正则表达式匹配的是文本内容,文本三剑客都是针对文本内容。
grep:过滤文本内容
sed:针对文本内容进行增删改查
awk:按行取列
一、grep
grep的作用使用正则表达式来匹配文本内容
1、grep选项
-m:匹配几次之后停止
#查找所有包含root的文本内容
[root@localhost opt]# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#使用-m选项匹配1次之后就停止
[root@localhost opt]# grep -m 1 root /etc/passwd
root:x:0:0:root:/root:/bin/bash
-v :取反 除了所要查的其他全部显示
#除了root其他都打印
[root@localhost opt]# grep -v root /etc/passwd-n:显示匹配的行号

-c :只统计匹配的行数
[root@localhost opt]# grep -c root /etc/passwd
2-o :仅限显示匹配到的结果
#显示所有的root
[root@localhost opt]# grep -o root /etc/passwd
root
root
root
root-q :静默模式,不输出任何信息
-A (after) 数字:后几行
#匹配到当前内容并附带3行
[root@localhost opt]# grep -A 3 root /etc/passwd
#定位
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
--
#定位
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin-B (before)数字:前几行
#匹配到前面3行
[root@localhost opt]# grep -B 3 dn /etc/passwd
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
test2:x:1000:1000:test2:/home/test2:/bin/bash
#定位
dn:x:1001:1001::/home/dn:/bin/bash-C 数字 :前后各几行
显示zlm前后各3行
[root@localhost opt]# grep -C 3 zlm /etc/passwd
tcpdump:x:72:72::/:/sbin/nologin
test2:x:1000:1000:test2:/home/test2:/bin/bash
dn:x:1001:1001::/home/dn:/bin/bash
#定位
zlm:x:1002:1002::/home/zlm:/bin/bash
#定位
zdm:x:1003:1003::/home/zdm:/bin/bash
zxc:x:1010:1010::/home/zxc:/bin/bash
nginx:x:1012:1012::/home/nginx:/sbin/nologin-e :多个条件 逻辑或
-E:匹配扩展正则表达式
-f :匹配两个文件相同的内容,按顺序以第一个文件为准
[root@localhost opt]# cat 111.txt
qq
112
123
[root@localhost opt]# cat 222.txt
123
#匹配两个文件相同的内容,按顺序以第一个文件为准
[root@localhost opt]# grep -f 111.txt 222.txt
123-r :递归目录 目录下的文件内容,软连接不包含在内
#在opt目录下查找关于123(123是内容)
[root@localhost opt]# grep -r 123 /opt/
/opt/xy102.txt:123
/opt/222.txt:123
/opt/test.txt:123
/opt/dec/test.txt:123
/opt/dec/xy102.txt:123
/opt/111.txt:123-R:递归目录 目录下的文件内容,软连接包含在内
二、sort
sort:以行为单位对文件的内容进行排序
格式:
sort 选项 参数 或者使用cat file | sort 选项
-f :忽略大小写,先排数字,字母按顺序,默认就会把大写字母排在最前面
[root@localhost opt]# cat 111.txt
qq
112
BBB
122
AAA
bbb
忽略大小写,先排数字,字母按顺序
[root@localhost opt]# sort -f /opt/111.txt
112
122
AAA
BBB
bbb
qq-b :忽略每行之前的空格,先排数字,字母按顺序(不是把空格删除,只是依然按照数字和字母的顺序排列)
[root@localhost opt]# cat /opt/111.txt
qq
112
123
122
123
bbb
#忽略空格,先排数字,字母按顺序
[root@localhost opt]# sort -b /opt/111.txt
112
122
123
123
bbb
qq-n :按照数字进行排序 字母在前,数字往后排
[root@localhost opt]# sort -n /opt/111.txt
bbb
qq
112
122
123
123-r :反向排序
[root@localhost opt]# cat -n /opt/111.txt
1 qq
2 112
3 123
4 122
5 123
6 bbb
7
#反向输出文本内容
[root@localhost opt]# cat -n /opt/111.txt | sort -r
7
6 bbb
5 123
4 122
3 123
2 112
1 qq-u :表示相同的数据只显示1行
[root@localhost opt]# cat 111.txt
qq
112
123
122
123
qq
[root@localhost opt]# sort -u 111.txt
112
122
123
qq-o :把排序后的结果转存到指定的文件
[root@localhost opt]# cat -n /etc/passwd | sort -rno /opt/cp.txt三、uniq
uniq去重 去除连续的重复的行,只显示一行
选项
-c: 统计连续重复的行的次数,合并连续重复的行
[root@localhost opt]# cat 111.txt
qq
112
BBB
122
122
122
AAA
BBB
BBB
bbb
[root@localhost opt]# uniq -c 111.txt
1 qq
1 112
1 BBB
3 122
1 AAA
2 BBB
1 bbb-u:显示仅出现一次的行(包括不是连续出现的重复行)
[root@localhost opt]# cat 111.txt
qq
112
BBB
122
122
122
AAA
BBB
BBB
bbb
[root@localhost opt]# uniq -u 111.txt
qq
112
BBB
AAA
bbb-d :仅显示连续重复的行(不包括非连续出现的内容)
[root@localhost opt]# cat 111.txt
qq
112
BBB
122
122
122
AAA
BBB
BBB
bbb
[root@localhost opt]# uniq -d 111.txt
122
BBB4、tr
tr:用来对标准输出的字符进行替换压缩和删除
格式:tr 选项 参数
-c: 保留字符集1的字符,其他的字符用字符集2进行替换
echo abc | tr -c ''ab 'a'
输出结果: abaa-d:删除字符集中的一部分
[root@localhost ~]# echo abc | tr -d 'ab'
c-s:替换 把字符集1的部分替换成字符集2的部分,连续重复出现的字符压缩成一个字符串
[root@localhost ~]# echo aaabc | tr -s 'a'
abc
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@localhost ~]# echo $PATH | tr -s ':' ';'
/usr/local/sbin;/usr/local/bin;/usr/sbin;/usr/bin;/root/bin四、cut
cut:快速裁剪 对字段进行采取和裁剪
-d :指定分隔符(默认的分隔符是tab键 不需要使用-d)
-f :对字段进行截取,指定输出段的内容
裁剪etc/passwd以:分割符的1-3行 1,3截取1行和3行
[root@localhost ~]# head -n 1 /etc/passwd | cut -d ':' -f 1-3
root:x:0
[root@localhost ~]# head -n 1 /etc/passwd | cut -d ':' -f 1,3
root:0
[root@localhost ~]# head -n 1 /etc/passwd
root:x:0:0:root:/root:/bin/bash-b:以字节为单位进行截取
-c :以字符为单位进行截取
-complement :输出的时候排除指定的字段
-output-delimiter:更改输出内容的分隔符
输出的时候以:分割符的不显示第2个
[root@localhost ~]# head -n 1 /etc/passwd | cut -d ':' --complement -f 1
x:0:0:root:/root:/bin/bash
[root@localhost ~]# head -n 1 /etc/passwd | cut -d ':' --output-delimiter='@' -f 1-5
root@x@0@0@root五、split
split 大文件拆分成若干小的文件
-l :按行来进行分割
[root@localhost opt]# split -l 20 test1.txt 123 将test1.txt文件 按20进行分割
-b :按照大小来进行分割
1、cat合并和paste合并有什么区别
cat合并是上下
paste是左右合并
[root@localhost opt]# cat 3.txt
11111111111111
aaaaa
[root@localhost opt]# paste 1.txt 2.txt > 4.txt
[root@localhost opt]# cat 4.txt
11111111111111 aaaaa2、 统计当前主机的连接状态
[root@localhost opt]# ss -antp | grep -v '^State' | cut -d ' ' -f 1 | sort | uniq -c
2 ESTAB
15 LISTEN
#grep -v '^State'取反除了以State开头的其他所有
#cut -d ' ' -f 1 以空格为分割符裁剪第一行
# sort 排序
#uniq -c 将连续重复的去重并显示数量六、正则表达式
正则表达式:由一类特殊字符以及字符所编写的一个模式,模式又来匹配文件当中的内容(字符)
校验我们输入的内容是否满足规定,格式,长度等等要求
主要用来匹配文本内容,命令的结果
通配符:只能用于匹配文件名和目录名,不能匹配文件的内容和命令结果
正则表达式:基本正则表达式
1、元字符(字符匹配)
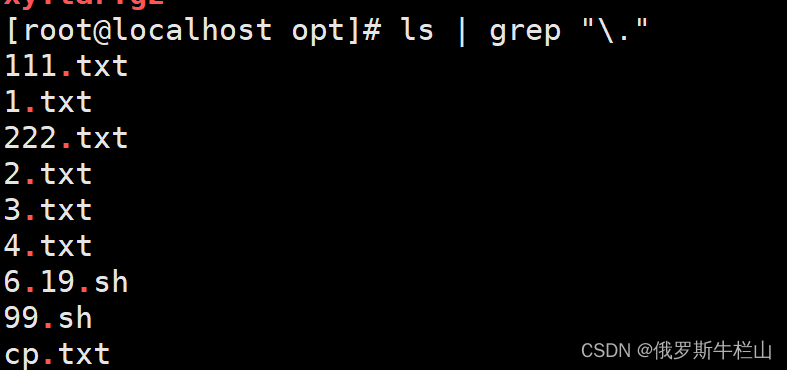
. 任意单个字符,也可以是一个汉字,每个字符都看一遍
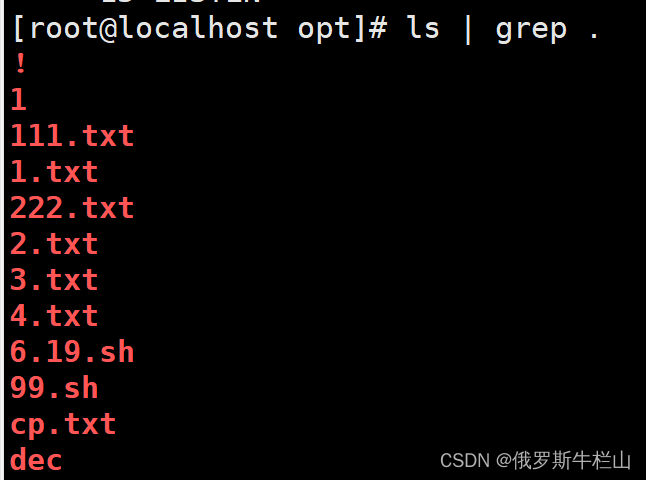
\ :转义符,恢复其本意,使用单引号或者双引号 引起来
[]:匹配指定范围内的任意单个字符或者数字
[] 中可以匹配多个 例如空格 大小写字母放在一起,每个条件不需要使用空格隔开
在正则表达式中更精确
[^]:取反
'^#' :匹配以#为开头 '^a'以a为开头
^$:表示空行 grep "^$" test1.txt 匹配空行
2、次数匹配
次数匹配:匹配字符出现的次数
*:匹配前面的字符任意次,0次也可以。贪婪模式,尽可能的匹配
.*:匹配前面的任意字符,至少要有1次,匹配所有。
\? :匹配前面的字符0次或者1次,可有可无
\+ :匹配前面的字符,至少出现一次
\ {n\}:匹配前面的字符=n次 可以小于n但不能大于n,而且前面的字符必须连续出现。a \{2\}
\{m,n\}:匹配前面的字符至少m次至多n次,且字符要连续出现,超出的不在匹配范围
\{,n\}:匹配前面的字符最多n次
\{n,\}:匹配前面的字符最少n次
3、位置锚定
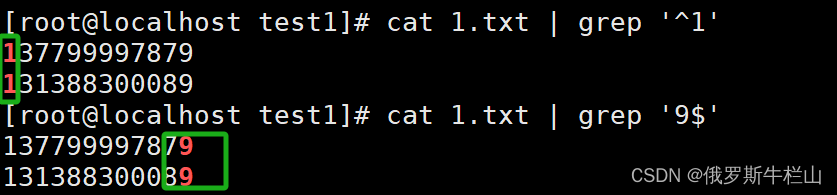
^:以什么开头 行首 '^1'以1为开头
$:以什么结尾 行尾 '4$'以4为结尾
'^root$'这一行只能有root
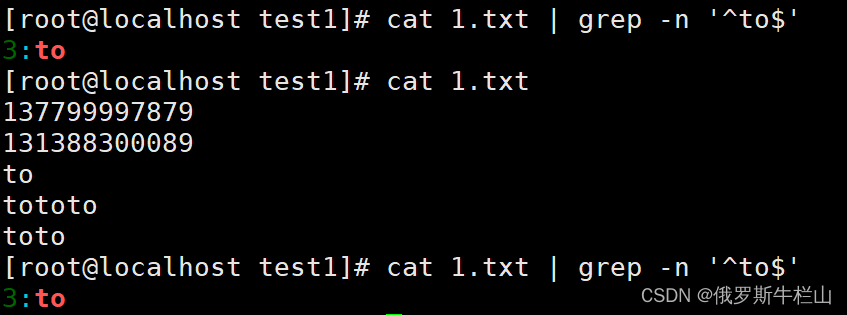
'^$' 空行
\<或者\b 词首锚定,匹配单词的左侧(连续的数字,字母,下划线都算单词内部)
\>或者\b 词尾锚定,用于匹配单词的右侧
hello-123
词首hello\b 或者 hello-\b
词尾\b123 或者\b-123
\broot\b 匹配整个单词root。空格隔开的也算整个单词
与^root$区别:整个一行只有这个单词
4、分组和逻辑关系
分组:()表示分组

或者:\| 逻辑或的意思 

七、 扩展正则表达式
扩展正则表达式:基本正则表达式的选项前的 \ 全部不用
特殊:\b需要加\
grep -E + 扩展正则或者egrep不需要+E
实例:打印2.txt文件中的电话号码
[root@localhost test1]# cat 2.txt | grep -E '(\([0-9]+\)|[0-9]+)[ -]?[0-9]+-[0-9]+'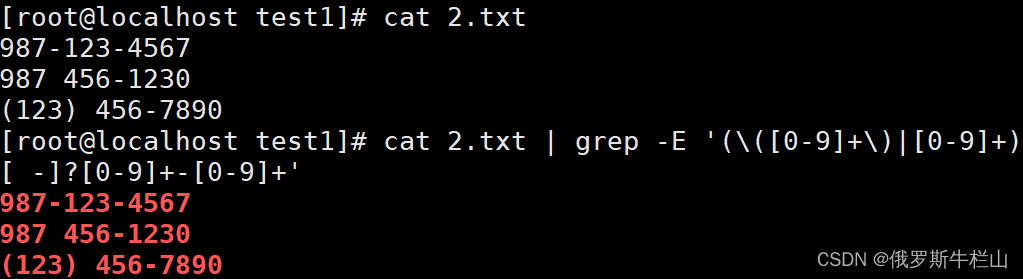
小练习
1、显示/etc/passwd中以sh结尾的行;
[root@localhost test1]# cat /etc/passwd | grep -E 'sh$'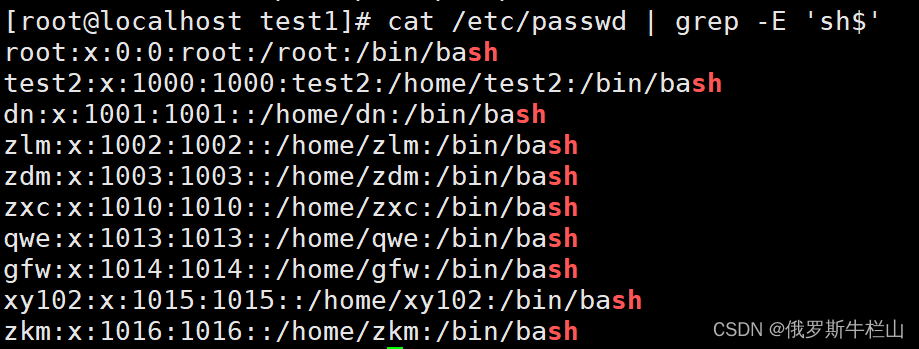
2、查找/etc/inittab中含有“以s开头,并以d结尾的单词”模式的行;
[root@localhost test1]# cat /etc/inittab | grep -E '(\bs[a-z]*d\b)'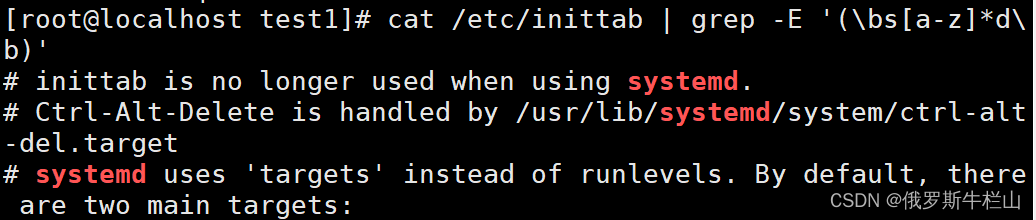
3、查找ifconfig命令结果中的1-255之间的整数;
[root@localhost /]# ifconfig | grep -E '\b([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\b'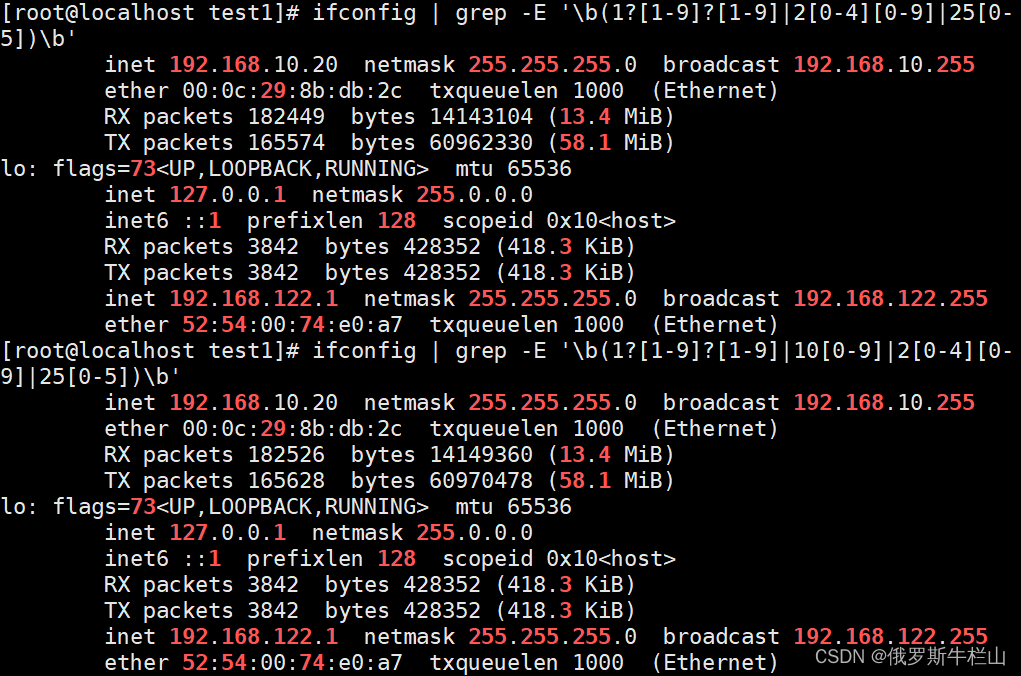
4、在/etc/passwd中取出默认shell为bash的行;
[root@localhost test1]# cat /etc/passwd | grep -E 'bash$'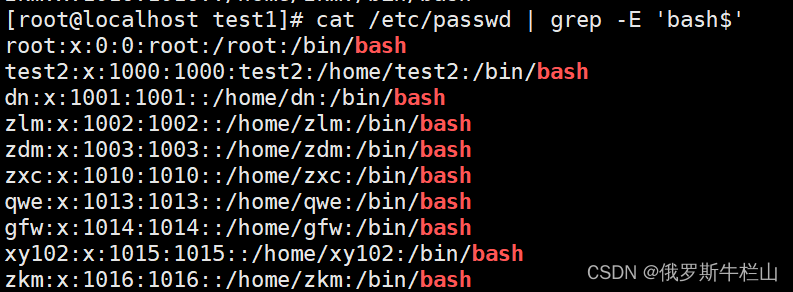
5、高亮显示passwd文件中冒号,及其两侧的字符
[root@localhost test1]# cat /etc/passwd | grep -E '.?:*:.'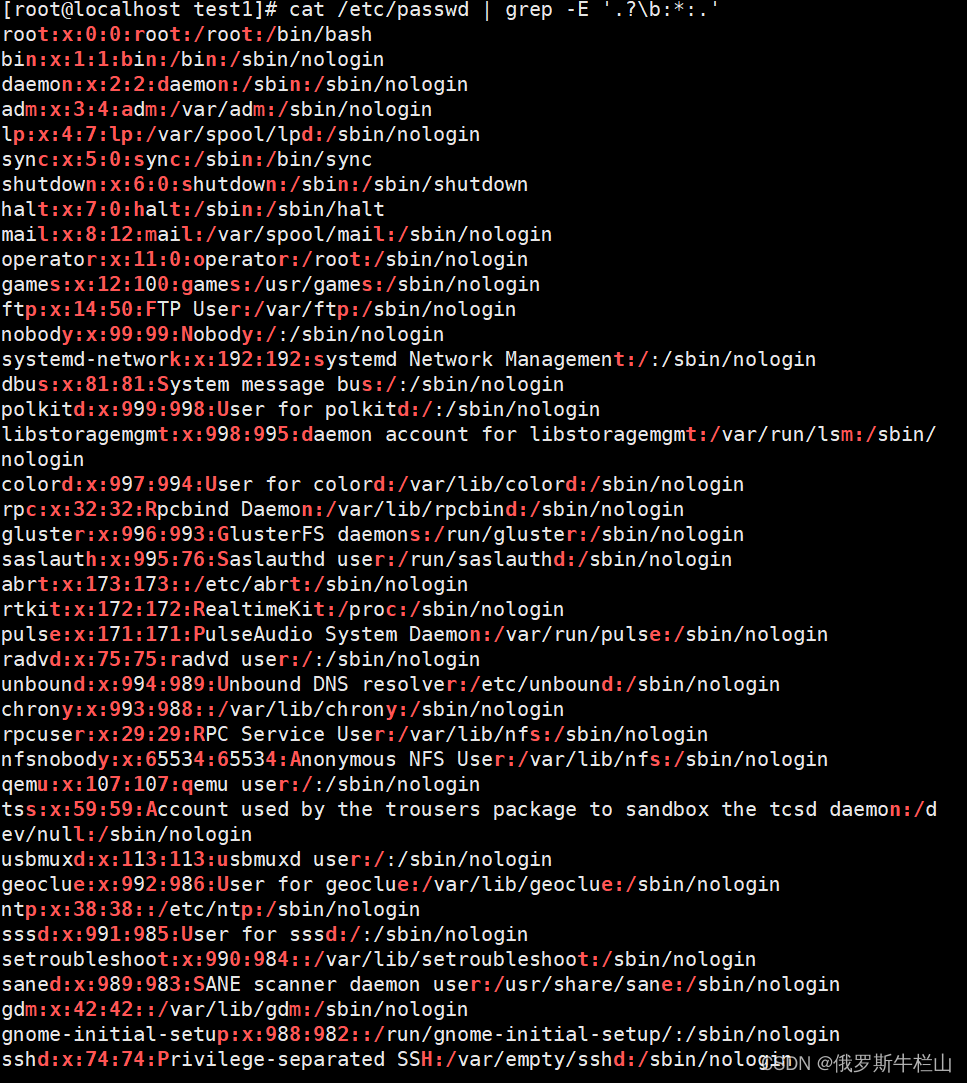
八、 sed
1、sed文件三剑客之二
sed :是有一种流编辑器,一次处理一行内容
处理方式:如果只是展示,会放在缓冲区(模式空间)展示结束之后,会从模式空间把操作结果删除
处理模式:一行一行处理,处理完当前行,才会处理下一行,直到文件的末尾
sed的命令格式以及操作选项
sed -e '操作选项' -e '操作选项' 文件1 文件2
-e 表示可以跟多个操作符,只有一个操作,-e可以省略
sed -e '操作符1:操作符2' 文件1 文件2
2、选项:
-e:用于执行多个操作命令
-f: 在脚本中定义好了操作符,然后根据脚本内容的操作符对文件进行操作
-i:直接修改目标文件(慎用)
-n:仅显示scrip处理后的结果(不加-n sed会有俩个输出结果,加了-n之后就会把默认的输出屏蔽只显示一个结果)
3、操作符:
p:打印结果
r:使用扩展正则表达式
s:替换,替换字符串
c:替换,替换行
y:替换,替换单个字符,多个字符替换必须和替换内容的长度保存一致
d:删除,删除行
a:增加,在指定行的下一行插入内容
i:增加,在指定行的上一行插入内容
r:在行后增加文件内容(读取其他文件)
$a:在最后一行插入内容
$i:在倒数第二行插入新的内容
$r:读取其他文件的内容然后插入到对象文件的最后一行
4、打印功能
打印内容
[root@localhost opt]# sed -n 'p' test1.txt
one
two
three
four
five
six
seven
eight
nine
ten寻址打印
显示行号
[root@localhost opt]# sed -n '=' test1.txt
1
2
3
4
5
6
7
8
9
即显示行号,又显示内容
[root@localhost opt]# sed -n '=;p' test1.txt
1
one
2
two
3
three
4
four
5
five
6
six
7
seven
8
eight
9
nine
10
ten指定地址查找
只显示第4行
[root@localhost opt]# sed -n '4p' test1.txt
four打印最后一行 $p
[root@localhost opt]# sed -n '$p' test1.txt
ten行号范围打印
从2行打印到末尾
[root@localhost opt]# sed -n '2,$p' test1.txt
two
three
four
five
six
seven
eight
nine
ten
打印第二行和第五行
[root@localhost opt]# sed -n '2p;5p' test1.txt
two
five打印奇数行和偶数行
奇数
[root@localhost opt]# sed -n 'p;n' test1.txt
one
three
five
seven
nine
偶数
[root@localhost opt]# sed -n 'n;p' test1.txt
two
four
six
eight
ten
#n的作用,跳过一行打印下一行5、文本内容进行过滤
过滤并打印包含o 的行 /所要查找的内容/
[root@localhost opt]# sed -n '/o/p' test1.txt
one
two
four
过滤并打印包含th的行
[root@localhost opt]# sed -n '/th/p' test1.txt
three使用正则表达式对文本内容进行过滤
[root@localhost opt]# sed -n '/^root/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash从指定行开始,打印到第一个以bash为结尾的行
从第8行打印到第一个以bash为结尾的行
[root@localhost opt]# sed -n '8,/bash$/p' /etc/passwdsed可使用的正则表达式 * .* {n,m} {n,}{,m} ? | () +
要么以root为开头要么以bash为结尾
[root@localhost opt]# sed -rn '/^root|bash$/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
test2:x:1000:1000:test2:/home/test2:/bin/bash
dn:x:1001:1001::/home/dn:/bin/bash
zlm:x:1002:1002::/home/zlm:/bin/bash
zdm:x:1003:1003::/home/zdm:/bin/bash
zxc:x:1010:1010::/home/zxc:/bin/bash
qwe:x:1013:1013::/home/qwe:/bin/bash
gfw:x:1014:1014::/home/gfw:/bin/bash
xy102:x:1015:1015::/home/xy102:/bin/bash
zkm:x:1016:1016::/home/zkm:/bin/bash6、小练习
如何免交互删除文本内容
sed方式
#-i 进入文本操作
#'d'删除
[root@localhost opt]# sed -i 'd' test1.txtcat方式
cat /dev/null > test1.txt7、 sed 的删除操作
删除指定行
删除第三行,并打印剩下的行
[root@localhost opt]# sed -n '3d;p' test1.txt
one
two
four
five
six
sevend
eight
nine
ten
除了第三行其他都删除
[root@localhost opt]# sed -n '3!d;p' test1.txt
three
除了第3行到第6行,其他都删除
[root@localhost opt]# sed -n '3,6!d;p' test1.txt
three
four
five
six匹配字符串的方式删除行
删除包含o的行
[root@localhost opt]# sed '/o/d' test1.txt
three
five
six
seven
eight
nine
ten
删除从one到six的行
[root@localhost opt]# sed '/one/,/six/d' test1.txt
seven
eight
nine
ten如何免交互的方式删除空行
[root@localhost opt]# cat test1.txt
one
two
three
four
five
six
seven
eight
nine
ten
[root@localhost opt]# grep -v '^$' test1.txt
one
two
three
four
five
six
seven
eight
nine
ten
[root@localhost opt]# cat test1.txt | tr -s '\n'
one
two
three
four
five
six
seven
eight
nine
ten
[root@localhost opt]# sed '/^$/d' test1.txt
one
two
three
four
five
six
seven
eight
nine
ten
8、主要功能:s替换字符串
替换每行第一个root
[root@localhost opt]# sed -n 's/root/test/p' /etc/passwd
test:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/test:/sbin/nologin
替换每行第二个root
[root@localhost opt]# sed -n 's/root/test/2p' /etc/passwd
root:x:0:0:test:/root:/bin/bash
替换每行所有root
[root@localhost opt]# sed -n 's/root/test/gp' /etc/passwd
test:x:0:0:test:/test:/bin/bash
operator:x:11:0:operator:/test:/sbin/nologin添加#实现注释功能
注释所有行
[root@localhost opt]# sed -n 's/^/#/p' test1.txt
#one
#two
#three
#four
#
#
#five
#six
#seven
#eight
#nine
#ten
注释4到5
[root@localhost opt]# sed -n '4,5 s/^/#/p' test1.txt
#four
#
注释4和7行
[root@localhost opt]# sed -n '5 s/^/#/p;7 s/^/#/p' test1.txt
#
#five首字母变大写
u& 转换首字母大写的特殊符合,\转义符
将首字母改为小写
[root@localhost opt]# sed 's/[a-z]/\u&/' test1.txt
One
Two
Three
Four
Five
Six
Seven
Eight
Nine
Ten
将所有的字母都替换成大写s/[a-z]/\u&/g
[root@localhost opt]# sed 's/[a-z]/\u&/g' test1.txt
ONE
TWO
THREE
FOUR
FIVE
SIX
SEVEN
EIGHT
NINE
TENl&把大写转换成小写的特殊字符,\转义符
[root@localhost opt]# sed 's/[A-Z]/\l&/' test2.txt
aAAA
bB
cC
所有替换 s/[A-Z]/\l&/g
[root@localhost opt]# sed 's/[A-Z]/\l&/g' test2.txt
aaaa
bb
cc整行替换
[root@localhost opt]# sed '/one/c 1' test1.txt
1
two
three
four
five
six
seven
eight
nine
ten9、单个替换
将/etc/sysconfig/network-scripts/ifcfg-ens33 的ip地址修改为192.168.10.100
[root@localhost opt]# sed '/^IP/c IPADDR=192.168.10.100' /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
DEVICE=ens33
ONBOOT=yes
BOOTPROTO=static
#替换结果
IPADDR=192.168.10.100
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
DNS1=218.2.135.1y单字符替换
将所有的t替换成1 w替换成2 o 替换成3
[root@localhost opt]# sed 'y/two/123/' test1.txt
i 3ne
123
1hree
f3ur
five
six
seven
eigh1
nine
1en10、 增加功能
#使用a在第3行的下一行插入一个zai
[root@localhost opt]# sed '3a zai' test1.txt
i one
two
three
#新增显示内容
zai
four
five
six
seven
eight
nine
ten
#使用i在第5行的上一行插入一个ba
[root@localhost opt]# sed '5i ba' test1.txt
i one
two
three
four
#新增显示内容
ba
five
six
seven
eight
nine
ten
#使用r将test2.txt的内容插入到test1.txt文件中two的下方
[root@localhost opt]# sed '/two/r test2.txt' test1.txt
i one
two
#新增显示内容
AAAA
BB
CC
three
four
five
six
seven
eight
nine
ten
使用$a将内容插入在文本内容的最后一行
[root@localhost opt]# sed '$a zai' test1.txt
i one
two
three
four
five
six
seven
eight
nine
ten
#新增显示内容
zai
使用$i将内容插入在文本内容的倒数第二行
[root@localhost opt]# sed '$i zai' test1.txt
i one
two
three
four
five
six
seven
eight
nine
#新增显示内容
zai
ten
使用$r将test2.txt的内容插入到test1.txt文件中最后一行
[root@localhost opt]# sed '$r test2.txt' test1.txt
i one
two
three
four
five
six
seven
eight
nine
ten
AAAA
BB
CC11、 sed进阶部分
使用sed对字符串和字符的位置进行互换
#字符串先进行分组,分组之后进行位置排序
[root@localhost opt]# echo ABC | sed -r 's/(A)(B)(C)/\1\3\2/'
ACB
[root@localhost opt]# echo ABC | sed -r 's/(A)(B)(C)/\3\1\2/'
CAB
[root@localhost opt]# echo ABC | sed -r 's/(A)(B)(C)/\2\1\3/'
BAC
[root@localhost opt]# echo zhangxiaoming | sed -r 's/(zhang)(xiao)(ming)/\3\1\2/'
mingzhangxiao
对字符位置进行互换,先分组,使用.代替字符,也可以直接使用原字符,然后再进行排序
[root@localhost opt]# echo 猪小明 | sed -r 's/(.)(.)(.)/\3\2\1/'
明小猪取出.jar之前的版本号
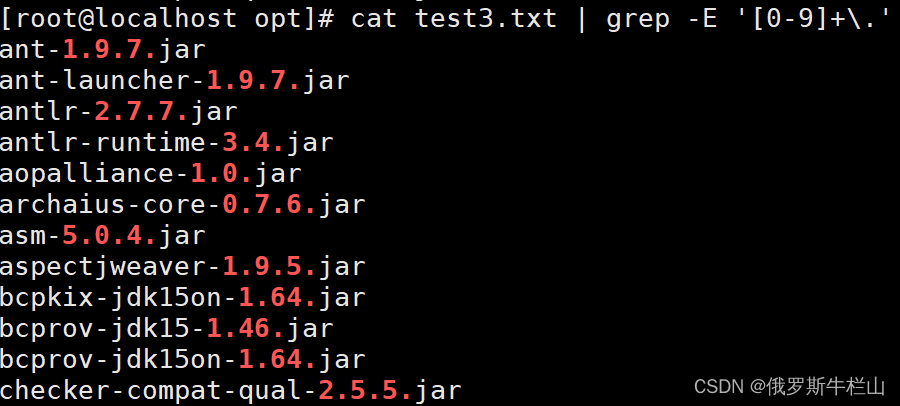
[root@localhost opt]# cat test3.txt
ant-1.9.7.jar
ant-launcher-1.9.7.jar
antlr-2.7.7.jar
antlr-runtime-3.4.jar
aopalliance-1.0.jar
archaius-core-0.7.6.jar
asm-5.0.4.jar
aspectjweaver-1.9.5.jar
bcpkix-jdk15on-1.64.jar
bcprov-jdk15-1.46.jar
bcprov-jdk15on-1.64.jar
checker-compat-qual-2.5.5.jar
[root@localhost opt]# cat test3.txt | grep -E '[0-9]+\.' 使用grep命令
使用sed命令
#先进行分组,分成3个组 .*代表任意长度的字符串 版本号位于第二组 取出第2组即可
[root@localhost opt]# cat test1.txt | sed -r 's/(.*)-(.*)(.jar)/\2/' test3.txt
1.9.7
1.9.7
2.7.7
3.4
1.0
0.7.6
5.0.4
1.9.5
1.64
1.46
1.64
2.5.512、 打印指定时间内的日志
[root@localhost opt]# sed -n '/Jun 21 13:50:01/,/Jun 21 14:01:01/p' /var/log/messages13、使用脚本的形式结合sed命令,把pxe自动装机做一个shell脚本
#关闭防火墙以及安全机制
systemctl stop firewalld
setenforce 0
#安装TFTP,xinetd服务,并将服务启动
yum -y install tftp-server xinetd
systemctl start tftp
systemctl enable tftp
systemctl start xinetd.service
systemctl enable xinetd.service
#vim /etc/xinetd.d/tftp`管理tftp服务配置
sed -i 's/yes/no/g' /etc/xinetd.d/tftp
#编辑文本内容
#wait = no
#修改成 no :可以并行安装多台客户机
#disable = no
#修改成 no: 后台启动tftp
重启两个服务
systemctl restart tftp
systemctl restart xinetd
配置DHCP
先安装`dhcp`服务
yum -y install dhcp
对`dhcp`服务进行配置:复制`dhcp`样板配置文件,覆盖`dhcp`实际的配置文件
yes | cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
sed -i 's/#ddns-update-style none;/ddns-update-style none;/' /etc/dhcp/dhcpd.conf
sed -i '15a next-server 192.168.10.20;' /etc/dhcp/dhcpd.conf
sed -i '16a filename "pxelinux.0";' /etc/dhcp/dhcpd.conf
sed -i 's/subnet 10.254.239.0 netmask 255.255.255.224 {/ subnet 192.168.10.0 netmask 255.255.255.0 {/' /etc/dhcp/dhcpd.conf
sed -i 's/range 10.254.239.10 10.254.239.20;/range 192.168.10.100 192.168.10.110;/' /etc/dhcp/dhcpd.conf
sed -i 's/rtr-239-0-1.example.org, rtr-239-0-2.example.org;/192.168.10.20;/' /etc/dhcp/dhcpd.conf
systemctl restart dhcpd
#挂载光盘
mount /dev/cdrom /mnt/
cp /mnt/images/pxeboot/initrd.img /var/lib/tftpboot/
cp /mnt/images/pxeboot/vmlinuz /var/lib/tftpboot/
yum -y install syslinux
cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/
yum -y install vsftpd
mkdir /var/ftp/centos7
cp -rf /mnt/* /var/ftp/centos7
systemctl restart vsftpd
mkdir /var/lib/tftpboot/pxelinux.cfg
cat > /var/lib/tftpboot/pxelinux.cfg/default <<EOF
default auto
prompt 0
label auto
kernel vmlinuz
append initrd=initrd.img method=ftp://192.168.10.20/centos7 ks=ftp://192.168.10.20/ks.cfg
label linux text
kernel vmlinuz
append initrd=initrd.img method=ftp://192.168.10.20/centos7
label linux rescue
kernel vmlinuz
append initrd=initrd.img method=ftp://192.168.10.20/centos7
EOF
#无人值守部分
yum -y install system-config-kickstart
cat > /var/ftp/ks.cfg <<EOF
#platform=x86, AMD64, or Intel EM64T
#version=DEVEL
install
keyboard 'us'
url --url="ftp://192.168.10.20/centos7"
lang zh_CN
auth --useshadow --passalgo=sha512
graphical
firstboot --disable
selinux --disabled
firewall --disabled
network --bootproto=dhcp --device=ens33
reboot
timezone Asia/Shanghai
bootloader --location=mbr
zerombr
clearpart --all --initlabel
part /boot --fstype="xfs" --size=512
part /home --fstype="xfs" --size=4096
part swap --fstype="swap" --size=4096
part / --fstype="xfs" --grow --size=1
%packages
@base
@core
@desktop-debugging
@dial-up
@directory-client
@fonts
@gnome-desktop
@guest-desktop-agents
@input-methods
@internet-browser
@java-platform
@multimedia
@network-file-system-client
@print-client
@x11
binutils
chrony
ftp
gcc
kernel-devel
kexec-tools
make
open-vm-tools
patch
python
%end
EOF九、awk
文件三剑客最后一个awk
wk :按行取列
awk默认分割符:空格,tab键,多个空格自动压缩成一个。
awk的工作原理,根据指令信息,逐行的读取文本内容,然后按照条件进行格式化输出。
1、awk的选项:
-F :指定分隔符,默认就是空格
-v :变量赋值
2、内置变量:
$#:(#表示数字) 按行需要取出的第几个字段
$0:打印所有,展示所有的文本内容(默认)
NR:需要处理的行号
NF:处理行的字段个数,特殊的$NF表示当前行的最后一个字段(几个字段)
FS:FS和F是一样的,都是指定分隔符,-F:FS=":"
OFS:指定输出内容的分隔符
RS:行分割符,可以根据RS的设置把文件内容切割成多个记录,也可以改变行的分隔符,默认是\n,回车,换行。
格式:
awk -F ‘操作符(动作)’处理对象
-F指定分隔符,如果是空格可以不加 动作:默认就是打印
[root@localhost opt]# awk '{print}' awk.txt #print后没加东西,默认$0
one two three
four five six
eight nine ten
[root@localhost opt]# awk '{print NR}' awk.txt #仅打印行号
1
2
3
4
[root@localhost opt]# awk '{print NR,$0}' awk.txt #不仅打印行号,也显示内容
1 one two three
2 four five six
3 eight nine ten
4 打印指定行
[root@localhost opt]# awk 'NR==2{print}' awk.txt #打印指定的第2行
four five six
[root@localhost opt]# awk 'NR==2,NR==5{print}' awk.txt #打印2到5行
four five six
eight nine ten
a b c
d e f
[root@localhost opt]# awk 'NR==2;NR==5{print}' awk.txt #打印第2和第5行
four five six
d e f
[root@localhost opt]# awk 'NR%2==0{print}' awk.txt #打印偶数行
four five six
a b c
g h i
m i n
[root@localhost opt]# awk 'NR%2==1{print}' awk.txt #打印奇数行
one two three
eight nine ten
d e f
j k l指定分隔符 -F+要分割符
#以:为分割符,查找1到3行的第3列
[root@localhost opt]# awk -F: 'NR==1,NR==3{print $3}' /etc/passwd
0
1
2
#打印第2行和第3行的第1列
[root@localhost opt]# awk -F: 'NR==2{print $1};NR==3{print $1}' /etc/passwd
bin
daemon3、awk怎么使用文本过滤
#过滤root,也可以使用正则表达式
[root@localhost opt]# awk '/root/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#正则表达式
[root@localhost opt]# awk '/bash$/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
test2:x:1000:1000:test2:/home/test2:/bin/bash
dn:x:1001:1001::/home/dn:/bin/bash
zlm:x:1002:1002::/home/zlm:/bin/bash
zdm:x:1003:1003::/home/zdm:/bin/bash
xy102:x:1004:1004::/home/xy102:/bin/bash
zzz:x:1006:1005::/home/zzz:/bin/bash
zxc:x:1010:1010::/home/zxc:/bin/bash
qqq:x:1011:1011::/home/qqq:/bin/bash4、BEGIN模式进行打印
格式:awk 'BEGIN{...};{...};END{...}' 文件
BEGIN{...}表示预先的条件,执行awk命令前的初始化操作
第二个{...}处理条件,如何对初始值进行操作
END{...}处理完之后的操作,一般都是打印
#BEGIN与END连用
有初始条件
[root@localhost opt]# awk 'BEGIN{x=1};{x++};END{print x}' awk.txt
9
#统计行数
[root@localhost opt]# awk 'BEGIN{x=0};{x++};END{print x}' awk.txt
8
#单独使用BEGIN,一次性执行,不需要处理条件
#乘法
[root@localhost opt]# awk 'BEGIN{print 10*2}' awk.txt
20
#幂运算
[root@localhost opt]# awk 'BEGIN{print 2**3}' awk.txt
8
#次方
[root@localhost opt]# awk 'BEGIN{print 2^3}' awk.txt
85、变量赋值
将外面的a的值传到awk里面进行赋值加一个 -v
read -p "输入第一个数" num1
read -p "输入第二个数" num2
sum=$(awk -v num1="$num1" -v num2="$num2" 'BEGIN{print num1^num2}')
echo $sum结果
[root@localhost opt]# sh awk.sh
输入第一个数2
输入第二个数3
86、不常用选项,了解
使用OFSS将:换成==
[root@localhost opt]# awk -v FS=":" -v OFS="==" '{print $1,$3}' /etc/passwd
root==0
bin==1
daemon==2
adm==37、 使用awk 进行条件判断打印
打印第三列大于999打印所有
[root@localhost opt]# awk -F: '$3>999{print $0}' /etc/passwd
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
test2:x:1000:1000:test2:/home/test2:/bin/bash
dn:x:1001:1001::/home/dn:/bin/bash
zlm:x:1002:1002::/home/zlm:/bin/bash
zdm:x:1003:1003::/home/zdm:/bin/bash
xy102:x:1004:1004::/home/xy102:/bin/bash
zzz:x:1006:1005::/home/zzz:/bin/bash
zxc:x:1010:1010::/home/zxc:/bin/bash
qqq:x:1011:1011::/home/qqq:/bin/bash
nginx:x:1012:1012::/home/nginx:/sbin/nologin
条件判断第三列等于1000,并打印所有
[root@localhost opt]# awk -F: '($3==1000){print $0}' /etc/passwd
test2:x:1000:1000:test2:/home/test2:/bin/bash8、awk的三元表达式
if else 语句
格式:awk -F: 'num=($3>$4)? $3:$4;'
转换成if语句
?=if
:=else
;=fi
if($3>$4)
then
echo $3
else
echo $4
fi
9、 awk的精确筛选:
$n(<>==)用于比较数值
$n~"字符串" 表示该字段包含某个字符串
$n!~"字符串" 该字段不包含某个字符串
$n=="字符串" 该字段等于这个字符串
$n!="字符串" 该字段不等于这个字符串
$NF 代表最后一个字段
#打印第7列包含bash这个字段的行,取得是行的第一列和最后一列,以:作为分隔符
[root@localhost opt]# awk -F: '$7~"bash" {print $1,$NF}' /etc/passwd
#取出第1列,第2列,和第3列,没有范围表示的,只有什么和什么
[root@localhost opt]# awk -F: '$7~"bash" {print $1,$2,$3}' /etc/passwd
root x 0
test2 x 1000
dn x 1001
zlm x 1002
zdm x 1003
xy102 x 1004
zzz x 1006
zxc x 1010
qqq x 1011
#精确匹配带有/bin/bash的字符串,==后面跟着的必须是完整的字符串,错一个字符也不能匹配到
[root@localhost opt]# awk -F: '$7=="/bin/bash" {print $1,$2,$3}' /etc/passwd
root x 0
test2 x 1000
dn x 1001
zlm x 1002
zdm x 1003
xy102 x 1004
zzz x 1006
zxc x 1010
qqq x 101110、逻辑关系
且和或
第一列等于dn且第七列等于/bin/bash
逻辑且 $1=="dn"可以使用()括起来
[root@localhost opt]# awk -F: '$1=="dn" && $7=="/bin/bash" {print $1,$7}' /etc/passwd
dn /bin/bash
逻辑或
[root@localhost opt]# awk -F: '$1=="dn" || $7=="/bin/bash" {print $1,$7}' /etc/passwd
root /bin/bash
test2 /bin/bash
dn /bin/bash
zlm /bin/bash
zdm /bin/bash
xy102 /bin/bash
zzz /bin/bash
zxc /bin/bash
qqq /bin/bash11、curl
curl是一个功能强大的命令
获取和发送数据
curl 域名/ip地址 获取网页的内容并且输出
curl www.baidu.com
curl 192.168.10.20
-O 下载文件到本地
-o 将文件下载到指定的路径
-x 发生post请求
-i 可以获取web软件的版本(服务端没有隐藏)
按行取列盘,不包含那个行的处理
12、小练习
awk取小数点几位以及小数运算怎么取整数
num=$(awk 'BEGIN{printf "%.2f",1.222*1.222}')
取小数点后两位,但是会四舍五入
[root@localhost nginx]# echo $num
1.49
只取整数部分
[root@localhost nginx]# num=$(awk 'BEGIN{printf "%.F",1.222+1.222}')
[root@localhost nginx]# echo $num
2连续取出test1.txt文件中的域名部分
[root@localhost opt]# cat test1.txt
1 www.kgc.com
2 mail.kgc.com
3 ftp.kgc.com
4 linux.kgc.com
5 blog.kgc.co
主机名取出来
[root@localhost opt]# cat test1.txt | awk -F '[ .]+' '{print $2}'
www
mail
ftp
linux
blog