5.4 召回集读取服务
学习目标
- 目标
- 无
- 应用
- 无
5.4.1 召回集读取服务
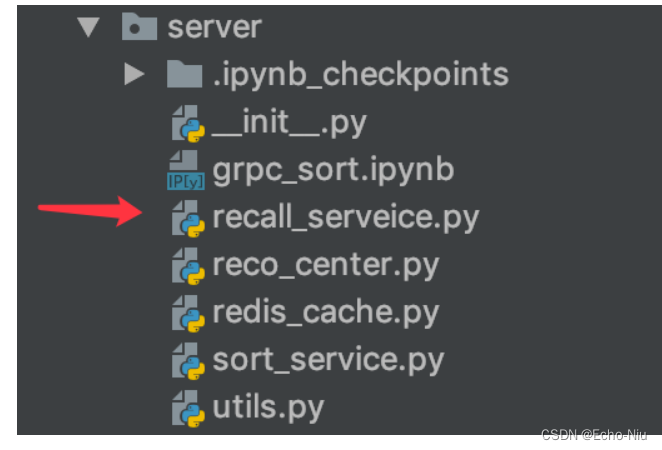
- 添加一个server的目录
- 会添加推荐中心,召回读取服务,模型排序服务,缓存服务
- 这里先添加一个召回集的结果读取服务recall_service.py
- utils.py中装有自己封装的hbase数据库读取存储工具
5.4.1 Hbase读取存储等工具类封装
为什么封装?
在写happybase代码的时候会有过多的重复代码,将这些封装成简便的工具,减少代码冗余
- 包含方法
- get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
- 获取具体表中的键、列族中的行数据
- get_table_cells(self, table_name, key_format, column_format=None, timestamp=None, include_timestamp=False):
- 获取Hbase中多个版本数据
- get_table_put(self, table_name, key_format, column_format, data, timestamp=None):
- 存储数据到Hbase当中
- get_table_delete(self, table_name, key_format, column_format):
- 删除Hbase中的数据
- get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
class HBaseUtils(object):
"""HBase数据库读取工具类
"""
def __init__(self, connection):
self.pool = connection
def get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
"""
获取HBase数据库中的行记录数据
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param include_timestamp: 是否包含时间戳
:return: 返回数据库结果data
"""
if not isinstance(key_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
if column_format:
data = table.row(row=key_format, columns=[column_format], include_timestamp=include_timestamp)
else:
data = table.row(row=key_format)
conn.close()
if column_format:
return data[column_format]
else:
# {b'als:5': (b'[141440]', 1555519429582)}
# {b'als:5': '[141440]'}
return data
def get_table_cells(self, table_name, key_format, column_format=None, timestamp=None, include_timestamp=False):
"""
获取HBase数据库中多个版本数据
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param timestamp: 指定小于该时间戳的数据
:param include_timestamp: 是否包含时间戳
:return: 返回数据库结果data
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
data = table.cells(row=key_format, column=column_format, timestamp=timestamp,
include_timestamp=include_timestamp)
conn.close()
# [(,), ()]
return data
def get_table_put(self, table_name, key_format, column_format, data, timestamp=None):
"""
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param data: 插入的数据
:param timestamp: 指定拆入数据的时间戳
:return: None
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes) or not isinstance(data, bytes):
raise KeyError("key_format or column or data type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
table.put(key_format, {column_format: data}, timestamp=timestamp)
conn.close()
return None
def get_table_delete(self, table_name, key_format, column_format):
"""
删除列族中的内容
:param table_name: 表名称
:param key_format: key
:param column_format: 列格式
:return:
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
table.delete(row=key_format, columns=[column_format])
conn.close()
return None
5.4.2 多路召回结果读取
-
目的:读取离线和在线存储的召回结果
- hbase的存储:cb_recall, als, content, online
-
步骤:
- 1、初始化redis,hbase相关工具
- 2、在线画像召回,离线画像召回,离线协同召回数据的读取
- 3、redis新文章和热门文章结果读取
- 4、相似文章读取接口
初始化redis,hbase相关工具
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from server import redis_client
from server import pool
import logging
from datetime import datetime
from server.utils import HBaseUtils
logger = logging.getLogger('recommend')
class ReadRecall(object):
"""读取召回集的结果
"""
def __init__(self):
self.client = redis_client
self.hbu = HBaseUtils(pool)
并且添加了获取结果打印日志设置
# 实施推荐日志
# 离线处理更新打印日志
trace_file_handler = logging.FileHandler(
os.path.join(logging_file_dir, 'recommend.log')
)
trace_file_handler.setFormatter(logging.Formatter('%(message)s'))
log_trace = logging.getLogger('recommend')
log_trace.addHandler(trace_file_handler)
log_trace.setLevel(logging.INFO)
在init文件中添加相关初始化数据库变量
import redis
import happybase
from setting.default import DefaultConfig
from pyspark import SparkConf
from pyspark.sql import SparkSession
pool = happybase.ConnectionPool(size=10, host="hadoop-master", port=9090)
redis_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=10,
decode_responses=True)
# 缓存在8号当中
cache_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=8,
decode_responses=True)
2、在线画像召回,离线画像召回,离线协同召回数据的读取
- 读取用户的指定列族的召回数据,并且读取之后要删除原来的推荐召回结果'cb_recall'
def read_hbase_recall_data(self, table_name, key_format, column_format):
"""
读取cb_recall当中的推荐数据
读取的时候可以选择列族进行读取als, online, content
:return:
"""
recall_list = []
try:
data = self.hbu.get_table_cells(table_name, key_format, column_format)
# data是多个版本的推荐结果[[],[],[],]
for _ in data:
recall_list = list(set(recall_list).union(set(eval(_))))
# self.hbu.get_table_delete(table_name, key_format, column_format)
except Exception as e:
logger.warning("{} WARN read {} recall exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
table_name, e))
return recall_list
测试:
if __name__ == '__main__':
rr = ReadRecall()
# 召回结果的读取封装
# print(rr.read_hbase_recall_data('cb_recall', b'recall:user:1114864874141253632', b'online:18'))
3、redis新文章和热门文章结果读取
def read_redis_new_article(self, channel_id):
"""
读取新闻章召回结果
:param channel_id: 提供频道
:return:
"""
logger.warning("{} WARN read channel {} redis new article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
channel_id))
_key = "ch:{}:new".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except Exception as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return list(map(int, res))
热门文章读取:热门文章记录了很多,可以选取前K个
def read_redis_hot_article(self, channel_id):
"""
读取新闻章召回结果
:param channel_id: 提供频道
:return:
"""
logger.warning("{} WARN read channel {} redis hot article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:hot".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except Exception as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
# 由于每个频道的热门文章有很多,因为保留文章点击次数
res = list(map(int, res))
if len(res) > self.hot_num:
res = res[:self.hot_num]
return res
测试:
print(rr.read_redis_new_article(18))
print(rr.read_redis_hot_article(18))
4、相似文章读取接口
最后相似文章读取接口代码
- 会有接口获取固定的文章数量(用在黑马头条APP中的猜你喜欢接口)
def read_hbase_article_similar(self, table_name, key_format, article_num):
"""获取文章相似结果
:param article_id: 文章id
:param article_num: 文章数量
:return:
"""
# 第一种表结构方式测试:
# create 'article_similar', 'similar'
# put 'article_similar', '1', 'similar:1', 0.2
# put 'article_similar', '1', 'similar:2', 0.34
try:
_dic = self.hbu.get_table_row(table_name, key_format)
res = []
_srt = sorted(_dic.items(), key=lambda obj: obj[1], reverse=True)
if len(_srt) > article_num:
_srt = _srt[:article_num]
for _ in _srt:
res.append(int(_[0].decode().split(':')[1]))
except Exception as e:
logger.error(
"{} ERROR read similar article exception: {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return res
完整代码:
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from server import redis_client
from server import pool
import logging
from datetime import datetime
from abtest.utils import HBaseUtils
logger = logging.getLogger('recommend')
class ReadRecall(object):
"""读取召回集的结果
"""
def __init__(self):
self.client = redis_client
self.hbu = HBaseUtils(pool)
def read_hbase_recall_data(self, table_name, key_format, column_format):
"""获取指定用户的对应频道的召回结果,在线画像召回,离线画像召回,离线协同召回
:return:
"""
# 获取family对应的值
# 数据库中的键都是bytes类型,所以需要进行编码相加
# 读取召回结果多个版本合并
recall_list = []
try:
data = self.hbu.get_table_cells(table_name, key_format, column_format)
for _ in data:
recall_list = list(set(recall_list).union(set(eval(_))))
# 读取所有这个用户的在线推荐的版本,清空该频道的数据
# self.hbu.get_table_delete(table_name, key_format, column_format)
except Exception as e:
logger.warning(
"{} WARN read recall data exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
return recall_list
def read_redis_new_data(self, channel_id):
"""获取redis新文章结果
:param channel_id:
:return:
"""
# format结果
logger.info("{} INFO read channel:{} new recommend data".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:new".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except redis.exceptions.ResponseError as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return list(map(int, res))
def read_redis_hot_data(self, channel_id):
"""获取redis热门文章结果
:param channel_id:
:return:
"""
# format结果
logger.info("{} INFO read channel:{} hot recommend data".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:hot".format(channel_id)
try:
_res = self.client.zrevrange(_key, 0, -1)
except redis.exceptions.ResponseError as e:
logger.warning("{} WARN read hot article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
_res = []
# 每次返回前50热门文章
res = list(map(int, _res))
if len(res) > 50:
res = res[:50]
return res
def read_hbase_article_similar(self, table_name, key_format, article_num):
"""获取文章相似结果
:param article_id: 文章id
:param article_num: 文章数量
:return:
"""
# 第一种表结构方式测试:
# create 'article_similar', 'similar'
# put 'article_similar', '1', 'similar:1', 0.2
# put 'article_similar', '1', 'similar:2', 0.34
try:
_dic = self.hbu.get_table_row(table_name, key_format)
res = []
_srt = sorted(_dic.items(), key=lambda obj: obj[1], reverse=True)
if len(_srt) > article_num:
_srt = _srt[:article_num]
for _ in _srt:
res.append(int(_[0].decode().split(':')[1]))
except Exception as e:
logger.error("{} ERROR read similar article exception: {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return res
if __name__ == '__main__':
rr = ReadRecall()
print(rr.read_hbase_article_similar('article_similar', b'13342', 10))
print(rr.read_hbase_recall_data('cb_recall', b'recall:user:1115629498121846784', b'als:18'))
# rr = ReadRecall()
# print(rr.read_redis_new_data(18))





![为什么 Go 不支持 []T 转换为 []interface](https://img-blog.csdnimg.cn/img_convert/53fc9d125f199fe3ddd1cf862fce5cd0.png)