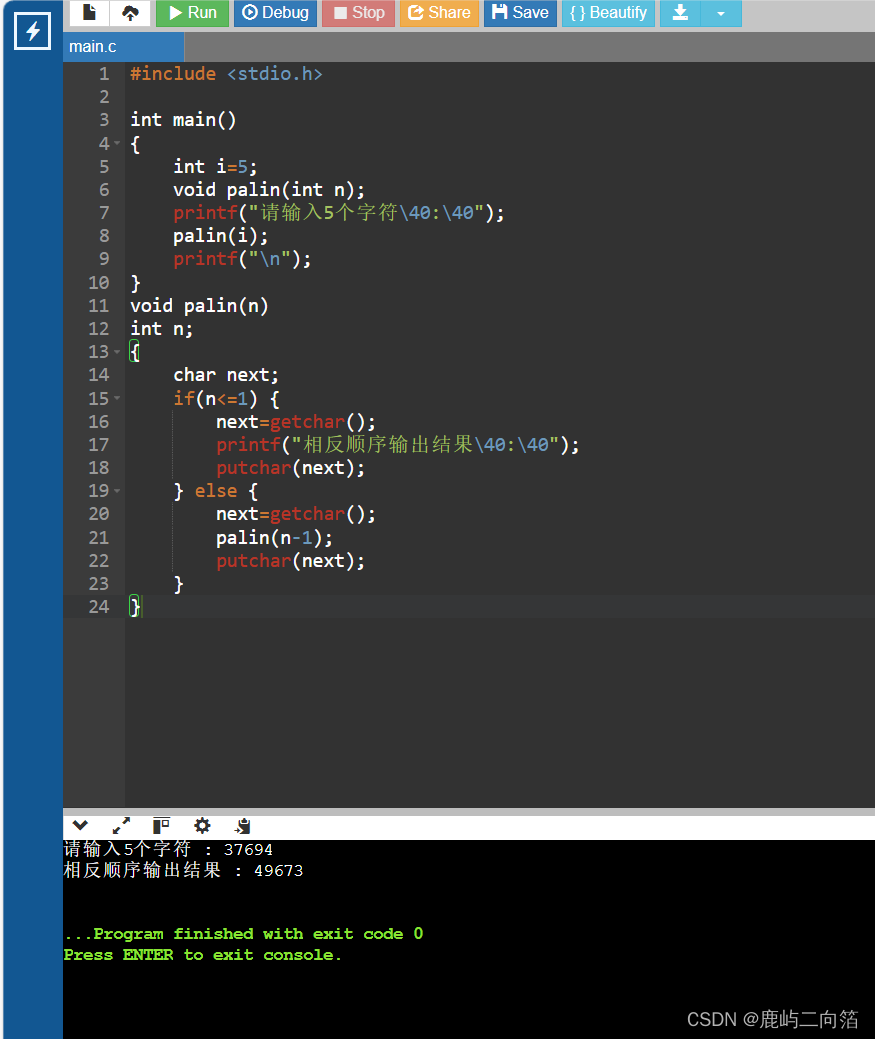
文章目录
- 一. 基础逻辑
- 二. DirtyManager
- 1. 初始化
- 2. 收集脏数据并check
- 3. 关闭资源
- 三. DirtyDataCollector
- 1. 初始化
- 2. 收集脏数据并check
- 3. run:消费脏数据
- 4. 释放资源
- 四. LogDirtyDataCollector
一. 基础逻辑
脏数据管理模块的基本逻辑是:
- 当数据消费失败时,将脏数据拦截并保存到dirtyDataCollector中;
- 全局metric判断:脏数据达到设定值之后,任务报错,flink停止运行,并将脏数据输出到flink日志中、或mysql的配置中。
对于代码实现:
DirtyManager用于管理DirtyDataCollector,串起DirtyDataCollector的生命周期,DirtyDataCollector主要用于收集脏数据并输出(到日志中,mysql中),脏数据数量达到设定值之后,flink停止运行。
具体的DataCollector实现有:

分别用于输出到taskmanager的日志、(最后报错时)jobmanager日志、输出到mysql表中。
所以这里有三层代码结构:
- DirtyManager:管理DirtyDataCollector
- DirtyDataCollector:主要用于收集脏数据并输出,并判断脏数据是否达到临界值
- 具体的DataCollector的实现:具体的输出实现:输出到日志,输出到mysql。
接下来我们逐个看每层的具体实现逻辑
二. DirtyManager
DirtyManager用于管理DirtyDataCollector,串起DirtyDataCollector的生命周期(open、run、close),主要流程如下:
- 设置系统配置给DirtyDataCollector
- 开启DirtyManager线程,主要用于DirtyDataCollector消费脏数据(收集脏数据)
- 关闭资源:DirtyDataCollector、DirtyManager的线程资源。
1. 初始化
初始化DirtyManager
- 根据配置加载特定的DirtyDataCollector:用于脏数据的收集
- 获取系统信息:jobId、jobName、operationName
- 获取脏数据metric,用于定期合并脏数据为全局脏数据。
public DirtyManager(DirtyConfig dirtyConfig, RuntimeContext runtimeContext) {
//通过反射注册DirtyDataCollector
this.consumer = DataSyncFactoryUtil.discoverDirty(dirtyConfig);
Map<String, String> allVariables = runtimeContext.getMetricGroup().getAllVariables();
this.jobId = allVariables.get(JOB_ID);
this.jobName = allVariables.getOrDefault(JOB_NAME, "defaultJobName");
this.operationName = allVariables.getOrDefault(OPERATOR_NAME, "defaultOperatorName");
this.errorCounter = runtimeContext.getLongCounter(Metrics.NUM_ERRORS);
}
2. 收集脏数据并check
被具体的连接器调用:
具体当连接器生产数据或写数据到数据源报错时,调用此方法收集脏数据
- 创建线程,用于异步执行DirtyDataCollector,开始消费脏数据到日志或mysql表中
- 添加脏数据条数,同步到全局脏数据metric中
- 脏数据信息,存到队列中,等待具体的脏数据收集器消费
- 子流程:判断脏数据条数是否大于总脏数据条数
public void collect(Object data, Throwable cause, String field, long globalErrors) {
if (executor == null) {
execute();
}
DirtyDataEntry entity = new DirtyDataEntry();
entity.setJobId(jobId);
entity.setJobName(jobName);
entity.setOperatorName(operationName);
entity.setCreateTime(new Timestamp(System.currentTimeMillis()));
entity.setDirtyContent(toString(data));
entity.setFieldName(field);
entity.setErrorMessage(ExceptionUtil.getErrorMessage(cause));
//积累metric:errorCounter,这里直接同步到jobmanager?
errorCounter.add(1L);
//将脏数据添加到队列,等待消费。
consumer.offer(entity, globalErrors);
}
/**
* 创建线程,用于异步执行DirtyDataCollector
*/
public void execute() {
if (executor == null) {
executor =
new ThreadPoolExecutor(
MAX_THREAD_POOL_SIZE,
MAX_THREAD_POOL_SIZE,
0,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(),
new ChunJunThreadFactory(
"dirty-consumer",
true,
(t, e) -> {
log.error(
String.format(
"Thread [%s] consume failed.", t.getName()),
e);
}),
new ThreadPoolExecutor.CallerRunsPolicy());
}
//初始化DirtyDataCollector:比如脏数据定时发送到mysql时的线程注册
consumer.open();
//拿出一个线程执行DirtyDataCollector的execute方法
executor.execute(consumer);
}
3. 关闭资源
/** Close manager. */
public void close() {
if (!isAlive.get()) {
return;
}
//先关闭datacollector的资源
if (consumer != null) {
consumer.close();
}
//再关闭executor线程
if (executor != null) {
executor.shutdown();
}
isAlive.compareAndSet(true, false);
}
三. DirtyDataCollector
处于第二层的dirtyDataCollector实现了脏数据的临时保存并等待具体DataCollector的消费,
它的基本逻辑是:
- 当脏数据消费失败时,将脏数据拦截并保存到consumeQueue中,等待被消费
- 全局的metric:脏数据达到设定值之后,任务报错,flink停止运行,并将脏数据输出到flink日志中。
1. 初始化
在DirtyManager实例化时,注册DirtyDataCollector时的操作,
这里获取脏数据最大值,允许消费脏数据失败的条数,以及对具体DataCollector的初始化,我们下节分析。
public void initializeConsumer(DirtyConfig conf) {
this.maxConsumed = conf.getMaxConsumed();
this.maxFailedConsumed = conf.getMaxFailedConsumed();
this.init(conf);
}
被DirtyManager调用:在开启脏数据收集器线程之前执行
初始化具体脏数据收集器:目前之后mysql脏数据收集器实现了此方法:消费线程、mysql连接
public void open() {
}
2. 收集脏数据并check
offer方法被DirtyManager的collect方法调用
- 用于存储具体脏数据并更新单个slot的脏数据条数。
- 每添加一条脏数据,就判断脏数据是否达到了设定值,如果是则抛出异常。
其中:globalErrors是上文AccumulatorCollector定期更新的结果。
//存储脏数据具体内容,并更新单个slot的脏数据条数
public synchronized void offer(DirtyDataEntry dirty, long globalErrors) {
consumeQueue.offer(dirty);
addConsumed(1L, dirty, globalErrors);
}
/**
* 添加脏数据
* 通过metric判断此时的脏数据条数,是否已经超过全局设置的脏数据条数
* @param count
* @param dirty
* @param globalErrors
*/
protected void addConsumed(long count, DirtyDataEntry dirty, long globalErrors) {
consumedCounter.add(count);
// 因为总体的脏数据需要tm和jm进行通讯(每tm心跳+1s),会有延迟,且当单slot运行时误差将达到最大
// 所以这里需要判断延迟情况
long max =
consumedCounter.getLocalValue() >= globalErrors
? consumedCounter.getLocalValue()
: globalErrors;
// 但这里仍然有误差:此时如果所有的slot都消费了脏数据那么其他slot的脏数据就记录不到。也就是会多消费脏数据
// 所以这里要有取舍:是否要消费完全准确的脏数据
if (max >= maxConsumed) {
StringJoiner dirtyMessage =
new StringJoiner("\n")
.add("\n****************Dirty Data Begin****************\n")
.add(dirty.toString())
.add("\n****************Dirty Data End******************\n");
throw new NoRestartException(
String.format(
"The dirty consumer shutdown, due to the consumed count exceed the max-consumed [%s]",
maxConsumed)
+ dirtyMessage);
}
}
3. run:消费脏数据
由DirtyManager开启脏数据消费线程,
具体的DataCollector(log、mysql)消费脏数据,发送到Taskmanager日志或mysql表中。
/**
* 开启脏数据消费线程
* 定时消费脏数据,发送到执行脏数据管理器中:log、mysql等
*/
@Override
public void run() {
while (isRunning.get()) {
try {
//指定的DataCollector消费脏数据
DirtyDataEntry dirty = consumeQueue.take();
consume(dirty);
} catch (Exception e) {
//未成功将脏数据收集到脏数据管理模块中
addFailedConsumed(e, 1L);
}
}
}
/**
* 消费脏数据用于输出到日志、mysql等
*/
protected abstract void consume(DirtyDataEntry dirty) throws Exception;
4. 释放资源
不同的DataCollector有不同的操作,下节分析
public abstract void close();
四. LogDirtyDataCollector
实现比较简单:拿到的数据直接打印到Taskmanager中,关闭时,设定isRunning为false
/**
* 没有线程,调用即输出到日志中
*/
@Slf4j
public class LogDirtyDataCollector extends DirtyDataCollector {
private static final long serialVersionUID = 7366317208451727471L;
private Long printRate;
@Override
protected void init(DirtyConfig conf) {
this.printRate = conf.getPrintRate();
}
/**
* 输出脏数据到taskmanager
* @param dirty dirty-data which should be consumed.
*/ @Override
protected void consume(DirtyDataEntry dirty) {
if (consumedCounter.getLocalValue() % printRate == 0) {
StringJoiner dirtyMessage =
new StringJoiner("\n")
.add("\n====================Dirty Data=====================")
.add(dirty.toString())
.add("\n===================================================");
log.warn(dirtyMessage.toString());
}
}
@Override
public void close() {
isRunning.compareAndSet(true, false);
log.info("Print consumer closed.");
}
}
下篇分析MysqlDirtyDataCollector是如何消费数据。