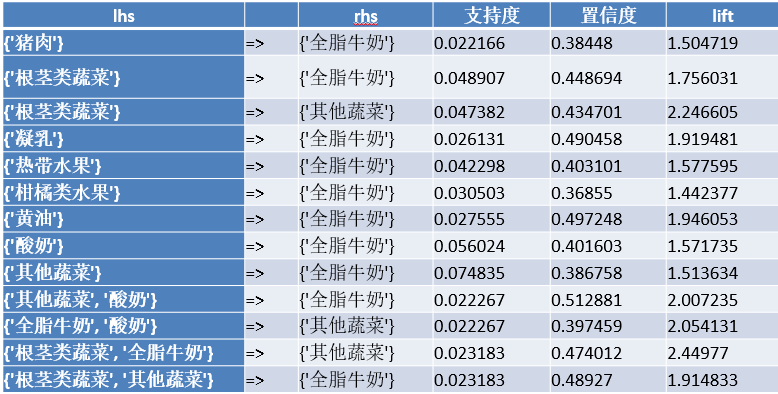
背景
我面临着需要尽可能准确识别手写金额的挑战。难点在于保持误判率低于0.01%。由于数据集中样本数量固定,因此数据增强是合乎逻辑的选择。快速搜索未发现针对光学字符识别(OCR)的现成方法。因此,我挽起袖子,亲自创建了一个数据增强例程。它在训练过程中被使用,并帮助我的模型实现了目标。继续阅读以了解详情。
通过每次训练图像时引入小的变化,模型不太可能过拟合,更容易泛化。我将其与TROCR一起使用,但任何其他模型也应该受益。
测试设置
由于无法分享来自专有数据集的图像,我原本想使用IAM手写数据库的样本,但我未收到使用权限的回复。因此,我为演示创建了一些自己的示例。
我将使用OpenCV和albumentations库进行三种类型的修改:形态学、噪声和变换。
OpenCV是一个众所周知的计算机视觉库。Albumentations是一个相对较新的Python库,用于进行简单但功能强大的图像增强。
还有一个不错的演示网站,你可以在其中尝试albumentations的功能。但由于无法使用自己的图像进行测试,因此我创建了一个Jupyter笔记本,用于在本文中渲染所有增强的图像。请随时在Colab中打开并进行实验。
我们将首先展示单独的修改,附有一些解释,然后讨论将它们结合在一起的技术。我将假设所有图像都是灰度的,并已经进行了对比度增强(例如,CLAHE)。
第一种增强技术:形态学修改
这些与结构的形状有关。简单来说:它们可用于使文本行看起来像用细或粗笔写的。它们被称为腐蚀和膨胀。不幸的是,这些目前还没有包含在albumentations库中,因此我必须借助opencv来实现。
为了产生像是使用宽线宽度笔的效果,我们可以膨胀原始图像:

另一方面,腐蚀(顺便说一下)模拟了使用细笔写的效果:

在这里要小心,最后一个参数——即迭代次数——不要设置得太高(这里设置为3),否则手写完全被去除。
cv2.dilate(img, kernel,iterations=random.randint(1, 3))对于我们的数据集,我们只能将其设置为1,因此这确实取决于你的数据。
第二种增强技术:引入噪声
我们可以从图像中删除黑色像素,也可以添加白色像素。有几种方法可以实现这一点。我尝试了许多方法,但这是我的简短清单:
黑色下降颜色的RandomRain非常有害。即使对我来说,仍然很难阅读文本。这就是为什么我选择将其发生的机会设置得很低的原因:


PixelDropout轻松将随机像素变为黑色:

与黑色滴落相比,具有白色滴落颜色的RandomRain使文字解体,从而增强了训练的难度。就像当拍摄了复印一份传真的照片时看到的低质量一样。可以将此变换发生的概率设置得更高。

在较小程度上,PixelDropout到白色也会产生相同的效果。但它更多地导致图像普遍褪色:

第三种增强技术:变换
ShiftScaleRotate:在这里要小心参数。尽量避免一些文本被切断并超出原始尺寸。同时进行缩放和旋转。确保不要过度使用太大的参数。否则,第一个样本的机会更大。你可以看到它实际上将文本移出图像。通过选择较大的边界框,可以防止这种情况——有效地在文本周围添加更多的空白。

模糊。老(但金贵)可靠的技术。将以不同的强度执行。

大结局:将它们全部组合在一起:
这就是力量所在。我们可以随机组合这些效果,创建每个训练时期都包含的独特图像。需要谨慎考虑,不要做太多相同类型的方法。我们可以使用albumentation库中的OneOf函数来实现这一点。OneOf包含一系列可能的变换,正如其名称所暗示的那样,将仅以概率P执行其中的一个。因此,将做更多或更少相似的变换分组是有意义的,以避免过度使用。以下是该函数:
import random
import cv2
import numpy as np
import albumentations as A
#gets PIL image and returns augmented PIL image
def augment_img(img):
#only augment 3/4th the images
if random.randint(1, 4) > 3:
return img
img = np.asarray(img) #convert to numpy for opencv
# morphological alterations
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
if random.randint(1, 5) == 1:
# dilation because the image is not inverted
img = cv2.erode(img, kernel, iterations=random.randint(1, 2))
if random.randint(1, 6) == 1:
# erosion because the image is not inverted
img = cv2.dilate(img, kernel,iterations=random.randint(1, 1))
transform = A.Compose([
A.OneOf([
#add black pixels noise
A.OneOf([
A.RandomRain(brightness_coefficient=1.0, drop_length=2, drop_width=2, drop_color = (0, 0, 0), blur_value=1, rain_type = 'drizzle', p=0.05),
A.RandomShadow(p=1),
A.PixelDropout(p=1),
], p=0.9),
#add white pixels noise
A.OneOf([
A.PixelDropout(dropout_prob=0.5,drop_value=255,p=1),
A.RandomRain(brightness_coefficient=1.0, drop_length=2, drop_width=2, drop_color = (255, 255, 255), blur_value=1, rain_type = None, p=1),
], p=0.9),
], p=1),
#transformations
A.OneOf([
A.ShiftScaleRotate(shift_limit=0, scale_limit=0.25, rotate_limit=2, border_mode=cv2.BORDER_CONSTANT, value=(255,255,255),p=1),
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0, rotate_limit=8, border_mode=cv2.BORDER_CONSTANT, value=(255,255,255),p=1),
A.ShiftScaleRotate(shift_limit=0.02, scale_limit=0.15, rotate_limit=11, border_mode=cv2.BORDER_CONSTANT, value=(255,255,255),p=1),
A.Affine(shear=random.randint(-5, 5),mode=cv2.BORDER_CONSTANT, cval=(255,255,255), p=1)
], p=0.5),
A.Blur(blur_limit=5,p=0.25),
])
img = transform(image=img)['image']
image = Image.fromarray(img)
return imageP代表事件发生的机会。它是一个介于0和1之间的值,其中1表示它总是发生,0表示永远不会发生。
所以,让我们看看它在实际操作中的效果:

看起来相当不错,对吧?
另一种方法:
在EASTER 2.0论文中,他们提出了TACo技术。它代表平铺和破坏。(🌮哈哈)它能够实现这样的效果:
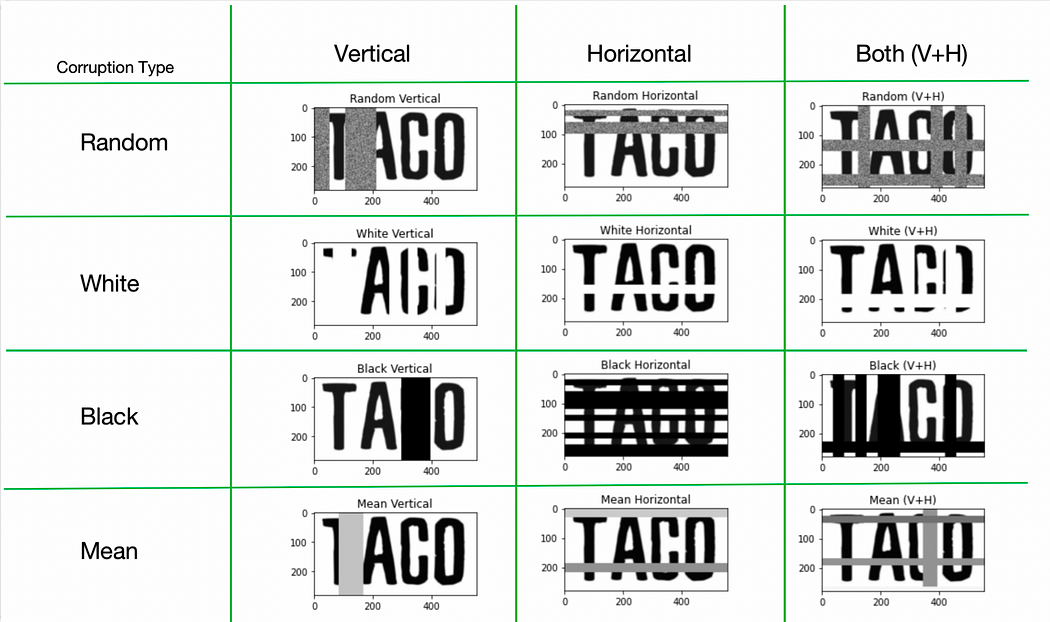
我还没有尝试过这个方法,因为我的直觉告诉我原始图像被破坏得太厉害。在我看来,如果我看不懂它,计算机也一样。然而,当考虑到作为人类,如果看到'TA█O',你可能会猜到它是'TACO'。我们会看周围的字母,而taco是一个常见的词。但是一个有字典支持的计算机可能会将其解读为'TAMO',这恰好是英语中表示“日本灰”的一个词。
结论
我们讨论了许多图像操作以及它们对OCR任务的好处。我希望这对你有所帮助,或者至少给了你一些尝试的灵感。你可以将我的方法作为基准,但可能需要微调一些参数,使其完美适应你的数据集。请告诉我你的模型准确性提高了多少!
我在这个Jupyter笔记本中公开了这个技术。
https://github.com/Toon-nooT/notebooks/blob/main/OCR_data_augmentations.ipynb
参考引用
https://opencv.org/
https://albumentations.ai/
https://fki.tic.heia-fr.ch/databases/iam-handwriting-database
https://arxiv.org/abs/2205.14879
https://github.com/Toon-nooT/notebooks
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓