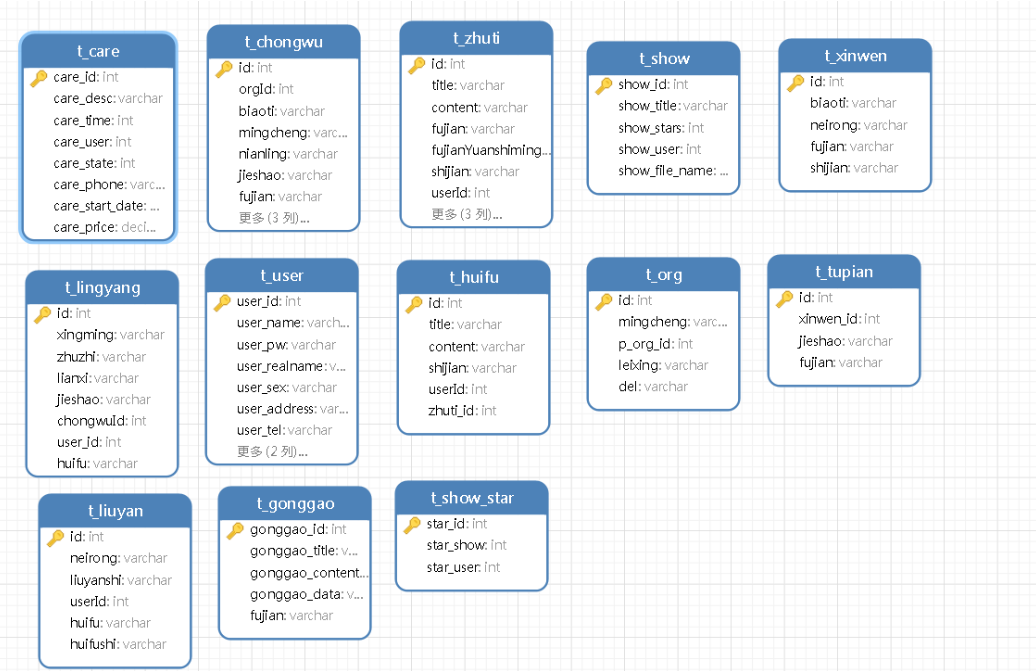
在公网IP为x.x.x.x、y.y.y.y和z.z.z.z并装有Centos8的服务器上进行hadoop集群搭建、zookeeper集群搭建和hbase搭建,都安装hadoop-3.1.3、server-jre-8u202-linux-x64、apache-zookeeper-3.6.4-bin和hbase-2.5.0-bin。
环境准备(三台服务器都一样)
第一步,创建统一工作目录。
# 软件安装路径
命令:mkdir -p /usr/local/src/server/
# 数据存储路径
命令:mkdir -p /usr/local/src/data/
# 安装包存放路径
命令:mkdir -p /usr/local/src/software/
第二步,在/usr/local文件夹中下载server-jre-8u202-linux-x64。
到地址:https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html下载server-jre-8u202-linux-x64的tar.gz压缩包。然后使用WinSCP将server-jre-8u202-linux-x64压缩包上传到/usr/local文件夹中。
命令:cd /usr/local/src/software
wget https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html/jre-8u202-linux-x64.tar.gz
第三步,上传、解压tar.gz压缩包。
命令:cd /usr/local/src/software
tar -zxvf server-jre-8u202-linux-x64.tar.gz -C /usr/local/src/server
第四步,配置jre环境变量,打开/etc/profile文件,在文件底部另起一行,加上下面代码:
export JAVA_HOME=/usr/local/src/server/jdk1.8.0_202
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH第五步,测试server-jre是否配置成功。
# 刷新profile文件
命令:source /etc/profile
# 查看jdk版本
命令:java -version
如果成功显示server-jre的版本,则说明server-jre配置成功。
第六步,关闭防火墙。
为了可以让本地的机器可以通过Web网页访问集群资源,为了防止在运行集群的时候出现集群不可访问的状况,需要关闭防火墙。
命令:systemctl stop firewalld
# 开机时禁用防火墙
命令:systemctl disable firewalld
第七步,各自修改主机名,配置IP地址映射。
命令:hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
对三台主机的IP地址进行映射,可以方便后续的配置,同时也方便对集群进行通信,三台机器同样操作。
在/etc/hosts文件中加入下面的代码:
x.x.x.x node1
y.y.y.y node2
z.z.z.z node3第八步,配置免密登录。
# 在~目录下执行,生成密钥
命令:cd
ssh-keygen -t rsa # 按四下enter
cd /root/.ssh/
cp id_rsa.pub authorized_keys
# 将node1的密钥拷到其他服务器上
ssh-copy-id -i node2
ssh-copy-id -i node3
第九步,集群时间同步。
命令:yum -y install ntpdate
ntpdate ntp4.aliyun.com
安装Hadoop(三台服务器都一样)
第一步,集群规划。
NameNode=NN DataNode=DN SecondaryNameNode=SNN
NodeManager=NM ResourceManager=RM
HDFS集群—主角色:NN 从角色:DN 主角色辅助角色:SNN
YARN集群—主角色:RM 从角色:NM
框架 node1 node2 node3
HDFS NN、DN DN SNN、DN
YARN NM RM、NM NMHadoop集群包括两个集群:HDFS集群和YARN集群。
两个集群都是标准的主从架构集群。
逻辑上分离:两个集群互相之间没有依赖、互不影响。
物理上在一起:某些角色进程往往部署在同一台物理服务器上。
MapReduce是计算框架、代码层面的组件,没有集群之说。
角色规划的准则:
根据软件工作特性和服务器硬件资源情况合理分配。
角色规划注意事项:
资源上有抢夺冲突的,尽量不要部署在一起。
工作上需要互相配合的,尽量部署在一起。
第二步,下载hadoop-3.1.3。
登录网址:https://archive.apache.org/dist/hadoop/common/
下载hadoop-3.1.3.tar.gz。也可以使用命令下载。
命令:cd /usr/local/src/software
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
第三步,上传、解压tar.gz压缩包。
命令:cd /usr/local/src/software
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local/src/server
第四步,配置环境变量。
在/etc/profile文件添加下面的代码:
export HADOOP_HOME=/usr/local/src/server/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin# 使环境变量生效
命令:source /etc/profile
# 测试是否配置成功
命令:hadoop version
如果结果显示“Hadoop 3.1.3”,则说明hadoop配置成功。
集群配置
配置文件在/usr/local/src/server/hadoop-3.1.3/etc/hadoop中。
第一步,对node1中的Hadoop自定义配置文件进行配置。
1)创建目录。
命令:mkdir /usr/local/src/server/hadoop-3.1.3/tmp
mkdir /usr/local/src/server/hadoop-3.1.3/dfs
2)配置hadoop-env.sh。
在hadoop-env.sh文件中加入下面的代码:
export JAVA_HOME=/usr/local/src/server/jdk1.8.0_202# 在文件末尾加入下面的代码,设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3)配置core-site.xml。
在core-site.xml文件中加入下面的代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- 配置Hadoop存储数据目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>4)配置hdfs-site.xml。
在hdfs-site.xml文件中加入下面的代码:
<configuration>
<!-- namenode存储hdfs名字的空间的元数据文件目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/name</value>
</property>
<!-- datanode上的一个数据块的物理的存储位置文件 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/data</value>
</property>
<!-- 指定HDFS保存数据副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置一个block的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- 定义namenode界面的访问地址 -->
<property>
<name>dfs.http.address</name>
<value>node1:50070</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 指定DataNode的节点配置文件 -->
<property>
<name>dfs.hosts</name>
<value>/usr/local/src/server/hadoop-3.1.3/etc/hadoop/workers</value>
</property>
</configuration>5)配置workers。
在workers文件中加入下面的代码:
node1
node2
node3注意:不要有多余的换行和空格
6)mapred-site.xml配置。
在mapred-site.xml文件中加入下面的代码:
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上,表示MapReduce使用yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启MapReduce小任务模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 设置历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 设置网页访问历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>7)配置yarn-site.xml。
在yarn-site.xml文件中加入下面的代码:
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- NodeManager获取数据的方式shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- yarn的web访问地址 -->
<property>
<description>
The http address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>
The https address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<!-- 开启日志聚合功能,方便我们查看任务执行完成之后的日志记录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>第二步,对node2中的Hadoop自定义配置文件进行配置。
1)创建目录。
命令:mkdir /usr/local/src/server/hadoop-3.1.3/tmp
mkdir /usr/local/src/server/hadoop-3.1.3/dfs
2)配置hadoop-env.sh。
在hadoop-env.sh文件中加入下面的代码:
export JAVA_HOME=/usr/local/src/server/jdk1.8.0_202# 在文件末尾加入下面的代码,设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3)配置core-site.xml。
在core-site.xml文件中加入下面的代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node2:9000</value>
</property>
<!-- 配置Hadoop存储数据目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>4)配置hdfs-site.xml。
在hdfs-site.xml文件中加入下面的代码:
<configuration>
<!-- namenode存储hdfs名字的空间的元数据文件目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/name</value>
</property>
<!-- datanode上的一个数据块的物理的存储位置文件 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/data</value>
</property>
<!-- 指定HDFS保存数据副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置一个block的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 指定DataNode的节点配置文件 -->
<property>
<name>dfs.hosts</name>
<value>/usr/local/src/server/hadoop-3.1.3/etc/hadoop/workers</value>
</property>
</configuration>5)配置workers。
在workers文件中加入下面的代码:
node1
node2
node3注意:不要有多余的换行和空格
6)mapred-site.xml配置。
在mapred-site.xml文件中加入下面的代码:
<configuration>
<!-- 指定MapReduce程序运行在Yarn上,表示MapReduce使用yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启MapReduce小任务模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 设置历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node2:10020</value>
</property>
<!-- 设置网页访问历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node2:19888</value>
</property>
</configuration>7)配置yarn-site.xml。
在yarn-site.xml文件中加入下面的代码:
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- NodeManager获取数据的方式shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<!-- yarn的web访问地址 -->
<property>
<description>
The http address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>
The https address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<!-- 开启日志聚合功能,方便我们查看任务执行完成之后的日志记录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>第三步,对node3中的Hadoop自定义配置文件进行配置。
1)创建目录。
命令:mkdir /usr/local/src/server/hadoop-3.1.3/tmp
mkdir /usr/local/src/server/hadoop-3.1.3/dfs
2)配置hadoop-env.sh。
在hadoop-env.sh文件中加入下面的代码:
export JAVA_HOME=/usr/local/src/server/jdk1.8.0_202# 在文件末尾加入下面的代码,设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3)配置core-site.xml。
在core-site.xml文件中加入下面的代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node3:9000</value>
</property>
<!-- 配置Hadoop存储数据目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>4)配置hdfs-site.xml。
在hdfs-site.xml文件中加入下面的代码:
<configuration>
<!-- namenode存储hdfs名字的空间的元数据文件目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/name</value>
</property>
<!-- datanode上的一个数据块的物理的存储位置文件 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/server/hadoop-3.1.3/dfs/data</value>
</property>
<!-- 指定HDFS保存数据副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置一个block的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- 定义secondarynamenode的通信地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50071</value>
</property>
<!-- 设置HDFS的文件权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 指定DataNode的节点配置文件 -->
<property>
<name>dfs.hosts</name>
<value>/usr/local/src/server/hadoop-3.1.3/etc/hadoop/workers</value>
</property>
</configuration>5)配置workers。
在workers文件中加入下面的代码:
node1
node2
node3注意:不要有多余的换行和空格
6)mapred-site.xml配置。
在mapred-site.xml文件中加入下面的代码:
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上,表示MapReduce使用yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启MapReduce小任务模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 设置历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node3:10020</value>
</property>
<!-- 设置网页访问历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node3:19888</value>
</property>
</configuration>7)配置yarn-site.xml。
在yarn-site.xml文件中加入下面的代码:
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- NodeManager获取数据的方式shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- yarn的web访问地址 -->
<property>
<description>
The http address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>
The https address of the RM web application.
If only a host is provided as the value,the webapp will be served on a random port.
</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<!-- 开启日志聚合功能,方便我们查看任务执行完成之后的日志记录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>集群启动
# 注意:如果集群是第一次启动,需要在Namenode所在节点格式化NameNode,非第一次不用执行格式化 Namenode 操作。
命令:hadoop namenode -format
# 在node1,node2,node3上分别启动HDFS、YARN
命令:cd /usr/local/src/server/hadoop-3.1.3/sbin
./start-dfs.sh (HDFS)
./start-yarn.sh (YARN)
# 在node1,node2,node3上查看集群的hadoop进程
命令:jps
若在node1,node2,node3上分别显示下面的结果,则说明启动集群启动成功。
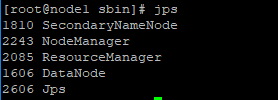

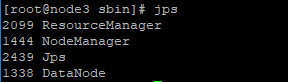
# 在node1,node2,node3上分别停止HDFS、YARN
命令:cd /usr/local/src/server/hadoop-3.1.3/sbin
./stop-dfs.sh (HDFS)
./stop-yarn.sh (YARN)
ZooKeeper的安装与配置(三台服务器都一样)
第一步,环境准备。
1)jvm环境;
2)JDK必须是7或以上版本;
3)使用shell进行远程连接。
第二步,下载安装ZooKeeper。
登录网址:https://dlcdn.apache.org/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz,下载apache-zookeeper-3.6.4-bin,然后通过WinSCP上传到/usr/local/src文件夹。
第三步,解压ZooKeeper安装包。
命令:cd /usr/local/src
tar -xvzf apache-zookeeper-3.6.4-bin.tar.gz -C /usr/local/
mv apache-zookeeper-3.6.4-bin zookeeper-3.6.4
第四步,配置ZooKeeper。
# 将/usr/local/zookeeper-3.6.4/conf中的zoo_sample.cfg改成zoo.cfg
命令:cd /usr/local/zookeeper-3.6.4/conf
mv zoo_sample.cfg zoo.cfg
# 在/usr/local/zookeeper-3.6.4下新建zkData文件夹
命令:cd /usr/local/zookeeper-3.6.4
mkdir zkData
最后对文件zoo.cfg进行编辑,将dataDir的路径换成文件夹zkData的路径,得到下面的代码:
dataDir=/usr/local/zookeeper-3.6.4/zkData
第五步,启动测试。
# 启动服务端
命令:cd /usr/local/zookeeper-3.6.4/bin
./zkServer.sh start
# 查看进程
命令:jps
# 启动客户端
命令:cd /usr/local/zookeeper-3.6.4/bin
./zkCli.sh
第六步,配置环境变量。
在文件/etc/profile中添加下面的代码:
#zookeeper
export ZK_HOME=/usr/local/zookeeper-3.6.4
export PATH=$PATH:$ZK_HOME/bin# 使环境变量生效
命令:source /etc/profile
第七步,对/usr/local/zookeeper-3.6.4/conf/zoo.cfg文件做进一步的修改。
说明:2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口,server后面的数字与后面的myid相对应。
server.1=x.x.x.x:2888:3888
server.2=y.y.y.y:2888:3888
server.3=z.z.z.z:2888:3888
第八步,进入/usr/local/zookeeper-3.6.4/zkData,修改myid文件,内容要和zoo.cfg中的修改相对应。
ZooKeeper集群测试
# 启动各个服务器的zookeeper
命令:./zkServer.sh start
# 查看当前zookeeper的状态
命令:./zkServer.sh status
若zookeeper正常启动,则可以发现,由于选举机制,不能成功启动第一台服务器node1和第二台服务器node2。
当启动第三台服务器node3时,出现选票超过半数,node3成为了leader,而node1和node2成为了follower。
安装Hbase
Hbase依赖于ZooKeeper、HDFS,在启动Hbase之前必须要启动ZooKeeper、HDFS,否则Hbase无法启动。
第一步,下载Hbase安装包。
登录网址:Index of /dist/hbase,下载hbase-2.5.0-bin.tar.gz,然后通过WinSCP上传到/usr/local/src文件夹。
第二步,解压Hbase安装包。
命令:cd /usr/local/src
tar -xvzf hbase-2.5.0-bin.tar.gz -C /usr/local/
第三步,配置环境变量。
在文件/etc/profile中添加下面的代码:
#Hbase
export PATH=$PATH:$HBASE_HOME/bin
export HBASE_HOME=/usr/local/hbase-2.5.0/# 使环境变量生效
命令:source /etc/profile
配置Hbase
第一步,配置hadoop-env.sh文件。
编辑文件/usr/local/hbase-2.5.0/conf/hadoop-env.sh,得到的代码如下:
export HBASE_HOME=/usr/local/hbase-2.5.0/
export JAVA_HOME=/usr/local/src/server/jdk1.8.0_202
export HADOOP_HOME=/usr/local/src/server/hadoop-3.1.3
export HBASE_LOG_DIR=$HBASE_HOME/logs
export HBASE_PID_DIR=$HBASE_HOME/pids
export HBASE_MANAGES_ZK=false注意:HBASE_MANAGES_ZK的值默认是true,作用是让Hbase启动的同时也启动ZooKeeper。在安装的过程中,采用独立运行ZooKeeper集群的方式,故将其属性值改为false。
第二步,配置hbase-site.xml文件。
编辑文件/usr/local/hbase-2.5.0/conf/hbase-site.xml,得到的代码如下:
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<!-- 设置HRegionServers共享目录,mycluster是在hadoop中设置的名字空间 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1/hbase</value>
</property>
<!--设置HMaster的rpc端口-->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!--设置HMaster的http端口-->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!--指定zookeeper集群端口-->
<property>
<name>hbase.zookeeper.property.clientPort</name> #zookeeper端口号
<value>2181</value>
</property>
<!一指定zookeeper数据目录,需要与zookeeper集群中的dataDir配置相一致 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/apache-zookeeper-3.6.4-bin/zkdata</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<!-- 指定缓存文件存储的路径 -->
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase-2.5.0/tmp</value>
</property>
</configuration>第三步,配置regionservers文件。
编辑文件/usr/local/hbase-2.5.0/conf/regionservers,得到的代码如下:
node1
node2
node3注意:regionservers文件负责配置Hbase集群中哪台节点作Region Server服务器。
第四步,分发配置。
# 将在node1配置好的hbase分发到node2和node3
命令:scp -r /usr/local/hbase-2.5.0 root@node2:/usr/local
scp -r /usr/local/hbase-2.5.0 root@node3:/usr/local
# 将在node1配置好的/etc/profile分发到node2和node3
命令:scp -r /etc/profile root@node2:/etc/
scp -r /etc/profile root@node3:/etc/
# 在node2和node3使环境变量生效
命令:source /etc/profile
注意:“export HBASE_PID_DIR=/usr/local/hbase-2.5.0/pids”在node2和node3上没有,需要在/usr/local/hbase-2.5.0目录下面使用命令“mkdir -p /usr/local/hbase-2.5.0/pids”创建pids文件夹。
启动Hbase
第一步,启动zookeeper(在全部虚拟机上启动)。
命令:cd /usr/local/apache-zookeeper-3.6.4-bin/bin
./zkServer.sh start
第二步,启动hadoop(在hadoop102上启动)。
命令:start-all.sh
第三步,启动hadoop(在hadoop102上启动)。
命令:start-all.sh
第四步,验证Hbase是否配置成功。
在浏览器输入网址:hadoop102:16010,若页面无法访问,则说明配置失败,需要对/usr/local/src/server/hadoop-3.1.3/etc/hadoop中的文件core-site.xml以及/usr/local/hbase-2.5.0/conf中的文件hbase-site.xml进行编辑,两个hadoop102端口号要一致。
编辑完成后,再次访问网页,若可以成功进入,则说明配置成功。