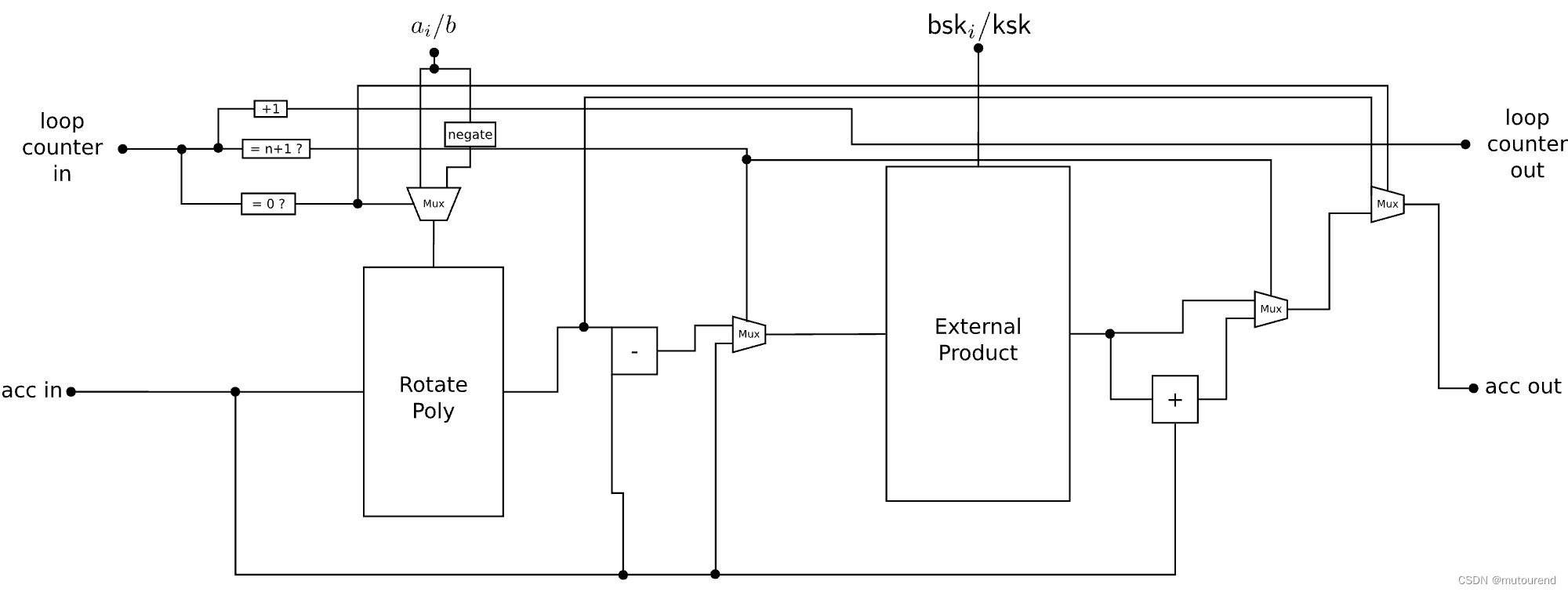
推荐平台:Matlab2022版及以上
在机器学习、深度学习领域,数据的多样性和数量直接影响模型的性能。生成对抗算法GAN(Generative Adversarial Network)通过对抗过程训练,能够生成高度逼真的数据样本,增加训练数据的多样性,从而提高模型的泛化能力。本文将生成对抗网络和故障识别程序结合,实现“批量生成样本-故障识别”一体化程序。目前还没有套用这个算法的文献,先到先得,抓住该创新点哦!
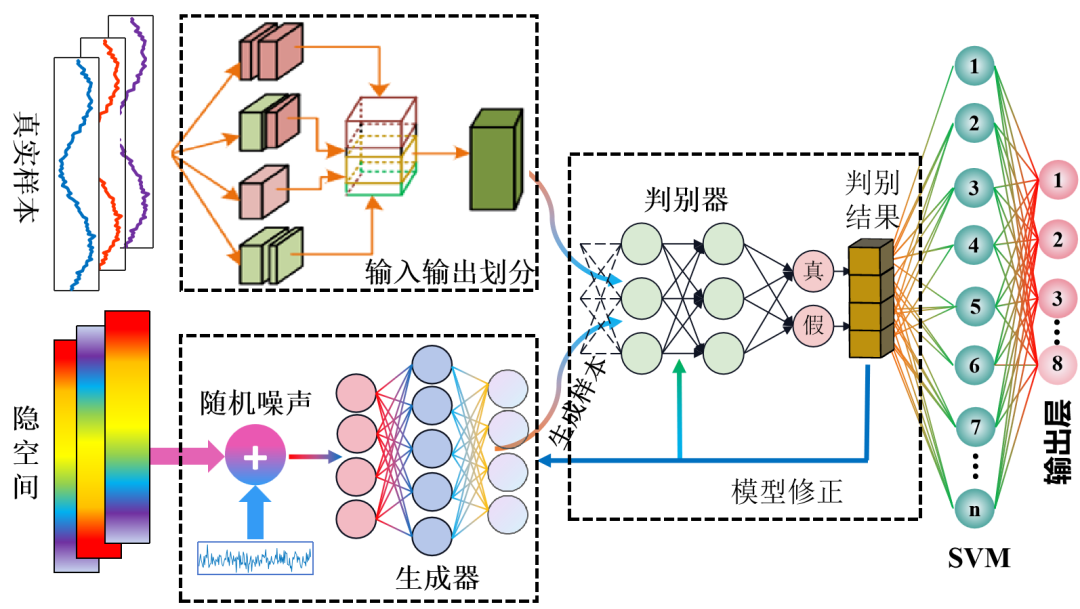
①数据准备
从Excel文件读取原始数据(以鸢尾花标准数据集为例),并进行预处理,如将特征矩阵转换为向量,计算数据的均值和标准差。
②定义生成器和判别器
-
生成器(Generator):初始定义为恒等映射,即输出输入的噪声数据。
-
判别器(Discriminator):通过Z-score归一化方法定义,用于评估数据与原始数据集的偏差。
③训练生成对抗网络
-
使用循环进行GAN的训练,每个周期中包含多个批次。
-
每个批次中,首先为生成器生成随机噪声,然后使用生成器产生合成数据。
-
训练判别器区分真实数据与合成数据,更新判别器和生成器的参数,以优化它们的性能。
④数据生成
-
完成训练后,使用训练好的生成器产生大量合成数据。
-
将生成的数据重新塑形并添加标签,形成新的合成数据集。
生成原始数据5倍的数据量:
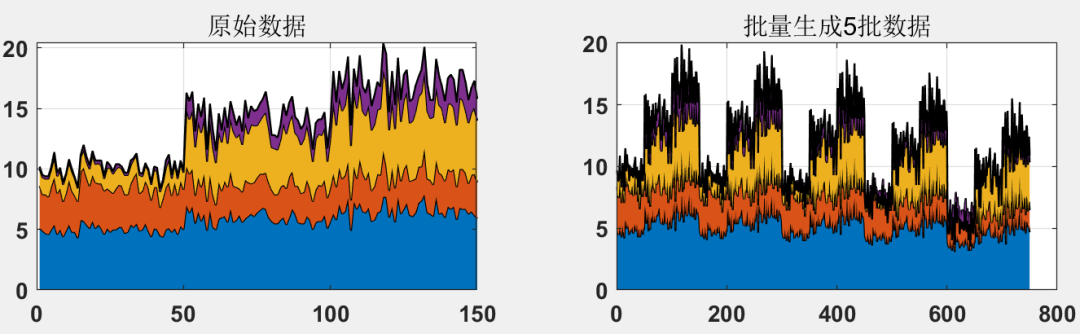
原始数据堆叠区域图:这个图显示了原始数据集中各个特征的堆叠区域图。不同颜色代表不同的特征值从图中可以观察到数据随时间或样本索引的变化趋势,有助于了解各特征之间的相互关系和其对时间的响应。
生成数据堆叠区域图:类似于原始数据的堆叠图,但这里展示的是通过生成对抗网络生成的数据。比较这两个图可以看出生成数据在整体趋势上与原始数据保持一致,说明生成模型能较好地模拟原始数据特征。
⑤数据可视化
使用各种图表(如散点图、直方图、箱线图等)显示原始数据和合成数据的特征分布和比较,验证生成数据的质量。
展示了某一特征在原始数据和生成数据中的分布情况。直方图比较两者在该特征上的统计分布是相似的。能够遵循原始数据的分布特性。

箱线图有助于快速识别数据中的异常值和分布范围;与原始数据的箱线图相对应,展示生成数据的同样统计信息。比较两者的箱线图可以评估生成数据在统计特性上的相似度。

下图是一个概率-概率(P-P)图,用来比较两个概率分布的相似性。图中的数据点越接近对角线,表明生成数据与原始数据在统计分布上越相似。
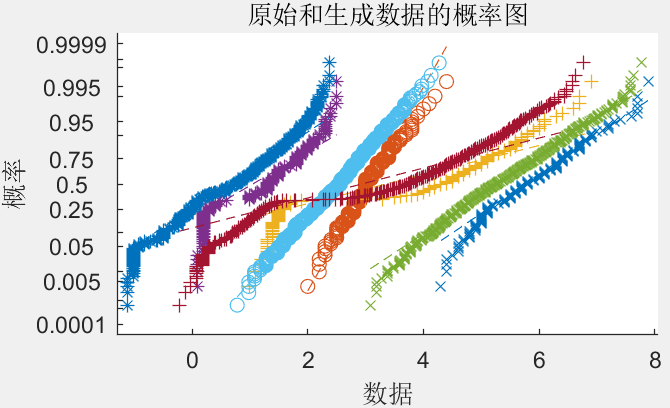
综合这些图表,可以对生成对抗网络生成的数据的质量进行全面的评估,检查其在多个方面与原始数据的相似度,从而验证GAN模型的有效性和适用性。
-
-
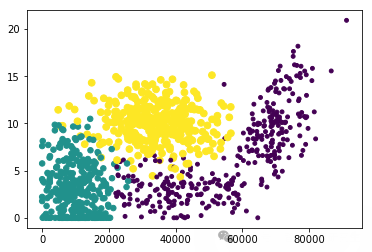
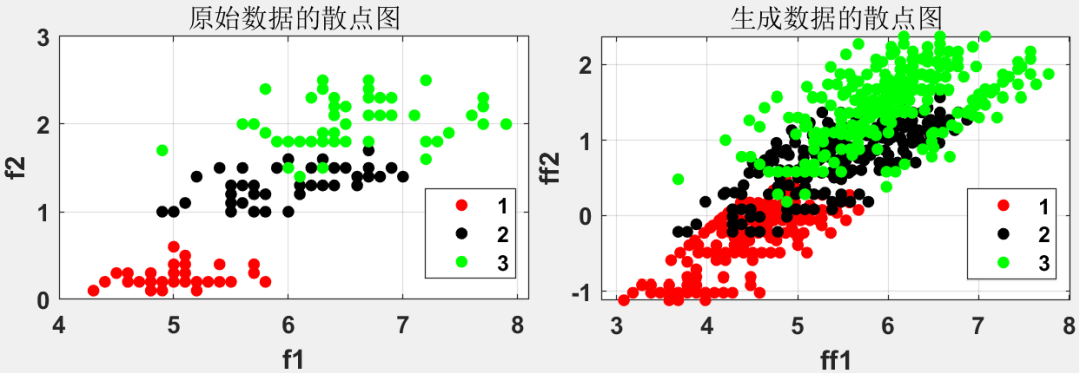
以两个特征(F1 和 F2)为轴,不同颜色代表不同的类别。
-
散点图显示了数据点在这两个特征空间中的分布情况,原始数据跟新生成数据的分布相似,且生成后的数据更密集,数据量充足。
-
故障识别结果

用生成数据训练SVM的精度为:96.5333%;训练完成后,原始数据集的测试精度为:96.6667%,表明新生成的数据能够生成高度逼真的数据样本,增加训练数据的多样性,从而提高模型的泛化能力。
部分程序
%% 非常基本的1维GAN生成合成数据
clear; % 清除工作区中的所有变量
close all; % 关闭所有图窗
clc; % 清除命令行窗口
%% 数据读取方法一
% load fisheriris_data.mat; % 加载Fisher鸢尾花数据集
% Target(1:50) = 1; Target(51:100) = 2; Target(101:150) = 3; Target = Target'; % 原始标签
%% 数据读取方法二 公众号:《创新优化及预测代码》
data = readtable('原始数据.xlsx'); % 从Excel文件读取数据到表格data
numericData = data{:, varfun(@isnumeric, data, 'OutputFormat', 'uniform')}; % 提取数值列 公众号:《创新优化及预测代码》
meas = numericData(:, 1:end-1); % 选择1-4列为输入特征
Target = numericData(:, end); % 选择最后一列为输出标签
original_data = reshape(meas, 1, []); % 预处理 - 将矩阵转换为向量
real_data_mean = mean(original_data); % 计算原始数据的均值
real_data_std = std(original_data); % 计算原始数据的标准差
% 定义生成器和判别器网络
generator = @(z) original_data; % 简单起见,使用恒等映射
discriminator = @(x) (x - original_data); % Z-score归一化
% 训练参数
num_samples = 500; % 样本数量
num_epochs = 4; % 训练周期
batch_size = 160; % 批量大小
learning_rate = 0.01; % 学习率
% 每次运行生成与原始数据样本数量相同的样本。所以,5次运行等于原始数据*5。部分图片来源于网络,侵权联系删除!
关注小编会不定期推送高创新型、高质量的学习资料、文章程序代码,为你的科研加油助力!