前言
本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。
根据模块知识,一次讲解单个或者多个模块的内容。
这里贴一下教程地址:https://docs.python.org/zh-cn/3/tutorial/stdlib.html
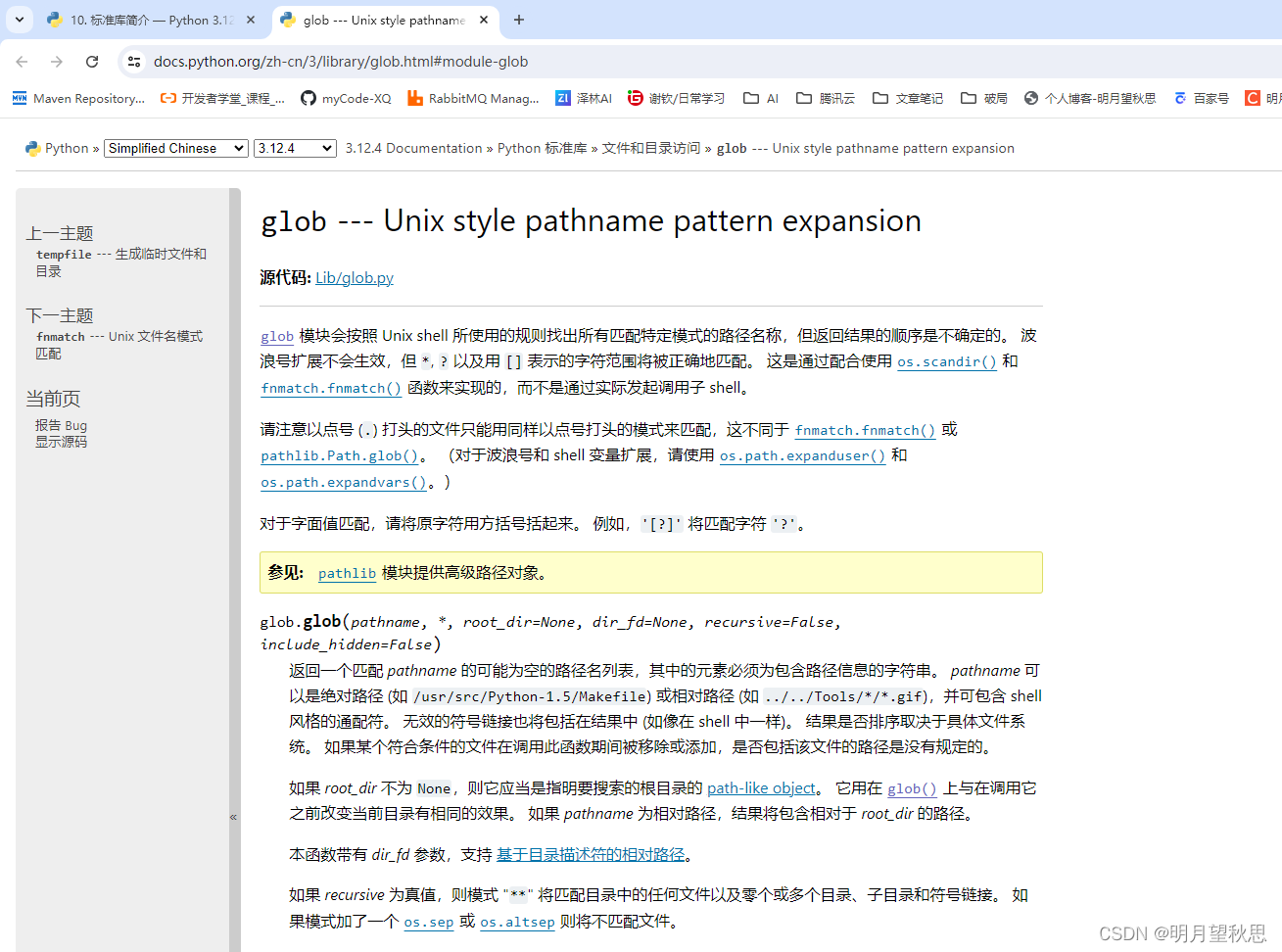
官方教程中,可以点击蓝字进入模块信息里面。如下两图示意。
文件通配符
glob模块提供了文件名匹配的函数,主要用于查找符合特定规则的文件路径名,类似于shell中的通配符。它可以帮助你根据模式(包含通配符如*, ?, […])搜索文件或目录。
常用函数
- glob.glob(pathname, *, recursive=False)
功能: 返回所有匹配指定模式的文件路径列表。
参数:
pathname: 字符串,表示匹配的模式。
recursive: 可选参数,默认为False。如果为True,则会递归地搜索子目录。
返回值: 匹配到的文件路径列表。
import glob
import os
# 查找当前目录下所有的.py文件
py_file = glob.glob("*.py")
print(py_file)
print("=================分隔符=================")
# 递归查找所有.py文件
all_txt_files = glob.glob("**/*.py", recursive=True)
print(all_txt_files)
print("=================分隔符=================")
# 当前目录是day8,里面就一个py文件,我们用上次学的os的切换目录的方式,切换到x目录去,这个目录文件更丰富
new_path = "E:/python_project/learn_base/x"
os.chdir(new_path)
x_py_file = glob.glob("*.py")
print(x_py_file)
print("=================分隔符=================")
# 递归查找所有.py文件
all_txt_files = glob.glob("**/*.py", recursive=True)
# 使用前面学的for循环打印每个文件的相对路径
for name in all_txt_files:
print(name)
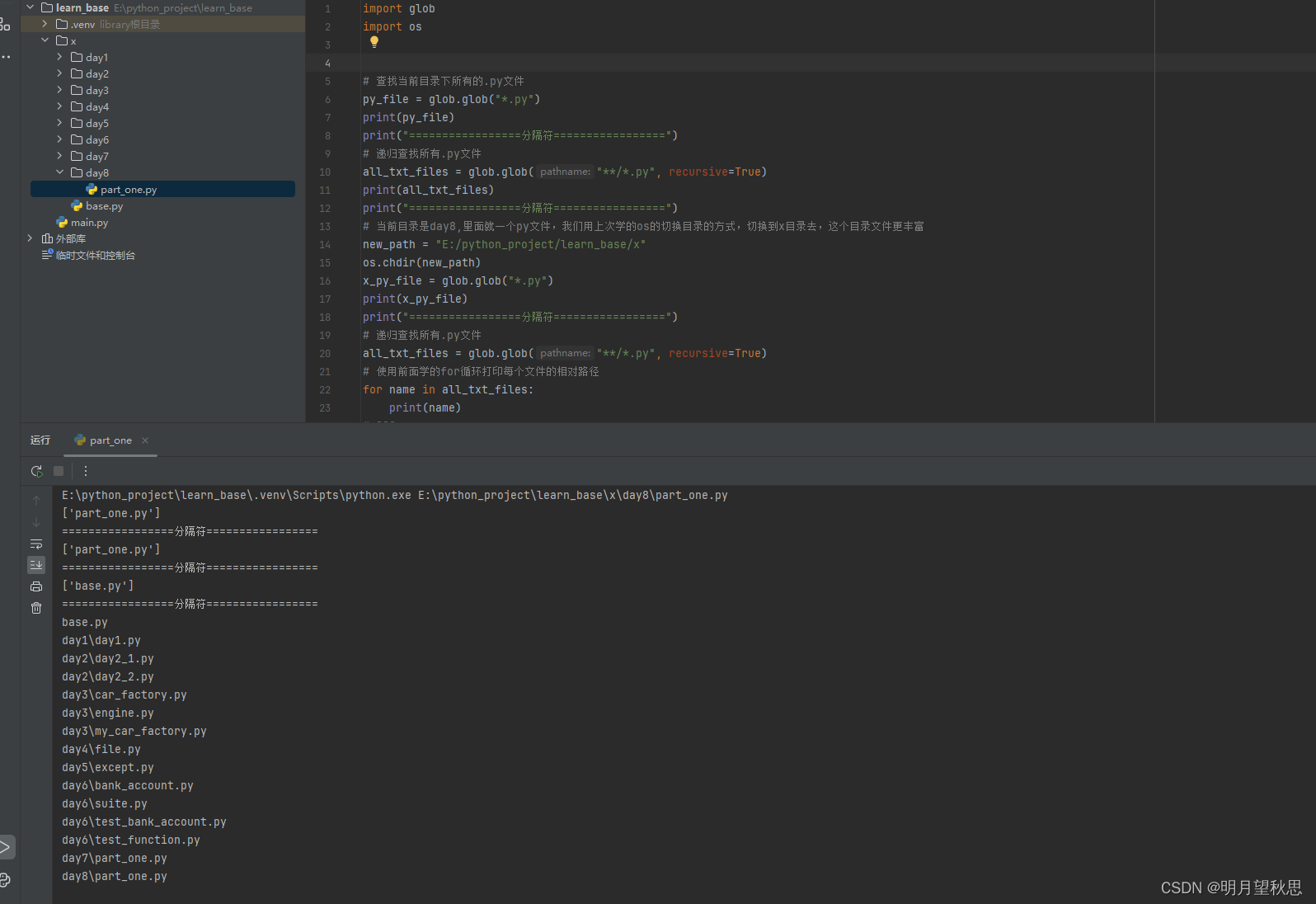
使用glob函数,普通查询和递归查询当前目录下的指定文件。这里查询的是py文件,因为这里面这个文件多,你可以切换到其他目录,试试其他类型的文件。
- glob.iglob(pathname, *, recursive=False)
功能: 类似于glob.glob(),但返回一个可迭代的generator对象,而不是列表。这对于处理大量文件匹配更为高效,因为它不会一次性加载所有结果到内存中。
参数与glob.glob()相同。
# 使用迭代器查找所有py文件
for py_file in glob.iglob("**/*.py", recursive=True):
print(py_file)
new_path = "E:/python_project/learn_base/x"
os.chdir(new_path)
print("=================分隔符=================")
for py_file in glob.iglob("**/*.py", recursive=True):
print(py_file)
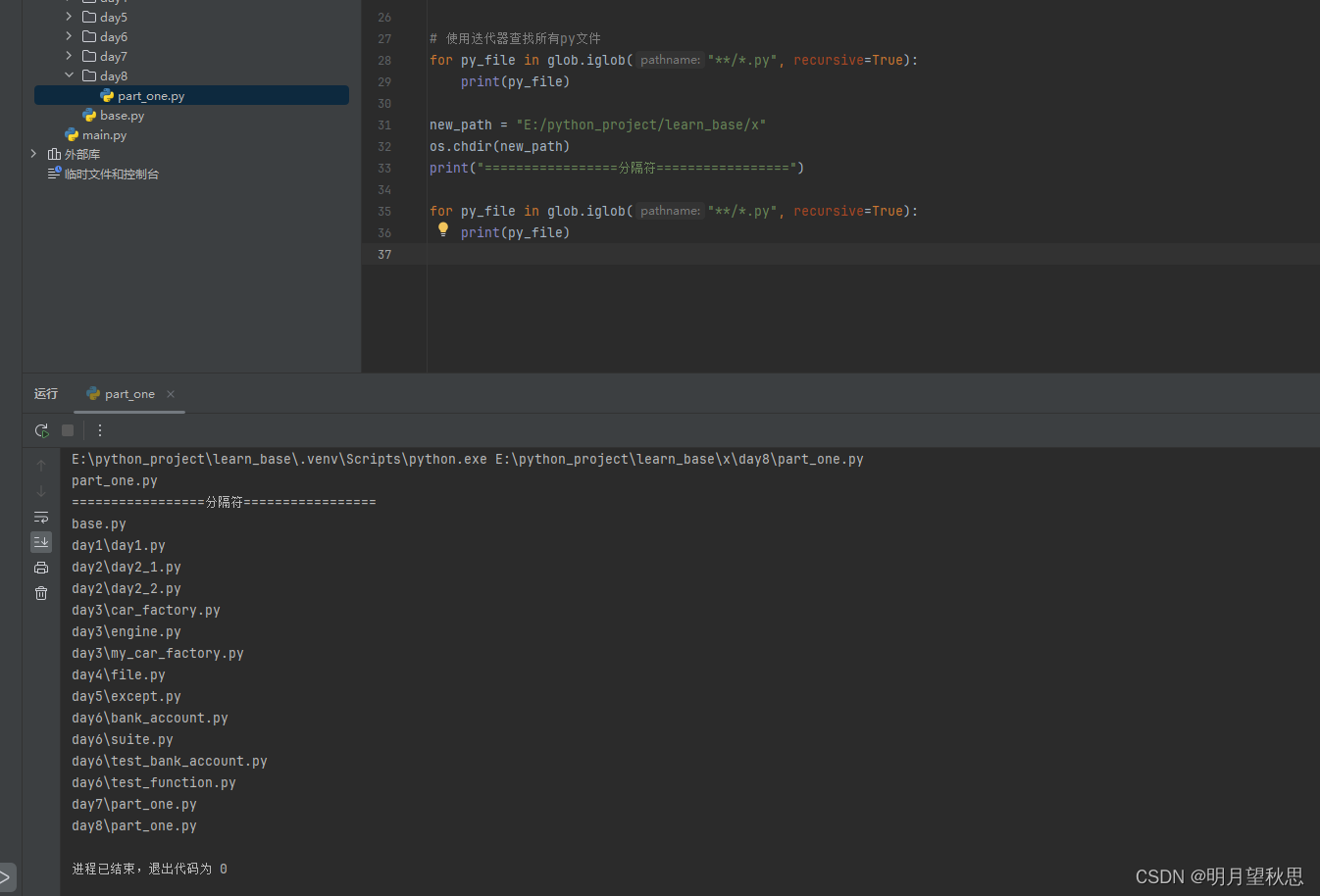
可以看到,两个函数返回的数据打印都一样的,那为什么要两个函数呢?
- 返回类型:
glob.glob(): 直接返回一个列表,其中包含了所有匹配指定模式的文件路径。这意味着它会立即执行查找操作,并将所有结果存储在一个内存中的列表里。对于小规模文件搜索,这很方便直接。但是,如果匹配到的文件数量非常大,这可能会消耗较多内存。
glob.iglob(): 返回一个迭代器,每次迭代时产生一个匹配的文件路径。这种方式更加内存高效,特别是在处理大量文件时,因为迭代器仅在需要时生成下一个匹配项,而不是一次性加载所有结果。这对于节省资源和处理大型文件系统尤其有用。 - 使用场景:
当你需要立即获得所有匹配项并可以接受其可能带来的内存消耗时,应使用glob.glob()。这适用于匹配结果较少,或者对性能和内存使用没有严格要求的情况。
如果你关心内存使用效率,特别是当预期匹配到的文件数量巨大时,应该选择glob.iglob()。迭代器允许你在处理每个匹配项的同时进行其他操作,比如逐个读取或处理文件,而无需等待整个列表被构造完成。
因此,提供这两个函数是为了满足不同场景下的需求:一个追求直接性和便捷性(glob.glob()),另一个注重效率和大规模数据处理的能力(glob.iglob())。我们可以根据实际场景选择使用,不过大多时候用glob函数就行,因为一般情况下我们遇不到追求效率和大规模数据处理的场景,但是不用不代表我们不需要知道有这个函数和场景。
命令行参数
argparse模块是用于处理命令行参数的工具。它让编写用户友好的命令行接口变得简单,可以自动生成帮助和使用消息,以及在参数解析错误时给出错误信息。argparse支持各种类型的命令行参数,包括位置参数、可选参数、flag(布尔开关)、值选项等,并且能够处理参数的默认值。
常用函数
-
ArgumentParser():创建一个ArgumentParser对象,它是命令行解析的基础。
-
add_argument():向parser中添加一个命令行参数的定义。
-
parse_args():解析命令行参数,返回一个命名空间对象,其中包含解析后的参数和值。
import argparse
def main():
# 创建ArgumentParser对象
parser = argparse.ArgumentParser(description="这是一个示例脚本,演示如何使用argparse处理命令行参数。")
# 添加一个位置参数
parser.add_argument("greeting", help="你要打招呼的内容")
# 添加一个可选参数,带有默认值
parser.add_argument("-n", "--times", type=int, default=1, help="打招呼的次数,默认为1次")
# 添加一个布尔开关
parser.add_argument("-v", "--verbose", action="store_true", help="开启详细输出模式")
# 解析命令行参数
args = parser.parse_args()
# 根据参数执行逻辑
for _ in range(args.times):
if args.verbose:
print(f"Verbose mode is on. Saying '{args.greeting}' for the {_ + 1} time.")
else:
print(args.greeting)
if __name__ == "__main__":
main()
编写好这些代码,我们就可以去命令行输入命令执行py文件了。
python part_two.py Hello
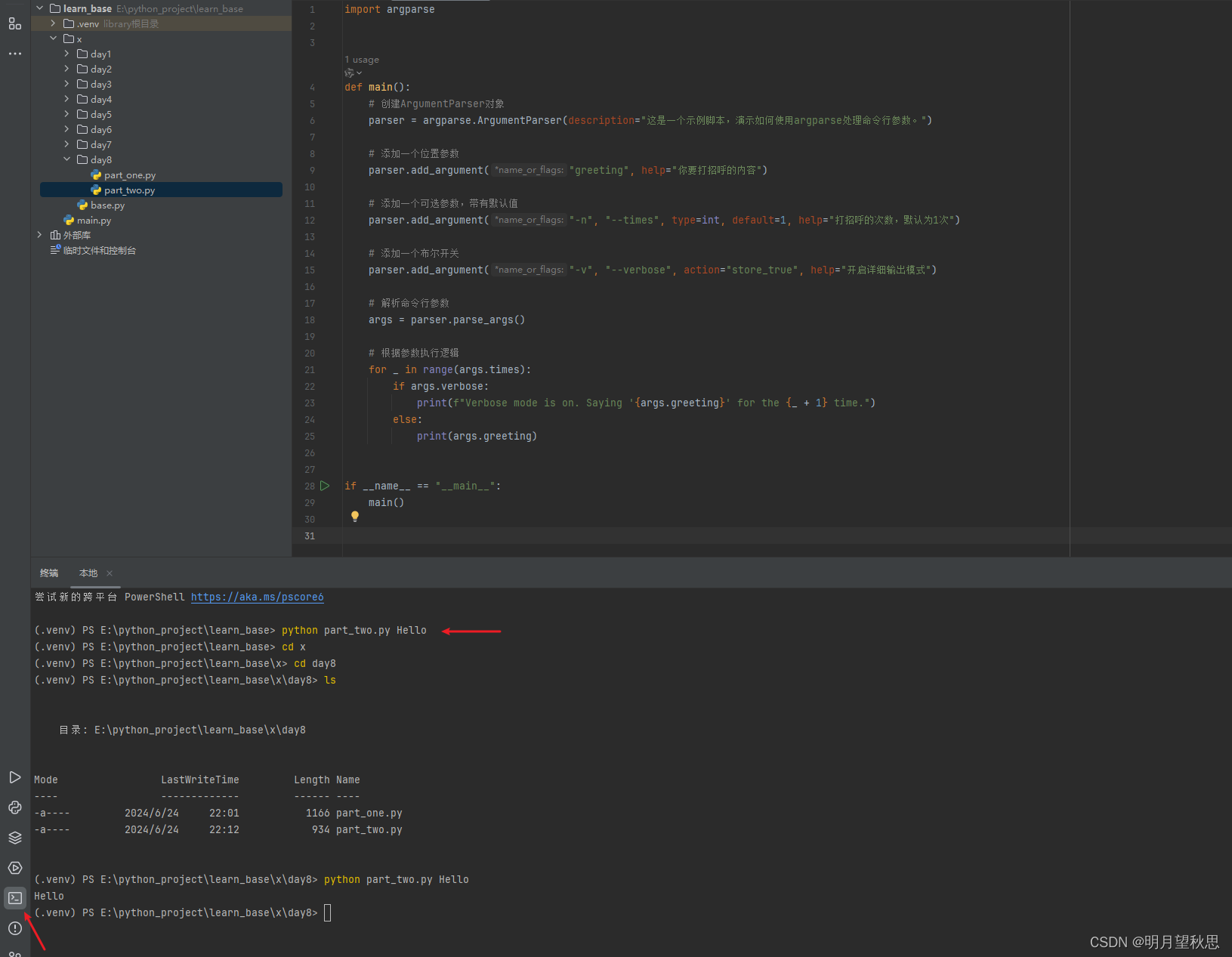
大家简单执行一下命令,看看结果,后面我们会仔细解释,到时候大家就要自己学习怎么写了。
注意看,左下角箭头指向的就是命令行,在IDE里面叫做终端。
看我命令行的第一个箭头,输出以后其实报错了,提示信息是目录文件不存在。因为我执行命令的目录是learn_base目录,实际上我们py文件在/learn_base/x/day8这个目录下,所以下面我使用cd命令进到了day8目录里面执行ls命令查询文件,确定了目标文件在这个目录后,输入执行命令,成功打赢了我们输入的hello。
不确定有没有命令行基础,这里讲两个命令让大家在遇到目录不对的情况切换目录。
cd:cd directory_name 进入目录下,注意如果你不输入全路径,那就是进入当前目录下的目录,目录不存在会报错的
cd … 返回上一层目录
怎么看当前在那一层目录呢? 看你命令行输入的光标,前面的路径就是你当前的目录了
ls: 就直接输就行,查询当前目录的所有文件和目录
命令行的命令太多了,入门又是好几篇文章,我们现在主要学习python,如果遇到需要输入这些命令,我就针对用到的单独讲讲,理解一下知道啥意思就行。
在我们代码里面,我们定义了三个参数,一个必填,两个选填,那么选填这两个参数有什么用呢?
我们根据代码,代码解释和执行情况来看看。
代码解释
为了让大家理解,我把代码解释贴出来,大家仔细理解,后面也会根据执行情况跟再解释一遍。
- 导入argparse模块:首先导入argparse模块,这是处理命令行参数的关键。
- 创建ArgumentParser对象:通过argparse.ArgumentParser()创建一个解析器对象,并为其提供一个描述字符串,该字符串会在帮助信息中显示。
- 添加位置参数:add_argument(“greeting”, help=“你要打招呼的内容”)定义了一个位置参数greeting,意味着它必须直接跟在脚本名称后面,没有前导短横线。help参数提供了关于此参数的描述,用户可以通过运行脚本加-h或–help查看。
- 添加可选参数:add_argument(“-n”, “–times”, type=int, default=1, help=“打招呼的次数,默认为1次”)定义了一个可选参数,可以用短形式-n或长形式–times指定,其类型为整数,并设定了默认值1。这意味着如果不提供这个参数,其值默认为1。
- 添加布尔开关:add_argument(“-v”, “–verbose”, action=“store_true”, help=“开启详细输出模式”)定义了一个布尔开关,使用-v或–verbose激活,无须跟随任何值。当这个选项被指定时,其值为True,否则为False。
- 解析参数:调用parser.parse_args()解析命令行参数,并将结果存储在args变量中,这是一个命名空间对象,属性对应于各个参数。
- 执行逻辑:根据args中的值执行相应的逻辑。这里,根据times的值重复打印greeting,并且如果启用了verbose模式,则额外打印一些调试信息。
第一点就不说了,导入模块,不导入模块的话类使用不了。
第二点:创建解析对象,提供描述字符串,这个字符串是在帮助信息里面的,怎么看帮助信息呢。基本上都可以这么查看。
终端输入命令:
# 两个都行
python part_two.py --help
python part_two.py -help
输出内容如图:
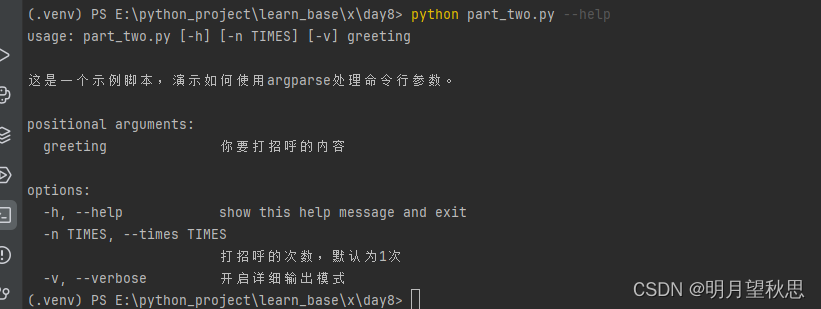
这个帮助信息告诉你哪些内容:
- 命令行示例,就是该文件的基本调用语法。part_two.py是脚本的名称,方括号[]内的参数是可选的,而没有方括号的greeting是位置参数,必须提供。
- 这个文件的信息,是干嘛用的。
- Positional Arguments (位置参数)。在命令行参数解析中,位置参数(Positional Arguments)是指那些必须按照特定顺序出现在命令行上的参数,它们不以破折号(-)或双破折号(–)开头。位置参数的位置决定了它们的含义,而不是通过一个特定的标识符来识别。
在我们这次的示例中,greeting是唯一的位置参数,用户必须直接在脚本名后面提供一个值,表示想要用于打招呼的具体内容。 - Optional Arguments(可选参数),它们通常以破折号开头,可以出现在命令行的任何位置(尽管它们之间以及与位置参数之间的顺序仍然重要)。可选参数提供了额外的灵活性和功能,允许用户选择性地指定参数。
在这次示例中,我们指定了两个,一个是-n的打招呼次数,一个是-v的布尔值开关,是否打印相信信息。至于-h和–h,这个在python的命令行参数解析中是默认的,不需要我们显示的定义。
帮助内容读完,再回去读代码,是不是一下就搞懂了。
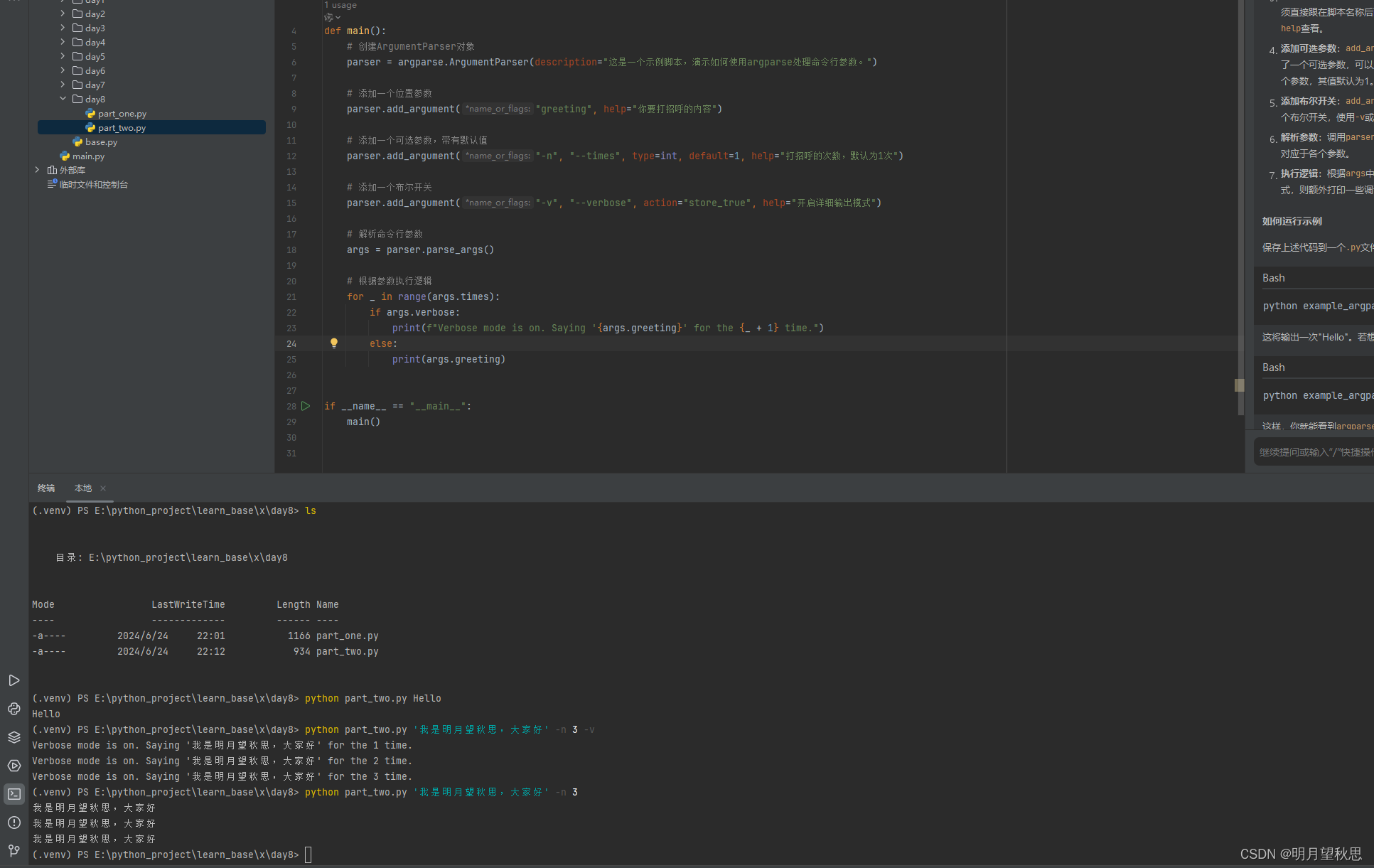
那么我们分别填两个可选参数和一个可选参数试试。
注意可选参数需要破折号+标识符的格式。

python part_two.py '我是明月望秋思,大家好' -n 3 -v
这个命令是什么意思?位置参数对应的打招呼的信息是:我是明月望秋思,大家好。打招呼次数3次。详细输出开关打开。也就是说执行这个命令,会输出3次详细的打招呼信息。
再看这个命令:
python part_two.py '我是明月望秋思,大家好' -n 3
相比上一个,是不是就是没有打开开关。那么执行这个命令,是不是就只会输出三遍简单的打招呼信息。
参数-n的逻辑,在代码的21行for循环语句
参数-v的逻辑,在代码的22行if条件语句
结尾
今天主要是命令行的内容讲的多一点,要稍微认真学习一下,多看多理解,有理解不了的,可以私信问我,我就当复习了。也可以自己查查资料,做到搞懂为止。
作业
- 使用glob函数搜索文件。
- 使用argparse模块,构建一个可执行的py文件,设置位置参数和可选参数,并在终端使用命令执行文件。最好不用和我用一个例子,自己构造一个!