0,什么是RAG?
RAG,即检索增强生成(Retrieval-Augmented Generation),是一种先进的自然语言处理技术架构,旨在克服传统大型语言模型(LLM)在处理开放域问题时的信息容量限制和时效性不足。RAG通过融合信息检索系统的精确性和语言模型的强大生成能力,为基于自然语言的任务提供了更灵活和精准的解决方案。
1,RAG与LLM的关系
RAG不是对LLM的替代,而是对其能力的扩展与升级。传统LLM受限于训练数据的边界,对于未见信息或快速变化的知识难以有效处理。RAG通过动态接入外部资源,使LLM能够即时访问和利用广泛且不断更新的知识库,从而提升模型在问答、对话、文本生成等任务中的表现。此外,RAG框架强调了模型的灵活性和适应性,允许开发者针对不同应用场景定制知识库,以满足特定领域的需求。
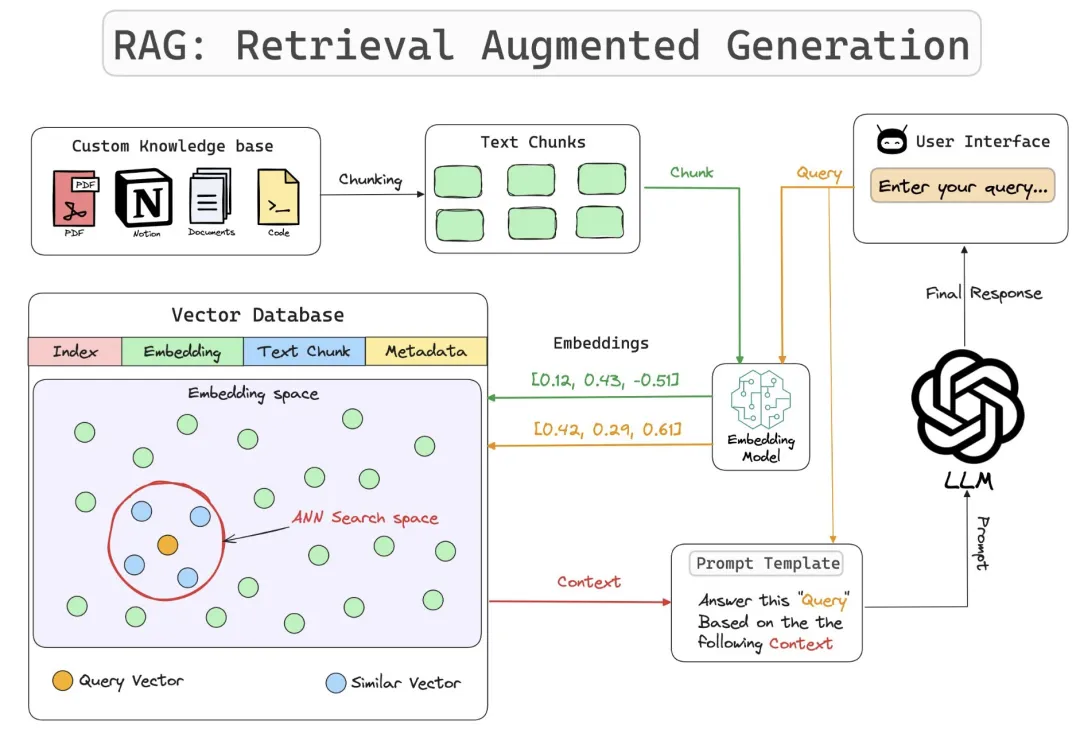
下图是 RAG 的大致流程:
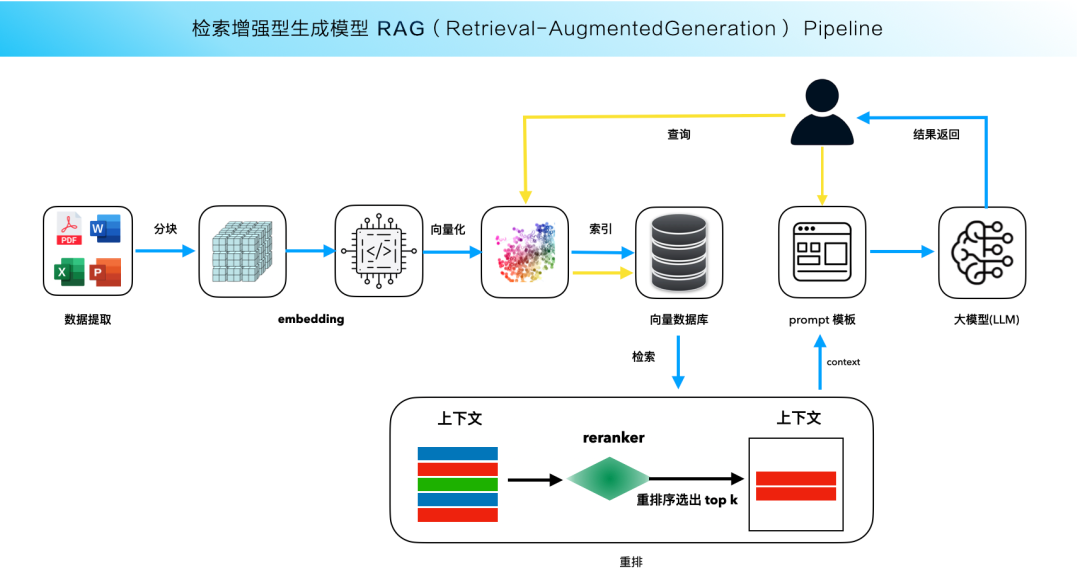
RAG为大型语言模型(LLM)配备了一个即时查询的“超级知识库”。这个“外挂”不仅扩大了模型的知识覆盖范围,还提高了其回答特定领域问题的准确性和时效性。
想象一下,传统的LLM像是一个博学多才但记忆力有限的学者,它依赖于训练时吸收的信息来回答问题。而RAG则是这位学者随时可以连线的庞大图书馆和实时资讯网络。当面临复杂或最新的查询时,RAG能让模型即时搜索并引用这些外部资源,就像学者翻阅最新的研究资料或在线数据库一样,从而提供更加精准、全面和最新的答案。这种设计尤其适用于需要高度专业化或快速更新信息的场景,比如医学咨询、法律意见、新闻摘要等。
基于此,RAG技术特别适合用于个人或企业的本地知识库应用,利用现有知识库资料结合LLM的能力,针对特定领域知识的问题提供自然语言对话交互,其答案比单纯依赖LLM更为准确。
2,下载/安装/运行Ollama
Ollama 本身不是 LLM,而是一个服务于 LLM 的工具。它提供了一个平台和环境,使得开发者和研究人员能够在本地机器上轻松地运行、测试和部署各种大型语言模型,Win系统下,安装配置教程参考文章:Ollama在Windows11部署与使用QWen2模型-CSDN博客
3,模型选择
Ollama官方提供的模型中,对中文支持较好的模型其实并不多,比较好的有:
-
Llama2-Chinese:基于Llama2微调。搜“Chinese”关键词就能找到。
-
Qwen系列:阿里的通义千问。所有尺寸的模型都支持32K的上下文长度。多语言支持。
关于Qwen2
阿里开源了通义Qwen2模型,可以说是现阶段这个规模最强的开源模型。发布后直接在 Huggingface LLM 开源模型榜单获得第一名,超过了刚发布的 Llama3 和一众开源模型。Qwen2在代表推理能力的代码和数学以及长文本表现尤其突出。推理相关测试及大海捞针测试都取得了很好的成绩。
模型概览:Qwen 2 模型组成包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。其中Qwen2-57B-A14B为 MoE 模型。
模型在中文、英文语料基础上,训练数据中增加了27种语言相关的高质量数据;增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。多个评测基准上的领先表现;代码和数学能力显著提升。
4,AnythingLLM
AnythingLLM 是一个基于大型语言模型(LLM)的综合平台,旨在为用户提供灵活且高效的自然语言处理解决方案。它不仅能够执行文本生成、问答、翻译等基本任务,还可以通过集成外部知识库和数据源,增强模型的知识范围和时效性。
下载地址:Download AnythingLLM for Desktop
下载后直接安装即可,安装完成后打开,大概长这样:
然后开始选择模型,由于Ollama其实有两种模式;聊天模式和服务器模式,所谓服务器模式,你可以简单理解为,Ollama在后端运行大模型,然后开放一个端口给到别的软件,让那些软件可以调用大模型的能力。
要开启服务器模式非常简单。在终端里输入下面的指令即可启动
ollama serve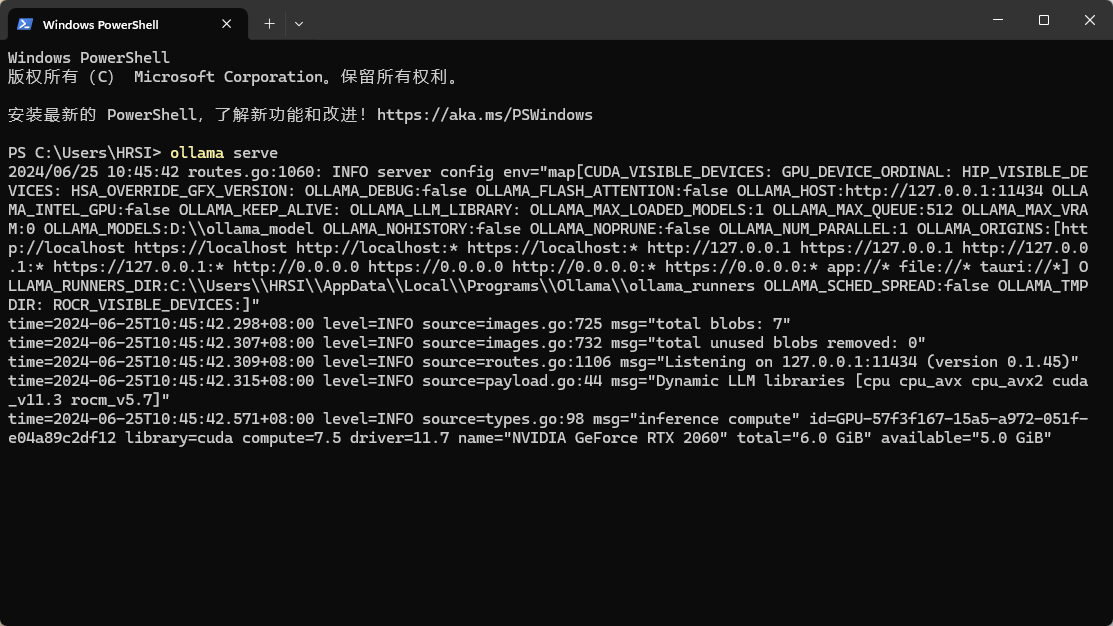
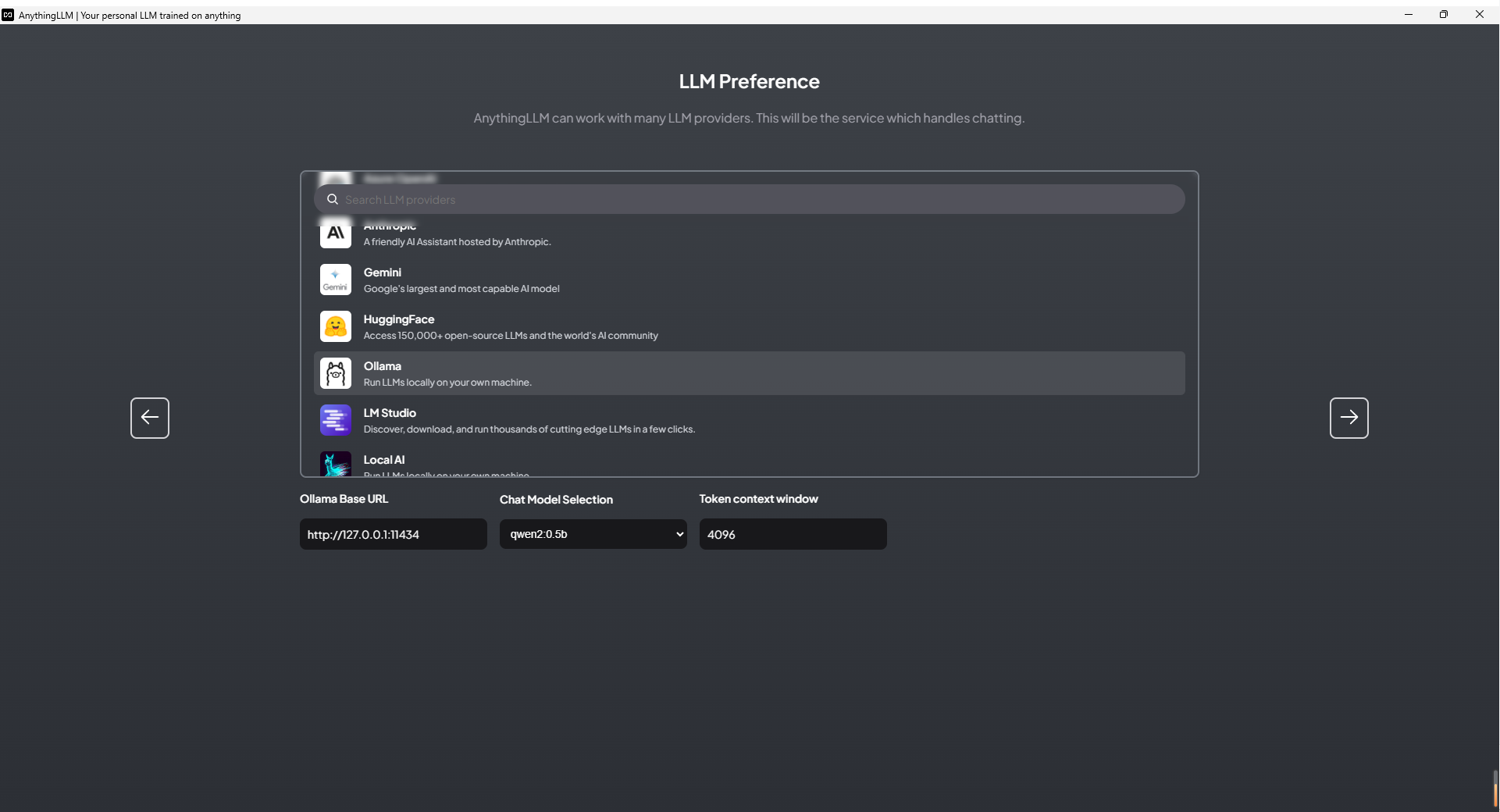
- 用服务器模式启动
Ollama后 - 在 AnythingLLM 界面中选择
Ollama - 然后在 Base URL中填:http://127.0.0.1:11434
- 选择 LLM 模型,比如 Qwen2 0.5b
- Token context window 可以先用默认的 4096
然后就到了下一步
5,搭建知识库
搭建一个知识库涉及两个关键点:
- Embedding Model(嵌入模型):它将高维度的数据转化为低维度的嵌入空间。这一数据处理过程在RAG中非常重要。
- Vector Store(向量数据库):专门用来高效处理大规模向量数据。
上图展示了默认的嵌入模型和向量数据库,我们将先使用默认设置。
接下来是填写个人信息,这一步可以略过。 然后,给你的 workspace 起一个名字,这一步也可以略过。 最后,你可以在建好的 workspace 中上传你的个人知识库内容。
支持上传的文件格式很多,比如PDF、Word等都支持,甚至你可以上传外部网站链接,可是不支持上传文件夹,假如你的文件有多层结构,就没办法呈现了
当然,数据源也可以是外部的其他知识网站
还可以根据项目来创建Workspace,一个项目建一个。然后,把关于这个项目的所有文档、所有网页都导入Workspace。聊天模式还有两种可以设置:
-
对话模式:大模型会根据你给的文档,以及它本来就有的知识储备,综合起来回答。
-
查询模式:大模型只是简单地针对文档进行回答。
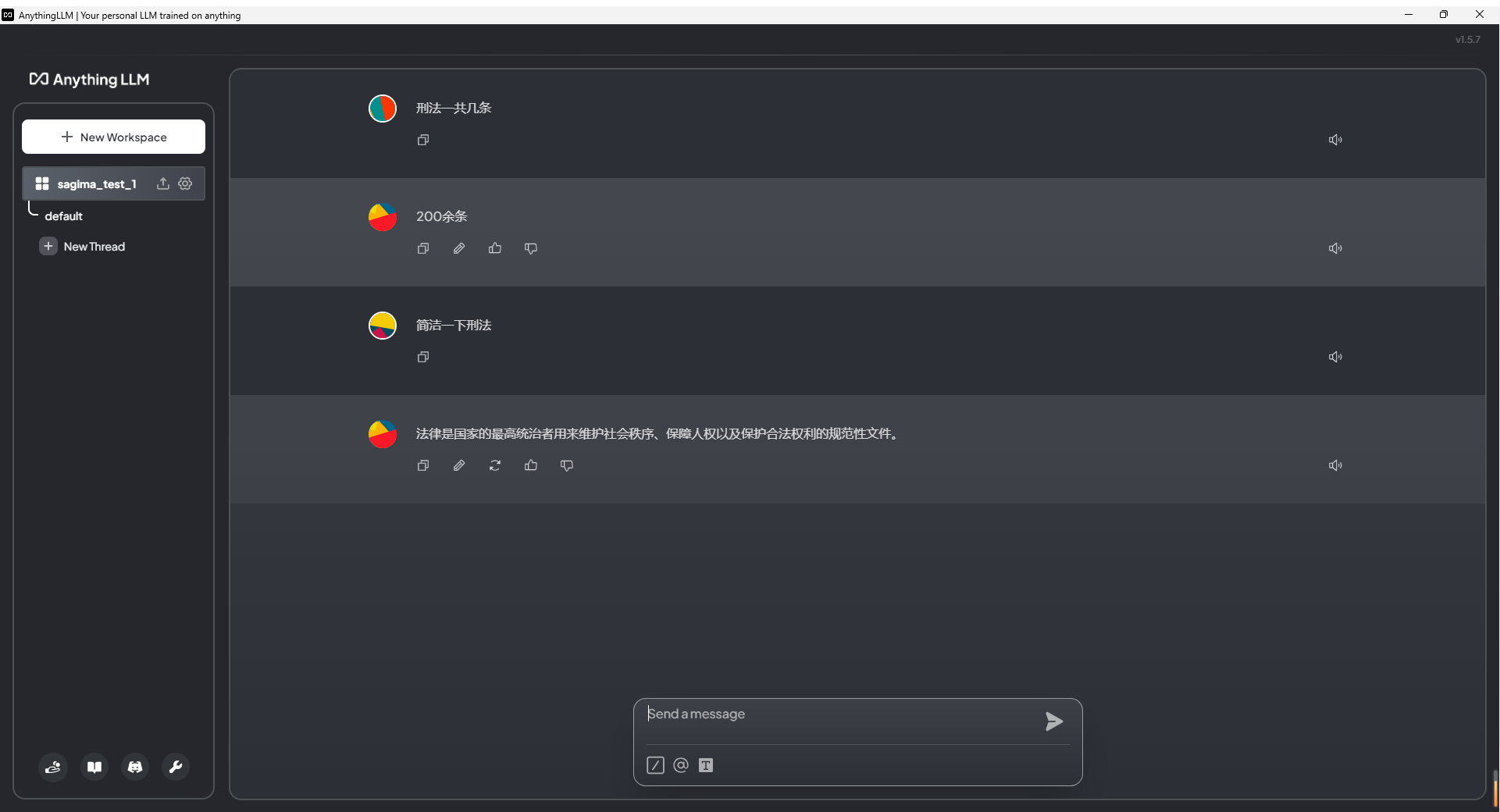
比如我上传了刑法的Word版,可以用查询模式进行对话,因为模型参数较少(只有0.5b),所以效果其实一般,主要是我的电脑只有2060显卡,没法测试更好地模型,在充分设计后应该效果会更好
至此,本地个人知识库已经搭建完毕,更多高阶操作还需要大家自己查询AnythingLLM的使用方法。