微信搜索”国际云安全联盟“,回复关键词“云事件”下载本报告
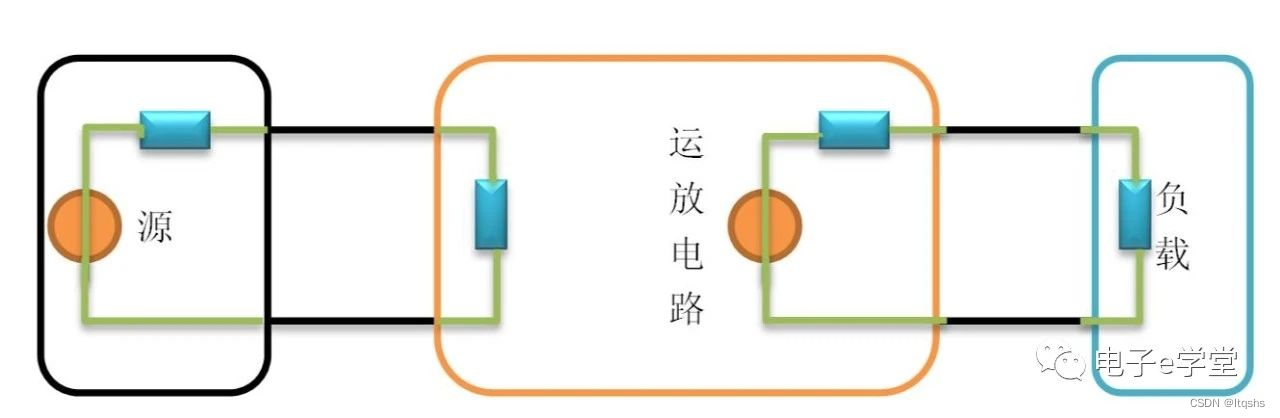
当今互联时代,全面的事件响应策略对于需要管理与降低风险的组织必不可少。然而,在基于云的基础设施和系统的事件响应策略方面,部分由于云的责任共担特性,存在诸多顾虑因素。
许多政府与行业的指南中都有针对传统的本地信息技术(IT)环境制定事件响应的框架,但是,当把云计算环境也考虑在内时,必须修改和完善传统事件响应框架中定义的角色和职责,以便与在不同云服务模式及部署模式的云服务提供商(以下简称:CSP)和云服务客户(以下简称:CSC)的角色和职责保持一致。
国际云安全联盟CSA发布《云事件响应(CIR)框架》,旨在为用户提供一个广泛使用的整体框架和一致的视图,提供有效准备和管理云事件风险的指南,并为CSP与CSC共享云事件响应实践提供透明和通用的框架。

CSC和CSP共同责任风险矩阵
云事件响应框架(CIR)可以定义为在云环境中管理网络攻击的过程,本白皮书框架采用了《CSA云计算关键领域安全指南》和《NIST计算机安全事件处理指南》(NIST 800-61rev2 08/2012)中普遍接受的“事件响应生命周期”,包括四个阶段:
· 第一阶段: 准备和后续评审
· 第二阶段:检测与分析
· 第三阶段:遏制、根除和恢复
· 第四阶段:事后分析

第一阶段:准备和后续评审
准备工作涉及云事件之前所需的策略和行动。有效的事件响应计划包括组建CIR团队(CIRT)、战略规划和准备、程序开发、技术准备和沟通计划创建。
在云环境中,CSC并不是所有系统的所有者。根据采用的服务模型及其相应的责任共担模型,一些工件和日志由CSP管理。当第三方 IR 提供者参与时,CIR 计划也应将它们包括在整个过程中。
CIR计划应包括:
· 现有环境、云架构、责任模型分析。
· 为有效和高效的CIR响应和补救制定事件处理计划、流程和程序/自动化(CSC和CSP)。
· 技术层面的准备(CSC和CSP),主动监控运行错误和恶意活动的指标。
· 沟通渠道准备(CSC和CSP)
同时,在整个IR过程中,组织应维护事件文件,确保有系统的记录,有效地审查事件和经验学习。
第二阶段:检测和分析
检测和分析涵盖了云事件的各种迹象和可能的原因,以便及早发现。为了确定根本原因,讨论了多种方法,早期事件通知的速度(以及基于业务影响的相应解决时间)也是CSP/CSC考虑的重点。
以下为分析事件,判断影响的步骤:
事件分析:如果问题判断是“假报警”,那么文档(也就是工单)应该将该评估更新并关闭该问题。必须评估每个指标,确定其合法性。
事件通知:事件响应计划需要系统地安排使得业务和服务运营影响最小化,并且在事件发生时通知相关方。事件发布应该取决于事件影响的严重程度,由于高度复杂的云环境存在大量的事件,只有那些关键和影响严重的事件才需要通知高层。CSP和CSC应将事件发布矩阵集成到双方合同和(或)SLA中。
事件通知时机:通知时间至关重要。尽管需要快速处置事件,但是尽快通知利益相关方也同样重要,使得他们理解当前情况,从而能够建议和采取必要行动降低事件影响。
事件影响:事件影响模型必须事先建立,CSP和CSC使用该模型保障在事件评估、事件影响、通知和相应的响应活动的一致性。事件优先矩阵(也被称为“影响和应急矩阵”)来源于影响的严重程度和应急水平。必下面例子包括了CSP和CSC应该共同考虑的关键影响类型:
· 业务:业务危急的范围和水平
· 财务:停工损失或声誉损害
· 监管/法律:数据隐私和合同条款
证据收集与处理:识别与调查相关的数据对于确定事件的根本原因和识别经验教训以避免重复至关重要。识别出的数据还可以帮助支持有益的信息共享计划,以防止类似事件的发生。
第三阶段:遏制、根除和恢复
遏制、根除和恢复解释了在进行调查和取证时选择正确策略阻止攻击者进一步破坏系统的重要性。
选择遏制策略:在某些情况下,一些组织将攻击者重定向到沙盒(一种类似蜜罐的遏制形式),以便监视攻击者的活动。IR团队应该与其法律顾问讨论该策略,确定其可行性。
根除:消除问题。这包括最大限度地减少损失、信息被盗和服务中断,以及消除威胁。
恢复:包括安全、及时地恢复计算服务。恢复过程将系统修复到原始的或增强的状态。此过程通过应用补丁、重建系统的密钥文件、重新安装应用程序、更改密码和从备份中恢复文件,将其返回到生产过程中。
第四阶段 事后分析
事后分析过程识别人员、流程或技术方面的差距,并将其转化为必须在准备阶段吸取的“经验教训”。这一结束阶段的关键目标是改进未来的事件处理。
事件评估
对事件特征的分析可以在最低限度上指出安全弱点和威胁、云配置弱点以及事件趋势的变化。这些数据可以作为反馈循环添加到风险评估过程中,可能导致选择和实施额外的控制措施、流程和预防措施。
事件评估指标
收集突发事件数据,确定是否随着时间的推移而存在显著的趋势。集到的事件数据应该包含以下信息的指标(性能指标):
· 平均检测时间(MTTD):发现安全事件的平均时间。
· 平均确认时间 (MTTA):安全操作员响应系统警报所需的时间。
· 平均恢复时间 (MTTR):使系统恢复运行状态所需的时间。
· 平均遏制时间 (MTTC):检测、响应、消除和从事件中恢复所需的平均时间。
· 威胁指标,例如DDoS攻击时的Gbps或Tbps。
· 威胁行为者TTP(策略、技术和程序)。这些包括网络钓鱼和账户操纵。
事件总结报告
事件结束后,管理事件的CIR团队应使用从先前阶段和事件评估收集的数据撰写正式的事后报告 (AAR)。通常认为有必要在向高层管理人员报告信息后向更广泛的公众发布报告,促进跨企业的事件信息共享,这种透明度有助于同行更好地识别和控制风险。
事故证据保留
在“第2阶段检测和分析”期间收集的所有已识别证据必须根据企业适用的法律、法规、行业或合同义务的要求予以保留。为以下三个目的保留证据:
· 监管合规要求(即审计日志、警报生成、活动报告和数据保留的特定级别和粒度)。数据保留可能不是受提供商影响的标准服务协议的一部分。
· 法律:支持对破坏PII/PHI或企业系统的起诉。
· 风险管理:反映和重新评估新的威胁策略和技术。
· 培训:为了促进团队更好地为未来的事件做好准备,将适应性事件学习纳入其中