本文字数:15291;估计阅读时间:39 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

Meetup活动
ClickHouse 上海首届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!
引言
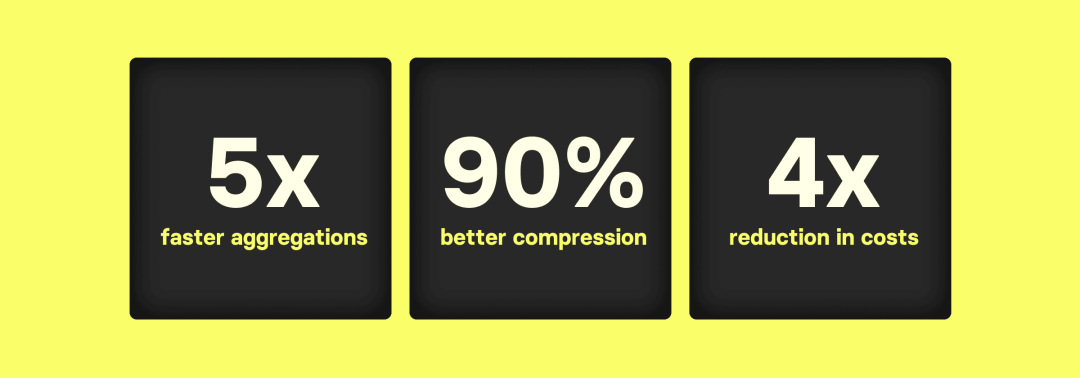
这篇博客探讨了在大规模数据分析和可观测性用例中,ClickHouse 与 Elasticsearch 在处理常见工作负载时的性能对比,特别是对数十亿行表的 count(*) 聚合。结果显示,ClickHouse 在处理大数据时的聚合查询性能显著优于 Elasticsearch。具体来说:
-
ClickHouse 的数据压缩效果远胜于 Elasticsearch,处理大数据集时,ClickHouse 需要的存储空间比 Elasticsearch 少 12 到 19 倍,因此可以使用更小、更便宜的硬件。

-
ClickHouse 中的 count(*) 聚合查询能够高效利用硬件资源,与 Elasticsearch 相比,ClickHouse 在大数据集聚合方面的延迟至少低 5 倍。
这意味着,在获得与 Elasticsearch 相同延迟的情况下,ClickHouse 需要的硬件规模更小,成本更低,具体来说便宜 4 倍。

-
ClickHouse 通过物化视图 (materialized views) 技术提供了更高效的存储和计算持续数据汇总,与 Elasticsearch 的转换 (transforms) 功能相比,进一步降低了计算和存储成本。

由于这些原因,我们越来越多地看到用户从 Elasticsearch 迁移到 ClickHouse,客户们强调:
-
在拍字节级别的可观测性用例中大幅降低成本:
“从 Elasticsearch 迁移到 ClickHouse 使我们的可观测性硬件成本降低了 30% 以上。”
——Didi Tech
-
克服数据分析应用的技术限制:
“这种迁移释放了新功能、增长和更容易扩展的潜力。”
——Contentsquare
-
监控平台的可扩展性和查询延迟显著改善:
“ClickHouse 帮助我们每月的数据量从数百万行扩展到数十亿行。”
“切换后,我们的平均读取延迟降低了 100 倍。”
——The Guild
在这篇文章中,我们将比较典型数据分析场景下的存储大小和 count() 聚合查询性能。为了适应博客的篇幅,我们将比较在单节点环境中独立运行 count() 聚合查询的大数据集性能。
博客的其余部分将首先解释我们为什么专注于基准测试 count() 聚合。然后我们会描述基准测试环境,解释我们的 count() 聚合性能测试查询和基准测试方法。最后,我们将展示基准测试结果。
在阅读基准测试结果时,您可能会想,“为什么 ClickHouse 这么快且高效?”简短的回答是对如何优化和并行化大规模数据存储和聚合执行的无数细节的关注。我们建议阅读《ClickHouse vs. Elasticsearch:Count 聚合的工作原理》一文,以获取该问题的深入技术答案。
ClickHouse 和 Elasticsearch 中的计数聚合
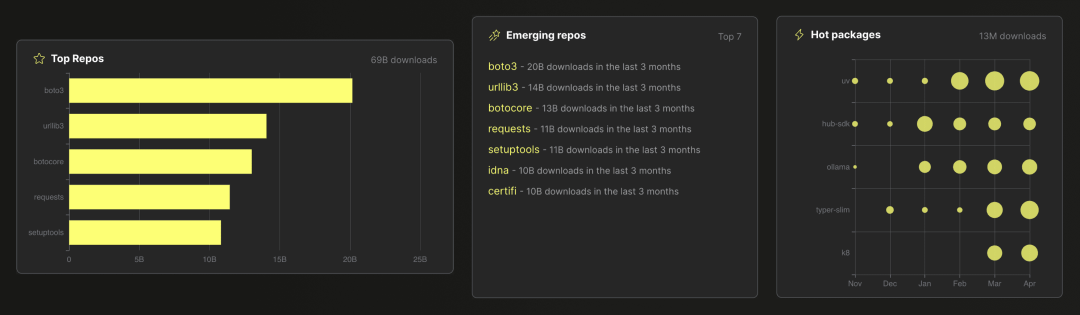
在数据分析场景中,聚合的一个常见用例是计算和排名数据集中值的频率。比如,ClickPy 应用程序的这个截图展示了所有数据可视化(分析了近 9000 亿行 Python 包下载事件),后台都使用了结合 count(*) 聚合的 SQL GROUP BY 子句:
同样地,在日志应用场景(或更广泛的可观测性应用场景)中,聚合最常见的应用之一是计算特定日志消息或事件发生的频率(并在频率异常时发出警报)。
在 Elasticsearch 中,等效于 ClickHouse 的 SELECT count(*) FROM ... GROUP BY ... SQL 查询的是 terms 聚合,这是一种 Elasticsearch 桶聚合 (bucket aggregation)。
我们在另一篇博客文章中描述了 Elasticsearch 和 ClickHouse 如何在后台处理这种计数聚合。在这篇文章中,我们将比较这些 count(*) 聚合的性能。
基准测试设置
数据
我们将使用公共的 PyPI 下载统计数据集。这个数据集不断增加,每一行都代表用户下载一个 Python 包(使用 pip 或类似技术)。去年,我的同事 Dale 构建了基于该数据集的分析应用程序,实时分析了近 9000 亿行数据(截至 2024 年 5 月),由 ClickHouse 聚合驱动。
我们使用了一个在公共 GCS 存储桶中托管为 Parquet 文件的版本。
从这个存储桶中,我们将加载 1、10 和 100* 亿行数据到 Elasticsearch 和 ClickHouse 中,以基准测试典型数据分析查询的性能。
*我们无法将 1000 亿行数据加载到 Elasticsearch 中。
硬件
这篇博客主要关注单节点数据分析性能。我们将多节点设置的基准测试留待未来的博客讨论。
我们为 Elasticsearch 和 ClickHouse 都使用了一个专用的 AWS c6a.8xlarge 实例。该实例具有 32 个 CPU 核心,64 GB RAM,本地附加 SSD(具有 16k IOPS),操作系统为 Ubuntu Linux。
另外,我们还比较了 ClickHouse Cloud 服务的性能,该服务节点在 CPU 核心数和 RAM 方面具有类似规格。
数据加载设置
我们从 GCS 存储桶中托管的 Parquet 文件中加载数据:
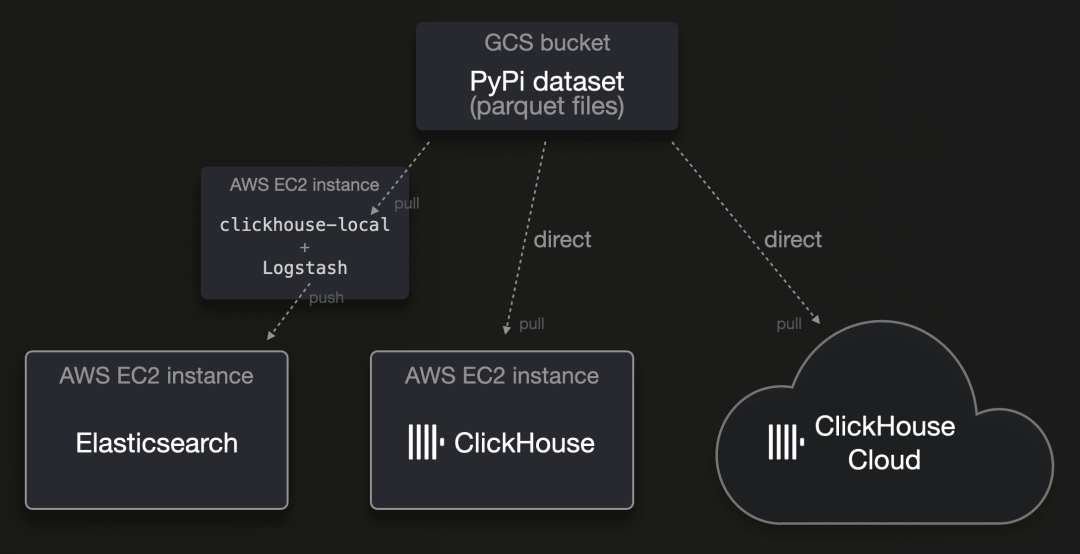
到 2024 年,Parquet 正日益成为分发分析数据的普遍标准。虽然 ClickHouse 开箱即支持这种格式,但 Elasticsearch 没有对这种文件格式的原生支持。其推荐的 ETL 工具 Logstash 也在撰写本文时不支持这种文件格式。
Elasticsearch
为了将数据加载到 Elasticsearch 中,我们使用了 clickhouse-local 和 Logstash。clickhouse-local 是将 ClickHouse 数据库引擎转换成的(极快的)命令行工具。ClickHouse 数据库引擎原生支持 90 多种文件格式,并提供 50 多种集成表函数和引擎,用于与外部系统和存储位置连接,这意味着它可以开箱即用并高度并行地读取或拉取几乎任何数据源中的几乎任何格式的数据。因为 ClickHouse 是关系型数据库引擎,我们可以利用 SQL 提供的所有功能,在将数据发送到 Logstash 之前,使用 clickhouse-local 动态过滤、丰富和转换这些数据。下图是用于 Logstash 的配置文件和将数据加载到 Elasticsearch 的命令行调用。
我们本可以使用 ClickHouse 的 url 表函数通过 clickhouse-local 将数据直接发送到 Elasticsearch 的 REST API。然而,Logstash 允许更容易地调整批处理和并行性设置,支持将数据发送到多个输出(例如,具有不同设置的多个 Elasticsearch 数据流),并且具有内置的弹性,包括反压和对失败批次的重试,具有中间缓冲和死信队列。
ClickHouse
如上所述,因为 ClickHouse 能够原生读取大多数云提供商的对象存储桶中的 Parquet 文件,我们只需使用这个 SQL 插入语句将数据加载到 ClickHouse 和 ClickHouse Cloud 中。对于 ClickHouse Cloud,我们通过利用所有服务节点来进一步提高并行度来加载数据。
我们没有尝试优化摄取吞吐量,因为这篇博客并不是为了比较 ClickHouse 和 Elasticsearch 的摄取吞吐量。我们将这留待未来的博客讨论。话虽如此,通过我们的测试,我们发现即使对 Logstash 的批处理和并行性设置进行了一些调整,Elasticsearch 加载数据的时间仍显著更长。当我们尝试加载 1000 亿行数据集时,它花费了 4 天时间加载了大约 300 亿行数据,我们计划为 Elasticsearch 包含基准测试结果,但未能成功加载如此大量的数据。而我们的 ClickHouse 实例则用显著更少的时间(不到一天)加载了完整的 1000 亿行数据集。
Elasticsearch 设置
Elasticsearch 配置
我们在一台机器上安装了 Elasticsearch 版本 8.12.2(GET / 输出),因此这台机器承担了所有角色,默认情况下使用可用 64 GB RAM 的一半作为 JVM 堆(GET _nodes/jvm 输出)。Elasticsearch 节点启动日志中记录的 heap size [30.7gb], compressed ordinary object pointers [true] 证明 JVM 可以使用高效的压缩对象指针,因为堆大小未超过 32 GB。Elasticsearch 将间接利用机器剩余的一半 64 GB RAM 来缓存从磁盘加载到操作系统文件系统缓存中的数据。
数据流
我们使用数据流来摄取数据,每个数据流由一系列自动滚动的索引支持。
从版本 8.5 开始,Elasticsearch 还支持针对时间序列数据的专用时间序列数据流。关于度量数据用例的性能比较将留待未来的博客讨论。
ILM 策略
为了设置回滚阈值,我们使用了一个索引生命周期管理 (ILM) 策略,配置了推荐的最佳实践来确保最佳分片大小(每个分片最多 200M 文档或分片大小在 10GB 到 50GB 之间)。此外,为了提高搜索速度并释放磁盘空间,我们配置了将回滚索引的段强制合并为一个段。
索引设置
分片数量
我们将数据流的支持索引配置为包含 1 个主分片和 0 个副本分片。正如在这里描述的,Elasticsearch 在进行词条聚合(我们在查询中使用)时,每个分片使用一个并行查询处理线程。因此,为了获得最佳搜索性能,分片数量应与我们测试机器上的 32 个 CPU 核心数量相匹配。然而,鉴于我们摄入的数据量很大(数十亿行),数据流的自动索引滚动已经创建了许多分片。此外,这也是实时流场景的更现实设置(原始 PyPi 数据集不断增长)。
索引编码
我们测试了使用较重的 best_compression 进行存储大小压缩,它使用 DEFLATE 编码而非默认的 LZ4 编码。
索引排序
为了支持索引编码的最佳压缩比以及 doc-ids 的紧凑且高效的编码,我们启用了索引排序,并使用所有现有的索引字段对存储字段(特别是 _source)和磁盘上的 doc_values 进行排序。我们按字段的基数升序排列了索引排序字段(这确保了最高可能的压缩率)。
索引映射
我们使用组件模板创建了 Elasticsearch 的 PyPi 数据流。下图勾勒了 PyPi 数据流的结构:
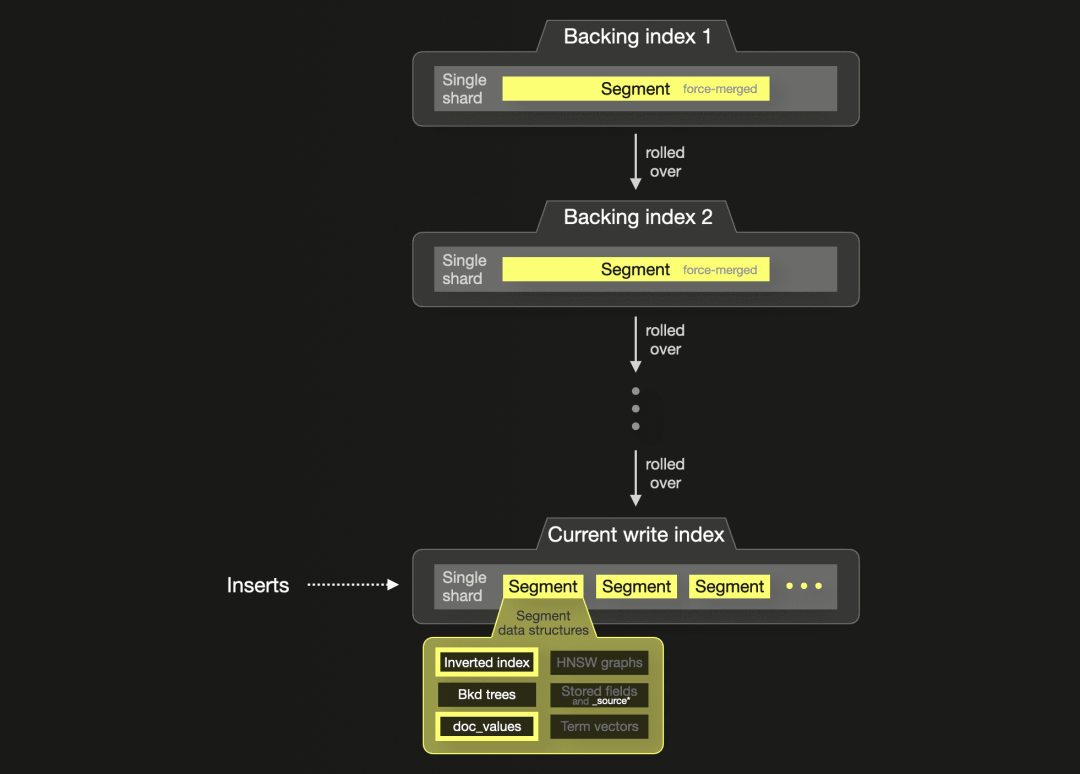
插入的文档包含 4 个字段,这些字段存储在索引中:
-
country_code
-
project
-
url
-
timestamp
为了与 ClickHouse 进行公平的存储和性能比较,我们关闭了除了倒排索引、doc_values 和 Bkd trees 之外的所有段数据结构,并在索引映射中仅使用了 keyword 和 date 数据类型。这些数据结构与数据分析的访问模式(如聚合和排序)相关。
keyword 类型填充了倒排索引(用于快速过滤)和 doc_values(用于聚合和排序)。此外,对于倒排索引,keyword 类型意味着字段值没有规范化和标记化。相反,它们未修改地插入倒排索引以支持精确匹配过滤。
因此,Elasticsearch 的倒排索引(按字典顺序排序的所有唯一标记列表,指向文档 ID 列表,具有二进制搜索查找功能)大致相当于 ClickHouse 的主索引(按字典顺序排序的主键列值稀疏列表,指向行块,具有二进制搜索查找功能)。
我们本可以通过禁用所有字段(例如 project 和 url)的倒排索引进一步优化 Elasticsearch 的数据存储,因为我们的基准查询并不对这些字段进行过滤。这可以通过在索引映射中将 keyword 类型的 index 参数设置为 false 来实现。然而,由于这些字段(project 和 url)也是我们 ClickHouse 表主键的一部分(因此,ClickHouse 主索引数据结构由这些字段的值填充),我们也保留了 Elasticsearch 这些字段的倒排索引。
date 类型在内部以长整型数字存储在 doc_values(用于聚合和排序)和 Bkd trees(日期查询在内部转换为利用 Bkd trees 的范围查询)中。因为我们在 ClickHouse 中也使用日期列作为主键列,所以我们没有关闭 Elasticsearch 中日期字段的 Bkd trees。
在这篇博客中,我们重点比较 column-oriented doc_values 数据结构与 ClickHouse 的列存储格式的聚合性能,其他数据结构的比较留待未来的博客讨论。
_source
为了比较 _source 的存储影响,我们使用了两种不同的索引映射:
-
一种存储 _source(参见段数据结构内部)
-
一种不存储 _source
请注意,通过禁用 _source,我们减少了数据存储大小。然而,索引到索引复制操作(例如,用于事后更改索引映射或将索引升级到新主要版本)和更新操作将不再可能。某些查询在性能上也会受到影响,因为 _source 是在请求索引文档字段的全部或大部分子集时最快的检索字段值的方法。尽管存储要求低得多,ClickHouse 始终允许表间复制和更新操作。
变换
为了进行连续数据转换,我们创建了用于预计算聚合的变换。我们优化了自动推导的变换目标索引的索引映射,以消除 _source。
ClickHouse 设置
配置 ClickHouse 比配置 Elasticsearch 要简单得多,所需的前期规划和设置代码也更少。
ClickHouse 配置
ClickHouse 以原生二进制方式部署。我们安装了 ClickHouse 版本 24.4,使用默认设置,无需配置内存设置。ClickHouse 服务器进程大约需要 1 GB 的 RAM 加上执行查询的峰值内存使用量。与 Elasticsearch 类似,ClickHouse 将利用机器剩余的可用内存来缓存从磁盘加载到操作系统级文件系统缓存中的数据。
表
我们创建了不同大小的 PyPi 数据集表,并使用了不同的压缩编码。
列压缩编码
类似于 Elasticsearch,我们测试了使用较重的 ZSTD 而不是默认的 LZ4 列压缩编码来存储数据。
表排序
为了进行公平的存储比较,我们使用了与 Elasticsearch 相同的数据排序方案,以支持列压缩编码的最佳压缩比。为此,我们将表的所有列添加到表的主键中,并按基数升序排列(这样可以确保最高的压缩率)。
表模式
下图勾勒了一个 PyPi ClickHouse 表的结构:
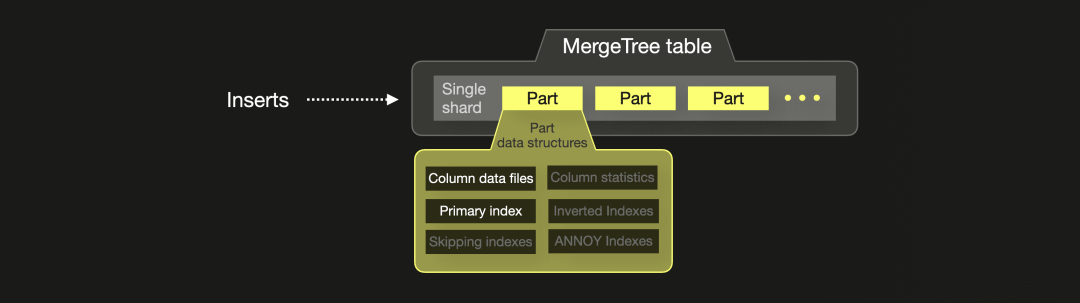
由于 ClickHouse 在单台机器上运行,因此每个表默认包含一个分片。插入会创建部分,并在后台合并。
插入的行包含与 Elasticsearch 中摄取的文档完全相同的 4 个字段。我们在 ClickHouse 表中将这些字段存储在 4 列中:
-
country_code
-
project
-
url
-
timestamp
基于我们的表模式,为表的所有 4 个列创建了列数据文件。稀疏主索引文件是根据表的排序键列的值创建并填充的。所有其他部分数据结构必须明确配置,并且我们的基准查询不使用这些数据结构。
请注意,我们对 country_code 列使用了 LowCardinality 类型来对其字符串值进行字典编码。虽然这是 ClickHouse 中低基数列的最佳实践,但这不是在此基准测试中 ClickHouse 存储要求大幅降低的主要原因。在这种情况下,对于 PyPi 数据集,与对 country_code 列使用完整的 String 类型相比,存储节省是微不足道的,因为该列的低基数值只是 2 个字母的代码,当数据按 country_code 排序时,这些代码压缩得很好。
物化视图
为了连续数据转换,我们创建了等同于 Elasticsearch 变换的物化视图,用于预计算聚合。
ClickHouse Cloud 设置
作为一个附带实验,我们也在 ClickHouse Cloud 上运行了相同的基准测试。
为此,我们创建了上述相同的表和物化视图,并将相同的数据量加载到一个 ClickHouse Cloud 服务中,该服务的硬件规格与我们的 EC2 测试机器大致相同:每个计算节点具有 30 个 CPU 核心和 120 GB RAM。这是最接近的匹配。请注意,ClickHouse 使用 1:4 的 CPU 对内存比例。此外,存储和计算是分离的。所有水平和垂直可扩展的 ClickHouse 计算节点都可以访问存储在对象存储中的相同物理数据,并且实际上是单个无限分片的多个副本:
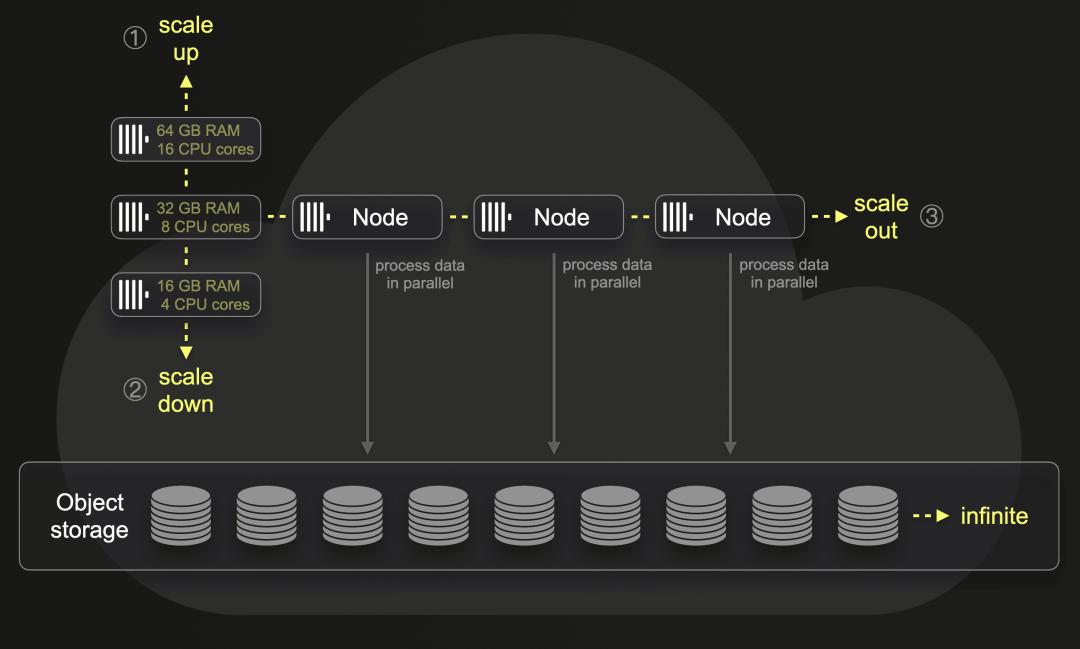
默认情况下,每个 ClickHouse Cloud 服务具有三个计算节点。传入查询通过负载均衡器路由到运行查询的特定节点。可以手动或自动简单地扩展计算节点的大小或数量。根据并行副本设置,可以通过多个节点并行处理单个查询,这不需要对实际数据进行任何物理重新分片或重新平衡。
我们将在 ClickHouse Cloud 服务中使用单个节点和多个并行节点运行一些基准查询。
基准查询说明
在 Elasticsearch 中,等同于 ClickHouse 的 count(*) 聚合(使用 SQL GROUP BY 子句和 count(*) 聚合函数)的是 terms 聚合。这里我们描述 Elasticsearch 和 ClickHouse 在底层如何处理这些查询。
我们在原始(未预先聚合)数据集上测试以下 count(*) 聚合查询的冷运行性能:
-
查询 ① - 最受欢迎的 3 个 PyPi 项目:该查询对整个数据集进行全扫描,聚合数据,排序并返回前 3 个结果。
-
ClickHouse SQL 查询
-
Elasticsearch DSL 查询
-
Elasticsearch ESQL 查询
-
-
查询 ② - 某一国家的前 3 个 PyPi 项目:该查询在聚合、排序和限制之前对数据集进行过滤。
-
ClickHouse SQL 查询
-
Elasticsearch DSL 查询
-
Elasticsearch ESQL 查询
-
我们还测试了相同查询在预先聚合的数据集上的性能:
-
查询 ①
-
ClickHouse SQL 查询
-
Elasticsearch DSL 查询**
-
Elasticsearch ESQL 查询**(不支持)
-
-
查询 ②
-
ClickHouse SQL 查询
-
Elasticsearch DSL 查询**
-
Elasticsearch ESQL 查询**(不支持)
-
请注意,在基准测试中,我们没有增加 term 聚合的分片大小参数值。
**我们发现使用 Elasticsearch 转换来预先计算桶大小时存在一个小问题。例如,预先计算每个项目的计数时,我们会按项目分组,然后使用 terms 聚合(也是按项目分组)来预先计算每个项目的计数。转换加载到目标索引的文档如下:
{
"project_group": "boto3",
"project": {
"terms": {
"boto3": 28202786
}
}
}转换目标索引的映射如下:
{
"project_group": {
"type": "keyword"
},
"project": {
"properties": {
"terms": {
"type": "flattened"
}
}
}
}请注意使用了扁平化字段类型。使用这种类型处理 terms 聚合的结果值是合理的。否则,每个唯一项目名称都需要一个单独的映射条目,这在预先不知道项目名称的情况下是不可能的,而且会导致动态映射时映射条目的爆炸增长。
这为我们的基准查询带来了两个问题:
-
扁平化类型目前不被 ESQL 支持。
-
所有值都被视为关键字。排序时,这意味着我们预先计算的计数值是按字典顺序而不是数值顺序进行比较的。因此,运行在转换索引上的 Elasticsearch 查询需要使用一个小的 painless 脚本,以启用预先计算的计数值的数值排序。
基准测试方法
在启用缓存的情况下,尤其是查询结果缓存,Elasticsearch 和 ClickHouse 能几乎瞬时地通过从缓存中获取数据提供结果。然而,我们关注的是在冷缓存情况下运行聚合查询,此时查询处理引擎必须从头开始加载和扫描数据并计算聚合结果。
查询运行时间
我们对数据集运行所有基准查询,这些数据集:
-
使用 Elasticsearch 和 ClickHouse 标准 LZ4 编码压缩
-
不在 Elasticsearch 中存储 _source
所有查询都在冷缓存情况下执行三次。每次只执行一个查询,即只测量延迟。在本文的图表中,我们将平均执行时间作为最终结果,并链接到详细的基准测试运行结果。
Elasticsearch
我们通过 Search REST API 运行 Elasticsearch 查询(DSL),并使用 JSON 响应主体中的 took 时间,表示服务器端的总执行时间。
ESQL 查询通过 ESQL REST API 执行。Elasticsearch ESQL 查询的响应不包括任何运行时间信息。不过,ESQL 查询的服务器端执行时间记录在 Elasticsearch 的日志文件中。
我们知道查询运行时间也可以在搜索慢日志中获得,但这些仅限于每个分片的级别,而不是整个查询执行的合并形式。
ClickHouse
所有 ClickHouse SQL 查询通过 ClickHouse 客户端执行,并从 query_log 系统表(query_duration_ms 字段)获取服务器端执行时间。
禁用缓存
Elasticsearch
对于查询处理,Elasticsearch 利用操作系统级文件系统缓存、分片级请求缓存和段级查询缓存。
对于 DSL 查询,我们在每个请求的基础上使用 request_cache-query-string 参数禁用请求缓存。然而,这对 ESQL 查询是不可能的。
查询缓存只能按索引启用或禁用,不能按请求启用或禁用。相反,我们在每次查询运行之前通过 clear cache API 手动清除请求和查询缓存。
Elasticsearch 没有 API 或设置来丢弃或忽略文件系统缓存,所以我们通过一个简单的过程手动清除它。
ClickHouse
与 Elasticsearch 类似,ClickHouse 利用操作系统文件系统缓存和查询缓存进行查询处理。
这两个缓存可以通过 SYSTEM DROP CACHE 语句手动清除。
我们通过查询的 SETTINGS 子句禁用每个查询的两个缓存:
… SETTINGS enable_filesystem_cache=0, use_query_cache=0;
查询峰值内存使用情况
ClickHouse
我们使用 ClickHouse query_log 系统表来跟踪和报告查询的峰值内存消耗(memory_usage 字段)。另外,我们还报告了某些查询的数据处理吞吐量(行/秒和 GB/秒),如 ClickHouse 客户端所报告的。这也可以通过 query_log 字段(例如 read_rows 和 read_bytes 除以 query_duration_ms)计算得出。
Elasticsearch
Elasticsearch 在 Java JVM 中运行所有查询,启动时分配了机器可用 64 GB RAM 的一半。Elasticsearch 不会直接跟踪 JVM 内存中的查询峰值内存消耗。Kibana 图形搜索分析器后台使用的搜索分析 API 仅分析查询的 CPU 使用情况。同样,搜索慢日志只跟踪运行时间而不跟踪内存。集群统计 API 返回集群和节点级别的指标和统计信息,例如当前的 JVM 内存使用峰值,可以通过调用 GET /_nodes/stats?filter_path=nodes.*.jvm.mem.pools.old 获得。这些统计信息与特定查询运行相关联可能很棘手,因为这些是考虑到所有查询和更广泛进程(包括内存密集型的后台段合并)的节点级别指标。因此,我们的基准测试结果不报告 Elasticsearch 查询的峰值内存使用情况。
基准测试结果
总结
在详细展示基准测试结果之前,我们先提供一个简要总结。
10 亿行数据集
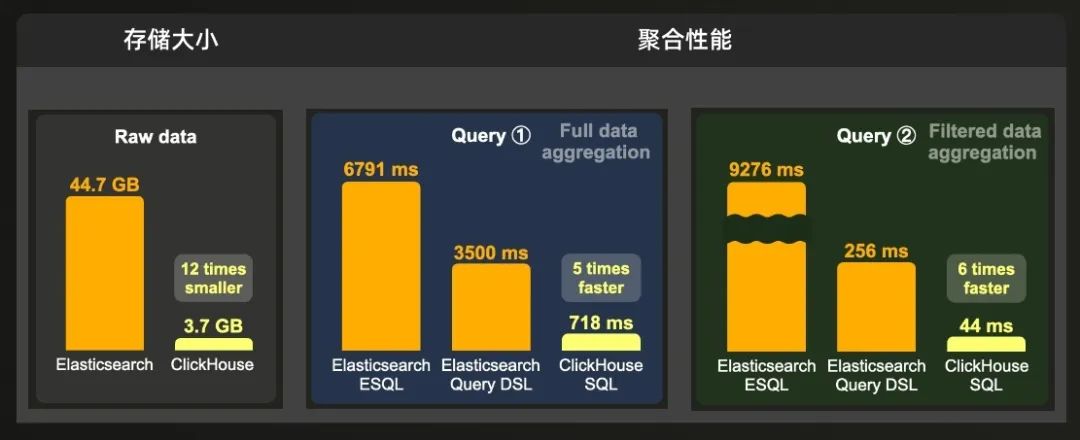
ClickHouse 存储 10 亿行数据集所需的磁盘空间比 Elasticsearch 少 12 倍。聚合查询 ①(执行全数据集聚合)在 ClickHouse 上的运行速度是 Elasticsearch(查询 DSL)的 5 倍。聚合查询 ②(聚合过滤后的数据集)在 ClickHouse 上的运行速度是 Elasticsearch(查询 DSL)的 6 倍。

当 10 亿行数据集以预聚合形式存在以加快聚合查询 ① 时,ClickHouse 所需的磁盘空间比 Elasticsearch 少 10 倍,并且在这个数据上的聚合查询 ① 运行速度是 Elasticsearch 的 9 倍。

当 10 亿行数据集以预聚合形式存在以加快聚合查询 ② 时,ClickHouse 存储这些数据的大小比 Elasticsearch 小 9 倍,并且过滤和聚合数据的速度是 Elasticsearch 的 5 倍。
100 亿行数据集
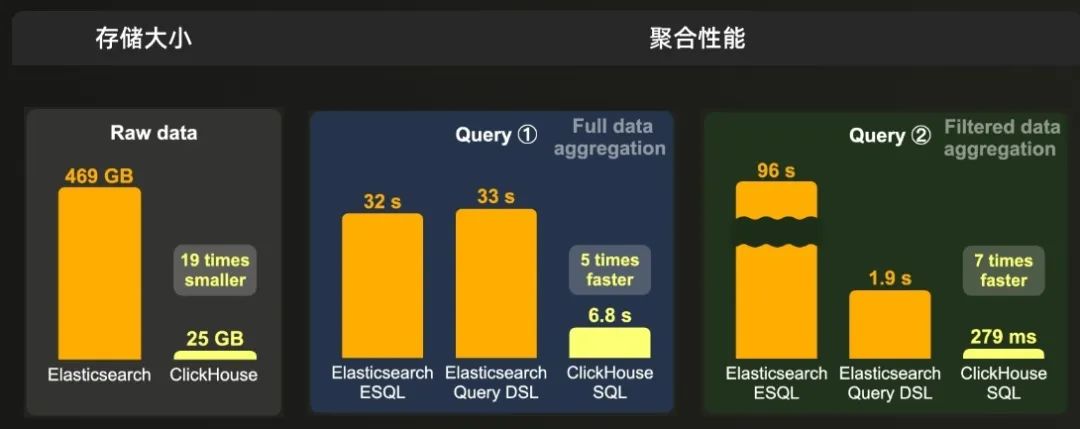
ClickHouse 存储原始数据的大小比 Elasticsearch 小 19 倍,并且全数据集聚合的速度是 Elasticsearch 的 5 倍,过滤数据集的速度是 7 倍。

当原始数据预聚合以加快聚合查询 ① 时,ClickHouse 所需的磁盘空间比 Elasticsearch 少 10 倍,并且聚合查询 ① 的运行速度是 Elasticsearch 的 12 倍。

当原始数据预聚合以加快聚合查询 ② 时,ClickHouse 存储数据的大小比 Elasticsearch 小 7 倍,并且过滤和聚合数据的速度是 Elasticsearch 的 5 倍。
在本节的其余部分,我们将首先详细展示 PyPi 数据集在原始(未预聚合)和预聚合形式下的存储大小。之后,我们将展示这些数据集上运行聚合查询的详细运行时间。
存储大小
原始数据
以下展示了原始(未预聚合)1、10 和 100 亿行 PyPi 数据集的存储大小。
10 亿行
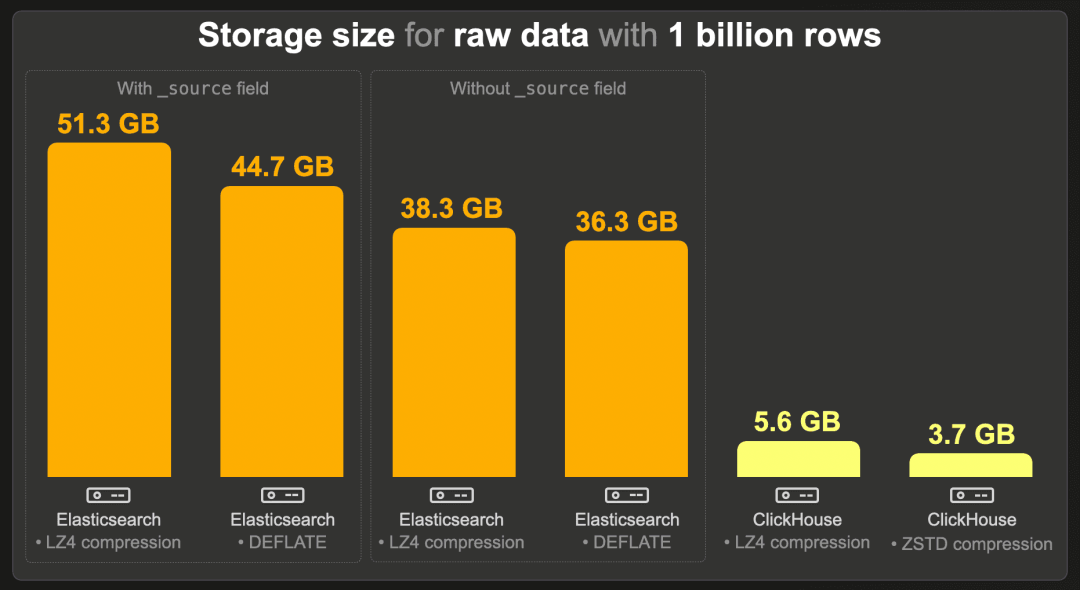
启用 _source 时,Elasticsearch 在默认的 LZ4 压缩下需要 51.3 GB。使用 DEFLATE 压缩时,这一数值减少到 44.7 GB。正如预期,我们的索引排序配置启用了高压缩比:如果没有索引排序,索引大小将是 135.6 GB(LZ4)和 91.5 GB(DEFLATE)。
禁用 _source 将存储大小减少到 38.3 GB(LZ4)和 36.3 GB(DEFLATE)之间。
索引编解码器(LZ4 或 DEFLATE)仅应用于存储字段(包括 _source),而不应用于 doc_values,这是在禁用 _source 后我们索引中剩余的主要数据结构。在 doc_values 中,每个列基于数据类型和基数单独编码(不使用 LZ4 或 DEFLATE)。不过,索引排序确实支持更好的 doc_values 前缀压缩,并启用了紧凑且高效访问的 doc-ids 编码。但总体上,doc_values 的压缩率并不像存储字段那样受益于索引排序。例如,在没有索引排序且没有存储字段(禁用 _source)的情况下,Elasticsearch 索引的存储大小为 37.7 GB(LZ4)和 35.4 GB(DEFLATE)。(这些大小甚至比有索引排序的情况略小,这是由于略微不同的滚动时间,导致分片和段的数据结构开销不同。)
与没有 _source 字段和相同压缩级别(LZ4 对 LZ4 和 DEFLATE 对 ZSTD)的 Elasticsearch 索引相比,ClickHouse 表使用 LZ4 时所需的存储空间约少 7 倍,使用 ZSTD 时约少 10 倍。
在 Elasticsearch 中,_source 字段是必须的,以功能上等同于 ClickHouse(例如,启用更新操作和运行重新索引操作,相当于 ClickHouse INSERT INTO SELECT 查询)。当使用相同的压缩级别(LZ4 对 LZ4 和 DEFLATE 对 ZSTD)时,ClickHouse 需要的存储空间少 9 到 12 倍。
100 亿行
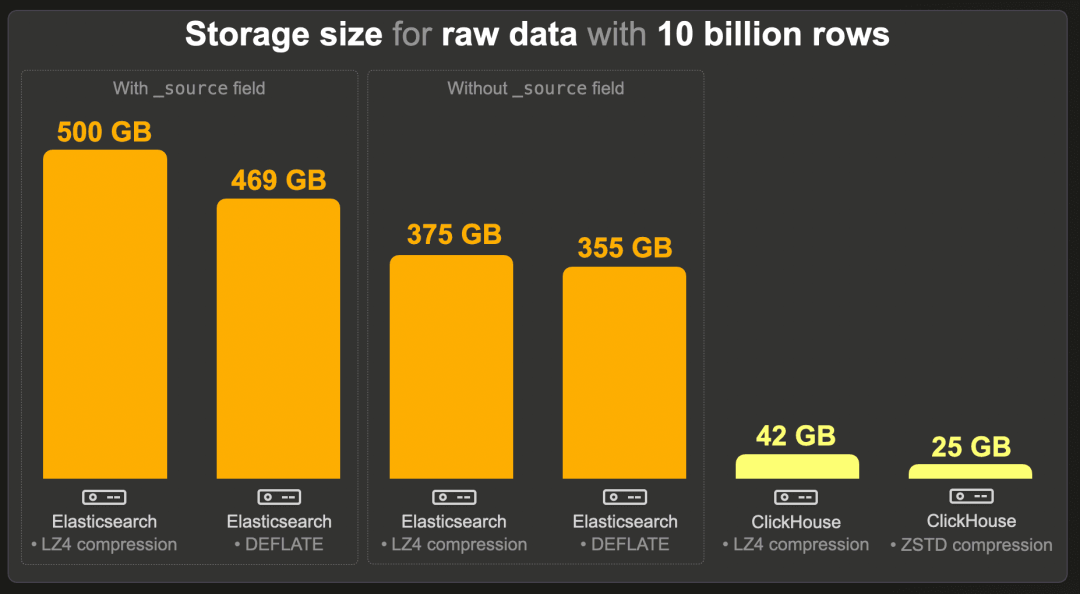
与 10 亿事件数据集类似,我们在 Elasticsearch 中测量了启用和禁用 _source 以及使用默认 LZ4 和较重 DEFLATE 编解码器的存储大小。同样,索引排序允许更高的压缩比(例如,没有索引排序且启用 _source 的情况下,索引大小将达到 1.3 TB(LZ4))。
与没有 _source 字段和相同压缩级别(LZ4 对 LZ4 和 DEFLATE 对 ZSTD)的 Elasticsearch 索引相比,ClickHouse 表需要的存储空间比 Elasticsearch 少 9 倍,比使用 ZSTD 压缩的 Elasticsearch 少 14 倍以上。
然而,当 Elasticsearch 的功能与 ClickHouse 等同(即在 Elasticsearch 中保留 _source)并且使用相同的压缩级别(LZ4 对 LZ4 和 DEFLATE 对 ZSTD)时,ClickHouse 需要的存储空间少 12 到 19 倍。
1000 亿行
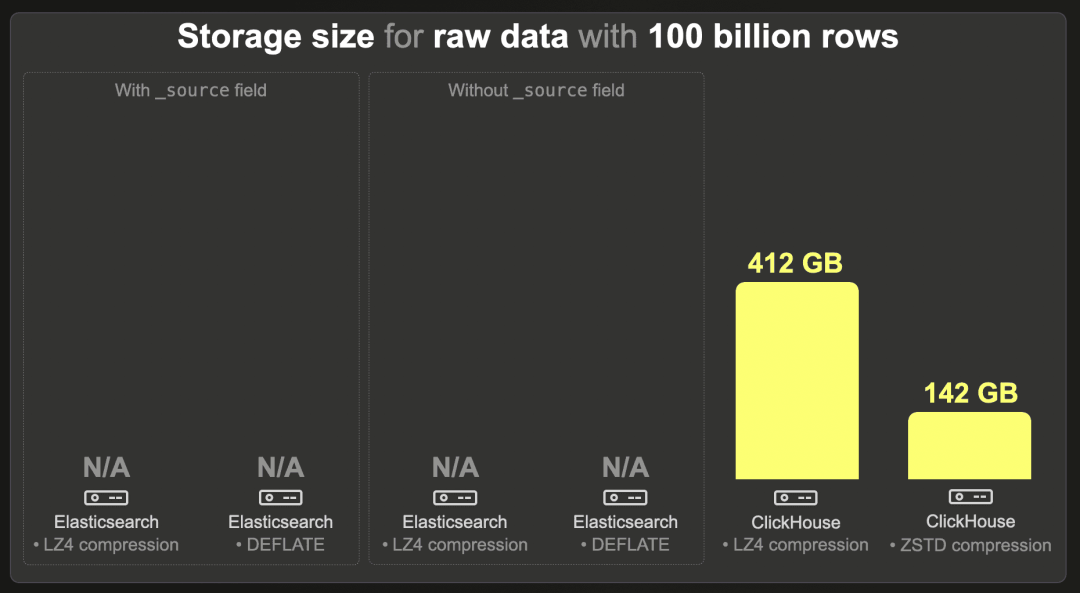
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 使用 LZ4 压缩时需要 412 GB,使用 ZSTD 压缩时需要 142 GB。
为了加快查询 ① 的预聚合数据
为了显著加快聚合查询 ① 计算最受欢迎的前三个项目,我们在 Elasticsearch 中使用了转换功能,在 ClickHouse 中使用了物化视图。这些功能会自动将摄取的原始(未预聚合)数据转换为单独的预聚合数据集。在本节中,我们展示这些数据集的存储大小。
10 亿行
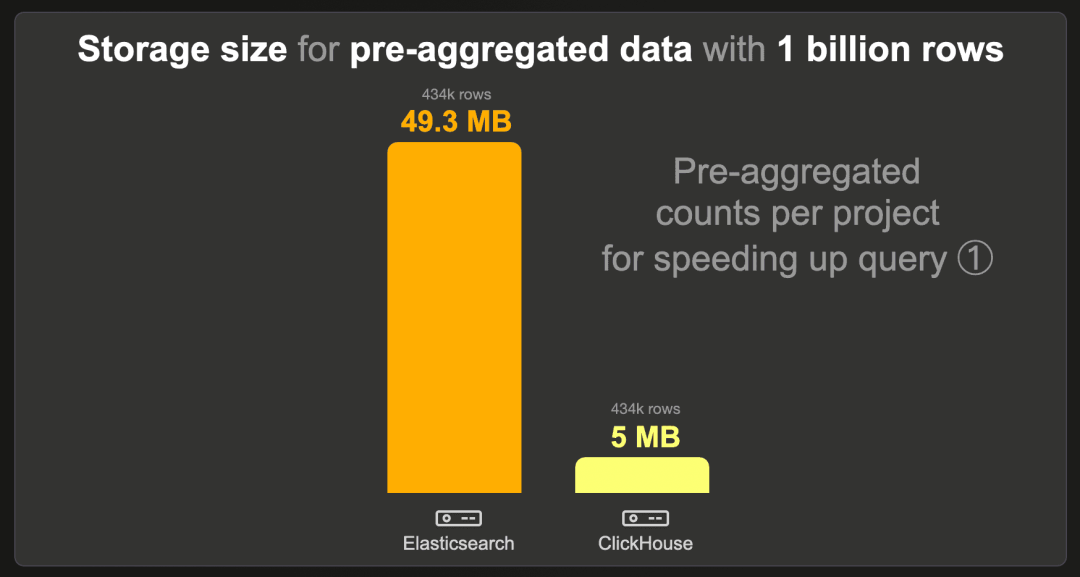
每个项目预聚合计数的数据集包含 434k 行,而不是原始的 10 亿行,因为每个现有项目有一行预计算的计数。我们对 Elasticsearch 和 ClickHouse 使用了标准的 LZ4 压缩编解码器,并在 Elasticsearch 中禁用了 _source。
ClickHouse 需要的存储空间比 Elasticsearch 少约 10 倍。
100 亿行
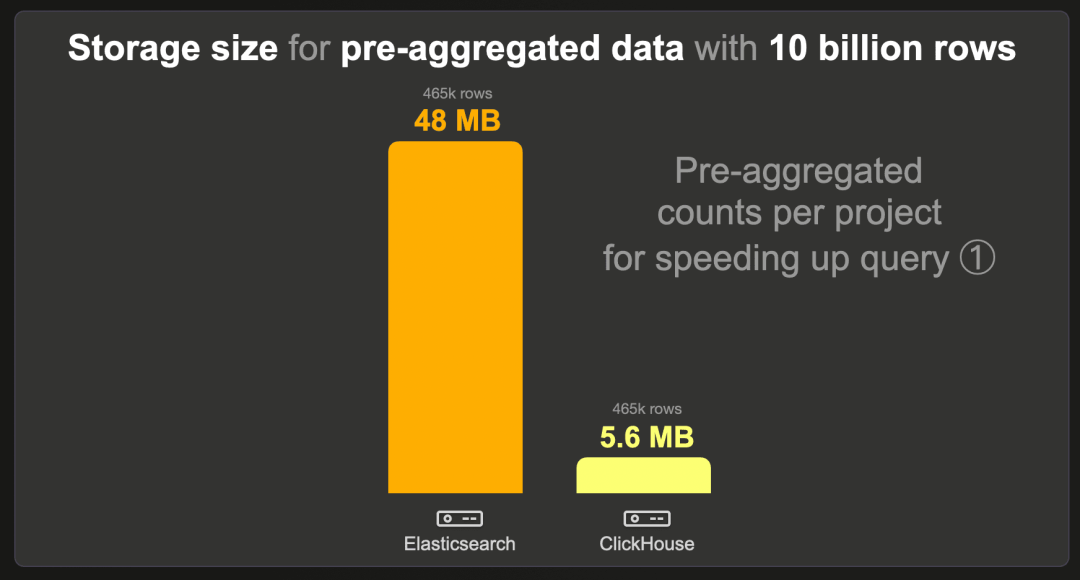
每个项目预聚合计数的数据集包含 465k 行,而不是 100 亿行,因为每个现有项目有一行预计算的计数。我们对 Elasticsearch 和 ClickHouse 使用了标准的 LZ4 压缩编解码器,并在 Elasticsearch 中禁用了 _source。
ClickHouse 需要的存储空间比 Elasticsearch 少 8 倍以上。
1000 亿行
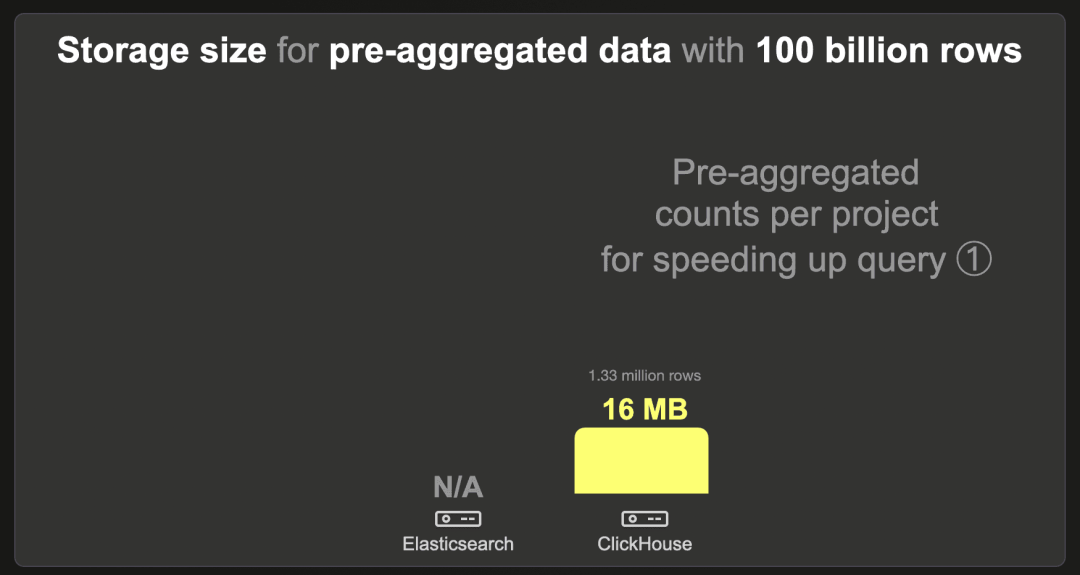
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 使用 LZ4 压缩时需要 16 MB。
为了加快查询 ② 的预聚合数据
同样,为了加快特定国家聚合查询 ② 的前三个项目,我们创建了单独的预聚合数据集,其存储大小如下所示。
10 亿行
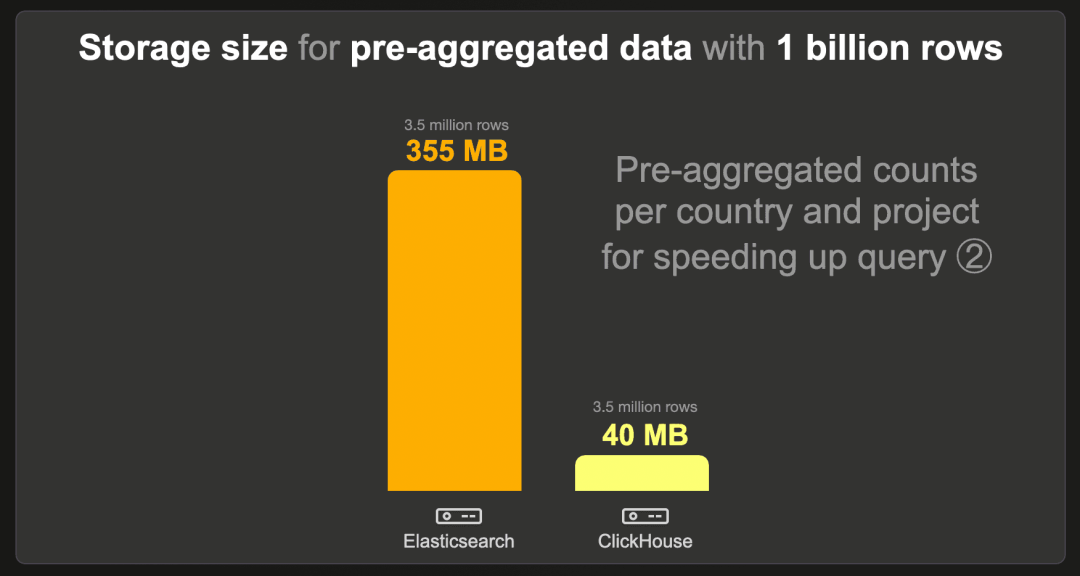
每个国家和项目的预聚合计数数据集包含 350 万行,而不是原始的 10 亿行,因为每个现有国家和项目组合有一行预计算的计数。我们对 Elasticsearch 和 ClickHouse 使用了标准的 LZ4 压缩编解码器,并在 Elasticsearch 中禁用了 _source。
ClickHouse 需要的存储空间比 Elasticsearch 少约 9 倍。
100 亿行
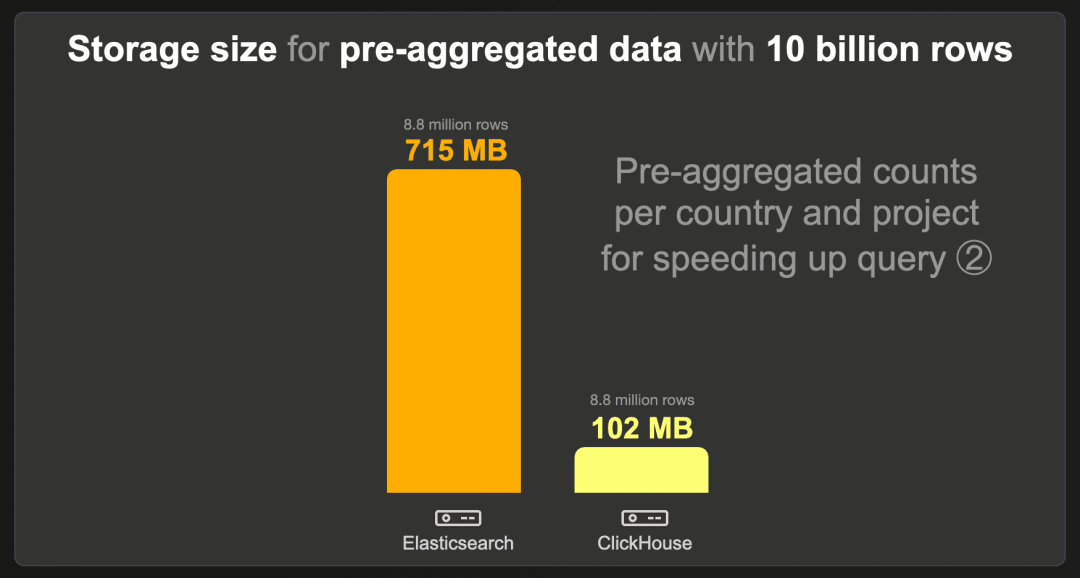
每个国家和项目的预聚合计数数据集包含 880 万行,而不是原始的 100 亿行,因为每个现有国家和项目组合有一行预计算的计数。我们对 Elasticsearch 和 ClickHouse 使用了标准的 LZ4 压缩编解码器,并在 Elasticsearch 中禁用了 _source。
ClickHouse 需要的存储空间比 Elasticsearch 少 7 倍。
1000 亿行
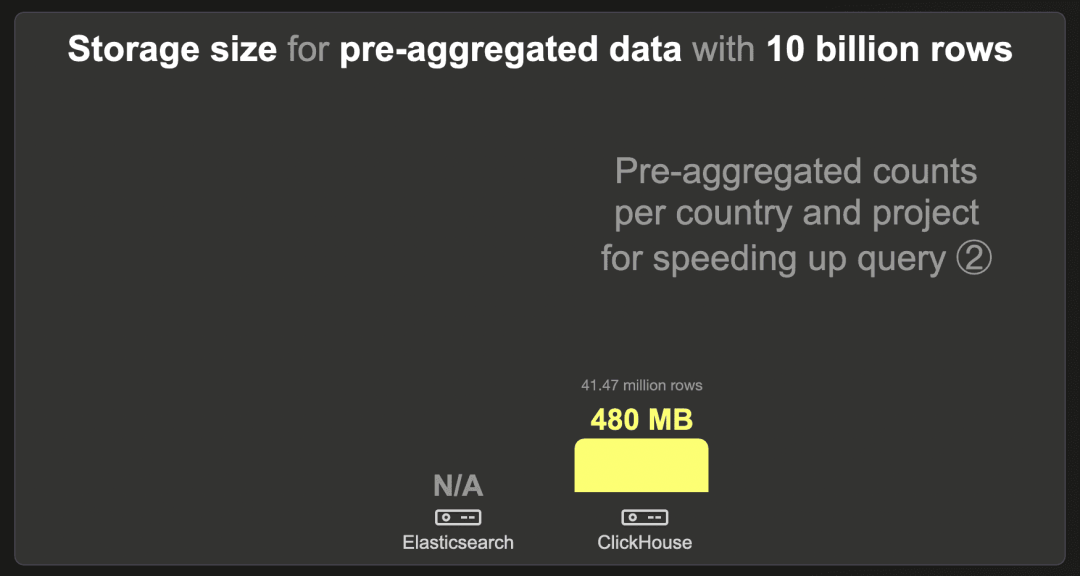
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 使用 LZ4 压缩时需要 480 MB。
聚合性能
本节展示了在原始(未预聚合)和预聚合数据集上运行我们的聚合基准查询的运行时间。
查询 ① - 全数据聚合
本节展示了基准查询 ① 的运行时间,该查询聚合并对整个数据集进行排名。
10 亿行 - 原始数据
这是在原始(未预聚合)10 亿行数据集上运行我们最受欢迎的前三个项目聚合查询的冷查询运行时间:
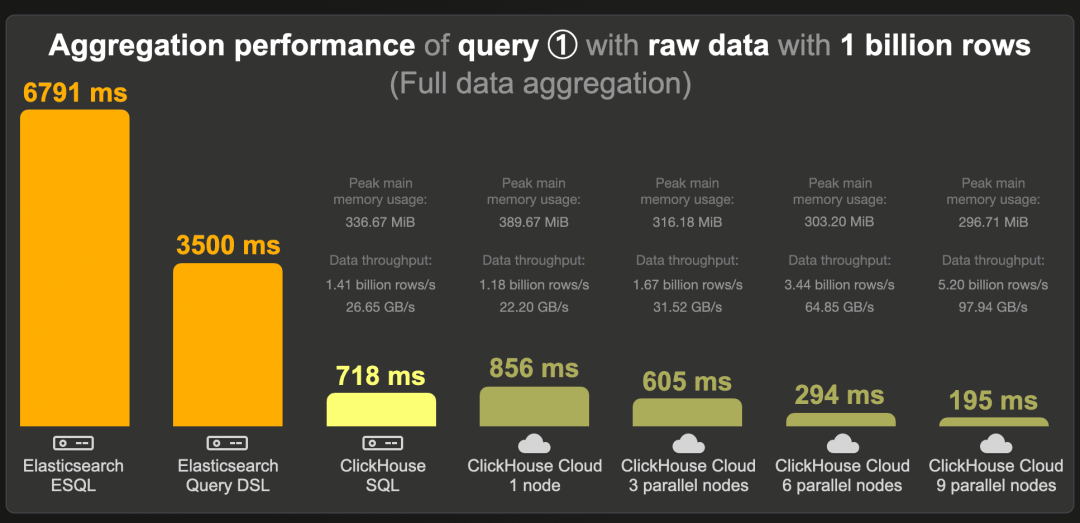
使用新的 ESQL 查询语言,Elasticsearch 运行查询的时间为 6.8 秒。通过传统的查询 DSL,运行时间为 3.5 秒。
我们注意到,在这个数据集上,查询 DSL 似乎比 ESQL 更好地利用了索引排序。当我们选择在未排序的索引上运行查询时,查询 DSL 的运行时间为 9000 秒,而 ESQL 为 9552 秒。
在相同规格的机器上,ClickHouse 运行查询的速度约为 Elasticsearch 的 5 倍。
在 ClickHouse Cloud 中,当在单个(相同规格的)计算节点上运行查询时,由于需要先从对象存储中获取数据到节点缓存中,冷运行时间比开源 ClickHouse 略慢。然而,启用节点并行查询处理后,单个 3 节点的 ClickHouse Cloud 服务运行查询的速度更快。通过水平扩展,这个运行时间可以进一步减少。当在 9 个计算节点上并行运行查询时,ClickHouse 每秒处理 52 亿行,数据吞吐量接近 100 GB 每秒。
请注意,我们用查询的峰值主内存使用量注释了 ClickHouse 的运行时间,对于完全聚合的数据量来说是适中的。
我们想找出在什么最小机器规格下 ClickHouse 可以以与在 32 核 EC2 机器上运行 Elasticsearch 查询相匹配的速度运行聚合查询。换句话说,我们试图看到使用更少的资源情况下 ClickHouse 会变慢,从而更接近 Elasticsearch。最快的方法是缩小 Elastic Cloud 计算节点,并在单个节点上运行查询。在 8 核 CPU 而不是 32 核的情况下,聚合查询在单个 ClickHouse Cloud 节点上的冷运行时间为 2763 毫秒(禁用缓存的情况下)。32 核的 EC2 机器是 c6a.8xlarge 实例,每小时价格从 $1.224 开始。8 核实例是 c6a.2xlarge,每小时价格从 $0.306 开始,比前者便宜 4 倍。
10 亿行 - 预聚合数据
这是在预聚合计数数据集(而非原始的 10 亿行数据集)上运行最受欢迎的前三个项目查询的运行时间:
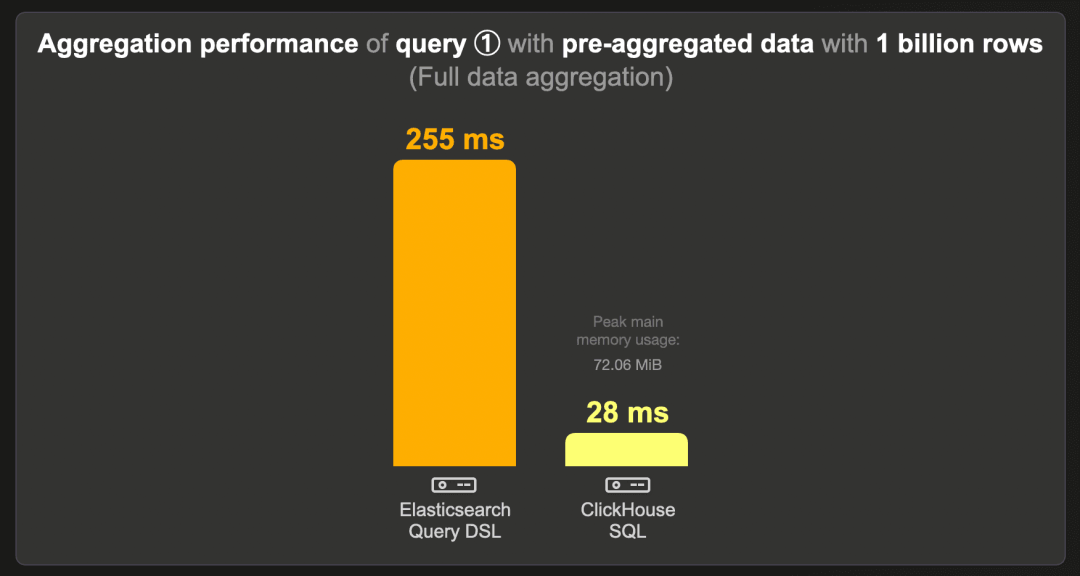
如前所述,ESQL 目前不支持用于生成预聚合数据集的扁平字段类型。
ClickHouse 运行查询的速度比 Elasticsearch 快 9 倍,使用约 75 MB 的 RAM。同样,由于查询延迟较低,使用并行 ClickHouse Cloud 计算节点对这个查询没有意义。
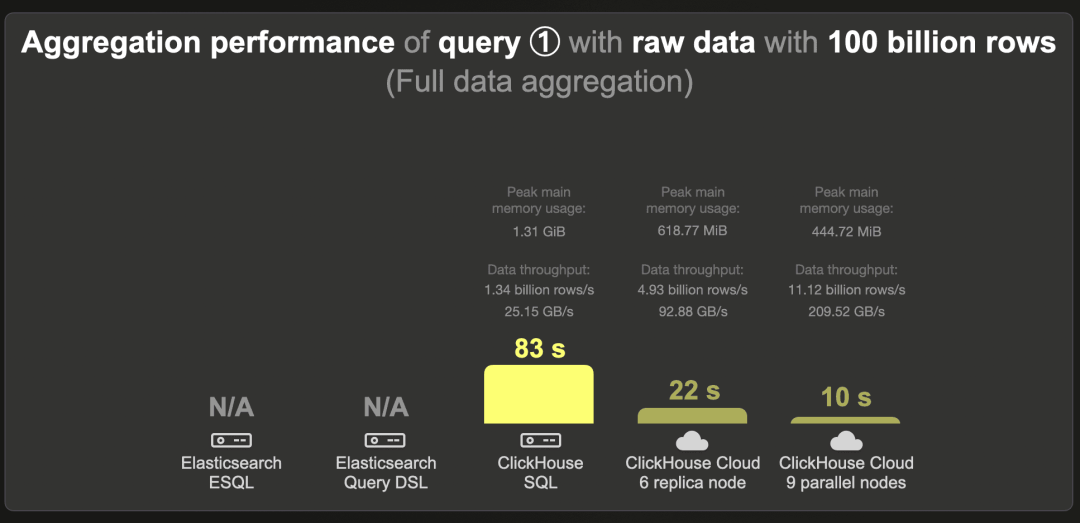
100 亿行 - 原始数据
这是在原始(未预聚合)100 亿行数据集上运行我们最受欢迎的前三个项目聚合查询的冷查询运行时间:
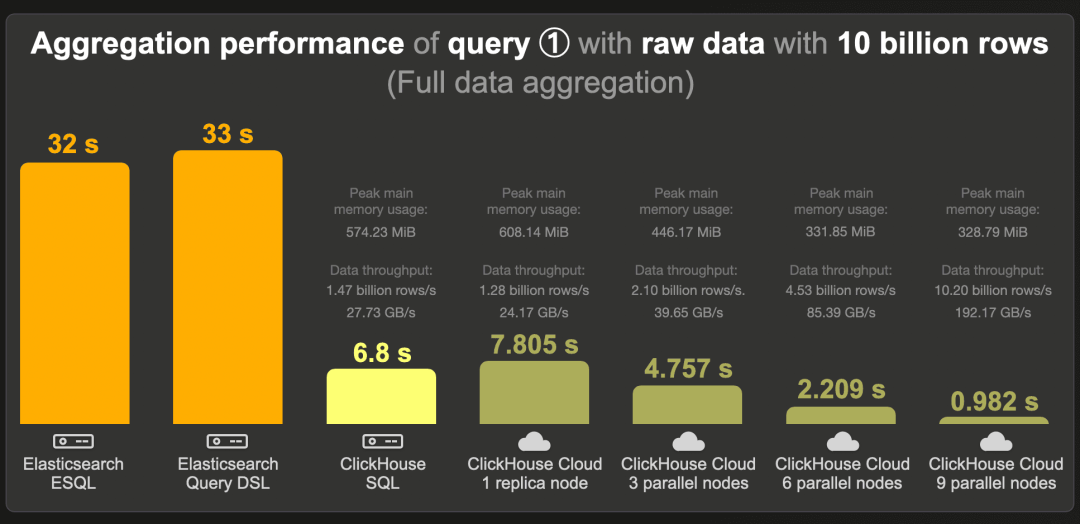
通过 ESQL 和查询 DSL 查询,Elasticsearch 分别需要 32 和 33 秒。
ClickHouse 运行查询的速度比 Elasticsearch 快约 5 倍,使用约 600 MB 的 RAM。
在 9 个计算节点并行的情况下,ClickHouse Cloud 为聚合完整的 100 亿行数据集提供了亚秒级延迟,查询处理吞吐量为每秒 102 亿行 / 每秒 192 GB。
100 亿行 - 预聚合数据
这是在预聚合计数数据集(而非原始的 100 亿行数据集)上运行最受欢迎的前三个项目查询的运行时间:
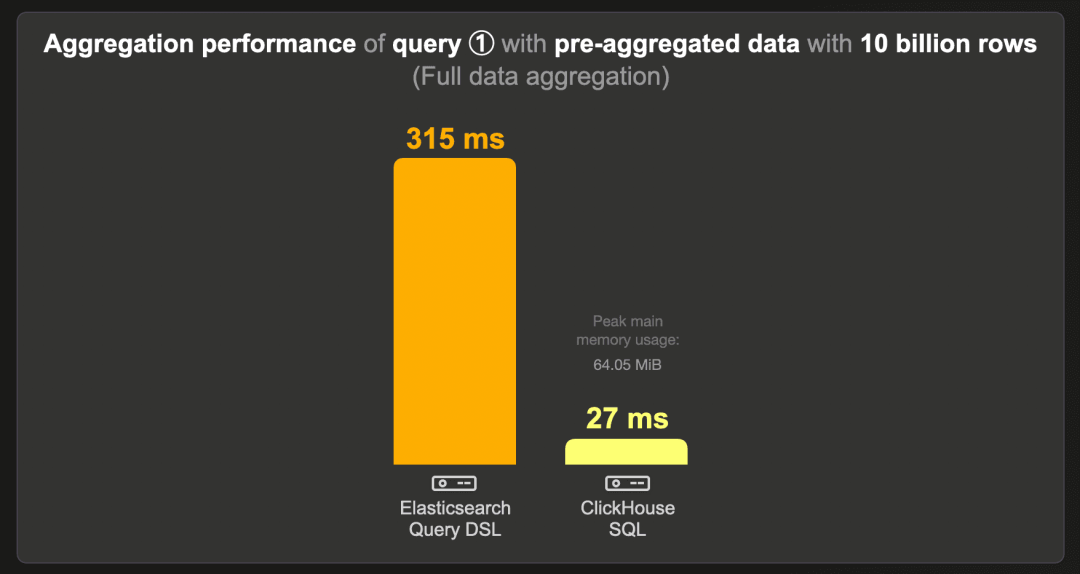
ClickHouse 运行查询的速度比 Elasticsearch 快约 12 倍,使用约 67 MB 的 RAM。
1000 亿行 - 原始数据
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
为了完整性,我们在这里展示 ClickHouse 查询的运行时间。在我们的测试机器上,ClickHouse 在 83 秒内运行查询。
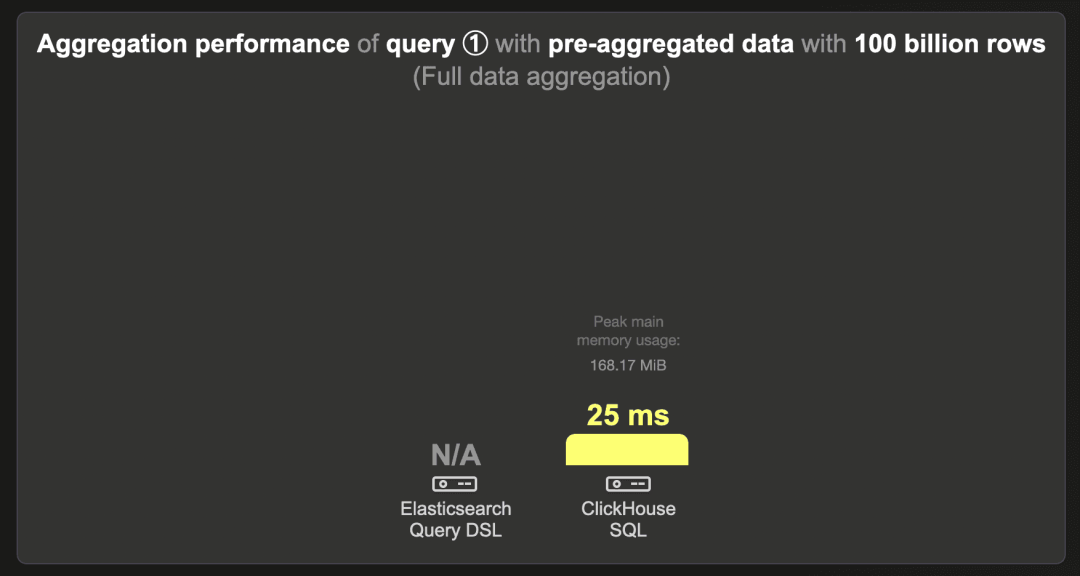
1000 亿行 - 预聚合数据
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 在 25 毫秒内运行查询。
查询 ② - 过滤数据聚合
本节展示了我们的聚合基准查询 ② 的运行时间,该查询在对特定国家的数据集应用和排名 count(*) 聚合之前进行过滤。
10 亿行 - 原始数据
下图展示了在原始(未预聚合)10 亿行数据集上,当数据集按特定国家过滤时计算前三个项目的查询冷运行时间:
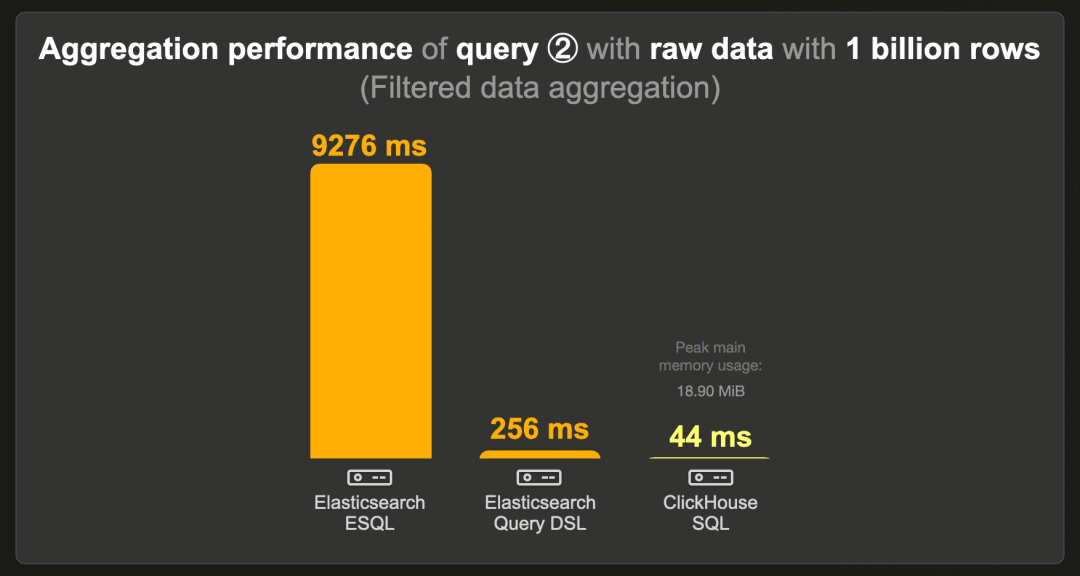
Elasticsearch 的 ESQL 查询运行时间最长,为 9.2 秒。等效的查询 DSL 变体运行速度显著更快(256 毫秒)。
ClickHouse 运行此查询的速度约为 Elasticsearch 的 6 倍,使用不到 20 MB 的 RAM。
由于查询延迟较低,使用并行 ClickHouse Cloud 计算节点对该查询没有意义。
10 亿行 - 预聚合数据
这是在预聚合计数数据集(而非原始的 10 亿行数据集)上运行基准查询 ②(当数据集按特定国家过滤时计算前三个项目)的运行时间:
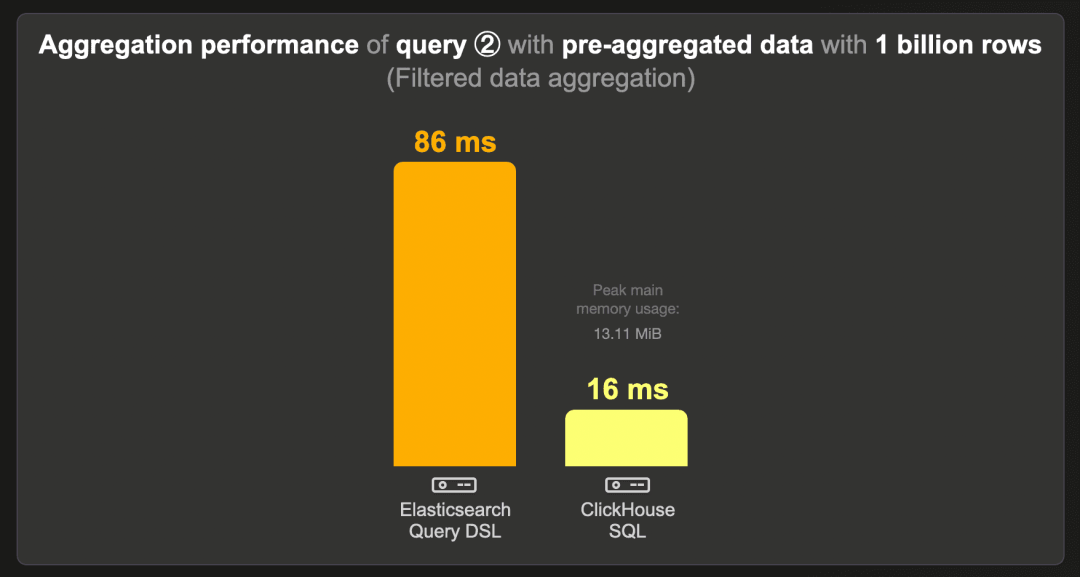
ClickHouse 运行此查询的速度比 Elasticsearch 快 5 倍以上,使用约 14 MB 的 RAM。
100 亿行 - 原始数据
下图展示了在原始(未预聚合)100 亿行数据集上运行基准查询 ② 的冷运行时间:
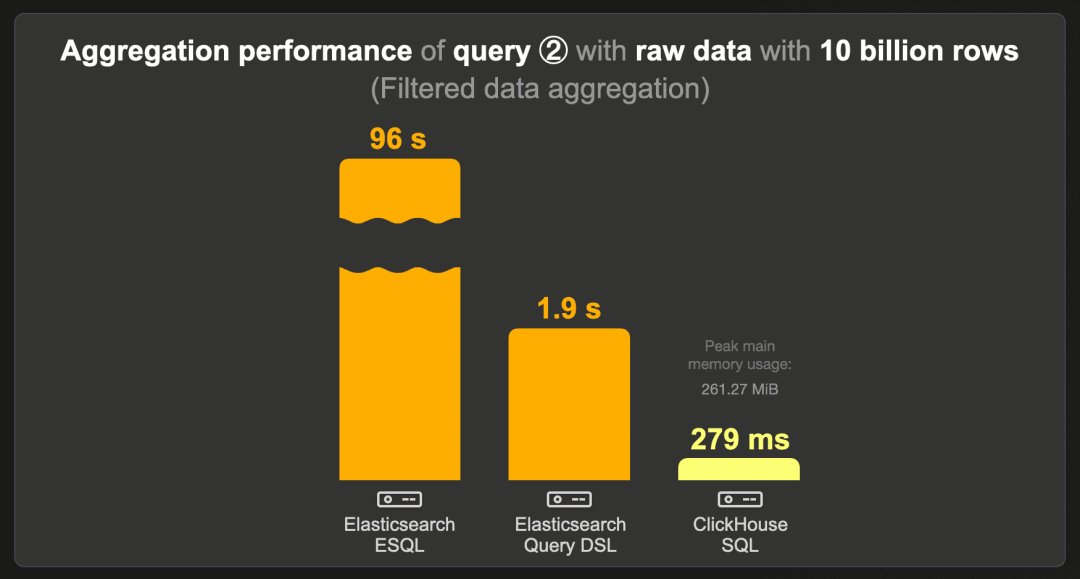
对于此查询,Elasticsearch 的 ESQL 表现不佳,运行时间为 96 秒。
与 Elasticsearch 查询 DSL 的运行时间相比,ClickHouse 运行此查询的速度快近 7 倍,消耗约 273 MB 的 RAM。
100 亿行 - 预聚合数据
这是在预聚合计数数据集(而非原始的 100 亿行数据集)上运行基准查询 ② 的运行时间:
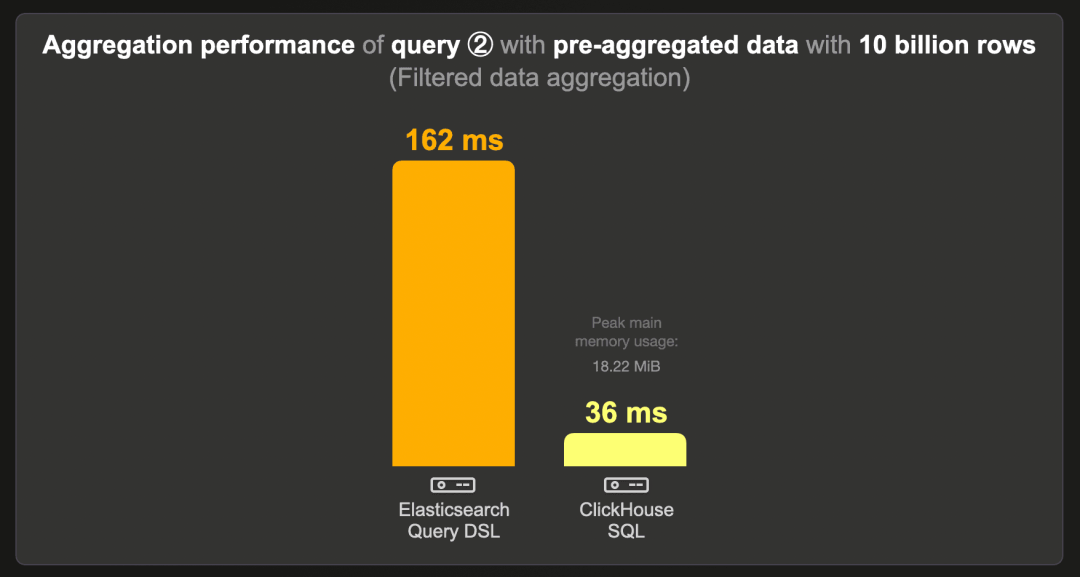
ClickHouse 运行此查询的速度约为 Elasticsearch 的 5 倍,使用约 19 MB 的 RAM。
1000 亿行 - 原始数据
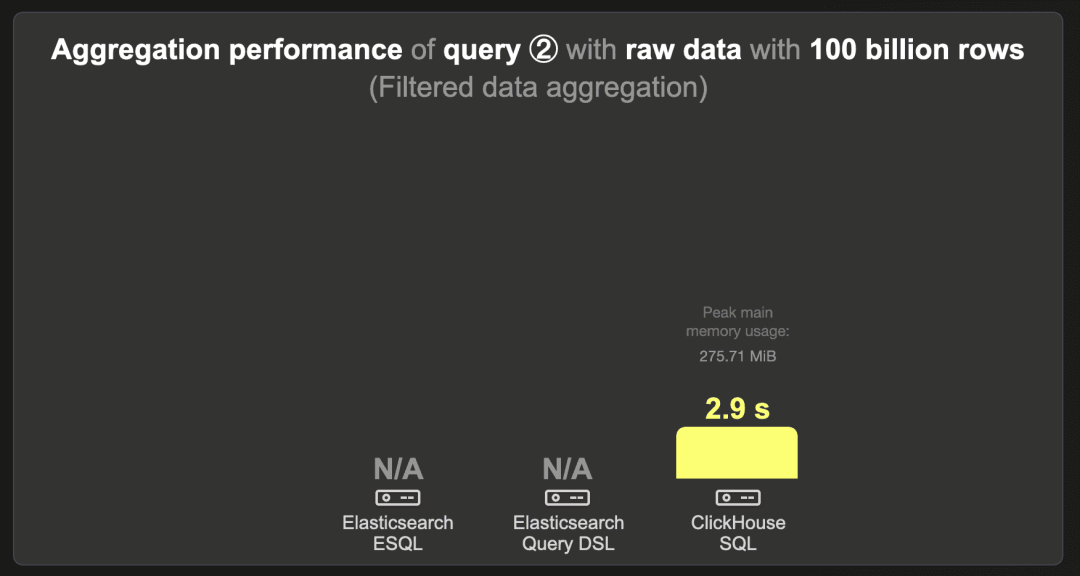
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 在 2.9 秒内运行查询。
1000 亿行 - 预聚合数据
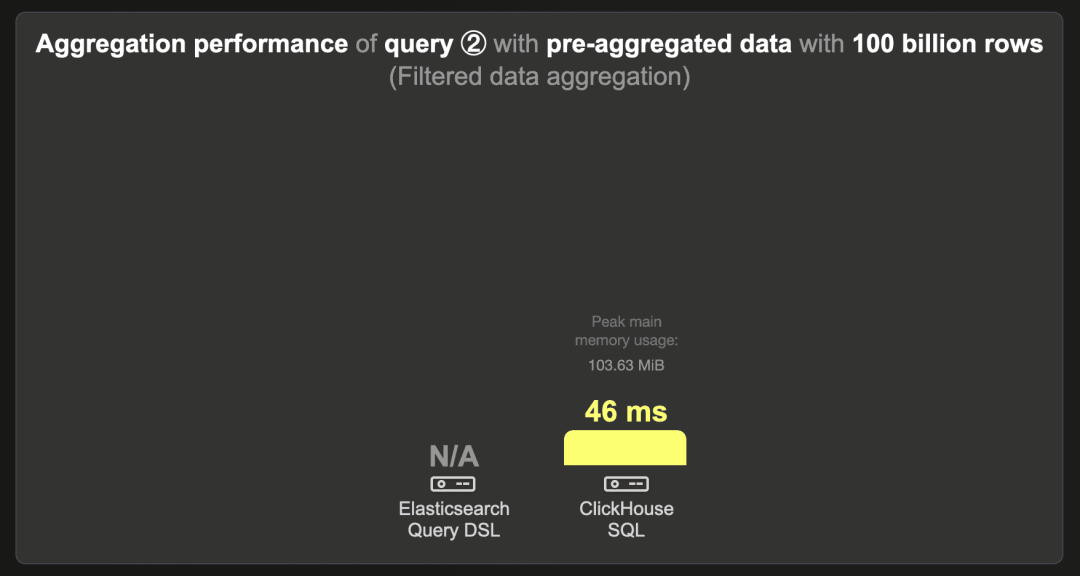
我们无法将 1000 亿行数据集加载到 Elasticsearch 中。
ClickHouse 在 46 毫秒内运行查询。
总结
我们的基准测试表明,对于现代数据分析用例中的大数据集,ClickHouse 可以更高效地存储数据,并比 Elasticsearch 更快地运行 count(*) 聚合查询:
-
ClickHouse 需要的存储空间少 12 到 19 倍,因此可以使用更小更便宜的硬件。
-
ClickHouse 在原始(未预聚合)和预聚合数据集上运行聚合查询的速度至少快 5 倍,使用的硬件成本比 Elasticsearch 低 4 倍。
-
ClickHouse 具有更高效的存储和计算连续数据汇总技术,进一步降低了计算和存储成本。
我们的附带博客文章提供了有关 ClickHouse 为什么如此快和高效的深入技术解释。
潜在的后续文章可以比较多节点集群性能、查询并发性、摄取性能和度量用例。
敬请期待!
Meetup 活动讲师招募
我们正为上海活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。
点击此处或扫描下方二维码,立刻报名成为讲师!

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求