2022年11月,OpenAI推出基于GPT-3.5的ChatGPT后,引发全球AI大模型技术开发与投资热潮。AI大模型性能持续快速提升。以衡量LLM的常用评测标准MMLU为例,2021年底全球最先进大模型的MMLU 5-shot得分刚达到60%,2022年底超过70%,而2023年底已提升至超过85%。以OpenAI为例,2020年7月推出的GPT-3得分43.9%,2022年11月推出的GPT-3.5提升至70.0%,2023年3月和2024年5月推出的GPT-4、GPT-4o分别提升至86.4%和87.2%。谷歌目前性能最佳的大模型Gemini 1.5 Pro得分达到85.9%。开源模型性能不容小觑,2024年4月推出的Llama 3 70B得分已经达到82.0%。

在语言能力之外,AI大模型的多模态能力也快速提升
2023年初,主流闭源大模型通常为纯文本的LLM。2023年至今,闭源模型的多模态能力具有大幅度提升,目前主流闭源大模型通常具备图像理解、图像生成能力。如图表24所示,虽然开源模型的文本能力有了较大提升,但大多数开源模型尚不具备多模态能力。目前大模型多模态能力的技术聚焦转向了原生多模态。全球仅谷歌和OpenAI发布了其原生多模态模型Gemini、GPT-4o。创建多模态模型时,往往分别训练不同模态的模型并加以拼接,而原生多模态模型一开始就在不同模态(文本、代码、音频、图像和视频)上进行预训练,因此能够对输入的各模态内容顺畅地理解和推理,效果更优。例如,对于非原生多模态模型的GPT-4,其语音模式由三个独立模型组成,分别负责将音频转录为文本、接收文本并输出文本、将该文本转换回音频,导致 GPT-4 丢失了大量信息——无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。而原生多模态模型GPT-4o,多种模态的输入和输出都由同一神经网络处理,因此信息丢失更少,模型效果更好。

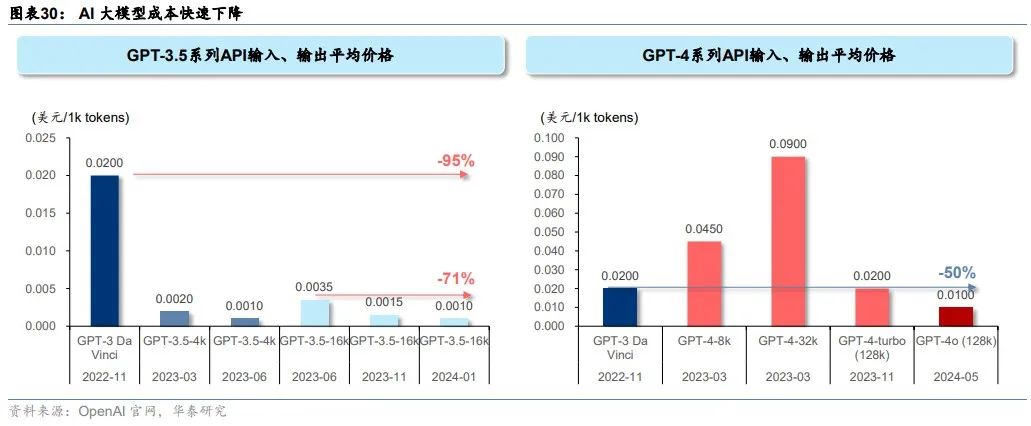
AI大模型不断提升的同时,得益于算力芯片性能的提升与推理部署的优化,大模型应用成本快速下降,为基于大模型的应用发展创造了基础。目前OpenAI最前沿的GPT-4o (128k)输入输出的平均价格比2022年11月的GPT-3 Da Vinci低一半,主打高性价比的GPT-3.5 (16k)平均价格则比GPT-3 Da Vinci低95%。在GPT-4系列中,GPT-4o (128k)平均价格相较2023年3月的GPT-4 (32K)低89%。
海外:微软&OpenAI与谷歌领先,Meta选择开源的防御性策略
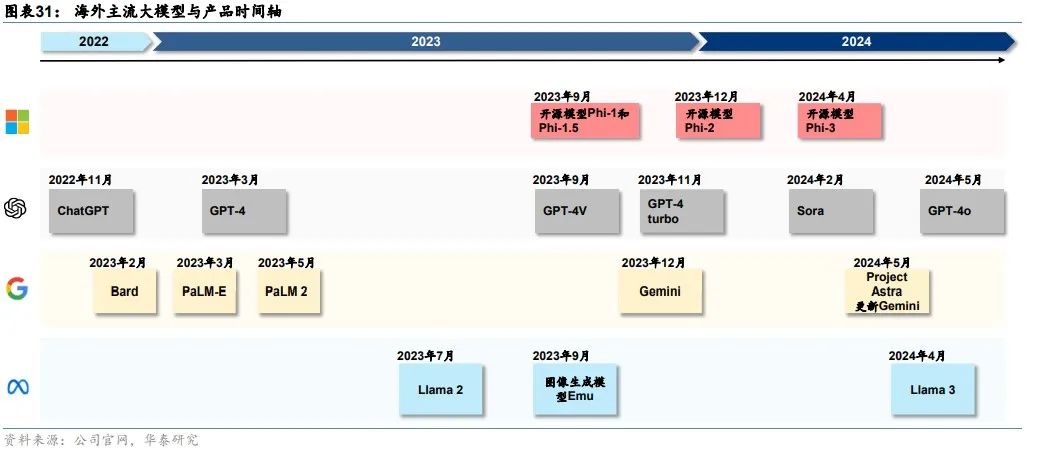
我们复盘了过去一年海外基础大模型训练企业在大模型技术、产品化和商业化上的进展。微软和OpenAI是目前大模型技术水平、产品化落地最为前沿的领军者,其对颠覆式创新的持续投入是当前领先的深层原因。谷歌技术储备丰厚,自有业务生态广阔并且是AI落地的潜在场景,过去由于管理松散未形成合力,我们看到谷歌从2023年开始整合Google Brain和Deepmind,目前正在产品化、生态化加速追赶。Meta选择模型开源的防御性策略,以应对OpenAI、谷歌等竞争对手的强势闭源模型。
微软&OpenAI:闭源模型全球领先,大模型产品化处于前沿
OpenAI最前沿模型GPT系列持续迭代。2022年11月,OpenAI推出的基于GPT-3.5的ChatGPT开启了AI大模型热潮。此后,OpenAI持续迭代GPT系列模型:1)2023年3月发布GPT-4,相比GPT-3.5仅支持文字/代码的输入输出,GPT-4支持输入图像并且能够真正理解;2)2023年9月发布GPT-4V,升级了语音交互、图像读取和理解等多模态功能;3)2023年10月将DALL・E 3与ChatGPT结合,支持文生图功能;4)2023年11月发布GPT-4 turbo,相比GPT-4性能提升,成本降低,支持128k tokens上下文窗口(GPT-4最多仅为32k);5)2024年5月发布其首个端到端多模态模型GPT-4o,在文本、推理和编码智能方面实现了 GPT-4Turbo 级别的性能,同时在多语言、音频和视觉功能上性能更优。GPT-4o 的价格是 GPT-4 turbo 的一半,但速度是其2倍。得益于端到端多模态模型架构,GPT-4o 时延大幅降低,人机交互体验感显著增强。
OpenAI多模态模型布局完整。在多模态模型方面,除了文生图模型DALL・E3,OpenAI在2024年2月推出了文生视频模型Sora,Sora支持通过文字或者图片生成长达60秒的视频,远超此前Runway(18秒)、Pika(起步3秒+增加4秒)、Stable Video Diffusion(4秒)等AI视频应用生成时长,此外还支持在时间上向前或向后扩展视频,以及视频编辑。
微软Phi系列小模型面向开源,将自研MAI系列大模型。微软自研小模型为客户提供更多选择,2023年发布Phi-1.0(1.3B)、Phi-1.5(1.3B)、Phi-2模型(2.7B),2024年开源了 Phi-3系列,包括3款语言模型——Phi-3-mini(3.8B)、Phi-3-small(7B)和Phi-3-medium(14B),以及一款多模态模型Phi-3-vision(4.2B)。此外,据The information 2024年5月报道,微软将推出一款参数达5000亿的大模型,内部称为MAI-1,由前谷歌AI负责人、Inflection CEO Mustafa Suleyman负责监督。
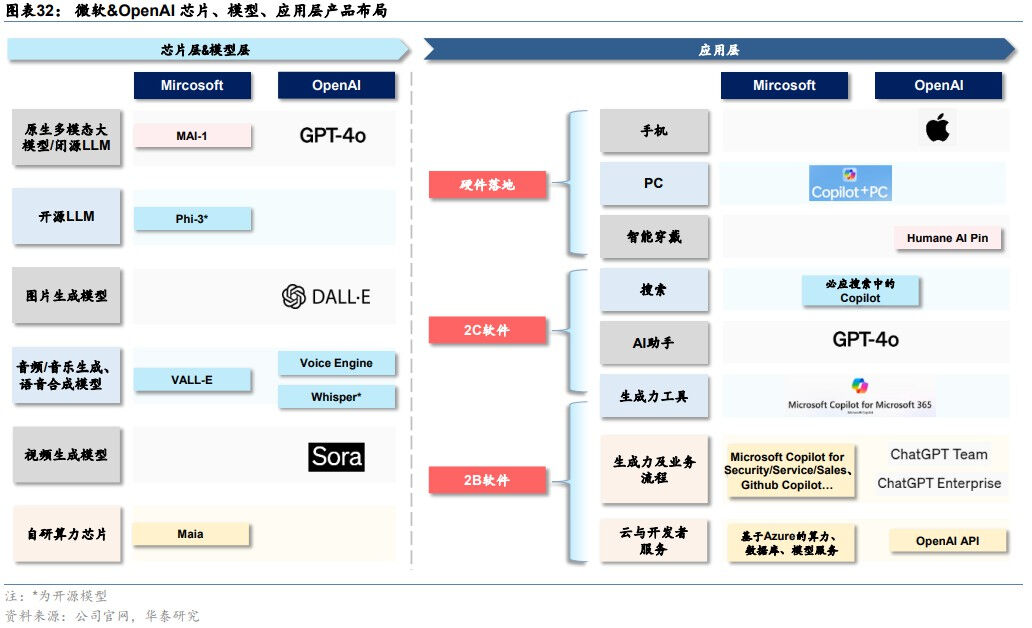
产品化方面,微软与OpenAI将大模型能力对原有的软件产品、云计算业务、智能硬件进行全面升级。1)微软围绕企业办公、客户关系管理、资源管理、员工管理、低代码开发等业务环节具有完整的产品矩阵,2023年以来推出相应的Copilot产品对原有产品进行AI大模型赋能,其中产品化最早、最为核心的是面向企业办公场景的Copilot for Microsoft 365,以及面向C端用户的Copilot for Windows,以及集成在Bing搜索、Edge浏览器的Copilot。2)云计算业务方面,Azure云业务向MaaS服务发展,提供算力、模型、数据工具、开发工具等服务。3)智能硬件方面,微软在2024年5月发布GPT-4o加持的Copilot+PC,除微软Surface以外,联想、戴尔、惠普、宏碁、华硕等PC厂商也将发布Copilot+PC新品。
谷歌:闭源模型全球领先,自有业务生态及AI潜在落地空间广阔
谷歌最前沿的闭源模型从PaLM系列切换到Gemini。2022-2023年,PaLM系列模型是谷歌的主力模型,2022年4月发布的PaLM、2022年10月发布的Flan PaLM以及2023年5月I/O大会发布的PaLM-2都是谷歌当时的主力大模型。2023年12月,谷歌发布全球首个原生多模态模型Gemini,包含 Ultra、Pro 和 Nano 三种不同大小。根据Gemini Technical Report,Ultra版在绝大部分测试中优于GPT-4。2024年2月,谷歌发布Gemini 1.5 Pro,性能更强,并且拥有突破性的达100万个Tokens的长上下文窗口。
2024年5月I/O大会上,谷歌对Gemini再次更新:1)发布1.5 Flash,是通过API提供的速度最快的Gemini模型。在具备突破性的长文本能力的情况下,它针对大规模地处理高容量、高频次任务进行了优化,部署起来更具性价比。1.5 Flash在总结摘要、聊天应用、图像和视频字幕生成以及从长文档和表格中提取数据等方面表现出色。2)更新1.5 Pro。除了将模型的上下文窗口扩展到支持200万个tokens之外,1.5 Pro的代码生成、逻辑推理与规划、多轮对话以及音频和图像理解能力进一步提升。
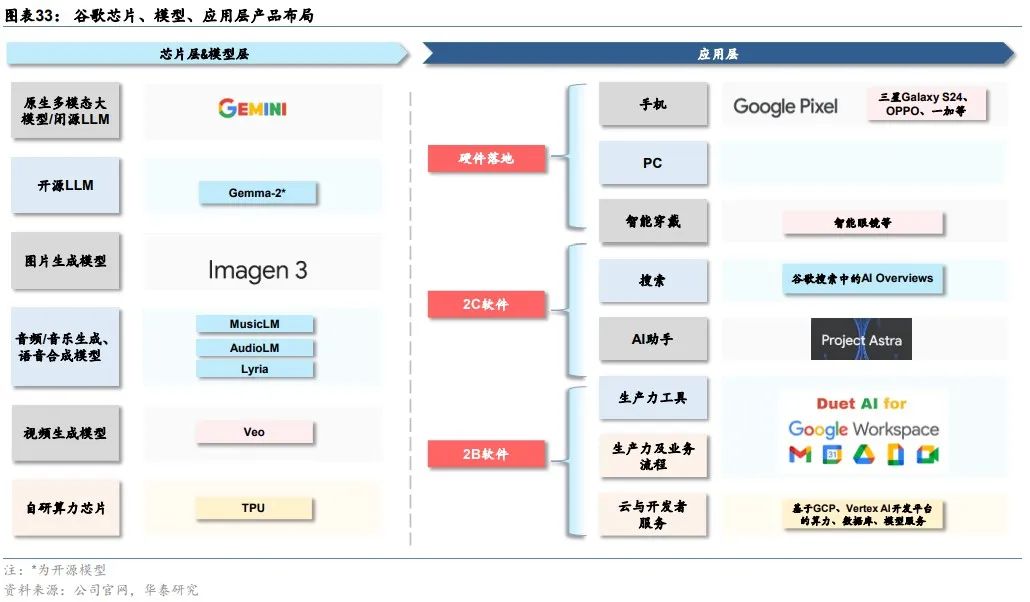
产品化方面,谷歌将大模型能力融入自有软件业务、云计算和智能硬件之中。1)自有软件业务:谷歌在2023年5月I/O大会上宣布将PaLM 2应用在超过25种功能和产品中,包括2B办公套件Workspace、聊天机器人Bard等等。随着谷歌主力大模型切换到Gemini,Workspace和Bard背后的大模型也同步切换。2)云计算:谷歌通过Vertex AI和Google AI Studio向MaaS延伸。Vertex AI是AI开发和运营(AIOps)平台,支持组织开发、部署和管理AI模型。Google AI Studio是基于网络的工具,可以直接在浏览器中设计原型、运行提示并开始使用API。3)智能硬件:2024年下半年,据Techweb,谷歌有望在10月推出Pixel9系列,预计将搭载基于最新Gemini模型的AI助手,执行复杂的多模态任务。
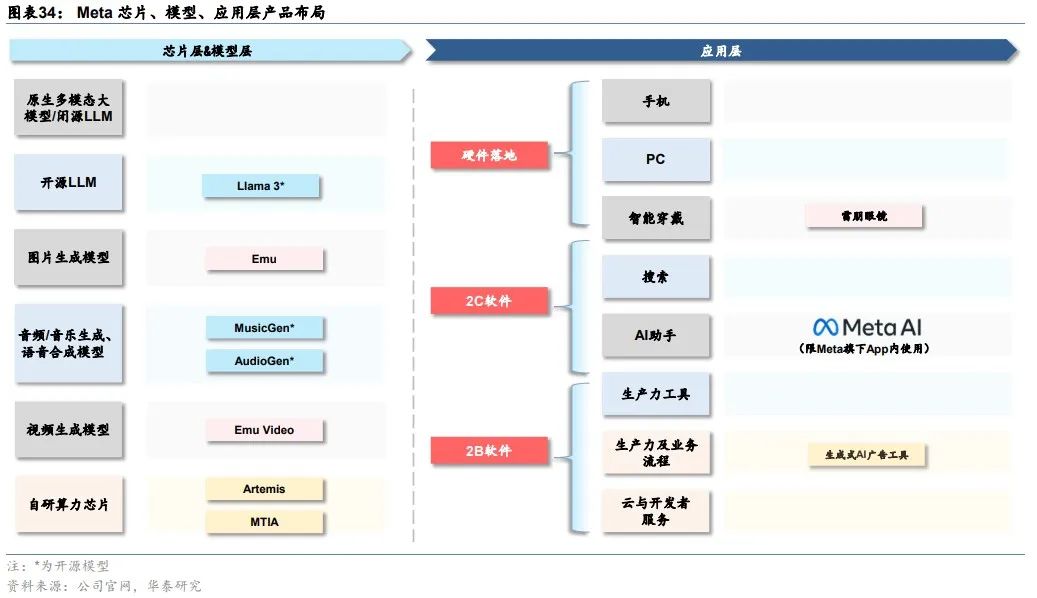
Meta:Llama开源模型领先
Meta凭借Llama系列开源模型在大模型竞争中独树一帜,目前已发布三代模型。Meta在2023年2月、7月分别推出Llama与Llama 2。Llama 2,提供7B、13B、70B三种参数规模,70B在语言理解、数学推理上的得分接近于GPT-3.5,在几乎所有基准上的任务性能都与PaLM 540B持平或表现更好。2024年4月,Meta发布Llama 3,Llama 3性能大幅超越前代Llama 2,在同等级模型中效果最优。本次开源参数量为8B和70B的两个版本,未来数个月内还会推出其他版本,升级点包括多模态、多语言能力、更长的上下文窗口和更强的整体功能。最大的400B模型仍在训练过程中,设计目标是多模态、多语言,根据Meta公布的目前训练数据,其性能与GPT-4相当。
Meta基于LLama系列模型打造智能助手Meta AI、雷朋Meta智能眼镜等硬件产品。Meta同时更新基于Llama 3构建的智能助手Meta AI,无需切换即可在 Instagram、Facebook、WhatsApp和 Messenger的搜索框中畅通使用 Meta AI。Llama 3很快将在 AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM和Snowflake 上推出,并得到AMD、AWS、戴尔、英特尔、英伟达、高通提供的硬件平台的支持。此外,雷朋Meta智能眼镜也将支持多模态的Meta AI。
国内大模型:格局清晰,闭源追赶GPT-4,开源具备全球竞争力
我们复盘了过去一年国内基础大模型训练企业在大模型技术、产品化和商业化上的进展:
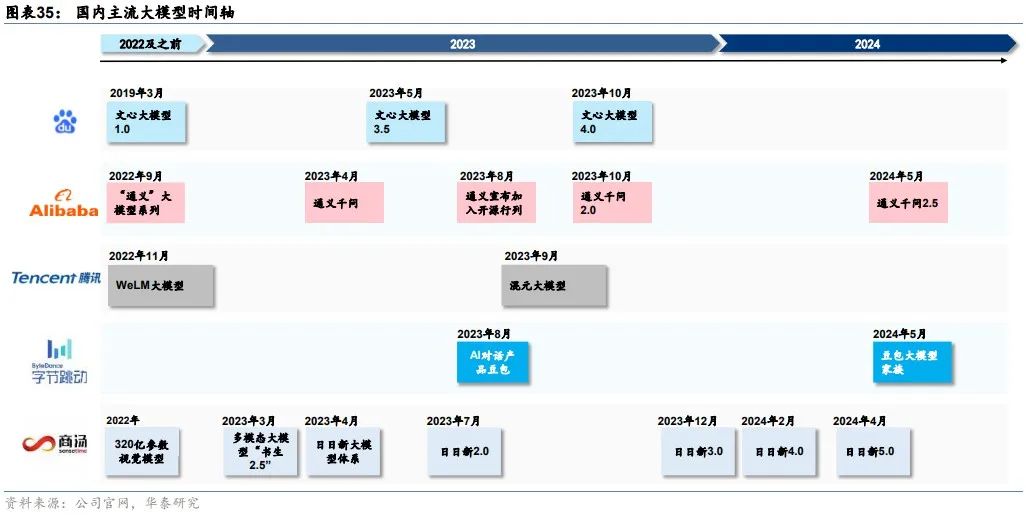
1)国内闭源大模型持续追赶OpenAI:我们看到23年中到23年底的国内主流大模型对标GPT-3.5,23年,开始对标GPT-4。例如2023年10月更新的文心4.0(Ernie 4.0)“综合水平与GPT4相比已经毫不逊色”,2024年1月更新的智谱GLM-4整体性能“逼近GPT-4”,2024年4月更新的商汤日日新5.0“综合性能全面对标 GPT-4 Turbo”。
2)国内竞争格局逐渐清晰,阵营可分为互联网头部企业、上一轮AI四小龙、创业企业。互联网头部企业中,目前百度与阿里在模型迭代与产品化上领先,字节跳动拥有领先的2C大模型应用豆包,但公开的大模型公司信息较少,腾讯的大模型迭代与产品化稍显落后。商汤是上一代“AI四小龙”公司中唯一在本轮AI 2.0浪潮中未曾掉队、持续创新领先的企业。创业公司中布局各有特色:智谱布局完整,开源、闭源模型兼具,2C/2B并重;月之暗面专注2C闭源,以长文本作为差异化竞争点;Minimax选择MoE模型,以2C社交产品切入;百川智能开源、闭源兼具,2B为主;零一万物从开源模型切入,目前开源和闭源模型兼具。
3)国内开源模型具备全球竞争力。以阿里Qwen系列、百川智能Baichuan系列、零一万物的Yi系列为代表的国内开源模型成为推动全球开源模型进步的重要力量。
百度:文心大模型持续迭代,B/C端商业化稳步推进
文心4.0综合能力“与 GPT-4相比毫不逊色”。继2023年3月发布知识增强大语言模型文心一言后,百度在2023年5月发布文心大模型3.5,2023年10月发布文心大模型4.0。相比3.5版本,4.0版本的理解、生成、逻辑、记忆四大能力都有显著提升:其中理解和生成能力的提升幅度相近,而逻辑的提升幅度达到理解的近3倍,记忆的提升幅度达到理解的2倍多。文生图功能方面,文心4.0支持多风格图片生成,一文生多图,图片清晰度提升。据百度创始人、董事长兼CEO李彦宏在百度世界2023上介绍,文心大模型4.0综合能力“与 GPT-4相比毫不逊色”。
AI重构百度移动生态。百度搜索、地图、网盘、文库等移动生态应用以AI重构。1)搜索:大模型重构的新搜索具有极致满足、推荐激发和多轮交互三个特点。2)地图:通过自然语言交互和多轮对话,升级为智能出行向导,提升用户出行和决策效率。3)百度网盘与文库:AI增加创作能力。网盘可以精准定位视频的特定帧,并总结长视频内容,提取关键信息和亮点。文库利用其庞大的资料库,辅助用户进行写作和制作PPT,成为生产力工具。4)百度GBI:用AI原生思维打造的国内第一个生成式商业智能产品。通过自然语言交互,执行数据查询与分析任务,同时支持专业知识注入,满足更复杂、专业的分析需求。
百度B/C端商业化稳步推进。根据李彦宏2024年4月在Create 2024百度AI开发者大会上的演讲,文心一言用户数已经突破2亿,API日均调用量也突破2亿,服务的客户数达到8.5万,利用千帆平台开发的AI原生应用数超过19万。
C端商业化:2023年10月推出文心一言4.0后,百度开启收费计划,开通会员后可使用文心大模型4.0,非会员则使用3.5版本。会员单月购买价格为59.9元/月,连续包月价格为49.9元/月,文心一言+文心一格联合会员价格为99元/月。文心一言会员可享受文心大模型4.0、文生图能力全面升级、网页端高阶插件、App端单月赠送600灵感值等权益,文心一格会员可享受极速生成多尺寸高清图像、创作海报和艺术字、AI编辑改图修图等权益。
B端落地:三星Galaxy S24 5G系列、荣耀Magic 8.0均集成了文心API,汽车之家使用文心API支持其AIGC应用程序。根据百度4Q23业绩会,百度通过广告技术改进和帮助企业构建个性化模型,在4Q23已经实现数亿元人民币的收入,百度预计2024年来自AI大模型的增量收入将增长至数十亿元人民币,主要来源包括广告和人工智能云业务。
阿里巴巴:通义大模型开源闭源兼具,落地行业广泛
通义千问2.5中文性能追平 GPT-4 Turbo。通义千问自2023年4月问世以来,2023年10月发布性能超越GPT-3.5的通义千问2.0,2024年5月发布通义千问2.5。在中文语境下,2.5版文本理解、文本生成、知识问答&生活建议、闲聊&对话,以及安全风险等多项能力上赶超GPT-4。
通义践行“全模态、全尺寸”开源。2023年8月,通义宣布加入开源行列,已陆续推出十多款开源模型。根据阿里云公众号,截至2024年5月,通义开源模型下载量已经超过700万。大语言模型方面,通义开源了参数规模横跨5亿到1100亿的八款模型:小尺寸模型参数量涵盖0.5B、1.8B、4B、7B、14B,可便捷地在手机、PC等端侧设备部署;大尺寸模型如72B、110B能够支持企业级和科研级的应用;中等尺寸模型如32B则在性能、效率和内存占用之间找到最具性价比的平衡点。此外,通义还开源了视觉理解模型Qwen-VL、音频理解模型Qwen-Audio、代码模型CodeQwen1.5-7B、混合专家模型Qwen1.5-MoE。
面向B端客户,通义通过阿里云服务企业超过9万,与诸多行业头部客户达成合作。根据阿里云公众号,截至2024年5月,通义通过阿里云服务企业超过9万、通过钉钉服务企业超过220万,现已落地PC、手机、汽车、航空、天文、矿业、教育、医疗、餐饮、游戏、文旅等领域。
面向C端用户,通义千问APP升级为通义APP,集成文生图、智能编码、文档解析、音视频理解、视觉生成等全栈能力,打造用户的全能AI助手。
腾讯:混元大模型赋能自身业务生态实现智能化升级
混元已经接入腾讯多个核心产品和业务,赋能业务降本增效。2023年9月,腾讯上线混元大模型。混元已升级为万亿级别参数的MOE架构模型。截至2023年9月,包括腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器在内的超过50个核心业务和产品接入混元大模型;2023年10月超过180个内部业务接入混元;2024年4月,腾讯所有协作SaaS产品超过400个应用全面接入混元,包括企业微信、腾讯会议、腾讯文档、腾讯乐享、腾讯云AI代码助手、腾讯电子签、腾讯问卷等等。
字节跳动:豆包大模型赋能内部业务,对话助手“豆包”用户数量居前
字节跳动在2023年并未对外官宣其大模型,在2024年5月火山引擎原动力大会上首次公开发布。字节豆包大模型家族涵盖9 个模型,主要包括通用模型 pro、通用模型 lite、语音识别模型、语音合成模型、文生图模型等等。字节跳动并未说明模型参数量、数据和语料,而是直接针对应用场景进行垂直细分。豆包大模型在2023年完成自研,已接入字节内部50余个业务,包括抖音、飞书等,日均处理1200亿Tokens文本,生成3000万张图片。
2C产品方面,字节跳动基于豆包大模型打造了AI对话助手“豆包”、AI应用开发平台“扣子”、互动娱乐应用“猫箱”以及AI创作工具星绘、即梦等。
2B方面,火山引擎也与智能终端、汽车、金融、消费等行业的众多企业已经展开了合作,包括OPPO、vivo、小米、荣耀、三星、华硕、招行、捷途、吉利、北汽、智己、广汽、东风本田、海底捞、飞鹤等。
商汤:“云、边、端”全栈大模型,5.0版本对标GPT-4 turbo
商汤日日新5.0综合性能对标GPT-4 turbo。2023年4月,商汤正式发布“日日新SenseNova”大模型体系,实现CV、NLP、多模态等大模型的全面布局。2024年4月,商汤日日新SenseNova升级至5.0版本,具备更强的知识、数学、推理及代码能力,综合性能全面对标 GPT-4 Turbo。日日新5.0能力提升主要得益三个方面:1)采用MoE架构,激活少量参数就能完成推理。且推理时上下文窗口达到 200K 左右。2)基于超过10TB tokens训练、覆盖数千亿量级的逻辑型合成思维链数据。3)商汤AI大装置SenseCore算力设施与算法设计的联合调优。
商汤推出“云、边、端”全栈大模型产品矩阵。1)云端模型即商汤最领先的基础模型系列。2)在边缘侧,商汤面向金融、医疗、政务、代码四个行业推出商汤企业级大模型一体机。一体机同时支持千亿模型加速和知识检索硬件加速,实现本地化部署,相比行业同类产品,千亿大模型推理成本可节约80%;检索大大加速,CPU工作负载减少50%,端到端延迟减少1.5秒。3)端侧模型方面,SenseChat-Lite 1.8B全面领先所有开源2B同级别模型,甚至在大部分测试中跨级击败了Llama2-7B、13B模型。日日新 5.0 端侧大模型可在中端性能手机上达到18.3字/秒的推理速度,在高端旗舰手机上达到78.3字/秒,高于人眼20字/秒的阅读速度。