一. 概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
二. 定义

Person是父类,也称作基类。Student是子类,也称作派生类
而继承方式与访问限定符一样,都包括public、protected、private
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
string _name = "peter"; // 姓名
int _age = 18; // 年龄
};
class Student : public Person
{
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
protected:
int _jobid; // 工号
};
int main()
{
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
}例如上边的代码,在实例化对象的时候,例如s,首先会去调用Student
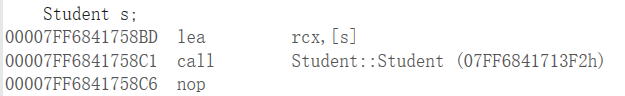
之后在Student内部由于继承的原因,会去调用Person

而根据访问限定符和继承方式的不同,成员所具有的权限也不同,具体情况如下
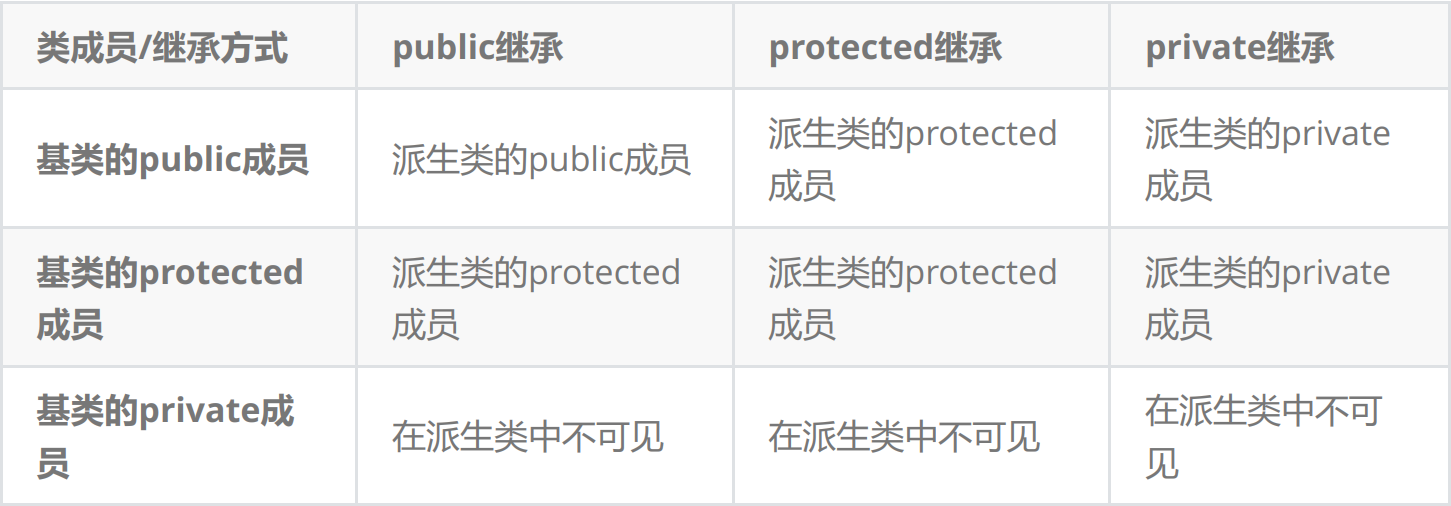
1.基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
2. 基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
3. 实际上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected> private
我们可以简单的测试一下
class Test1
{
public:
int a;
protected:
int b;
private:
int c;
};
class Test2 : public Test1
{
public:
void Print()
{
cout << a << ' ' << b << ' ' << c << endl;
}
protected:
int d;
};
int main()
{
Test2 t1;
t1.Print();
cout << t1.a << ' ' << t1.b << ' ' << t1.c << endl;
}当这段代码以不同的继承方式运行的时候,我们可以直接通过编译器的报错来观察(自己试吧)
而还有几点需要注意
1.使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
2. 在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强
3.友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员
4.基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例
三. 基类和派生类对象赋值转换
派生类对象可以赋值给基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
赋值转换仅限于公有继承,这是由于若是保护或者私有继承,在继承中会发生权限的转换,而若是权限发生了转换,再赋值给基类的话就会产生问题
与不同类型变量的赋值有所不同,它并不涉及类型转换,而是语法天然支持的行为
基类对象不能赋值给派生类对象。
基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。,但可能会产生越界问题,这里基类如果是多态类型,可以使用RTTI(RunTime Type Information)的dynamic_cast 来进行识别后进行安全转换。
四. 继承中的作用域
1. 在继承体系中基类和派生类都有独立的作用域。
2. 子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
例如下面的代码
class Test1
{
public:
int a=10;
};
class Test2 : public Test1
{
public:
void Print()
{
cout << a << endl;
}
protected:
int a=20;
};
int main()
{
Test2 t1;
t1.Print();
} 
可以看到,的确是直接访问自己的同名成员
3. 需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
class Test1
{
void Print(int i)
{
cout << "void Print(int i)" << endl;
}
public:
int a=10;
};
class Test2 : public Test1
{
public:
void Print()
{
cout << "void Print()" << endl;
}
protected:
int a=20;
};
int main()
{
Test2 t1;
t1.Print();
} 
而若是这样调用Print函数则会发生报错,需要标明基类
t1.Print(10);//error
t1.Test1::Print(10);当然,在实际中在继承体系里面最好不要定义同名的成员。
五. 派生类的默认成员函数
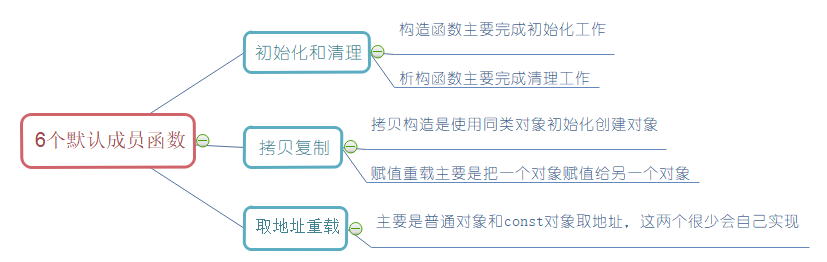
前四个默认成员函数在派生类中是如何生成的呢?
首先,如果我们不去自己实现,而是让编译器自动生成的话,那么这四个默认构造函数遵循的规律都是一致的,派生类中的自定义类型与内置类型与我们之前学过的一样进行处理,而继承下来的则去调用基类中对应的默认成员函数
我们若是想要自己去实现的话,首先是初始化:
即使没有发生隐藏操作,我们也不能直接在子类中进行父类成员的初始化,而是去调用父类的构造函数
class Test1
{
public:
Test1(int a)
:_a(a)
{}
int _a;
};
class Test2 : public Test1
{
public:
Test2(int a, int b)
:Test1(a)
,_b(b)
{}
protected:
int _b;
};而在拷贝构造中,我们所传入的是一个派生类的对象,而同样,我们也必须去调用父类的拷贝构造,在我们进行基类拷贝构造传参的时候,我们可以直接将派生类拷贝构造传入的对象直接作为参数,因为会进行切片处理为一个基类的对象
class Test1
{
public:
Test1(int a)
:_a(a)
{}
Test1(const Test1& t)
:_a(t._a)
{}
int _a;
};
class Test2 : public Test1
{
public:
Test2(int a, int b)
:Test1(a)
, _b(b)
{}
Test2(const Test2& t)
:Test1(t)
,_b(t._b)
{}
protected:
int _b;
};而赋值运算符重载与拷贝构造类似,需要注意的一点是基类与派生类的赋值运算符重载的函数名是一样的,因此,我们需要在调用基类的赋值运算符重载时标明基类
class Test1
{
public:
Test1(int a)
:_a(a)
{}
Test1(const Test1& t)
:_a(t._a)
{}
Test1 operator=(const Test1& t)
{
_a = t._a;
}
int _a;
};
class Test2 : public Test1
{
public:
Test2(int a, int b)
:Test1(a)
, _b(b)
{}
Test2(const Test2& t)
:Test1(t)
,_b(t._b)
{}
Test2& operator=(const Test2& t)
{
if (this != &t)
{
Test1::operator=(t);
_b = t._b;
}
return *this;
}
protected:
int _b;
};而析构函数比较特殊,我们依旧采用上面的方式
~Test2()
{
~Test1();
}会发现编译器报错了,这是因为,编译器会对析构函数名进行特殊处理,处理成destrutor(),因此导致隐藏
~Test2()
{
Test1::~Test1();
}这样写貌似就没有什么问题了,但是,若是我们测试一下,会发现另一个问题,那就是基类的析构函数被调用了两次,这是因为,由于栈区中遵循后进先出,而在构造的时候,基类先完成构造,之后才是派生类,而在析构的时候,我们就需要保证先析构派生类的成员,再析构基类的成员,而我们自己写显然不太能实现这样的效果,因此就在调用派生类的析构函数之后默认调用一次基类的析构函数。
六. 多继承
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承
在多继承中,多个父类之间要用逗号隔开
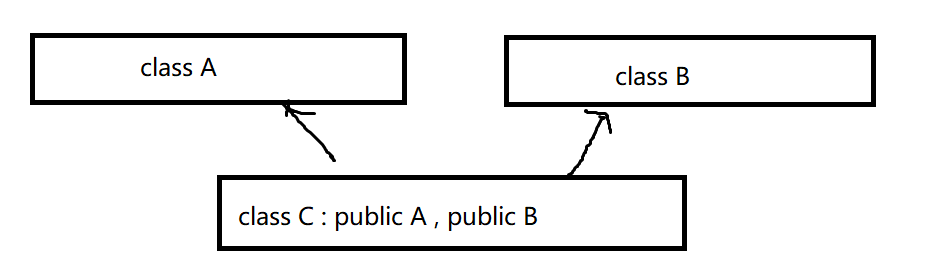
class A
{
public:
int _a = 1;
};
class B
{
public:
int _b = 2;
};
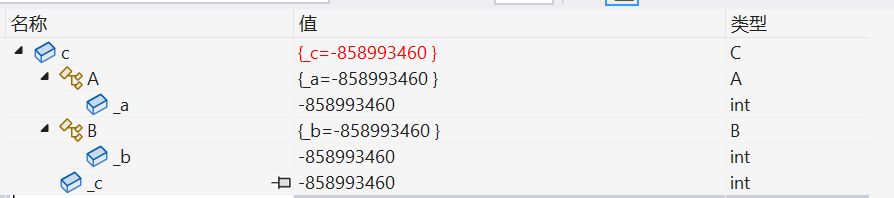
class C : public A, public B
{
public:
int _c = 3;
};
int main()
{
C c;
}
菱形继承:菱形继承是多继承的一种特殊情况
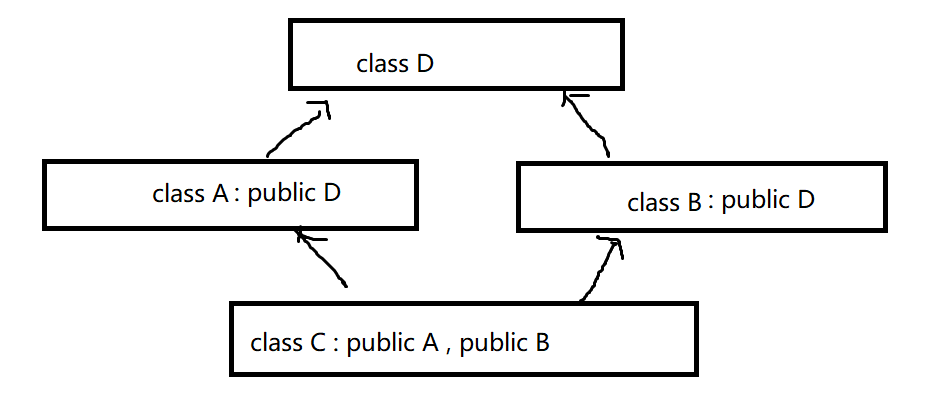
当然,菱形继承也不只是限于这种规律的方式
这样也属于菱形继承
然而菱形继承存在数据冗余和二义性的问题。例如上面的C类中就包括了两份D成员
class D
{
public:
int _d = 4;
};
class A :public D
{
public:
int _a = 1;
};
class B :public D
{
public:
int _b = 2;
};
class C : public A, public B
{
public:
int _c = 3;
};
int main()
{
C c;
}
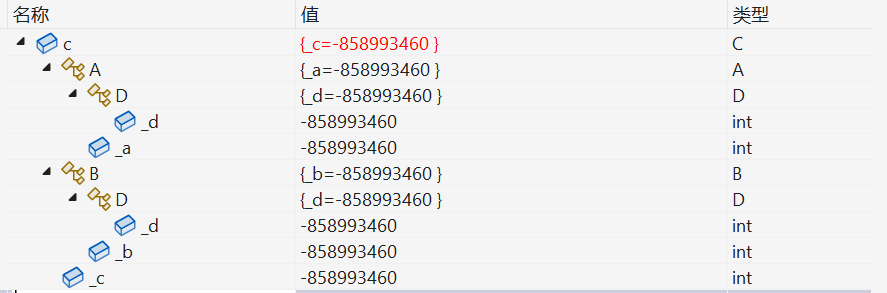
为了解决这个问题,就需要使用到虚拟继承
而虚拟继承使用上只需要在继承方式前加上virtual,要注意的是,虚拟继承不是发生在多继承上的,而是发生在多继承前多个派生类去继承一个基类的过程中
class D
{
public:
int _d;
};
class A :virtual public D
{
public:
int _a;
};
class B :virtual public D
{
public:
int _b;
};
class C : public A, public B
{
public:
int _c;
};
int main()
{
C c;
c.B::_d = 1;
}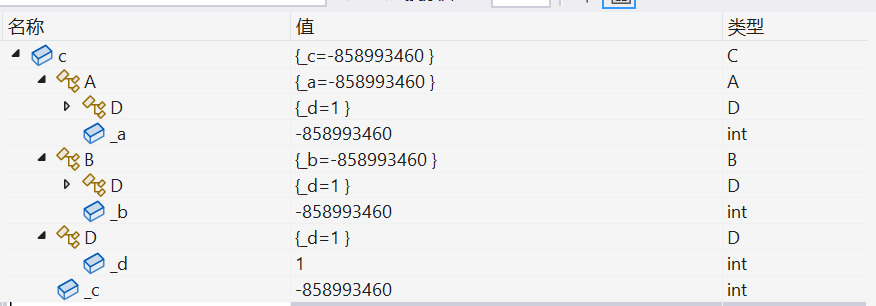
可以看到,在A类和B类包含了D类的同时,D类也出现在了c对象中
我们可以通过内存来探究一下原理
首先先看一下不使用虚拟继承的情况
class D
{
public:
int _d;
};
class A :public D
{
public:
int _a;
};
class B :public D
{
public:
int _b;
};
class C : public A, public B
{
public:
int _c;
};
int main()
{
C c;
c.A::_d = 1;
c.B::_d = 2;
c._a = 3;
c._b = 4;
c._c = 5;
}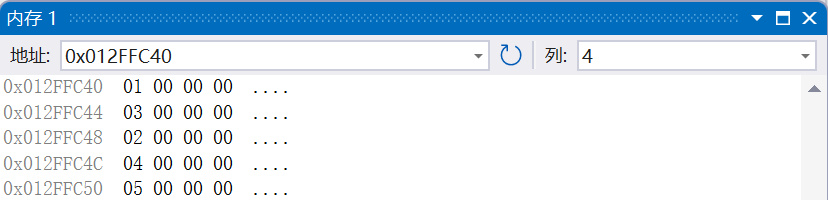
我们可以看到,内存由小到大依次存放的是A类中的D类、成员_a、B类中的D类、成员_b、以及成员_c
而若是使用虚拟继承
class D
{
public:
int _d;
};
class A :virtual public D
{
public:
int _a;
};
class B :virtual public D
{
public:
int _b;
};
class C : public A, public B
{
public:
int _c;
};
int main()
{
C c;
c.A::_d = 1;
c.B::_d = 2;
c._a = 3;
c._b = 4;
c._c = 5;
}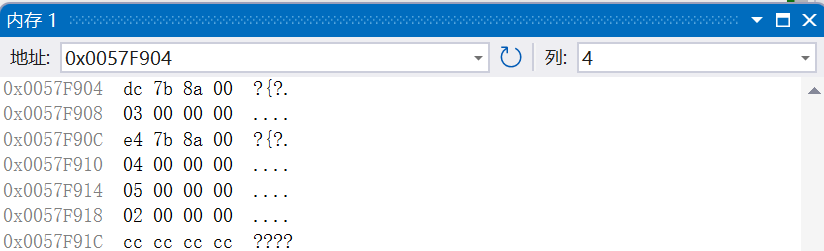
可以看到,在04和0C中有些不太一样的东西,其实是一个指针,存放的是地址,我们可以先不去管他,而首先依次是成员_a、 成员_b、成员_c,而由于是虚拟继承,只有一个成员_d,而它被放在了最后
而我们如何通过A类和B类去寻找对应的D类呢,这就涉及到那两个指针
我们依然是通过内存窗口来观察,
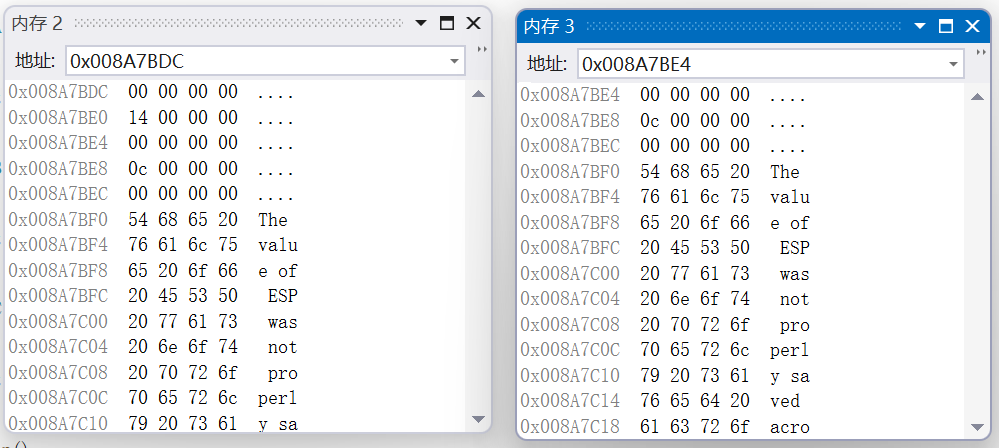
在这个地址下面四个字节的位置,分别存储了一个数字,转换为10进制为20和12,而这两个数字代表的是对应的偏移量,例如在对应的指针向下寻找偏移量的字节数,就是所虚拟继承的_d
而这两个指针所指向的其实是对应的虚基表,而这两个指针也被称为虚基表指针,具体作用我们已经在上面说过了
当然,虚拟继承的底层很复杂,因此,我们尽量不要去使用菱形继承
七. 继承与结合
这是继承
class A
{
public:
int _a;
};
class B :public A
{
public:
int _b;
};这是结合
class A
{
public:
int _a;
};
class B
{
public:
A a;
int _b;
};public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。
组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象
我们需要根据实际情况来选择使用继承还是组合
而若是存在都适合的情况,优先使用组合,组合的耦合度低,代码维护性好。