背景
上游调用方,反馈当前welink-front服务不可用;
临时解决办法
手动重启welink-front服务,重启之后观测到业务日志正常刷,说明该问题暂时得到了解决;
但没过多久,上游调用方的同学又找来了,反馈当前服务又不可用了,果然该来的总是会来;
现象
直接jmap -heap [pid]打印堆内存大小,瞧着内存使用情况挺正常的;

gc日志显示,当前java服务在频繁的进行FullGC;
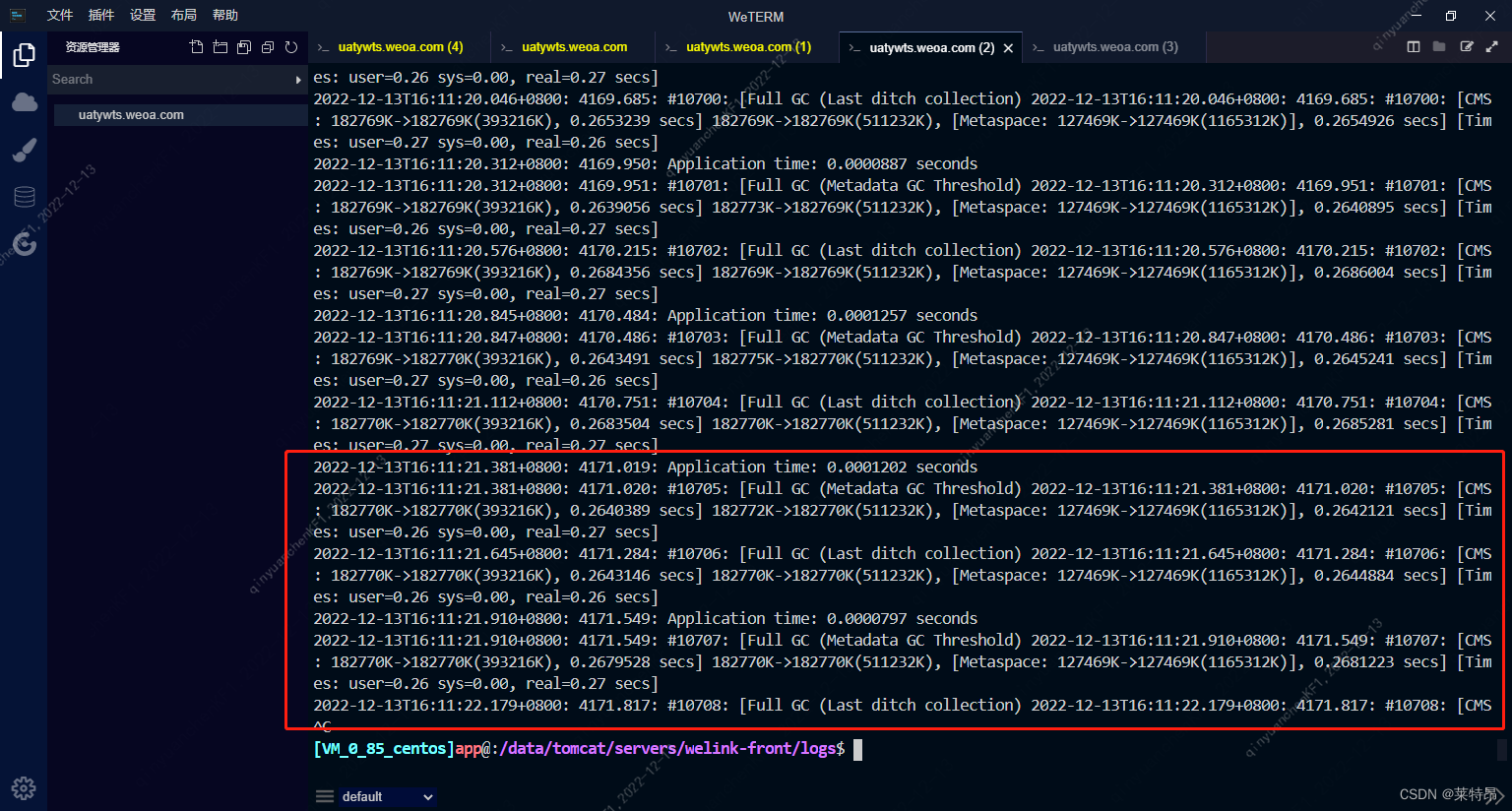
这里有个点,就是FullGC后,堆可用内存大小基本没怎么变化,GC了个寂寞;
细细想来,FullGC的原因无非那么几种:
1、实际业务导致堆内存短时间内暴增,例如高并发场景;
2、大对象;
3、内存泄漏,老年代存在大量释放不掉的对象;
4、元数据区满了;
5、堆外内存;
6、System.gc();
其实纠结那么多干嘛,直接jstat -gccause [pid]看GC原因就好了;
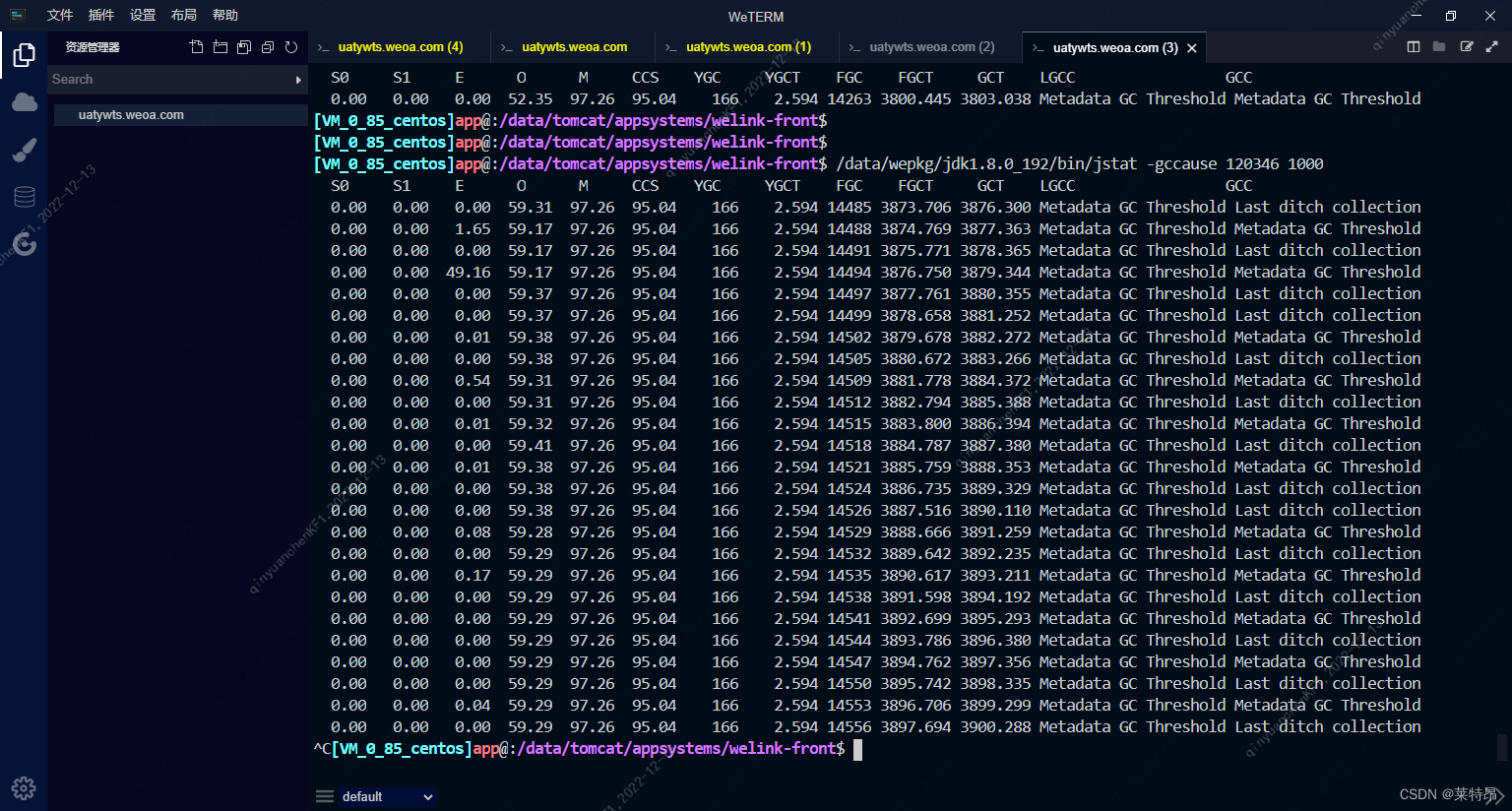
其实到这里就很明了了,元数据区内存使用率97.26%,上次GC原因为:Metadata GC Threshold,当前GC原因为:Last ditch collection;
Metadata GC Threshold:metaspace空间不能满足分配时触发,这个阶段不会清理软引用;
Last ditch collection:经过Metadata GC Threshold触发的full gc后还是不能满足条件,这个时候会触发再一次的gc cause为Last ditch collection的full gc,这次full gc会清理掉软引用;
到这里基本可以断定,就是元数据区内存不够霍霍了;根据前面堆内存打印显示,元数据区内最大为128M;这个也跟前面GC日志的结果相吻合;
所以解决方案就是直接调大堆内存和元数据区内存;
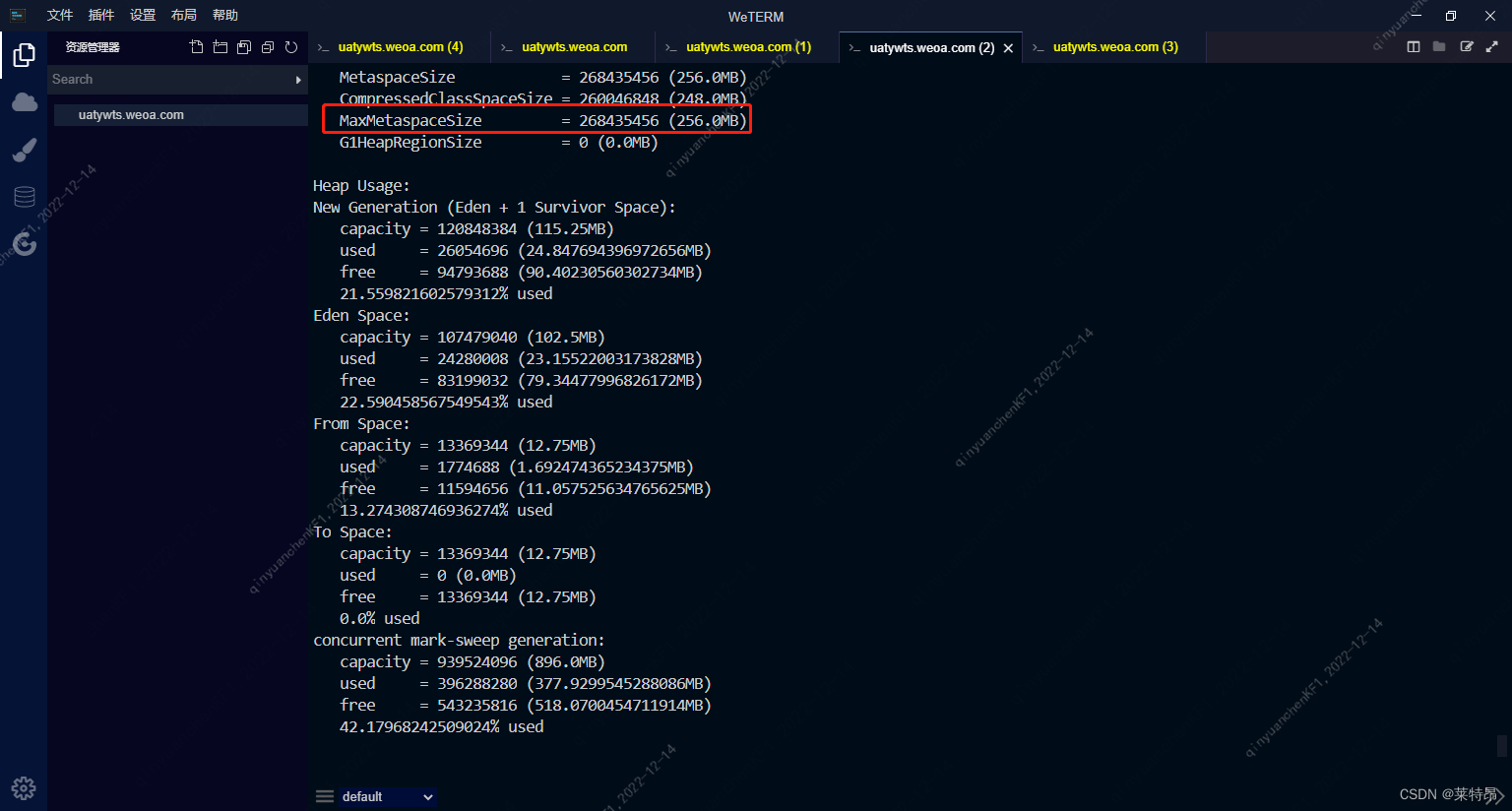
为什么是直接调大元数据区的内存大小呢?
是因为在测试环境的发布模板中,我们通常会直接将内存调小;
反思与总结
测试环境的问题,发现了应当立即定位分析根本原因,然后评估影响并确定解决方案,不要把悬念带上生产;