Applied Spatial Statistics(七):Python 中的空间回归
本笔记本演示了如何使用 pysal 的 spreg 库拟合空间滞后模型和空间误差模型。
- OLS
- 空间误差模型
- 空间滞后模型
- 三种模型的比较
- 探索滞后模型中的直接和间接影响
import numpy as np
import pandas as pd
import geopandas as gpd
import seaborn as sns
import matplotlib.pyplot as plt
from libpysal.weights import Queen
from splot.esda import plot_moran
from esda.moran import Moran
import spreg
1.数据
在此笔记本中,我将使用 2020 年美国总统选举数据集进行演示。
voting 数据框包含县级投票给民主党的人数百分比(编码为 new_pct_dem)以及该县的一些社会经济变量。该数据集仅包含美国本土 48 个州的统计数据。
voting = pd.read_csv('https://raw.github.com/Ziqi-Li/gis5122/master/data/voting_2020.csv')
voting[['median_income']] = voting[['median_income']]/10000
voting.head()
| county_id | state | county | NAME | proj_X | proj_Y | total_pop | new_pct_dem | sex_ratio | pct_black | ... | median_income | pct_65_over | pct_age_18_29 | gini | pct_manuf | ln_pop_den | pct_3rd_party | turn_out | pct_fb | pct_uninsured | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17051 | 17 | 51 | Fayette County, Illinois | 597979.5531 | 1796861.993 | 21565 | 18.445122 | 113.6 | 4.7 | ... | 4.6650 | 18.8 | 14.899142 | 0.4373 | 14.9 | 3.392715 | 1.923652 | 58.930984 | 1.3 | 8.2 |
| 1 | 17107 | 17 | 107 | Logan County, Illinois | 559814.6766 | 1920479.975 | 29003 | 29.420030 | 97.2 | 6.9 | ... | 5.7308 | 18.0 | 17.256836 | 0.4201 | 12.4 | 3.847224 | 2.332850 | 56.631552 | 1.6 | 4.5 |
| 2 | 17165 | 17 | 165 | Saline County, Illinois | 650278.3579 | 1660709.808 | 23994 | 25.601911 | 96.9 | 2.6 | ... | 4.4090 | 19.9 | 13.586730 | 0.4692 | 8.7 | 4.128654 | 1.778139 | 59.147937 | 1.0 | 4.2 |
| 3 | 17097 | 17 | 97 | Lake County, Illinois | 654010.9262 | 2174576.605 | 701473 | 62.275888 | 99.8 | 6.8 | ... | 8.9427 | 13.7 | 15.823132 | 0.4847 | 16.3 | 7.308201 | 1.954177 | 71.151975 | 18.7 | 6.8 |
| 4 | 17127 | 17 | 127 | Massac County, Illinois | 640398.9863 | 1599902.491 | 14219 | 25.626118 | 89.5 | 5.8 | ... | 4.7481 | 20.8 | 12.370772 | 0.4097 | 7.4 | 4.067788 | 1.396443 | 62.281425 | 1.0 | 5.4 |
5 rows × 22 columns
然后我们阅读了美国的县边界文件。
shp = gpd.read_file("https://raw.github.com/Ziqi-Li/gis5122/master/data/us_counties.geojson")
#Merge the shapefile with the voting data by the common county_id
shp_voting = shp.merge(voting, on ="county_id")
#Dissolve the counties to obtain boundary of states, used for mapping
state = shp_voting.dissolve(by='STATEFP').geometry.boundary
选择本练习中要使用的变量,我从列表中选择了 6 个预测因子。
variable_names = ['sex_ratio', 'pct_black', 'pct_hisp',
'pct_bach', 'median_income','ln_pop_den']
y = shp_voting[['new_pct_dem']].values
X = shp_voting[variable_names].values
2.OLS model (baseline)
这里我演示如何使用 spring 来拟合 OLS 模型。当然你也可以使用 statsmodels。
#In the spreg.OLS() you need to specify the y and X, also variable names (optional)
ols = spreg.OLS(y, X, name_y='new_pct_dem', name_x=variable_names)
print(ols.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : None
Dependent Variable : new_pct_dem Number of Observations: 3103
Mean dependent var : 33.7616 Number of Variables : 7
S.D. dependent var : 16.2257 Degrees of Freedom : 3096
R-squared : 0.6091
Adjusted R-squared : 0.6083
Sum squared residual: 319249 F-statistic : 803.9833
Sigma-square : 103.117 Prob(F-statistic) : 0
S.E. of regression : 10.155 Log likelihood : -11592.001
Sigma-square ML : 102.884 Akaike info criterion : 23198.003
S.E of regression ML: 10.1432 Schwarz criterion : 23240.284
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 5.83676 1.96534 2.96984 0.00300
sex_ratio 0.00613 0.01754 0.34970 0.72659
pct_black 0.48310 0.01401 34.47681 0.00000
pct_hisp 0.23952 0.01329 18.02612 0.00000
pct_bach 0.97537 0.02854 34.17057 0.00000
median_income -1.66008 0.19755 -8.40329 0.00000
ln_pop_den 2.13283 0.12925 16.50160 0.00000
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 33.073
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 1166.636 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 6 268.617 0.0000
Koenker-Bassett test 6 118.745 0.0000
================================ END OF REPORT =====================================
我们可以与 statsmodels 进行比较,结果相同
查看 OLS 残差图
ols.u
array([[ 0.98102642],
[-7.61122909],
[ 3.44911401],
...,
[-3.82424613],
[-0.7422498 ],
[-1.11507546]])
from matplotlib import colors
#For creating a discrete color classification
norm = colors.BoundaryNorm([-20, -10, -5, 0, 5, 10, 20],ncolors=256)
ax = shp_voting.plot(column=ols.u.reshape(-1),legend=True,figsize=(15,8), norm=norm, linewidth=0.0)
state.plot(ax=ax,linewidth=0.3,edgecolor="black")
plt.title("Map of residuals of the OLS model",fontsize=15)
Text(0.5, 1.0, 'Map of residuals of the OLS model')
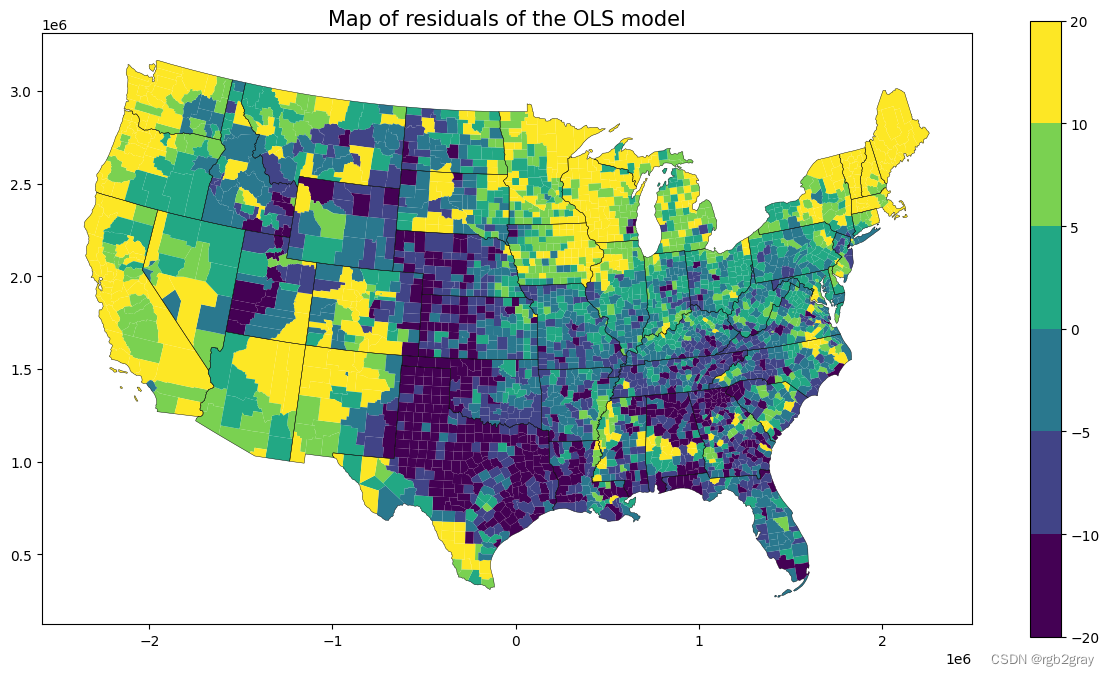
从 OLS 残差图中,我们可以看到空间自相关性很强,高/低残差聚集在一起。这强烈表明我们的模型缺少空间结构,并且违反了 OLS 的独立性假设。
然后让我们通过计算残差的 Moran’s I 来更定量地评估空间自相关性。
#Here we use the Queen contiguity
w = Queen.from_dataframe(shp_voting)
#row standardization
w.transform = 'R'
#The warning is saying there are two counties without neighbors, lets don't worry about this for now.
<ipython-input-14-9c7ca81e50b6>:2: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = Queen.from_dataframe(shp_voting)
('WARNING: ', 2441, ' is an island (no neighbors)')
('WARNING: ', 2701, ' is an island (no neighbors)')
/usr/local/lib/python3.10/dist-packages/libpysal/weights/weights.py:224: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
There are 2 islands with ids: 2441, 2701.
warnings.warn(message)
#Here, lets calculate the Moran's I value, and plot it.
#ols.u is the residuals from the OLS model
ols_moran = Moran(ols.u, w, permutations = 199) #199 permutations
plot_moran(ols_moran, figsize=(10,4))
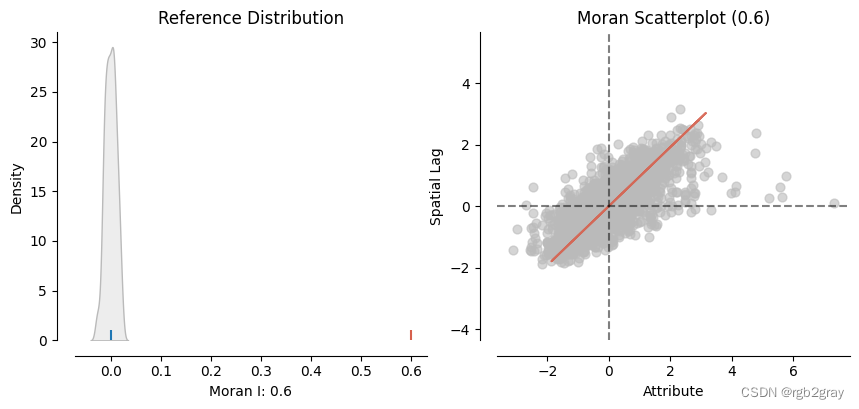
我们发现 Moran’s I 值等于 0.6,这让我们确信 OLS 残差图上确实存在很强的空间模式。
现在有两个选择:我们可以使用 滞后模型,或者我们可以使用 误差模型。
一个便利之处在于,如果您将权重矩阵传递给 OLS 函数,同时指定 spat_diag=True,那么您将获得一些额外的空间诊断,可以帮助您做出决定。如果您指定 moran=True,这还包括残差的 Moran’s I。
ols = spreg.OLS(y, X, w=w, spat_diag=True, moran=True,
name_y='pct_dem', name_x=variable_names)
print(ols.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : unknown
Dependent Variable : pct_dem Number of Observations: 3103
Mean dependent var : 33.7616 Number of Variables : 7
S.D. dependent var : 16.2257 Degrees of Freedom : 3096
R-squared : 0.6091
Adjusted R-squared : 0.6083
Sum squared residual: 319249 F-statistic : 803.9833
Sigma-square : 103.117 Prob(F-statistic) : 0
S.E. of regression : 10.155 Log likelihood : -11592.001
Sigma-square ML : 102.884 Akaike info criterion : 23198.003
S.E of regression ML: 10.1432 Schwarz criterion : 23240.284
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 5.83676 1.96534 2.96984 0.00300
sex_ratio 0.00613 0.01754 0.34970 0.72659
pct_black 0.48310 0.01401 34.47681 0.00000
pct_hisp 0.23952 0.01329 18.02612 0.00000
pct_bach 0.97537 0.02854 34.17057 0.00000
median_income -1.66008 0.19755 -8.40329 0.00000
ln_pop_den 2.13283 0.12925 16.50160 0.00000
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 33.073
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 1166.636 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 6 268.617 0.0000
Koenker-Bassett test 6 118.745 0.0000
DIAGNOSTICS FOR SPATIAL DEPENDENCE
TEST MI/DF VALUE PROB
Moran's I (error) 0.6000 56.164 0.0000
Lagrange Multiplier (lag) 1 1952.063 0.0000
Robust LM (lag) 1 18.792 0.0000
Lagrange Multiplier (error) 1 3119.345 0.0000
Robust LM (error) 1 1186.074 0.0000
Lagrange Multiplier (SARMA) 2 3138.137 0.0000
================================ END OF REPORT =====================================
从 L-M 检验中,我们可以预期误差模型比滞后模型更为合适(比较稳健得分:1186 比 18)。
3.Spatial Error Model (SEM)
现在让我们使用“spreg.ML_Error()”拟合空间错误模型,其中您需要指定 y、X 和权重矩阵 w。
sem = spreg.ML_Error(y, X, w=w, name_x=variable_names, name_y='new_pct_dem')
print(sem.summary)
/usr/local/lib/python3.10/dist-packages/scipy/optimize/_minimize.py:913: RuntimeWarning: Method 'bounded' does not support relative tolerance in x; defaulting to absolute tolerance.
warn("Method 'bounded' does not support relative tolerance in x; "
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ML SPATIAL ERROR (METHOD = full)
---------------------------------------------------
Data set : unknown
Weights matrix : unknown
Dependent Variable : new_pct_dem Number of Observations: 3103
Mean dependent var : 33.7616 Number of Variables : 7
S.D. dependent var : 16.2257 Degrees of Freedom : 3096
Pseudo R-squared : 0.5167
Log likelihood : -10170.5905
Sigma-square ML : 33.4938 Akaike info criterion : 20355.181
S.E of regression : 5.7874 Schwarz criterion : 20397.462
------------------------------------------------------------------------------------
Variable Coefficient Std.Error z-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 19.00473 1.49728 12.69280 0.00000
sex_ratio -0.04056 0.00988 -4.10353 0.00004
pct_black 0.74856 0.01685 44.43261 0.00000
pct_hisp 0.31866 0.01734 18.37383 0.00000
pct_bach 0.72854 0.02000 36.42952 0.00000
median_income -2.42279 0.15714 -15.41832 0.00000
ln_pop_den 1.83430 0.13375 13.71399 0.00000
lambda 0.86984 0.00994 87.51130 0.00000
------------------------------------------------------------------------------------
================================ END OF REPORT =====================================
空间滞后误差项的 lambda(或其他使用 rho 的软件或符号)系数非常显著,并且其幅度相当大,这表明残差中存在很强的空间自相关性,这被滞后误差项捕获。
请注意,sem 的 sem.e_filtered 属性应该是 iid 误差。而 sem.u 是自回归误差 + iid 误差。现在让我们再次查看残差的 Moran’s I。
sem.e_filtered
array([[-2.82249844],
[-2.93425648],
[ 1.76293602],
...,
[ 0.58894001],
[ 4.25853052],
[-4.82251595]])
sem_moran = Moran(sem.e_filtered, w, permutations = 199) #199 permutations
plot_moran(sem_moran, zstandard=True, figsize=(10,4))
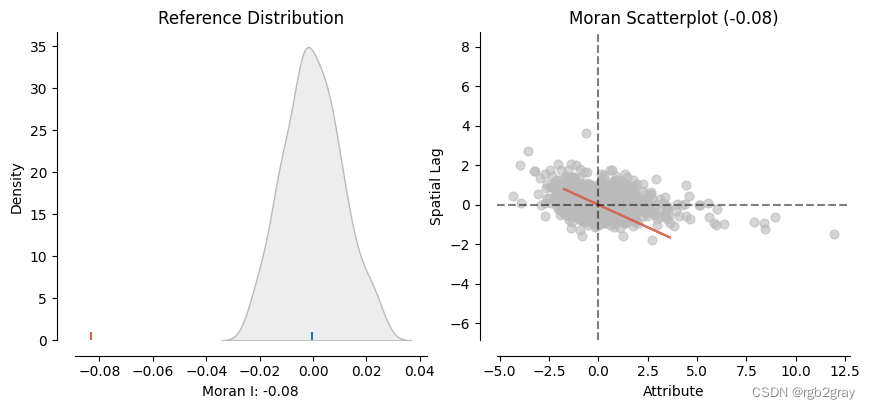
非常低的 Moran’s I -> 随机
ax = shp_voting.plot(column=sem.e_filtered.reshape(-1),legend=True,figsize=(15,8), norm=norm, linewidth=0.0)
state.plot(ax=ax,linewidth=0.3,edgecolor="black")
plt.title("Map of filtered residuals of the SEM model",fontsize=15)
Text(0.5, 1.0, 'Map of filtered residuals of the SEM model')
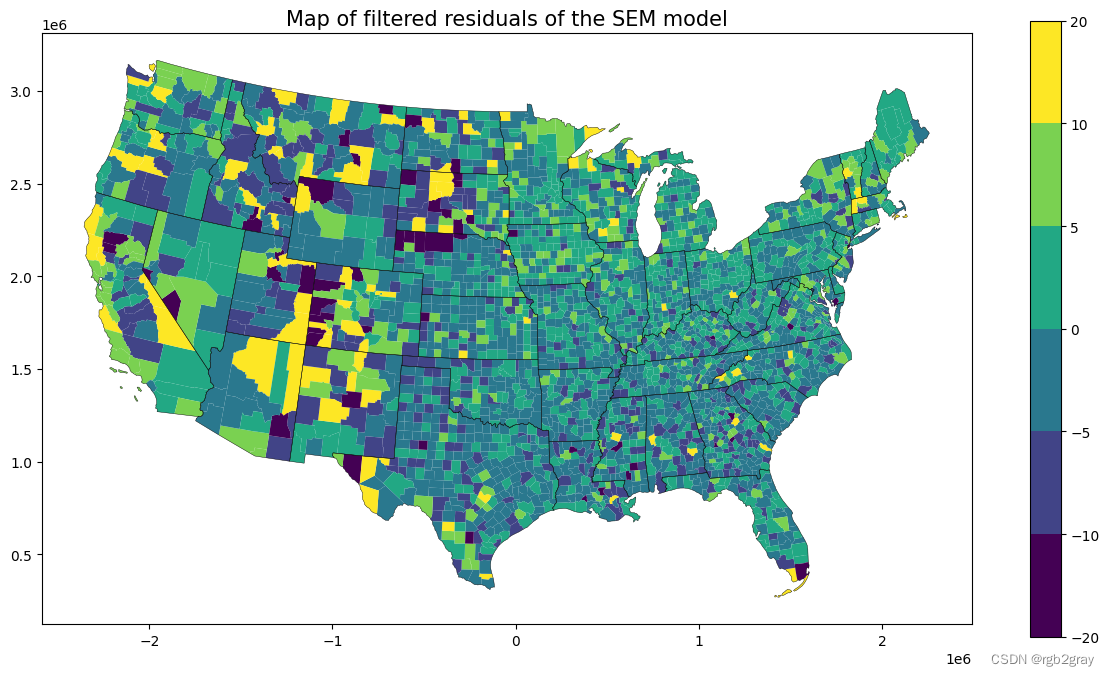
随机模式!太棒了!
4.Spatial Lag Model
类似地,让我们将此重复到空间滞后模型
slm = spreg.ML_Lag(y, X, w=w, name_y='new_pct_dem', name_x=variable_names)
print(slm.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: MAXIMUM LIKELIHOOD SPATIAL LAG (METHOD = FULL)
-----------------------------------------------------------------
Data set : unknown
Weights matrix : unknown
Dependent Variable : new_pct_dem Number of Observations: 3103
Mean dependent var : 33.7616 Number of Variables : 8
S.D. dependent var : 16.2257 Degrees of Freedom : 3095
Pseudo R-squared : 0.7744
Spatial Pseudo R-squared: 0.5591
Log likelihood : -10853.5647
Sigma-square ML : 59.4991 Akaike info criterion : 21723.129
S.E of regression : 7.7136 Schwarz criterion : 21771.450
------------------------------------------------------------------------------------
Variable Coefficient Std.Error z-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 1.07097 1.50321 0.71245 0.47618
sex_ratio 0.01044 0.01333 0.78274 0.43378
pct_black 0.27765 0.01295 21.43381 0.00000
pct_hisp 0.16619 0.01060 15.68552 0.00000
pct_bach 0.83467 0.02200 37.93947 0.00000
median_income -2.99112 0.15043 -19.88429 0.00000
ln_pop_den 1.47061 0.10082 14.58655 0.00000
W_new_pct_dem 0.58112 0.01342 43.31362 0.00000
------------------------------------------------------------------------------------
================================ END OF REPORT =====================================
空间滞后项“W_new_pct_dem”的 rho 系数显著,且幅度很大,这表明因变量具有很强的空间溢出效应。
slm_moran = Moran(slm.u, w, permutations = 199) #199 permutations
plot_moran(slm_moran, zstandard=True, figsize=(10,4))
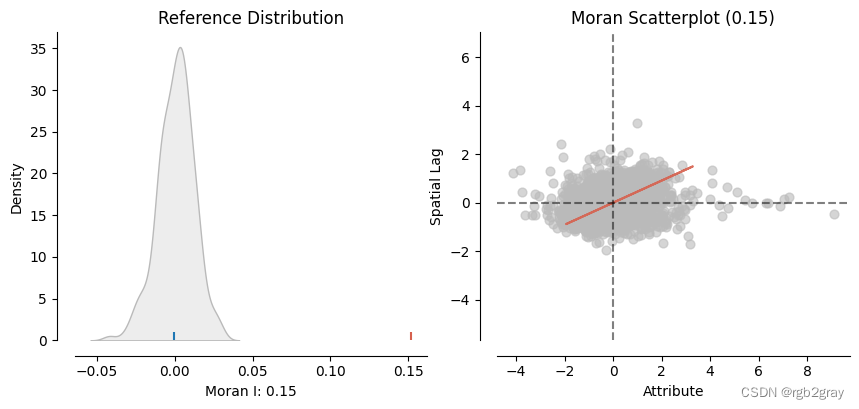
ax = shp_voting.plot(column=slm.u.reshape(-1),legend=True,figsize=(15,8), norm=norm, linewidth=0.0)
state.plot(ax=ax,linewidth=0.3,edgecolor="black")
plt.title("Map of residuals of the spatial lag model",fontsize=15)
Text(0.5, 1.0, 'Map of residuals of the spatial lag model')
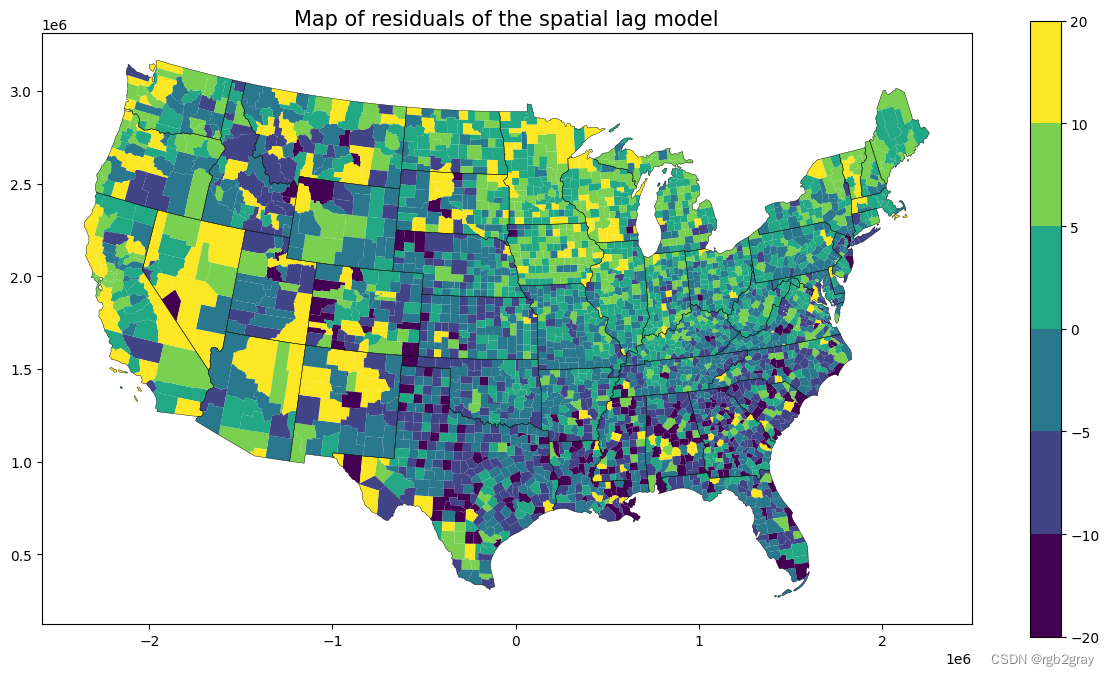
5.滞后、误差和 OLS 模型的交叉比较。
总体而言,我们看到尽管有一些变化(例如,在 SEM 模型中,%black 的影响更大),但估计值是一致的。OLS 模型不可靠,因为我们知道假设被违反了。在滞后模型中,即使我们考虑了邻近投票偏好,残差仍然显示出一些弱自相关性。而在误差模型中,我们确实观察到了随机残差。
所以如果我需要做出决定,我会使用误差模型。这也得到了 LM 测试的证据以及误差模型具有最低 AIC 值的支持。
| Predictor | OLS Estimates | SLM Estimates | SEM Estimates |
|---|---|---|---|
| CONSTANT | 5.83* | 1.07 | 19.00* |
| sex_ratio | 0.00 | 0.01 | -0.04* |
| pct_black | 0.48* | 0.27* | 0.74* |
| pct_hisp | 0.23* | 0.16* | 0.31* |
| pct_bach | 0.97* | 0.83* | 0.72* |
| median_income | -1.66* | -2.99* | -2.42* |
| ln_pop_den | 2.13* | 1.47* | 1.83* |
| lambda | NA | 0.58* | 0.86* |
| AIC | 23198.00 | 21723.12 | 20355.18 |
| Moran’s I of residuals | 0.60 | 0.15 | -0.08 |
6.更多关于 SLM 模型的内容:间接影响的检查。
场景:如果莱昂的 bach 百分比增加 1%,会怎样?附近县的 dem 百分比会发生什么变化?
步骤:
- 使用 w.full() 获取完整的 n x n 矩阵
- 计算 (I-pW)^-1*beta(此处的估计值是 SLM 模型中的 bach 百分比,因此为 0.83),现在您获得了完整的 n x n 变化交互。
- 找到任何感兴趣的县的行索引。
- 现在您可以选择该县的列并检查这将如何影响其他县。
#1.
w.full()[0]
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
np.identity(3103)
array([[1., 0., 0., ..., 0., 0., 0.],
[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.],
[0., 0., 0., ..., 0., 0., 1.]])
#2.
effects = np.linalg.inv(np.identity(3103) - 0.58*w.full()[0])*0.83 #n=3103, rho=0.58, est_pct_bach = 0.83
effects
array([[8.92141250e-01, 1.32877317e-03, 1.52996497e-14, ...,
3.14050249e-31, 5.12287114e-06, 1.79564935e-10],
[9.49123691e-04, 8.98379566e-01, 1.43986921e-13, ...,
4.16193409e-29, 1.14493906e-03, 1.32924287e-10],
[1.27497081e-14, 1.67984741e-13, 9.03375896e-01, ...,
8.63302503e-23, 5.33348558e-13, 2.63149009e-21],
...,
[2.61708541e-31, 4.85558978e-29, 8.63302503e-23, ...,
8.88070682e-01, 8.55288372e-27, 1.32652812e-25],
[3.65919367e-06, 1.14493906e-03, 4.57155907e-13, ...,
7.33104319e-27, 8.95542764e-01, 4.10759600e-10],
[1.12228084e-10, 1.16308751e-10, 1.97361756e-21, ...,
9.94896087e-26, 3.59414650e-10, 9.05420698e-01]])
#3. find the row index for Leon, which is 67.
shp_voting[shp_voting['NAME_x'] == "Leon"]
| GEOID | STATEFP | NAME_x | county_id | geometry | state | county | NAME_y | proj_X | proj_Y | ... | median_income | pct_65_over | pct_age_18_29 | gini | pct_manuf | ln_pop_den | pct_3rd_party | turn_out | pct_fb | pct_uninsured | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 67 | 12073 | 12 | Leon | 12073 | POLYGON ((1080730.82089 870592.41110, 1086551.... | 12 | 73 | Leon County, Florida | 1.120705e+06 | 889449.6751 | ... | 5.3106 | 12.9 | 30.040722 | 0.4896 | 2.0 | 6.023568 | 1.202364 | 71.910474 | 6.8 | 8.1 |
| 1050 | 48289 | 48 | Leon | 48289 | POLYGON ((-30255.42040 920246.79226, -30598.62... | 48 | 289 | Leon County, Texas | 3.831304e+02 | 913423.2253 | ... | 4.3045 | 24.2 | 12.342525 | 0.5271 | 5.7 | 2.767577 | 0.899446 | 68.074417 | 5.2 | 17.0 |
2 rows × 26 columns
#Total effects for Leon can be obtained in the diagnoal of the full effects matrix.
effects[67,67]
0.903899945968712
这表明,大学毕业生人数每增加 1%,民主党的投票份额将增加约 0.90%(直接 + 间接)。请注意,这大于滞后模型的系数(即 0.83),该系数仅捕捉直接影响。
间接影响是其自身与邻居之间的空间相互作用的结果,约为 0.07%(0.90 - 0.83)
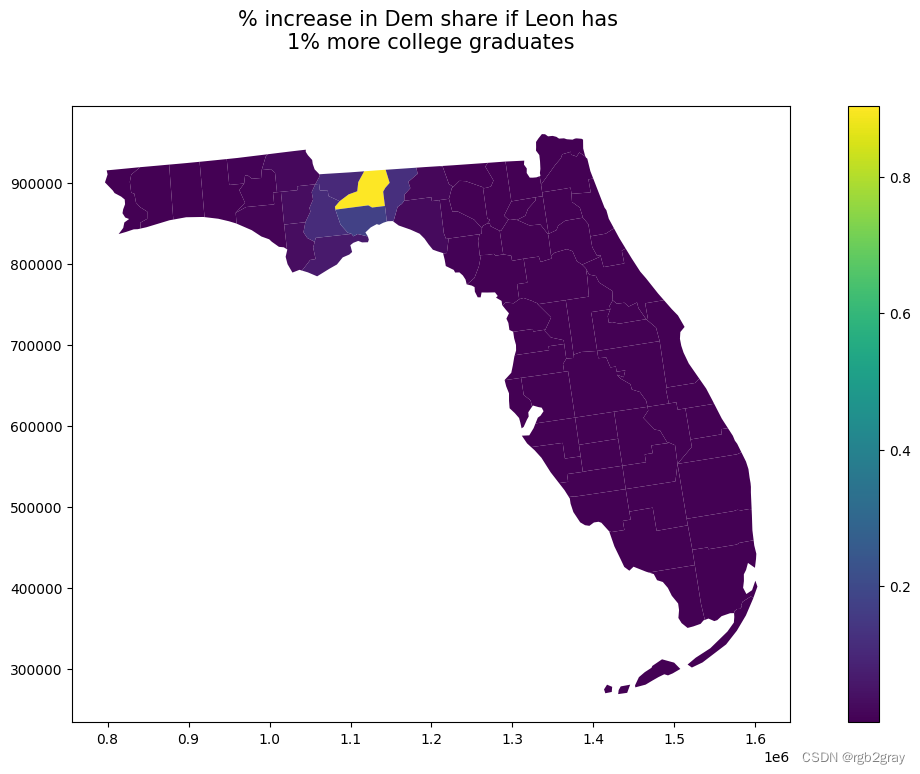
现在让我们来看看莱昂的变化如何影响周边县市。
#get the effects for leon and plot it
shp_voting['d_pct_bach_leon'] = effects[:,67]
ax = shp_voting[shp_voting['state'] == 12].plot(column='d_pct_bach_leon',legend=True,
figsize=(15,8), linewidth=0.0,aspect=1)
plt.title("% increase in Dem share if Leon has \n1% more college graduates",fontsize=15,y=1.08)
Text(0.5, 1.08, '% increase in Dem share if Leon has \n1% more college graduates')
shp_voting[(shp_voting['state'] == 12) & (shp_voting['NAME_x'] == "Jefferson")].d_pct_bach_leon
2808 0.121902
Name: d_pct_bach_leon, dtype: float64
因此,我们基本上可以看出,如果莱昂的大学毕业生人数增加 1%,预计附近县的 %dem 份额将增加约 0.12%。例如,受莱昂变化的影响,杰斐逊县的 dem 份额可能会增加 0.12%。
shp_voting[(shp_voting['state'] == 12) & (shp_voting['NAME_x'] == "Miami-Dade")].d_pct_bach_leon
2607 1.163942e-08
Name: d_pct_bach_leon, dtype: float64
然而,我们可以看到,对于迈阿密戴德等较远的县,间接溢出效应基本为零。这是因为效应的幅度 (rho) 以及指定的 W 矩阵非常局部。