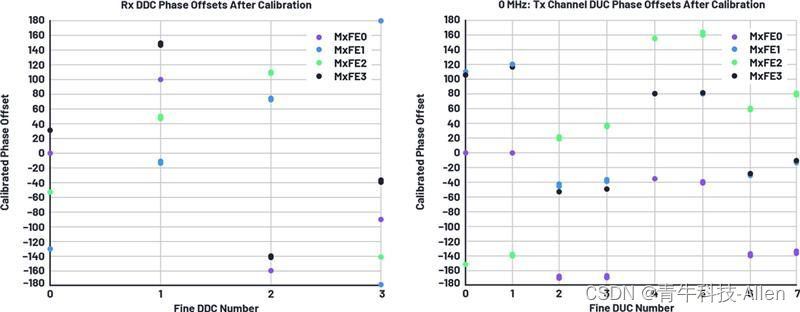
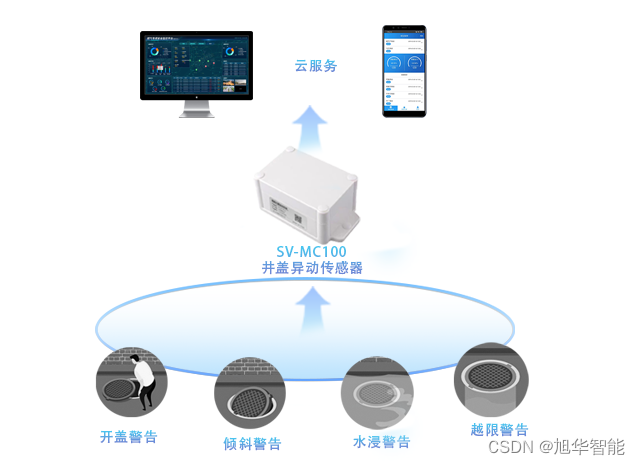
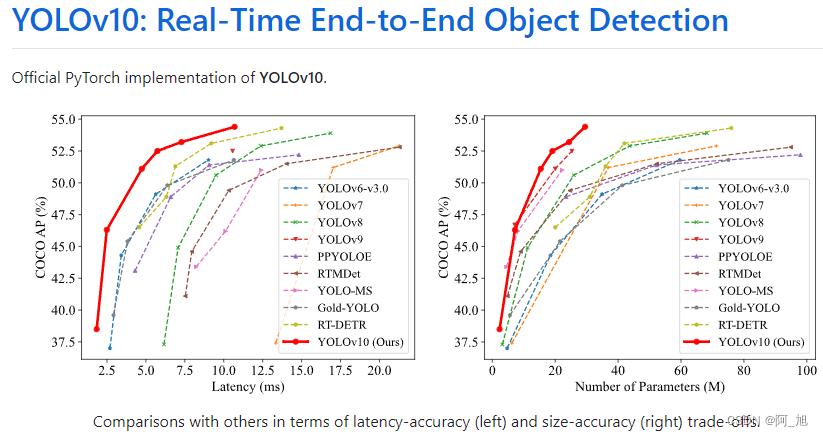
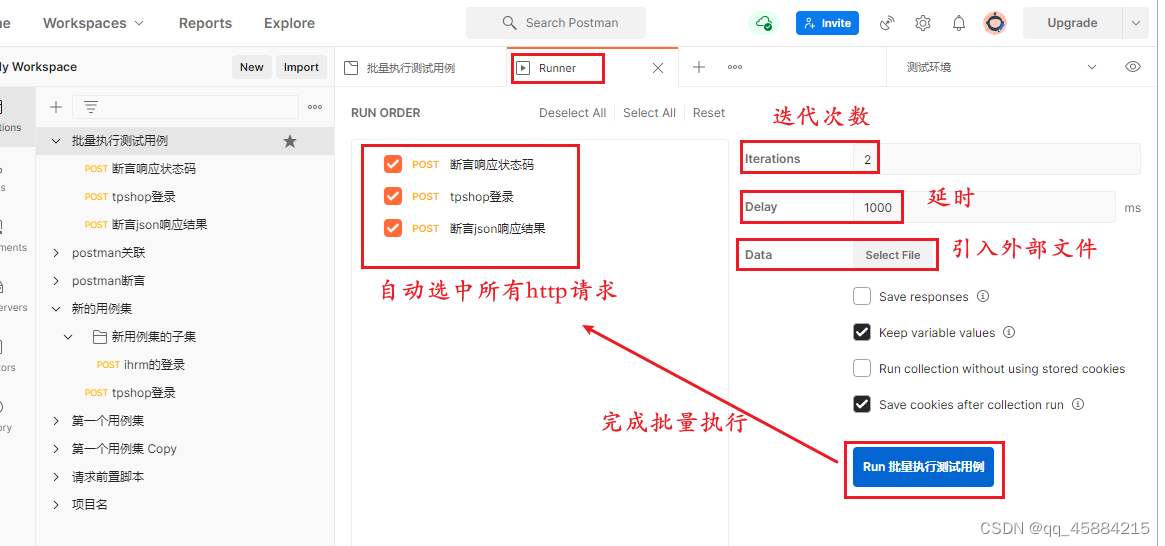
- Transformer
→
\to
→ 【知名应用】BERT (unsupervised trained Transformer)
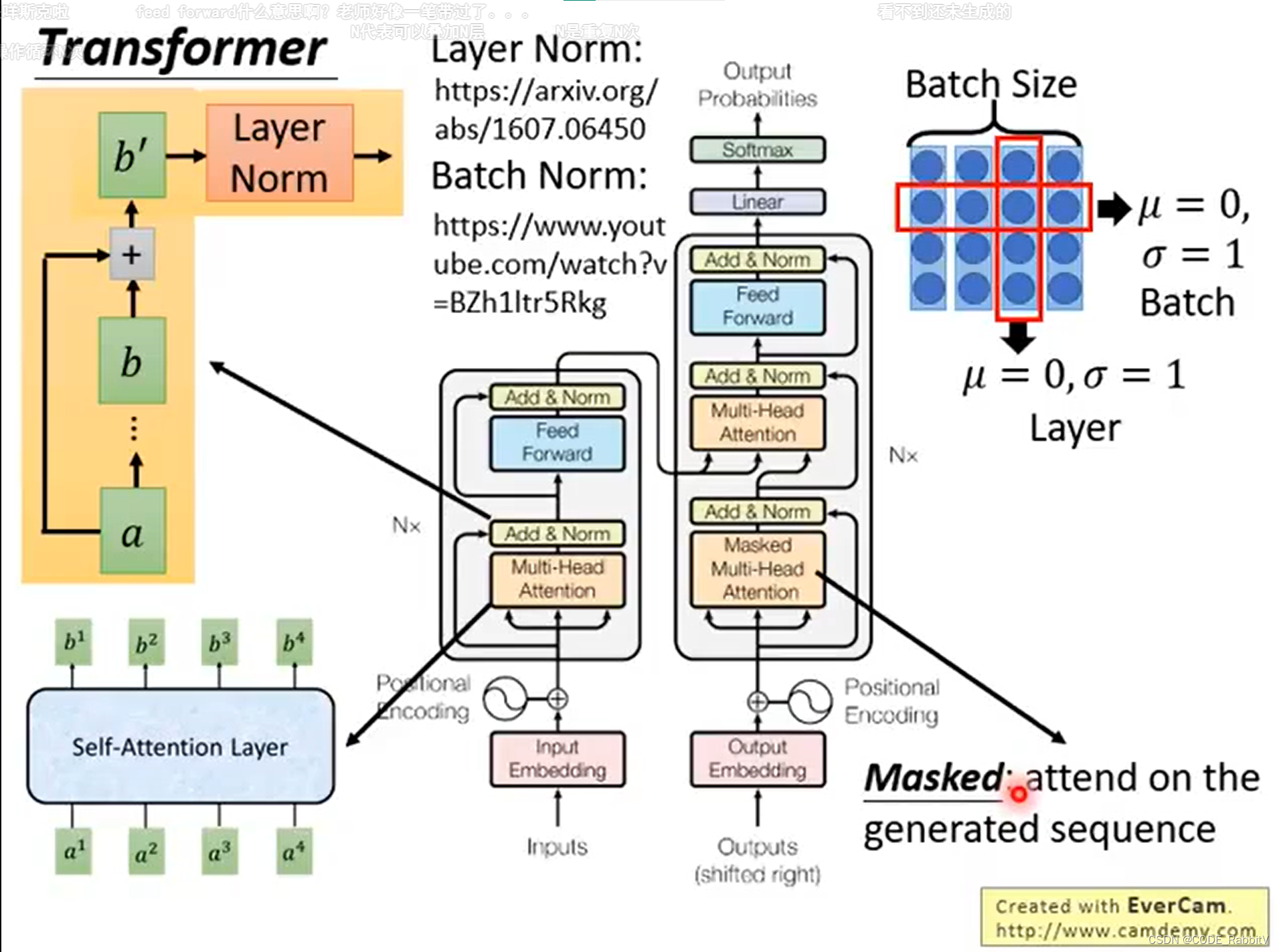
- Transformer :seq2Seq model with
self-attention, 后续会主要说明self-attention - Transformer的组成:
Self-attention是 Attention变体,擅长捕获数据/特征的内部相关性
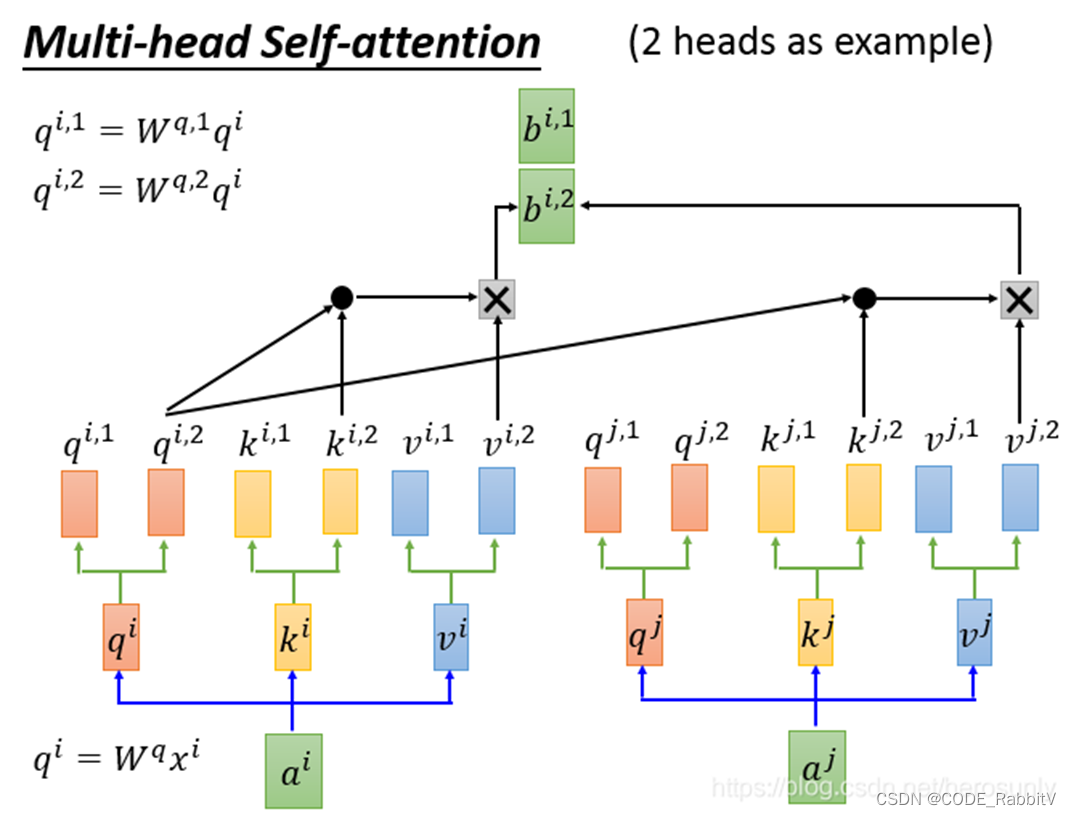
Self-attention 组成 Multi-head Self-attention
Multi-head Self-attention 反复利用组成Transforme
- Transformer :seq2Seq model with
-
【Seq】Sequence:考虑分别用 RNN 和 CNN 处理
 .....
.....
- 【左图】RNN: hard to parallel (需要序列输入进去处理)
- 【右图】CNN: replace RNN (单层覆盖范围有限,需要叠多层来扩展覆盖范围)
-
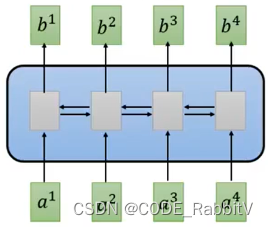
【replace CNN】Self-attention Layer: 类似双向RNN的作用,但是可并行化
- 【STEP-1】计算
qkv: q:query, k:key, v:value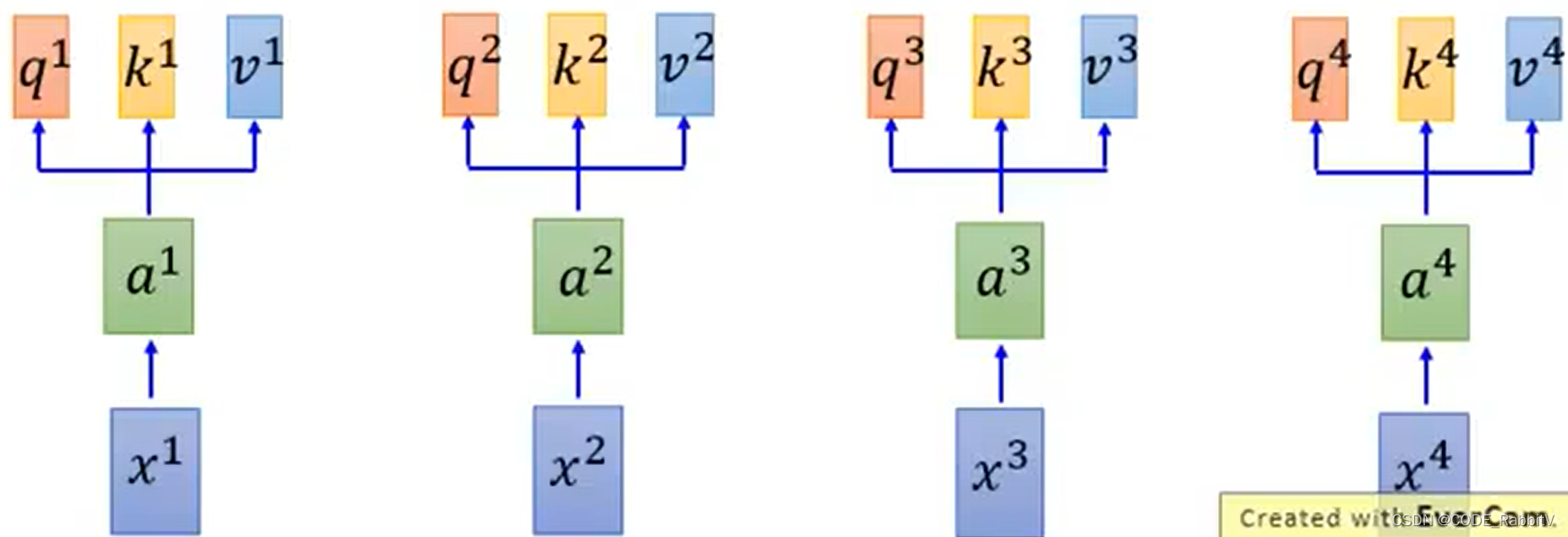 .....
.....

- 【STEP-2】每一个 q 对每一个 k 做 attention: 如 scaled dot-product attention
α i , j = q i ⋅ k j / d , d is the dim of q and k \alpha_{i,j}=q^i \cdot k^j / \sqrt{d}, \text{d is the dim of q and k} αi,j=qi⋅kj/d,d is the dim of q and k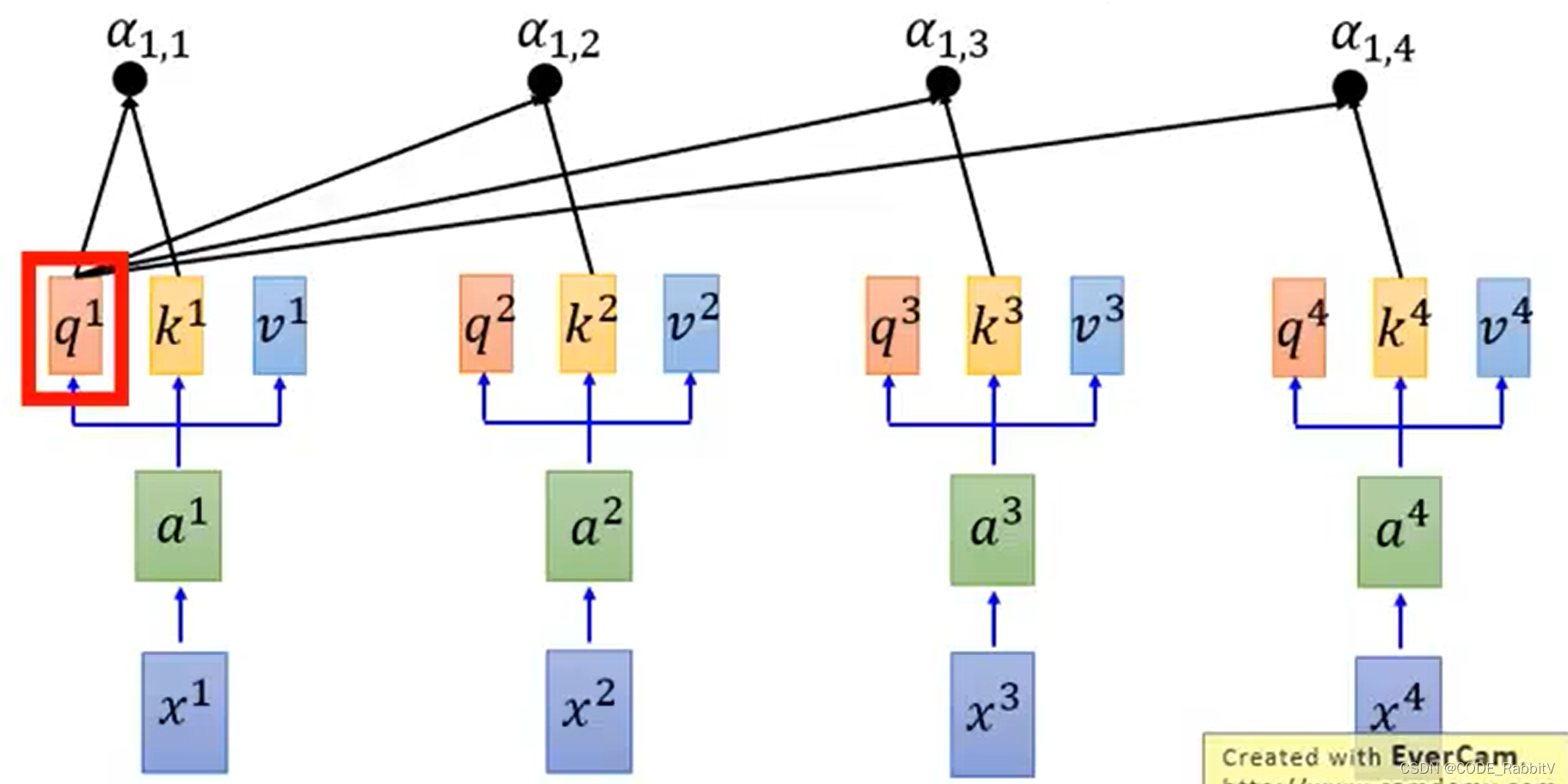
- 【STEP-3】经过
softmaxlayer:
α ^ i , j = exp α i , j ∑ k exp α i , k \hat{\alpha}_{i, j}=\exp{\alpha_{i, j}}\sum_k \exp{\alpha_{i,k}} α^i,j=expαi,jk∑expαi,k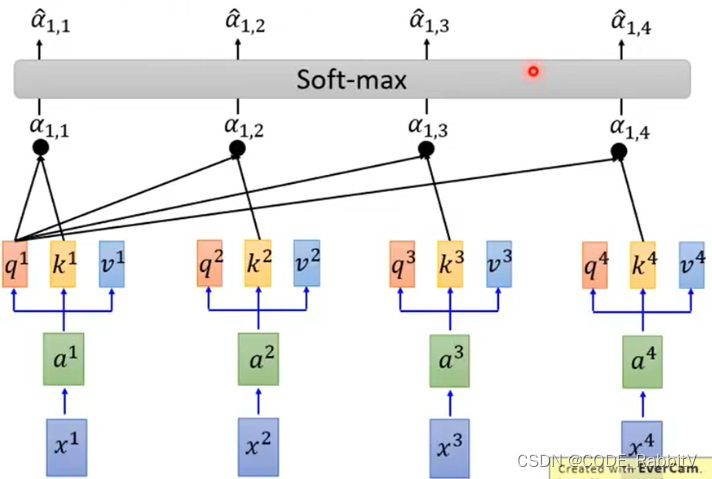
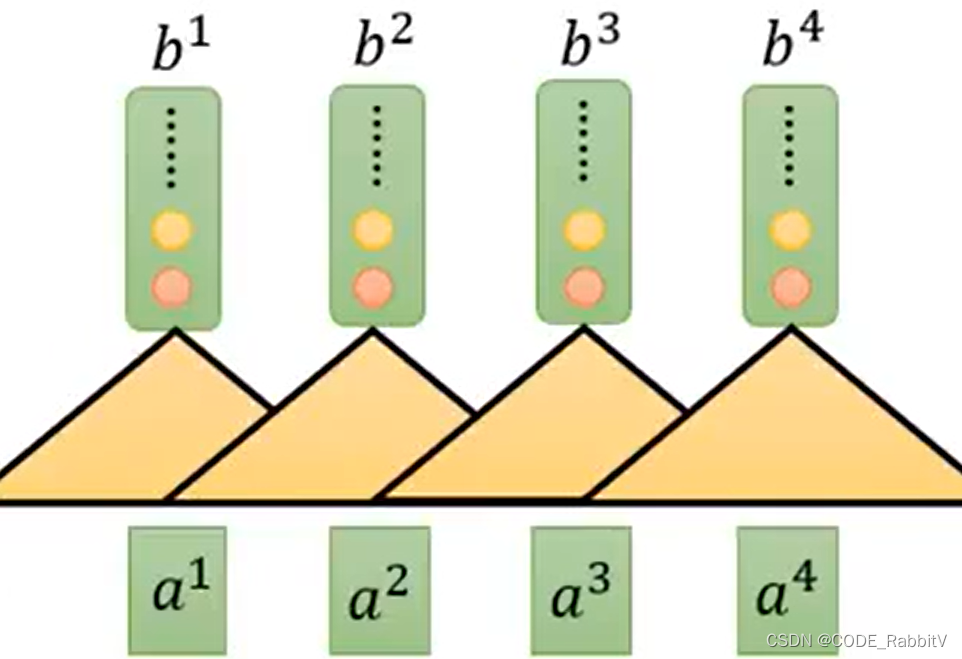
- 【STEP-4】计算输出
b:
b i = ∑ j α ^ i , j v j b^i = \sum_j \hat{\alpha}_{i,j}v^j bi=j∑α^i,jvj
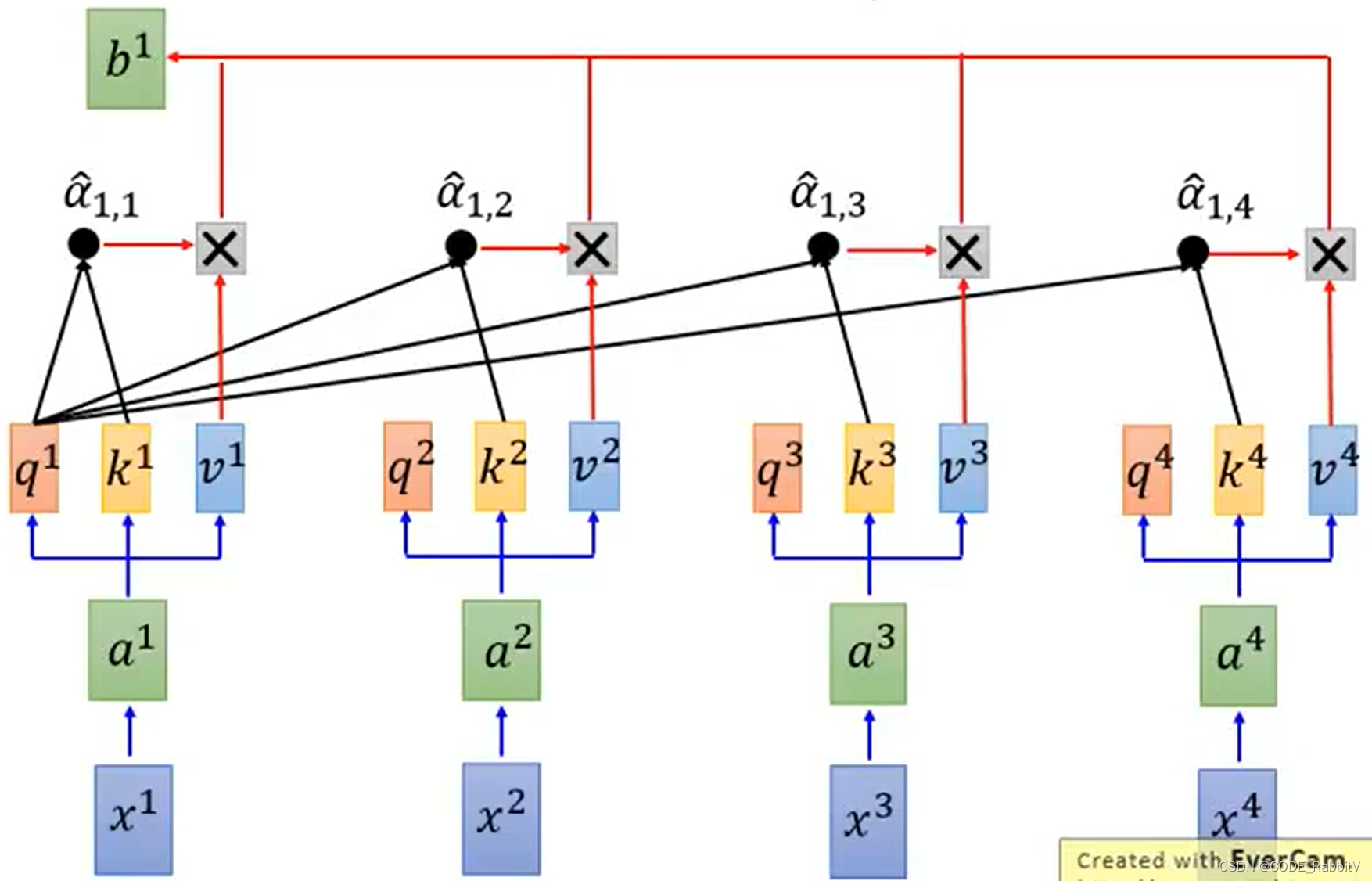
- 【STEP-1】计算
- 矩阵计算版本总结
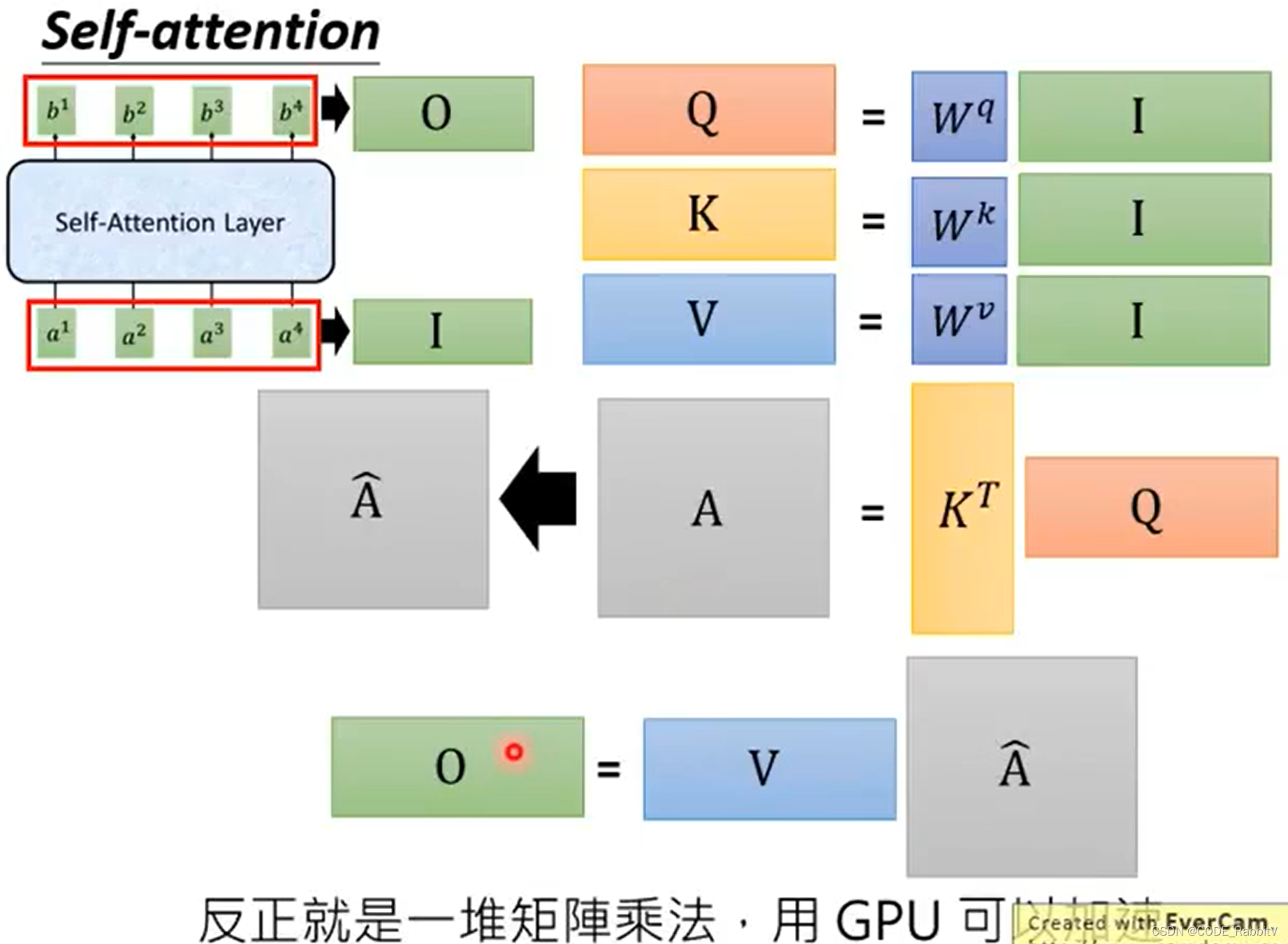
-
拓展:
- multi-head Self-attention: 多组 qkv 来关注不同信息
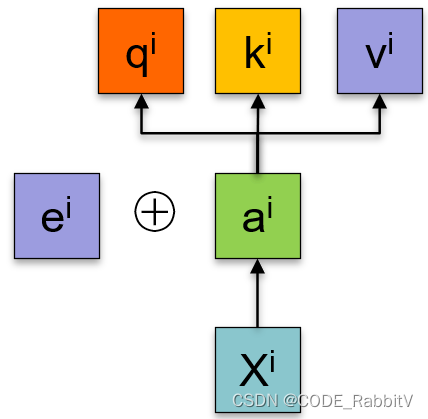
- positional encoding: α i \alpha^i αi += e i e^i ei, 可以引入位置信息 e i e^i ei
参考资料:
- 李宏毅深度学习 B站 视频资料