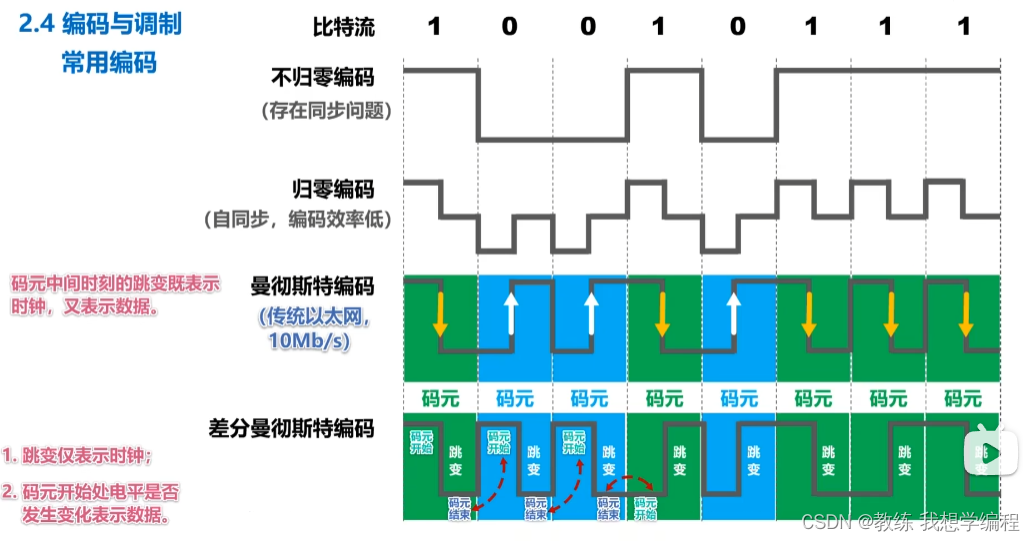
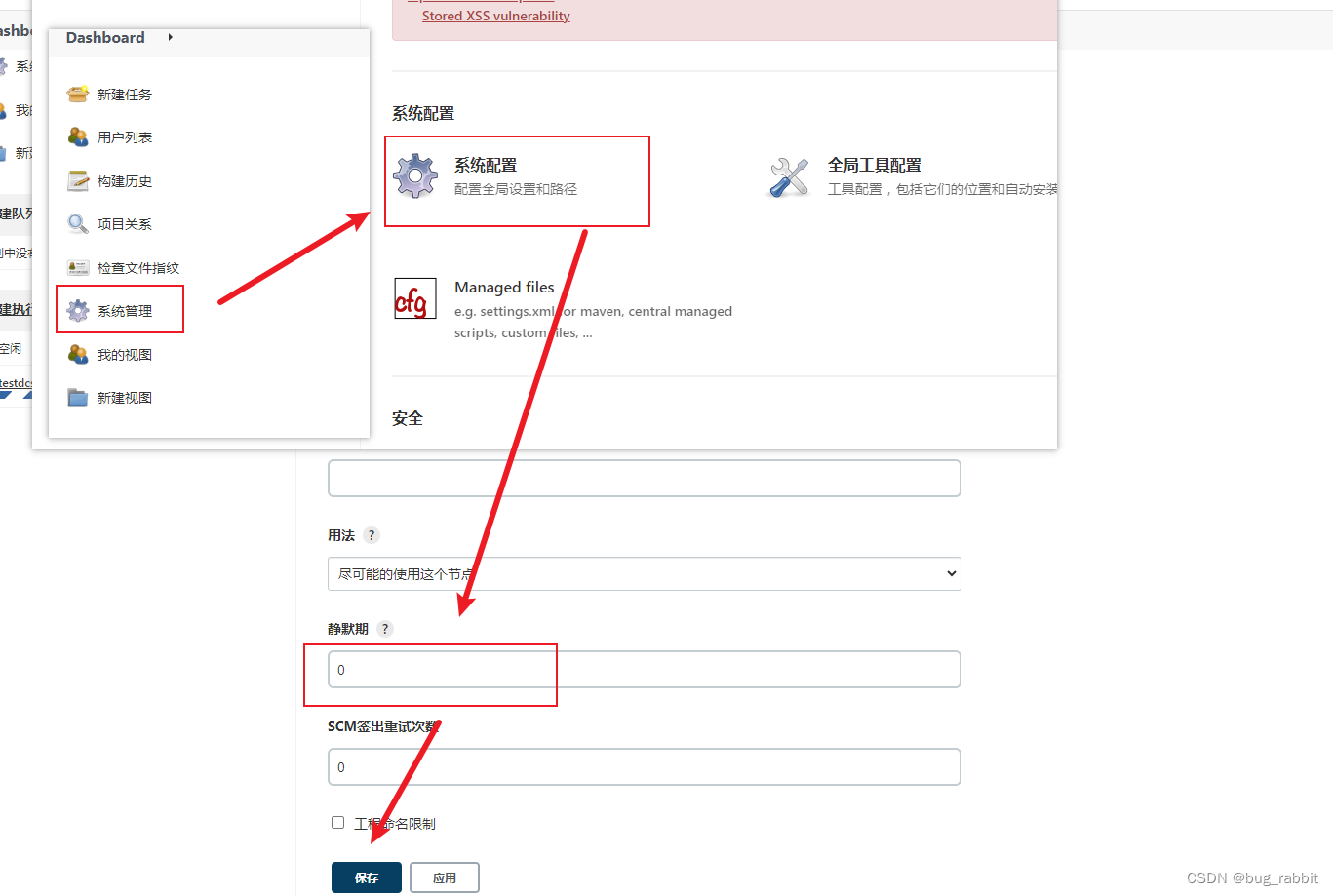
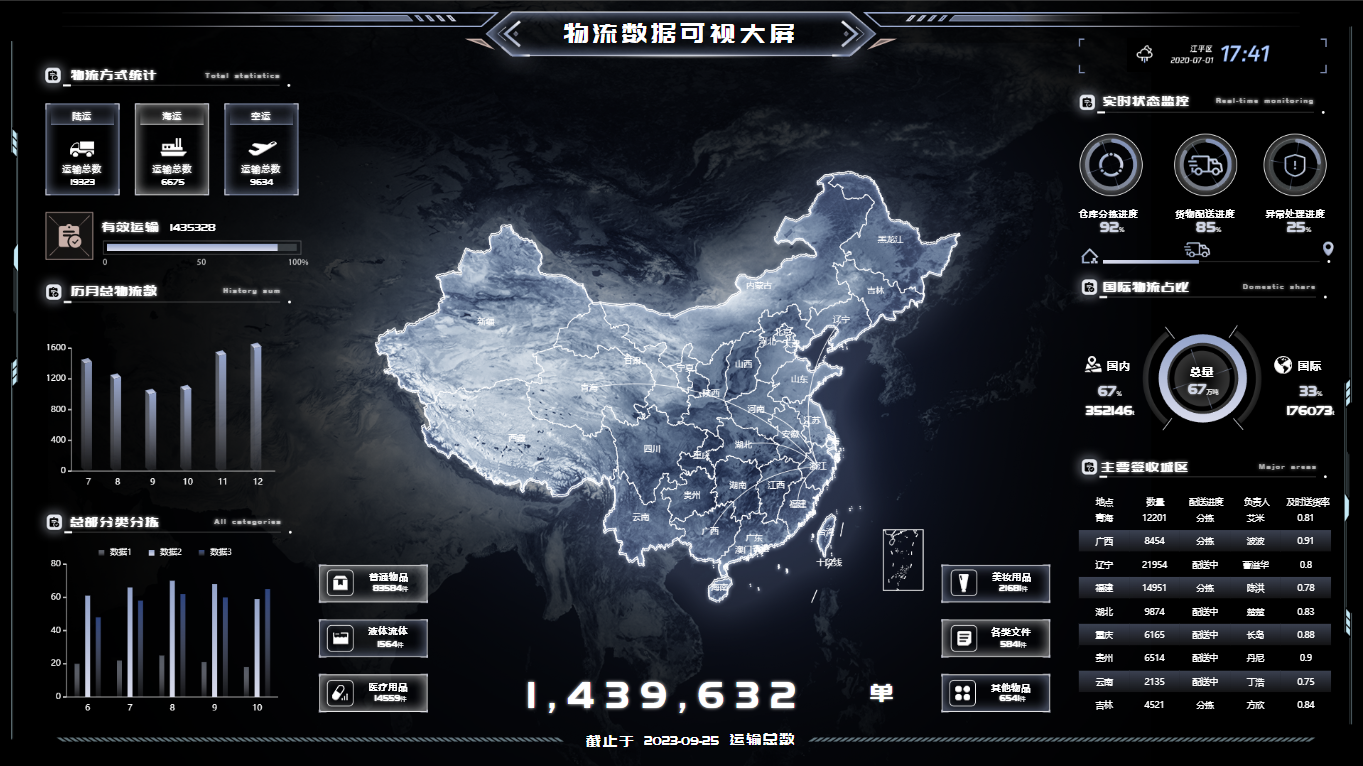
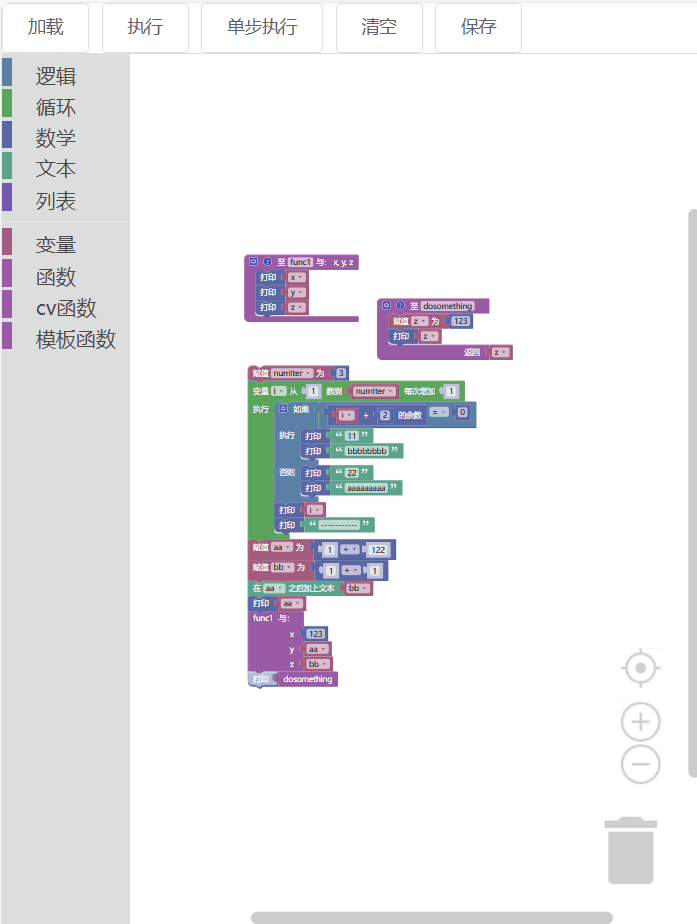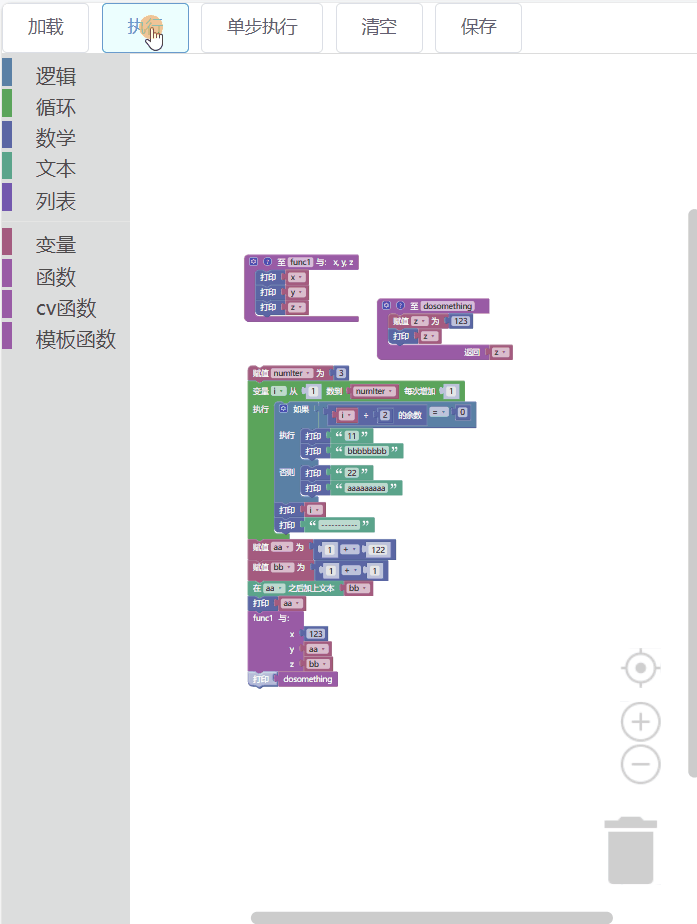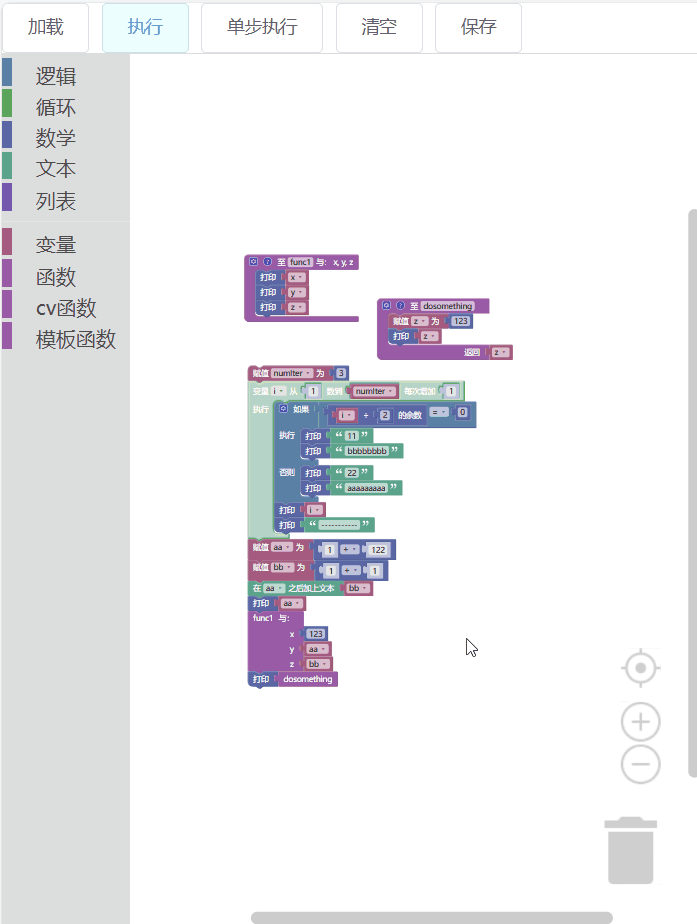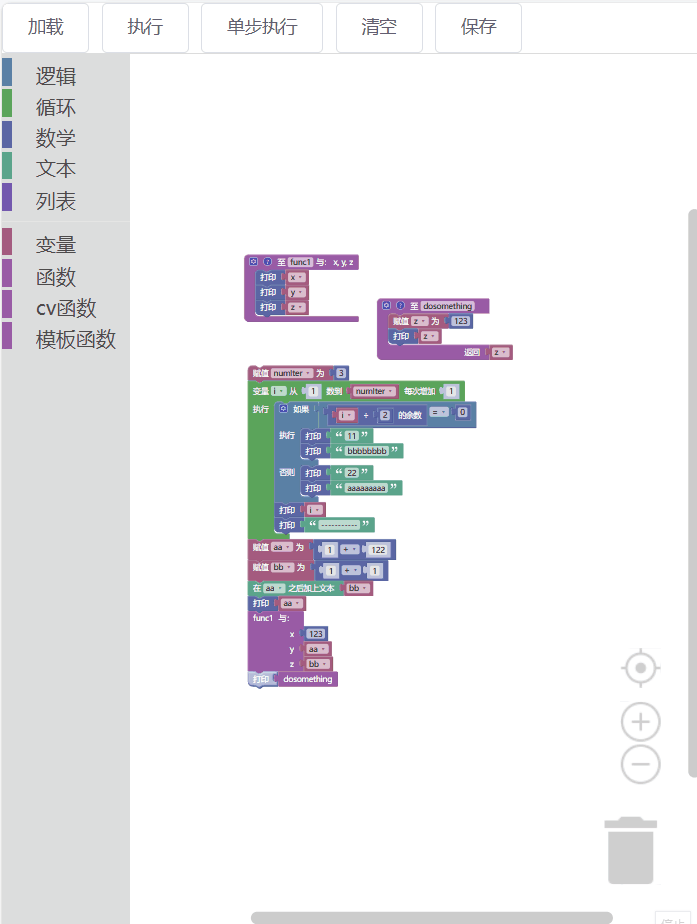
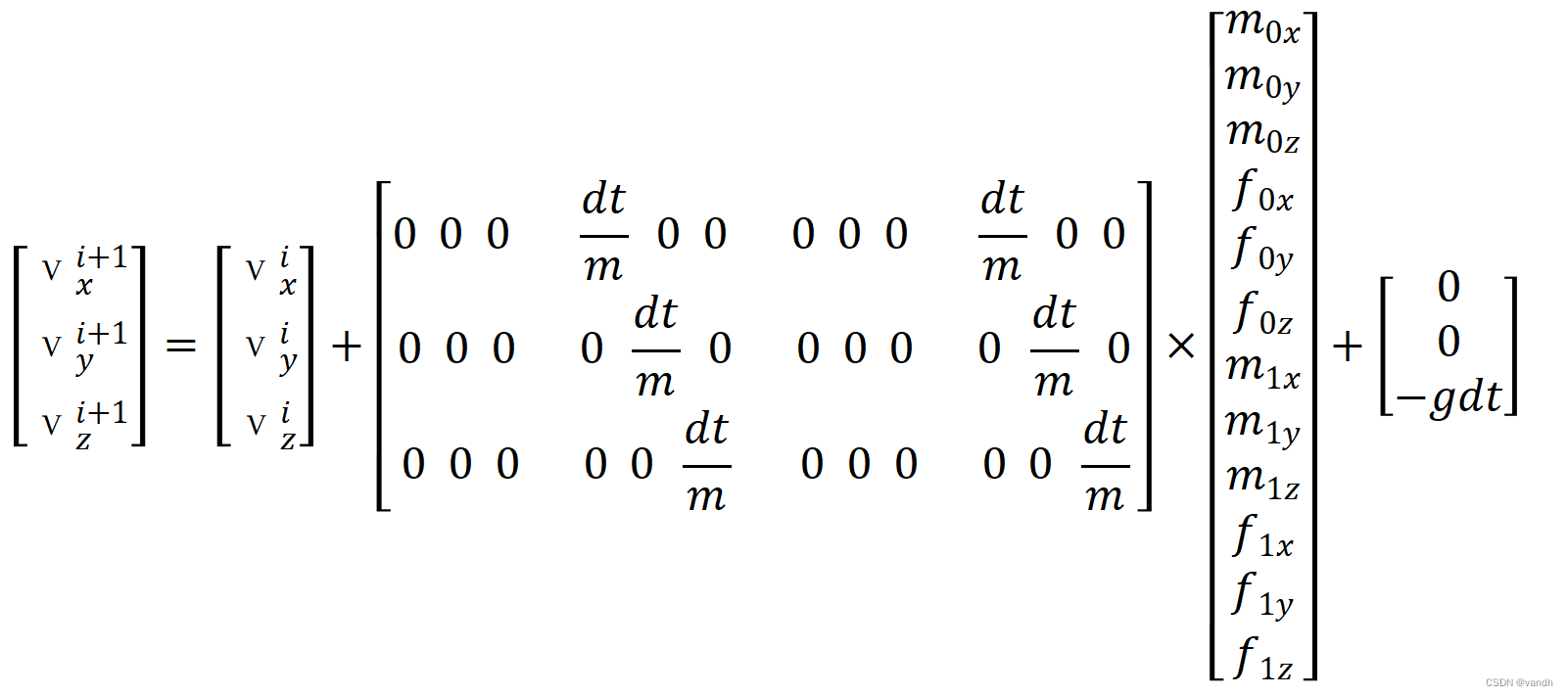1.代码
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
import jieba # 如果你处理的是中文文本,需要jieba分词
import re
# 停用词列表,这里只是示例,你可以根据需要添加或修改
stopwords = ['的', '是', '在', '了', '有', '和', '人', '我', '他', '她', '它', '们', '...','0','1','2','3','4','5','6','7','8','9','10','12','20','30']
# 读取Excel文件
df = pd.read_csv('word.csv', encoding='gbk')
# 假设你的数据在名为'text'的列中
texts = df['text'].tolist()
# 数据清洗和分词
cleaned_texts = []
for text in texts:
# 去除标点符号和非中文字符
cleaned_text = re.sub(r'[^\u4e00-\u9fa5\w]', '', text)
# 使用jieba进行分词
words = jieba.cut(cleaned_text)
# 去除停用词
filtered_words = [word for word in words if word not in stopwords]
cleaned_texts.append(' '.join(filtered_words))
# 生成词频字典
word_freq = Counter()
for text in cleaned_texts:
word_freq.update(text.split())
# 绘制词云图
wordcloud = WordCloud(font_path='simhei.ttf', # 设置字体文件,确保能正确显示中文
background_color='white',
stopwords=None, # WordCloud已经通过上面的步骤去除了停用词
min_font_size=10).generate_from_frequencies(word_freq)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
2.运行结果