比较(四)利用python绘制平行坐标图
平行坐标图(Parallel coordinate plot)简介
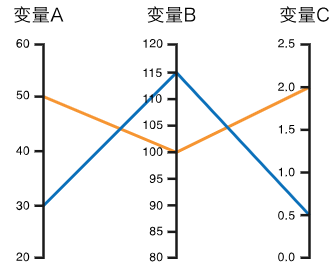
平行坐标图可以显示多变量的数值数据,最适合用来同一时间比较许多变量,并表示它们之间的关系。缺点也很明显,
不同的轴线排列顺序可能会影响读者对数据的理解。
快速绘制
-
基于pandas
import pandas import matplotlib.pyplot as plt import seaborn as sns from pandas.plotting import parallel_coordinates # 导入数据 data = sns.load_dataset('iris') # 利用parallel_coordinates快速绘制 parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) plt.show()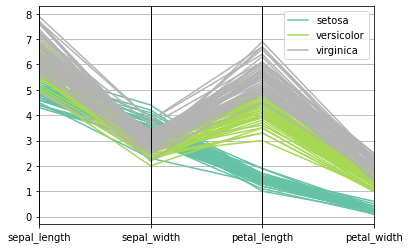
-
基于plotly
import plotly.express as px # 导入数据 df = px.data.iris() # 利用parallel_coordinates快速绘制 fig = px.parallel_coordinates( df, color="species_id", labels={"species_id": "Species","sepal_width": "Sepal Width", "sepal_length": "Sepal Length", "petal_width": "Petal Width", "petal_length": "Petal Length", }, color_continuous_scale=px.colors.diverging.Tealrose, color_continuous_midpoint=2) # 隐藏色阶bar fig.update_layout(coloraxis_showscale=False) fig.show()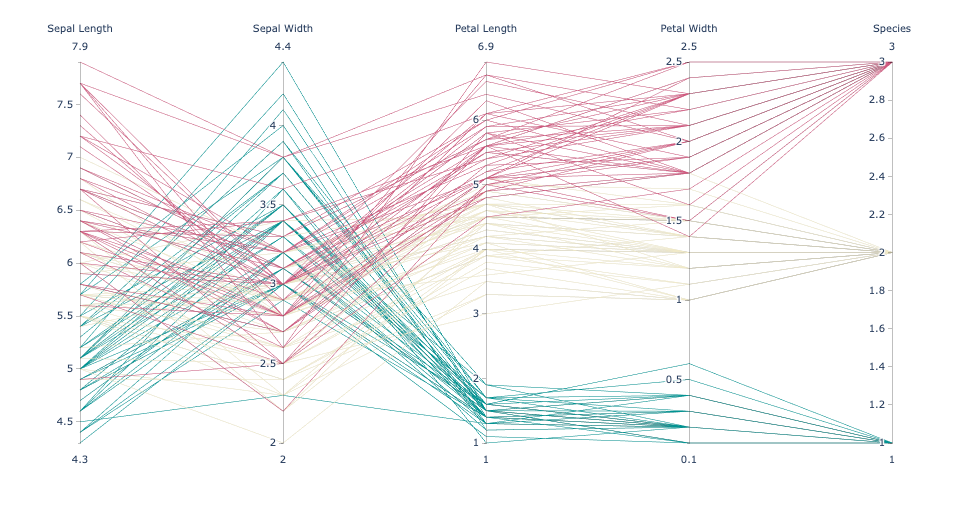
绘制类平行坐标图
-
利用searbon绘制(点线图)
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd # 导入数据 url = "https://raw.githubusercontent.com/jennybc/gapminder/master/data-raw/08_gap-every-five-years.tsv" df = pd.read_csv(url, sep='\t') # 计算各变量均值 average_data = df.groupby('continent')[['gdpPercap', 'lifeExp', 'pop']].mean() # 各变量标准化处理 normalized_data = (average_data - average_data.mean()) / average_data.std() # 绘制平行坐标图 plt.figure(figsize=(8, 6)) parallel_plot = sns.lineplot(data=normalized_data.transpose(), dashes=False, markers=True, markersize=8) # 标题 plt.title('Parallel Plot \nAverage GDP, Life Expectancy, and Population by Continent') # 删除y轴刻度与标签 plt.yticks([]) # 图例 plt.legend(title='Continent', bbox_to_anchor=(1, 1), ) plt.show()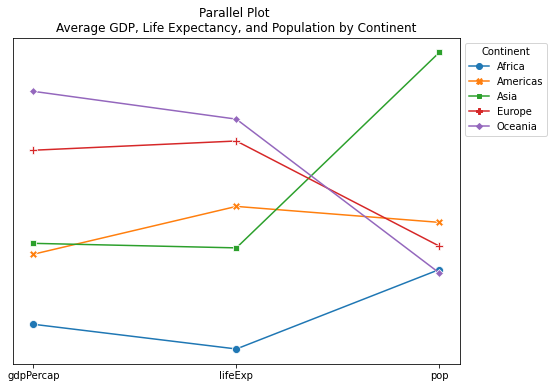
-
利用matplotlib绘制(斜率图)
import matplotlib.pyplot as plt import pandas as pd # 导入数据 url = "https://raw.githubusercontent.com/jennybc/gapminder/master/data-raw/08_gap-every-five-years.tsv" df = pd.read_csv(url, sep='\t') def add_label(continent_name, year): ''' 添加文本标签 ''' # 计算y位置 y_position = round(df[year][continent_name]) # 计算x位置 if year==1952: x_position = year - 1.2 else: x_position = year + 0.12 # 添加标签 plt.text(x_position, y_position, f'{continent_name}, {y_position}', fontsize=8, color='black', ) # 筛选1952~1957的数据 years = [1952, 1957] df = df[df['year'].isin(years)] # 计算每个大陆每年的平均 GDP df = df.groupby(['continent', 'year'])['gdpPercap'].mean().unstack() # 人为改变一个值,使至少一个大陆在两个日期之间减少(方便对比下降数据) df.loc['Oceania',1957] = 8503 # 初始化布局 plt.figure(figsize=(6, 8)) # 年份的y轴(1952、1957) plt.axvline(x=years[0], color='black', linestyle='--', linewidth=1) # 1952 plt.axvline(x=years[1], color='black', linestyle='--', linewidth=1) # 1957 # 添加y标签(BEFORE、AFTER) plt.text(1951, 11000, 'BEFORE', fontsize=12, color='black', fontweight='bold') plt.text(1957.1, 11000, 'AFTER', fontsize=12, color='black', fontweight='bold') # 绘制每个大陆的线 for continent in df.index: # 计算1952、1957的gdp value_before = df[df.index==continent][years[0]][0] value_after = df[df.index==continent][years[1]][0] # 上升为绿色、下降为红色 if value_before > value_after: color='red' else: color='green' # 添加线 plt.plot(years, df.loc[continent], marker='o', label=continent, color=color) # 每年添加各大洲的标签 for continent_name in df.index: for year in df.columns: add_label(continent_name, year) # 标题 plt.title(f'Slope Chart: \nComparing GDP Per Capita between {years[0]} vs {years[1]} \n\n\n') # 删除y轴 plt.yticks([]) # 删除边框 plt.box(False) plt.show()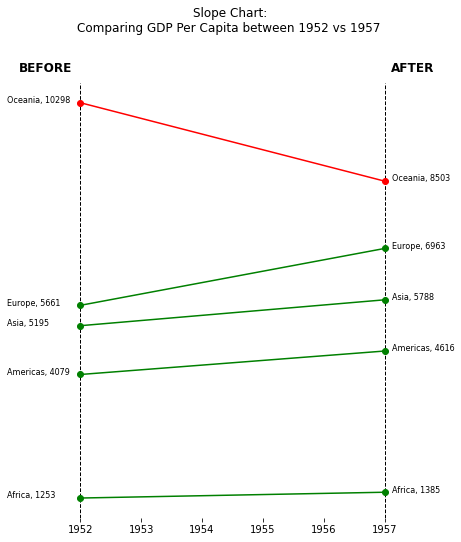
总结
以上通过pandas的parallel_coordinates和plotly的parallel_coordinates快速绘制平行坐标图,并利用seaborn和matplotlib绘制类平行坐标图。
共勉~







![[C++深入] --- malloc/free和new/delete](https://img-blog.csdnimg.cn/direct/41e1a2ecc9be486d85ac0515f7ee226d.png)