论文链接:GroupViT: Semantic Segmentation Emerges from Text Supervision
代码链接:https://github.com/NVlabs/GroupViT/tree/main
作者:Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang
发表单位:加州大学圣地亚哥分校、NVIDIA
会议/期刊:CVPR2022
一、研究背景
视觉场景自然地由语义相关的像素组组成。
在视觉场景理解中,分组和识别是关键的任务,常见于目标检测和语义分割等应用。传统的深度学习方法通常依赖于像素级的标注,通过全卷积网络(Fully Convolutional Networks, FCNs)直接在输出层进行像素级的分类。然而,这些方法存在两个主要问题:
-
高昂的标注成本:训练高性能的模型需要大量的像素级标注数据,这些数据的获取非常耗时且昂贵。
-
泛化能力差:模型只能识别训练时见过的类别,难以推广到未见过的新类别。
近年来,基于文本监督的视觉表示学习取得了显著进展,通过学习图像和文本之间的对比特征,可以在零样本的情况下进行图像分类和目标识别。这为研究如何在没有像素级标注的情况下实现语义分割提供了新的思路。
本文贡献:
-
超越深度网络中规则形状的图像网格,引入了一种新颖的GroupViT架构,可以将视觉概念分层自下而上分组为不规则形状的组。
-
无需任何像素级标签和训练,仅使用对比损失进行图像级文本监督,GroupViT 成功学会将图像区域分组在一起,并以零样本方式转移到多个语义分割词汇表。
-
第一个探索从单独的文本监督到多个语义分割任务的零样本迁移的工作,而不使用任何像素级标签,并为这项新任务建立了强大的基线。
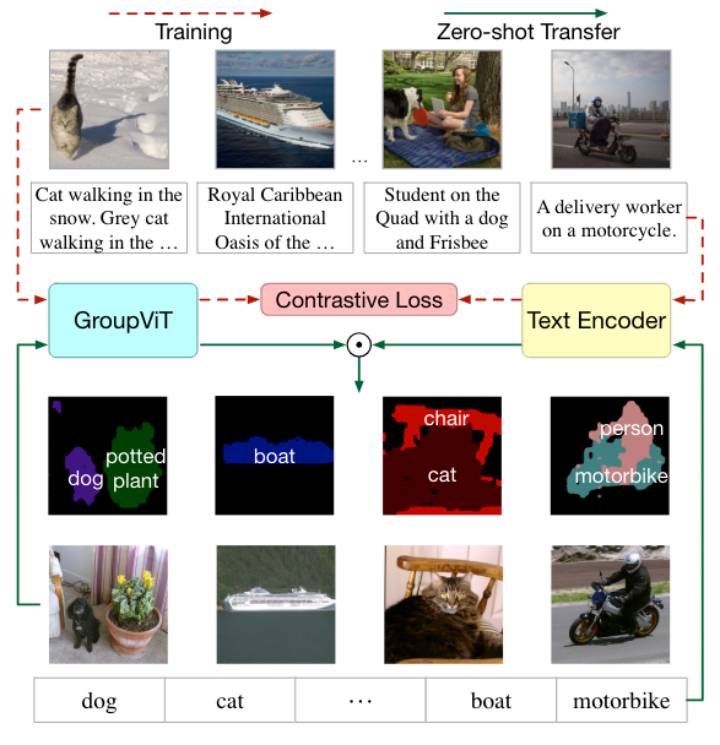
首先,使用成对的图像文本数据联合训练 GroupViT 和文本编码器。借助 GroupViT,有意义的语义分组会自动出现,无需任何掩码注释。然后,将训练好的 GroupViT 模型转移到零样本语义分割的任务中
二、整体框架
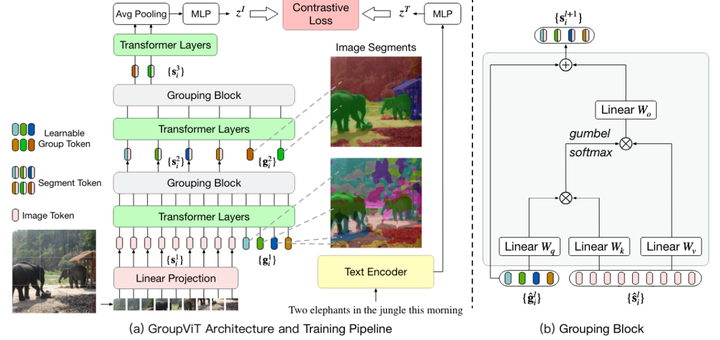
GroupViT 的架构和训练流程
GroupViT模型包含由多个Transformer层构成的层次结构,这些层被分为多个阶段,每个阶段在逐渐变大的视觉片段上运行。右侧图像展示了不同分组阶段中出现的视觉片段。在较低的阶段,像素被分组为物体的部分,例如大象的鼻子和腿;在更高的阶段,这些部分被进一步融合成整个物体,例如整个大象及其背景森林。
每个分组阶段以一个分组块结束,该块负责计算学习的组标记和片段(图像)标记之间的相似性。分配通过在组标记上应用Gumbel-Softmax计算,并转换为one-hot硬分配。分配给同一组的片段标记被合并在一起,形成新的片段标记,作为输入传递到下一个分组阶段。
该模型仅使用图像-文本对的对比学习进行训练,无需像素级标签,实现了零样本迁移的语义分割。在推理阶段,模型通过比较图像片段和文本类别的相似度,为每个片段分配类别标签,达到高效的语义分割效果。
三、核心方法
3.1 Grouping Vision Transformer
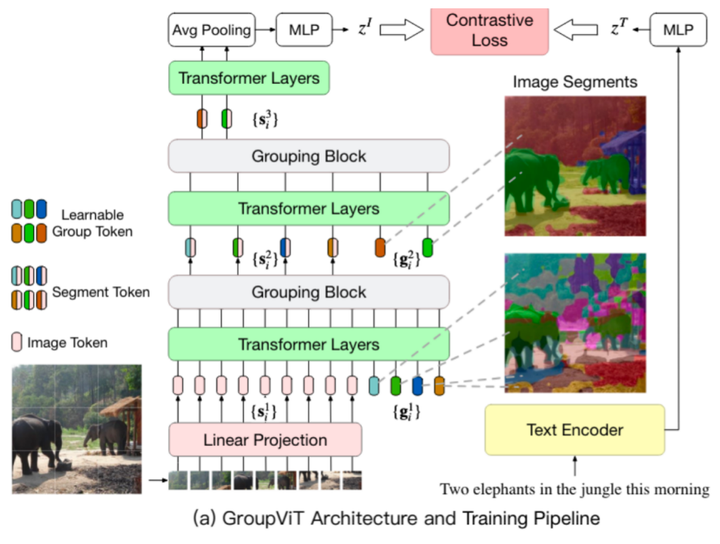
GroupViT的网络结构
遵循 Vision Transformer (ViT) 的设计,首先将输入图像分割成 N 个不重叠的块,并将每个块线性投影到潜在空间中。每个投影块视为输入图像标记,表示为 。在每个分组阶段,除了图像标记之外,还连接一组可学习的组标记,并将它们输入到该阶段的 Transformer 中。
如上图所示,模型不是通过 Transformer 的所有层传递所有 N 个输入图像标记,而是将其层分成分组阶段的层次结构。每个阶段的末尾都包含一个Grouping Block分组块,用于将较小的组合并为较大的组。
假设有L个分组阶段,每个阶段由l 索引并具有一组可学习的组标记 ,M 代表每个分组阶段中的组标记(group tokens)的数量。为简单起见,将输入到第一个分组阶段的图像块
视为起始片段
的集合,其中 N=M0。将
简化为
,类似地将
简化为
,从l=1 开始,对于每个分组阶段,首先将
连接在一起,然后输入到多个 Transformer 层中,每个 Transformer 层执行信息传播:
其中 [⋅;⋅]表示串联运算符。然后,通过分组块将更新的 Ml−1个图像片段标记分组为 Ml个新片段标记:
在每个分组阶段 Ml<Ml−1,即组标记逐渐减少,导致图像片段逐渐变大和变少。在最后的分组阶段 L之后,应用 Transformer 层在所有分段标记上,最后对它们的输出进行平均以获得最终的全局图像表示 zI:
GroupViT 在第一阶段之后将视觉信息重新组织成任意图像片段,因此不限于规则网格结构。
分组块 (Grouping Block)
作用:将相似的图像标记合并成更大的语义片段。每个分组块在一个分组阶段的末尾,使用学习到的分组标记 (group tokens) 来指导图像标记 (image tokens) 的合并。

分组块 (Grouping Block)的结构
如上图所示,每个分组阶段结束时的分组块将学习到的组标记和图像片段标记作为输入。根据嵌入空间中的相似性,将分配给同一组标记的所有片段标记合并到单个新图像片段中。
计算组标记和片段标记之间的相似性矩阵 Al,通过在组标记上计算的 Gumbel-Softmax 操作:
其中, 是第 l 阶段更新后的分组标记,
是第 l 阶段更新后的图像标记。 Wq和 Wk 分别是组和片段标记的学习线性投影的权重,{γi} 是从 Gumbel(0, 1) 分布中抽取的 i.i.d 随机样本。通过对所有组进行 argmax 的one-hot操作来计算要为其分配段标记的组:
其中 sg是停止梯度算子。通过直通技巧, 具有分配给单个组的one-hot值,但其梯度等于 Al 的梯度,这使得分组块可微分并且端到端可训练。
作者将这种one-hot分配策略称为硬分配。将片段标记分配给不同的组后,合并属于同一组的所有标记的嵌入,以形成新的片段标记 :
其中 Wv和 Wo 是投影合并特征的学习权重。硬分配的替代方法是软分配,它使用 Al 而不是 A^ l 来计算上式。根据实验结果,硬分配比软分配产生更有效的分组。
分组块类似于之前提出的 Slot Attention 机制的单次迭代。虽然 Slot Attention 通过自我监督学习实例级分组,但分组块通过弱文本监督对相似的语义区域进行分组。例如在实验预测可视化图的第二行中,两匹马被分组在一起。
上述内容的解释:假设输入图像被分割成多个小块,每个小块代表一个图像标记。在第一个分组阶段,模型通过自注意力机制学习到一些分组标记,这些标记代表图像中的不同部分。例如,一个分组标记可能代表大象的腿,另一个代表大象的鼻子。在分组块中,通过计算这些分组标记与图像标记之间的相似度,模型将相似的图像标记合并在一起,形成新的、更大的语义片段。这个过程在多个分组阶段中重复进行,最终将整个图像分割成具有语义意义的片段,例如整个大象及其背景森林。
3.2 Learning from Image-Text Pairs
在GroupViT模型中,通过从图像-文本对中学习(Learning from Image-Text Pairs)来训练模型。具体来说,主要是通过对比学习(contrastive learning)来实现,包括图像-文本对比损失和多标签对比损失。
3.2.1 图像-文本对比损失 (Image-Text Contrastive Loss)
对比学习的目标是将匹配的图像和文本对拉近在共同的嵌入空间中,同时将不匹配的对推开。
(a) 架构
-
图像编码器:GroupViT充当图像编码器,输入图像后输出图像的嵌入向量。
-
文本编码器:一个基于Transformer的文本编码器,用于将文本输入编码成嵌入向量。
图像编码器和文本编码器共同将输入图像和文本编码成嵌入向量,并在共同的嵌入空间中计算相似度。
(b) 损失函数
对比损失由两个部分组成:图像到文本的对比损失(image-to-text contrastive loss)和文本到图像的对比损失(text-to-image contrastive loss)。总的对比损失为:
图像到文本的对比损失:
文本到图像对比损失:
其中:
-
B 是批次大小。
-
ziI 和 ziT 分别是第 i 个图像和文本的嵌入向量。
-
τ 是一个可学习的温度参数,用于缩放对比学习的logits。
3.2.2 多标签对比损失 (Multi-Label Image-Text Contrastive Loss)
为了增强视觉分组能力,GroupViT引入了多标签对比损失,使用文本提示生成额外的文本标签。
(a) 生成多标签文本
-
对每个文本句子,提取其中的名词(nouns),并使用一组手工制作的句子模板(例如,“A photo of a {noun}”)生成新的文本标签。
-
对于每个图像-文本对,生成 KKK 个新的文本标签。
(b) 多标签对比损失公式
多标签对比损失的目标是对每个图像-文本对,除了原始的文本标签外,还引入生成的多标签进行对比学习。总的多标签对比损失为:
图像到多标签对比损失:
多标签到图像对比损失:
其中:
-
K 是为每个图像生成的多标签数量。
-
zTki 是第 i 个图像对应的第 k 个生成的文本标签的嵌入向量
3.2.3 总损失
最终的对比损失结合了图像-文本对比损失和多标签对比损失:
3.2.4 多标签应该如何生成?
对于每个文本句子,从中提取出所有的名词(nouns)。名词通常表示图像中的物体或场景,是进行语义分割的重要标记。例如,对于描述“大象在森林中行走”的文本,提取出的名词可能是“大象”和“森林”。
使用一组预定义的句子模板,将提取的名词构造为新的文本标签。例如,模板可以是“A photo of a {noun}”。对于提取出的“大象”和“森林”,生成的多标签文本分别为“A photo of an elephant”和“A photo of a forest”。
通过这种方式,每个图像-文本对将生成多个(通常为 K 个)新的文本标签。
多标签对比学习的目标是通过引入多个文本标签来增强模型的学习效果,使得模型能够在更广泛的语义空间中进行学习。
这些生成的文本标签将作为额外的监督信号,用于对比学习。这样一来,模型不仅能学习到图像与原始文本描述的关系,还能学习到图像与多个具体名词(即物体和场景)的关系,从而提升模型在语义分割任务上的表现。
3.3 Zero-Shot Transfer to Semantic Segmentation
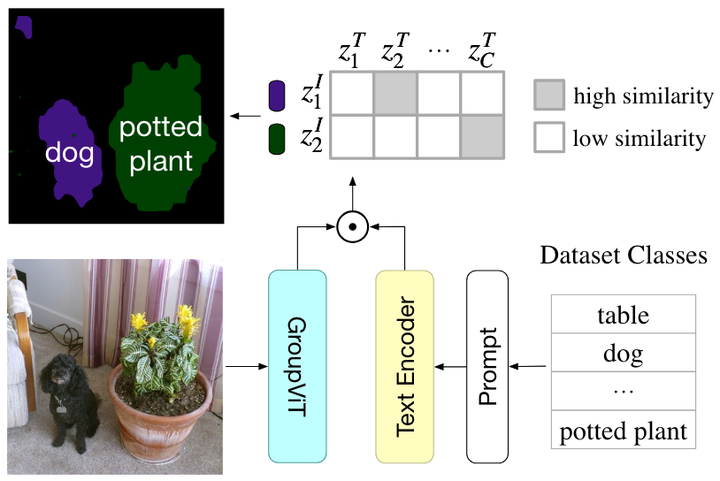
GroupViT 到语义分割的零样本迁移。 GroupViT 的每个输出片段的嵌入对应于图像的一个区域。将每个输出段分配给嵌入空间中具有最高图像文本相似度的对象类。
由于GroupViT自动将图像分组为语义相似的片段,其输出可以轻松地零样本转移到语义分割,而无需进一步的微调。该过程如下:
推断图像片段:
-
对测试图像进行处理,通过GroupViT模型传递,但不对最终输出片段应用AvgPool。
-
获得每个片段的嵌入
,其中每个片段标记对应于输入图像的任意形状的区域。
计算相似性:
-
计算每个片段标记的嵌入与数据集中所有语义类的文本嵌入之间的相似性。
-
将每个图像片段分配给相似度最高的语义类。
具体来说:
-
令
为第 l 分组阶段的分配矩阵,表示第 l 阶段的输入和输出段之间的映射。
-
通过乘积
计算输入块
和最终阶段输出标记
提示工程:
-
使用提示工程将所有语义分割标签名称转化为句子,如“A photo of a {noun}”。
-
将数据集中标签名称的嵌入表示为
,其中 C 是类别的数量。
分类:
-
为了将图像片段
分类为 C 类之一,计算
之间的点积相似度。
-
将图像片段分配给相似度最高的类。
四、实验结果

硬分配与软分配和多标签对比损失的消融结果
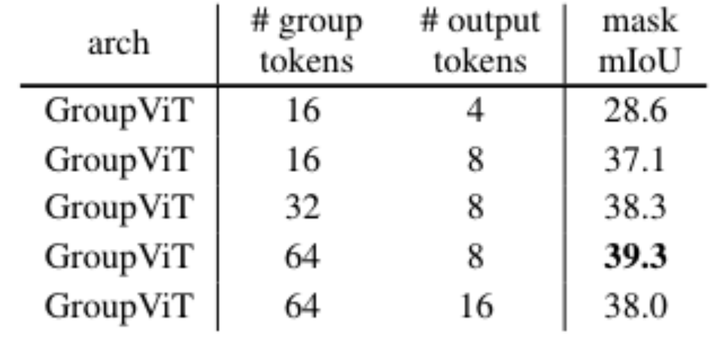
不同数量的组和输出标记的消融结果
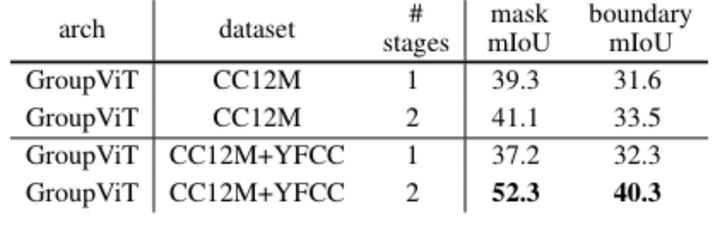
单阶段和多阶段分组的消融结果

1 阶段和 2 阶段 GroupViT 的视觉结果。 2-stage GroupViT 生成的分割图比 1-stage GroupViT 生成的分割图更平滑、更准确。1 阶段和 2 阶段 GroupViT 的视觉结果。 2-stage GroupViT 生成的分割图比 1-stage GroupViT 生成的分割图更平滑、更准确
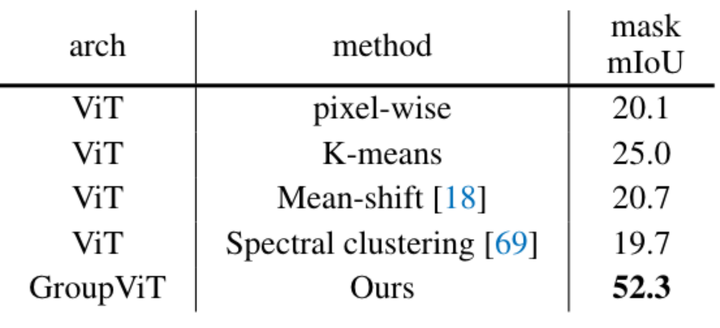
与零样本基线的比较

组tokem学到的概念。重点介绍了组tokem在不同阶段涉及的区域
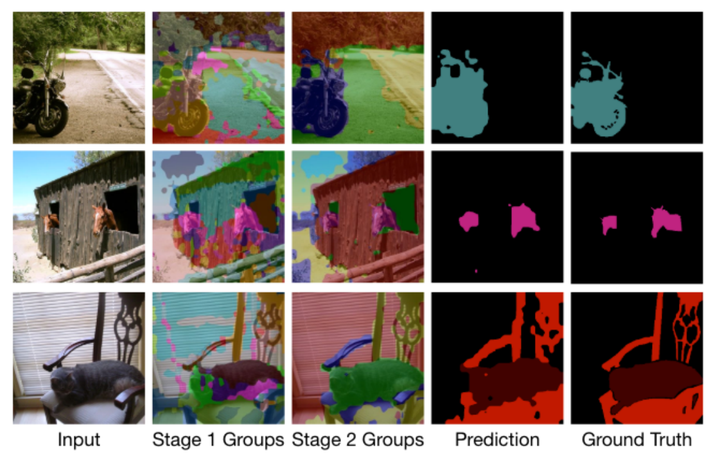
PASCAL VOC 2012 的定性结果。阶段 1/2 组是在分配标签之前对结果进行分组。PASCAL VOC 2012 的定性结果。阶段 1/2 组是在分配标签之前对结果进行分组

与完全监督传输的比较。零样本✓意味着无需任何微调即可转移到语义分割。报告了 PASCAL VOC 2012 和 PASCAL Context 数据集验证分割的 mIoU







![适用于 Windows 11 的 5 大数据恢复软件 [免费和付费]](https://img-blog.csdnimg.cn/img_convert/7d514dfaf1bb7c2c5d07e90c2167093f.jpeg)



