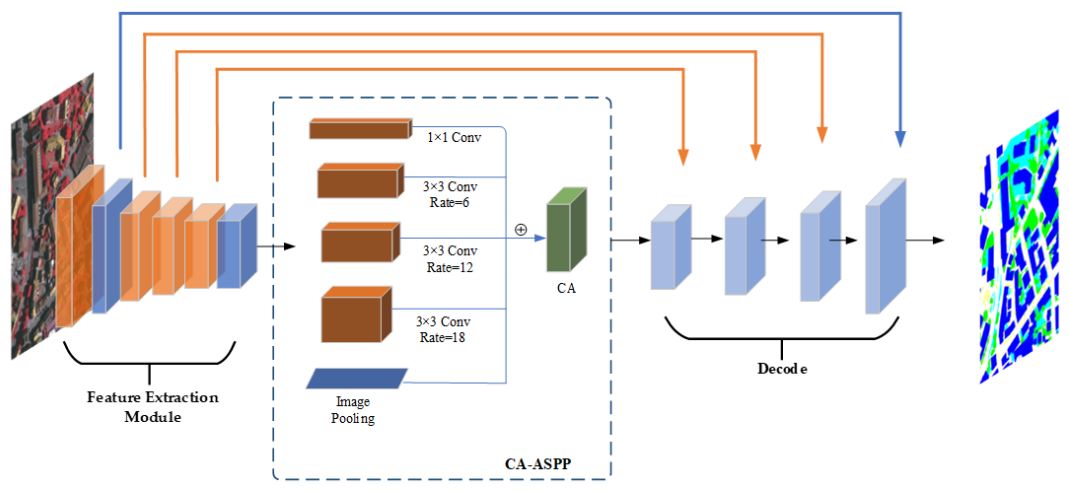
创新点:
- 新的遥感图像语义分割网络CAS-Net的提出:
-
在孔径空间金字塔池化(ASPP)模块中引入坐标注意力(CA),从而提高了遥感图像中分类对象的可识别性和目标定位精度。
-
引入Dice系数到交叉熵损失函数中,最大化了模型的梯度优化,解决了图像分类不平衡问题。
-
- 对小目标分割的新方法:
-
充分利用地面对象的对称性,并通过对称量化来减少参数数量,实现轻量级模型,同时保持了模型的性能。
-
引入了坐标注意力机制,使模型能够获取不同对象之间的关系,并避免了遥感图像中空间关系信息的丢失,从而提高了分割准确性。
-
关注下方《学姐带你玩AI》🚀🚀🚀
回复“坐标12”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏