本文参考:
SwinTransformer:使用shifted window的层级Transformer(ICCV2021)_tzc_fly的博客-CSDN博客
https://zhuanlan.zhihu.com/p/430047908
目录
1 为什么在视觉中使用Transformer
2 Swin-Transformer算法总体架构
3 Swin-Transformer Block详述
3.1 transformer通用结构
3.2 Swin-Transformer Block 结构
3.2.1 为什么区分W-MSA模式和SW-MSA模式
3.2.2 W-MSA模式
3.2.3 SW-MSA模式
3.2.4 SW-MSA模式为什么要进行cyclic shift/reverse cyclic shift操作
4 Window Attention详述
4.1 MSA计算
4.2 相对位置编码
5 Patch Merging详述
6 算法总结
1 为什么在视觉中使用Transformer
计算机视觉一直由CNN主导,CNN作为各种视觉任务的backbone网络,这些体系结构的进步导致了性能的提高,从而广泛提升了整个领域。
NLP中网络体系结构的演变走了一条不同的道路,今天流行的体系结构是Transformer。Transformer是为sequence modeling而设计的,它以关注数据中的长期依赖关系而闻名。它在语言领域的巨大成功促使研究人员研究了它对计算机视觉的适应性,在图像分类和联合视觉-语言建模效果较号。
我们相信,跨越计算机视觉和自然语言处理的统一体系可以使这两个领域受益。Swin transformer在各种视觉问题上的出色表现能鼓励视觉和语言信号的统一建模。
2 Swin-Transformer算法总体架构

过程描述:
(1)输入图像为(batch=2, channel=3, height, width),经过resize等预处理后变为(2, 3, 224, 224)
(2)给图像赋予embedding,以patch_size=4*4*3(3通道的4*4像素)为一个patch(NLP中的token),reshape后变为(2,56*56,96),即56*56个token,每个token的embedding维数为96.
(3)在Swin-Transformer Block模块中,首先以window_size=7切分patches得到![]() 。然后在window内通过W-MSA和SW-MSA进行多头注意力机制的计算。接着再还原回(B,H,W,C)。所以在整个阶段只优化了特征权重,并没有改变维度。
。然后在window内通过W-MSA和SW-MSA进行多头注意力机制的计算。接着再还原回(B,H,W,C)。所以在整个阶段只优化了特征权重,并没有改变维度。
(4)Patch Merging阶段主要是进行降采样(缩小分辨率),并且调整通道数(embedding维度)
(5)经过多次第(4)、(3)步之后变为(B, H/32, W/32, 8C),即(2, 7*7, 768),reshape之后变为(2, 768, 49),在最后一维avgpooling后再squeeze变为(2, 768)
(6)然后通过全连接将最后一维变为分类数量,比如(2, 10)
3 Swin-Transformer Block详述
3.1 transformer通用结构
Swin-Transformer的核心采用了transformer的通用结构如下:

Swin-Transformer使用了成对的transformer结构,一个是W-MSA,另一个是SW-MSA。
W-MSA和SW-MSA分别是具有规则配置和移动窗口配置的多头自注意力模块。
W-MSA: Window Multi-head Self Attention
SW-MSA: Shifted Window Multi-head Self Attention
3.2 Swin-Transformer Block 结构
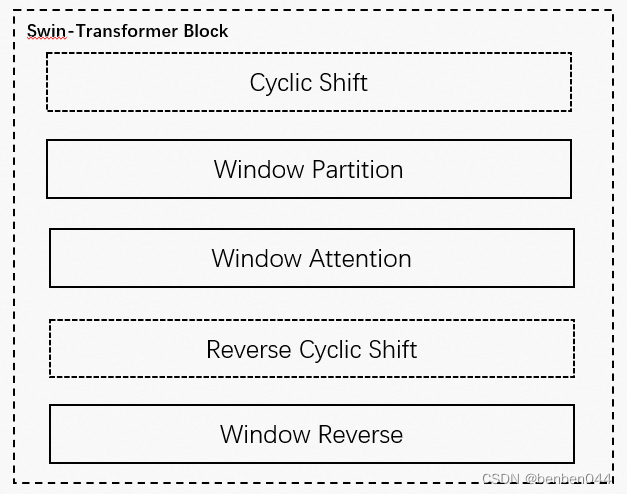
当Block为W-MSA模式时,cyclic shift和reverse cyclic shift是不存在的。当Block为SW-MSA模式时,以上步骤全部存在。
3.2.1 为什么区分W-MSA模式和SW-MSA模式
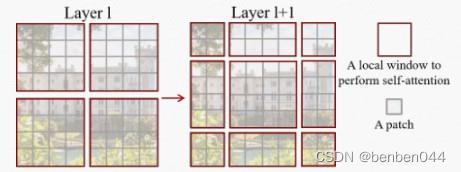
首先为了降低自注意力计算的复杂性,我们通过将图片按照window切分并只在window内计算注意力。
在上图中,Layer L为W-MSA模式计算自注意力,此时的缺陷就是缺乏跨窗口连接从而限制了建模能力。
而在Layer L+1层中,窗口分区被移动,从而产生新的窗口,新窗口中的自注意力计算跨越了层l中以前窗口的边界,从而提供了它们之间的连接,显著增强了建模能力。
通过交替使用W-MSA和SW-MSA,使得自注意力计算仅局限在窗口内部,同时又允许跨窗口连接。
3.2.2 W-MSA模式
假如Block输入的x为(2, 56, 56, 96),对应(batch, height, width, embedding)信息。
首先,Window Partition根据window_size=7将x分为一个个window,后续在window内进行MSA。经过该步骤后数据维度为(2*8*8, 7* 7, 96)。2*8*8解释:2为样本数量,8为height切分window_size后的数量,另一个8为width切分window_size后的数量。
然后,Window Attention在7*7窗口内进行MSA,该过程只进行权重更新不会更改数据维度,输出还是(128, 49, 96)。
最后,将数据还原到输入图像大小,即(2, 56, 56, 96)。
3.2.3 SW-MSA模式
假如Block输入的x仍为(2, 56, 56, 96),依然对应(batch, height, width, embedding)信息。
首先,通过cyclic shift对窗口元素进行移位,得到的数据维度仍然为(2, 56, 56, 96)
其次,Window Partition根据window_size=7将x分为一个个window,后续在window内进行MSA。经过该步骤后数据维度为(2*8*8, 7* 7, 96)。
然后,Window Attention在7*7窗口内进行MSA,该过程只进行权重更新不会更改数据维度,输出还是(128, 49, 96)。
接着,将数据还原到输入图像大小,即(2, 56, 56, 96)。
最后,通过reverse cyclic shift对之前移位的窗口进行反向移位操作,得到的(2, 56, 56, 96)。
3.2.4 SW-MSA模式为什么要进行cyclic shift/reverse cyclic shift操作

如上图所示,在SW-MSA模式下移动窗口会增加窗口的数量,从(h/M, w/M)个变成(h/M+1, w/M+1),如上图从4个增加到了9个,并且有些窗口大小是小于M*M的。
解决方法一:将大小不足M*M的窗口填充到M*M的大小,并在计算注意力时屏蔽这些填充值。但是这种native的做法会增加很多计算量(比如计算的窗口数量从2*2变成3*3)。
解决方法二:向左上角循环移位,在这个移位之后,一个批处理窗口可能由几个在特征图中不相邻的子窗口组成,使用mask机制将自注意力计算限制在每个子窗口内。通过循环移位,批处理窗口的数量与常规窗口分区的数量相同。
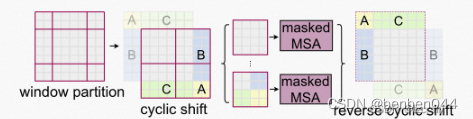
将图中浅色ABC windows转移到深色ABC的填充部分,这个操作可以用两次torch.roll实现,第一次将第一行移动到最后一行,第二次将第一列移动到最后一列。从而使得最后的feature map依然为2*2的windows,保持原有的计算量,然后再使用图中紫色部分的masked MSA进行计算。结束之后,再reverse cyclic shift。
当我们做cyclic shift 后有:

对于第二个特征图,我们可以很几何地按照之前地window划分方式(标准的2*2个窗口)去计算,但是对于3个窗口:即(4+6),(2+8),(1+3+7+9)的attention会混在一起,所以需要在计算每个窗口时进行mask MSA。
以窗口(4+6)为例,假设该窗口一共有4个patch:

当自注意力计算时,重点在于QKT,为了保证信息只在cyclic shift前的window内交互,我们要确保只存在属于window 4和window 4的两个patch计算attention,换言之就是在计算注意力时候只有行和列属于相同编号的元素才保留,其他元素都mask。

至此,我们利用shift后的feature,和上面说的mask结合,就能得到正确的MSA结果。
我们最后把shift还原,即reverse shift。
4 Window Attention详述
传统的Transformer都是基于全局来计算注意力,而swin-transformer则将注意力的计算限制在每个窗口内,从而减少了计算量。
计算公式为:
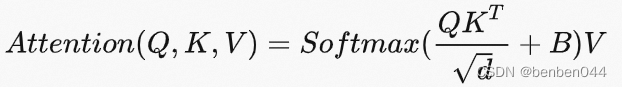
Swin-transformer使用attention机制与原始计算的区别在于公式中的计算后加入了相对位置编码。
4.1 MSA计算
假设输入数据维度为(128, 49, 96)。
首先,通过全连接将embedding维度乘以3,得到(128, 49, 288)。
然后,将维度变为(128, 49, 3, num_heads, 288/num_heads),继续变为(3, 128, num_heads, 49, 288/num_heads),然后q, k, v分别为(128, num_heads, 49, 288/num_heads)=(128, 3, 49, 96)。
接着,得到attention值(128, 3, 49, 49),加上相对位置编码信息(1, 3, 49, 49)后,再进行softmax后乘以v得到最终值,输出维度仍然为(128, 49, 96)。
4.2 相对位置编码
此处相对位置编码并不是固定的,是需要训练的。在模型定义中初始化相对位置编码参数,在后续训练中更新这部分参数。
首先我们计算每个token的相对位置索引信息,这个是一次性的,和window_size相关。相对位置索引=基准点的绝对位置索引-该点的绝对位置索引。对于2*2的window来说,基准点的绝对位置索引分别为(0,0),(0,1),(1,0),(1,1)。

得到了相对位置索引之后,就可以根据索引拿到对应的编码权重值。
5 Patch Merging详述
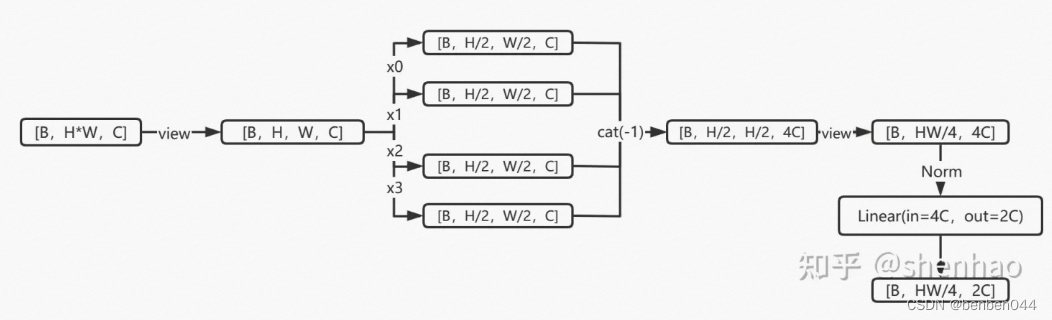
降采样操作,用于缩小分辨率,调整通道数进而形成层次化的设计。
每次降采样时在行和列方向间隔2选取元素,然后在embedding维度拼接。因为H,W各缩小为1/2,所以embedding维度会变成原先的4倍。最后再通过一个全连接调整embedding维度为原来的2倍。
整体流程如下:
6 算法总结
(1)时间复杂度减少,主要是在于分别只在window内计算注意力
(2)为了融合不同窗口之间的信息,采用shifted window划分策略,不用于过去的sliding window这种native的方式,shifted window的特点在于cyclic shift + masked MSA + reverse cyclic shift,这实现了无padding且不增加窗口数量的情况下达到sliding window的效果
(3)层级的架构可以考虑不同尺度的window,从而获得多尺度信息