
CVPR2023论文速览Transformer
news2026/2/17 3:18:58
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1851590.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

全面的WAS存储权限管理方案,了解一下
WAS存储权限管理通常指的是对Windows Azure Storage(WAS)的存储设备进行权限控制和管理。在企业中,随着数据量的飞速增长,对存储设备的安全性、效率和成本的关注也日益增加。有效的WAS存储权限管理可以确保数据的安全性࿰…

Python | Leetcode Python题解之第166题分数到小数
题目: 题解:
class Solution:def fractionToDecimal(self, numerator: int, denominator: int) -> str:if numerator % denominator 0:return str(numerator // denominator)s []if (numerator < 0) ! (denominator < 0):s.append(-)# 整数部…
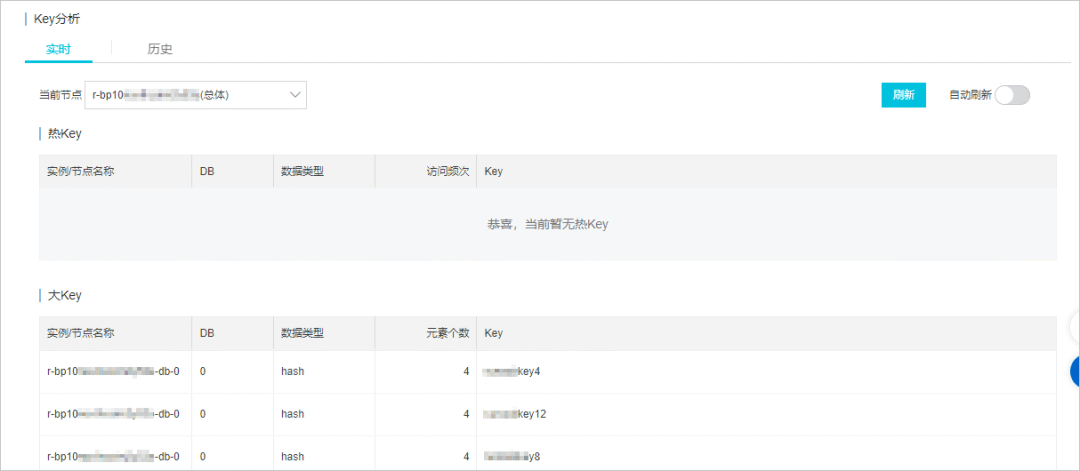
Redis大key有什么危害?如何排查和处理?
什么是 bigkey?
简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准: String 类型的 value 超过 1MB 复合类型(Li…

Magento1与Magento2的区别
本人接触magento有些年头了。。。 2012年开始用magento 1.7。2016年开始用magento2.0。 截止到目前。M1最新版本是1.9.3.3。 M2最新版本是2.2.2。 想当年第一次接触magento的时候,是跟同事一起,网上下载的Alan Storm的深入理解magento系统,…

VB计算圆柱体积和表面积
已知圆半径和圆柱的高,计算圆柱体积和表面积。
Public Class Form1Private Sub Button1_Click(sender As Object, e As EventArgs) Handles Button1.ClickConst PI 3.14159Dim r As Integer, h As IntegerDim t As Single, s As Singler Val(TextBox1.Text)h V…
高考志愿填报,如何权衡学校和专业?
高考是人生的分水岭,成绩好的学生能就读更好的大学,获得更多的学习资源,但也有一些同学即使凭借高分数进入了高校,专业的学习过程却不尽如人意,他们也没有将100%的精力投入到专业学习当中。
无论高考结束之后获得了多…
saas产品运营案例 | 联盟营销计划如何帮助企业提高销售额?
在当今数字化时代,SaaS(软件即服务)产品已成为企业提高效率、降低成本的重要工具。然而,面对激烈的市场竞争,如何有效地推广SaaS产品、提高销售额,成为许多企业面临的挑战。林叔将以ClickFunnels为例&#…
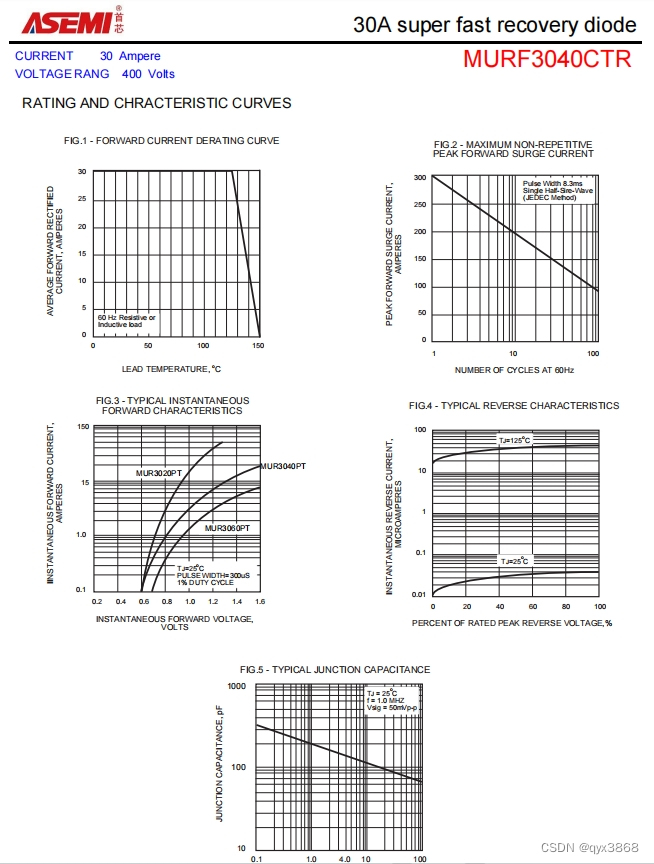
MURF3040CTR-ASEMI智能AI应用MURF3040CTR
编辑:ll
MURF3040CTR-ASEMI智能AI应用MURF3040CTR
型号:MURF3040CTR
品牌:ASEMI
封装:TO-220F
恢复时间:35ns
最大平均正向电流(IF):30A
最大循环峰值反向电压(VR…

牛客练习题打卡--redis
A list保证数据线性有序且元素可重复,它支持lpush、blpush、rpop、brpop等操作,可以当作简单的消息队列使用,一个list最多可以存储2^32-1个元素;
redis中set是无序且不重复的;
zset可以按照分数进行排序 ,是有序不重复的;
Redi…
![[图解]建模相关的基础知识-14](https://img-blog.csdnimg.cn/direct/684a51ed12ab455ab4b458bfb41326fc.png)
[图解]建模相关的基础知识-14
1 00:00:00,360 --> 00:00:03,690 相当于把行的数量给削减了
2 00:00:03,700 --> 00:00:10,540 你看,T4等于所有
3 00:00:10,550 --> 00:00:12,660 符合这种条件的,e属于T3
4 00:00:12,670 --> 00:00:15,210 然后性别是男性
5 00:00:15,…

20.Cargo和Crates.io
标题 一、采用发布配置自定义构建1.1 默认配置1.2 修改配置项 二、将crate发布到Crates.io2.1 编写文档注释2.2 常用(文档注释)部分2.3 文档注释作用测试2.4 为包含注释的项添加文档注释2.5 使用pub use导出公有API2.6 创建Crates.io账号2.7 发布2.8 版本…

若依框架集成微信支付
1. 添加微信支付相关依赖
<!-- 微信支付 -->
<dependency><groupId>com.github.wxpay</groupId><artifactId>wxpay-sdk</artifactId><version>0.0.3</version>
</dependency>
<dependency><groupId>com.gi…

了解OpenEuler及安装OpenEuler实验环境
OpenEuler中国社区
OpenEuler操作系统介绍 OpenEuler是一款开源、免费的操作系统,由openEuler社区运作。当前openEuler内核源于Linux,支持鲲鹏及其它多种处理器,能够充分释放计算芯片的潜能,是由全球开源贡献者构建的高效、稳定、…
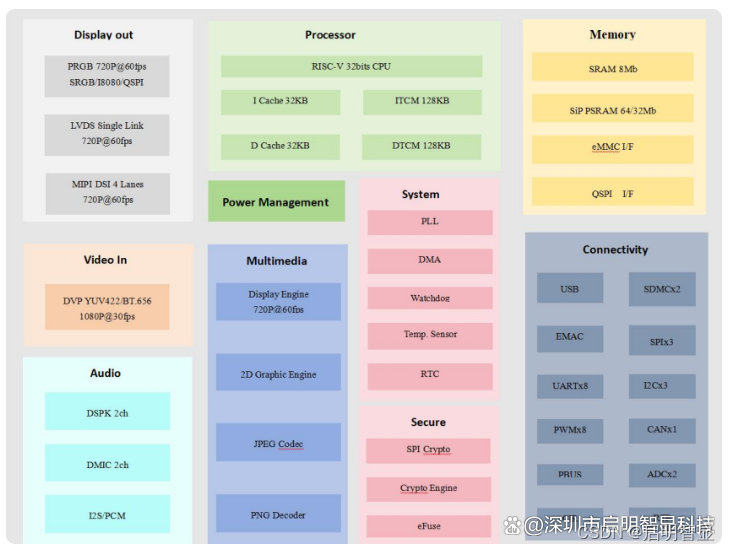
【启明智显产品分享】工业级HMI芯片——Model3,不止是速度,USB\CAN\8路串口
一、引言
Model3作为一款工业级HMI芯片,其性能卓越且功能全面。本文将从多个角度深入介绍Model3芯片,以展示其不仅仅是速度的代表。
二、Model3核心特性介绍
Model3工业级跨界MCU是一款国产自主的基于RISC-V架构的高性能芯片,内置平头哥E…
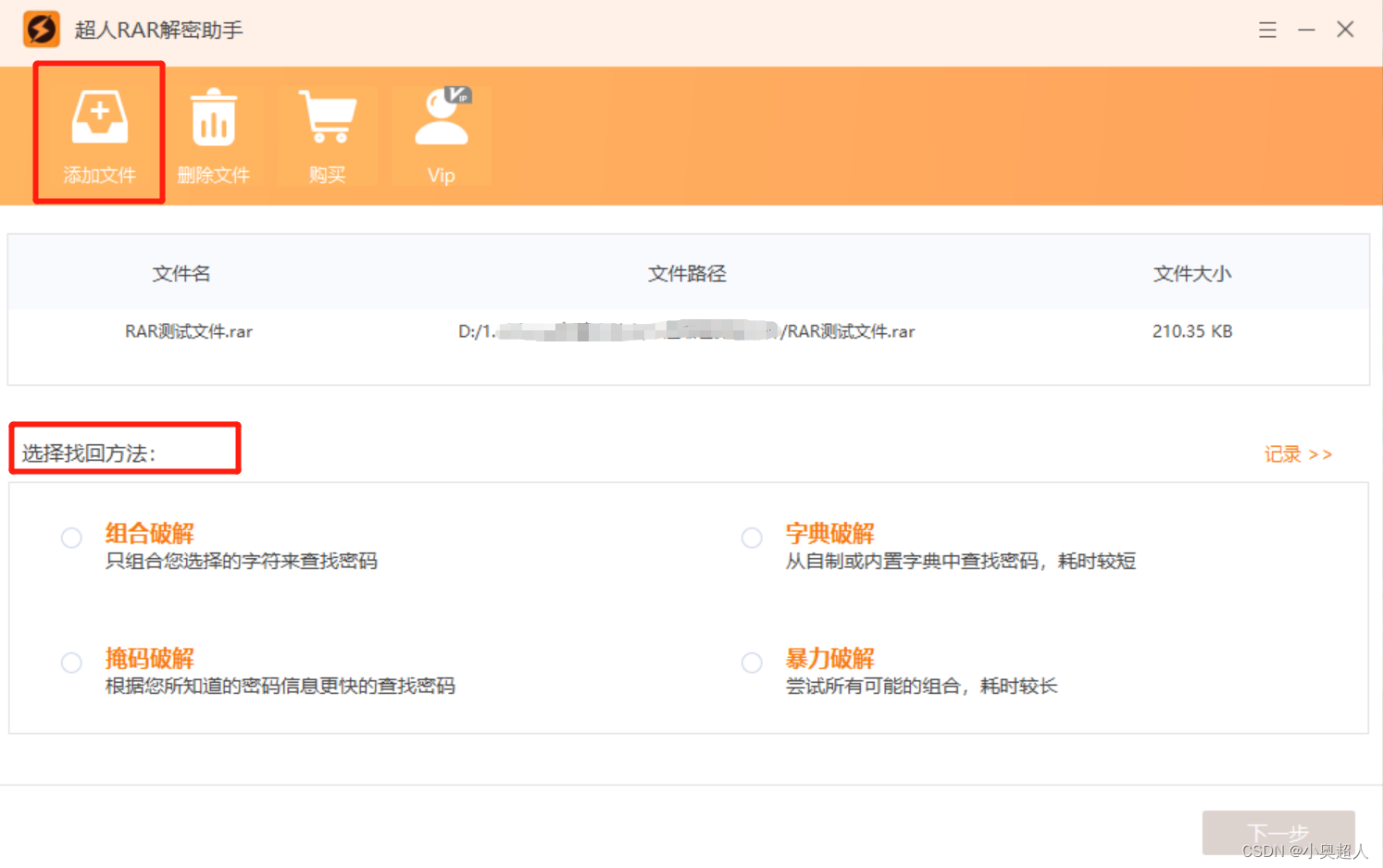
技巧:合并多个RAR分卷压缩
因为文件压缩之后体积仍然过大,大家可能会选择进行分卷压缩,那么rar分卷压缩包之后如何合并成一个压缩包文件呢?今天我们来学习rar分卷压缩包,合并成一个的方法。
最基础的方法就是将分卷压缩包解压出来之后,再将文件…
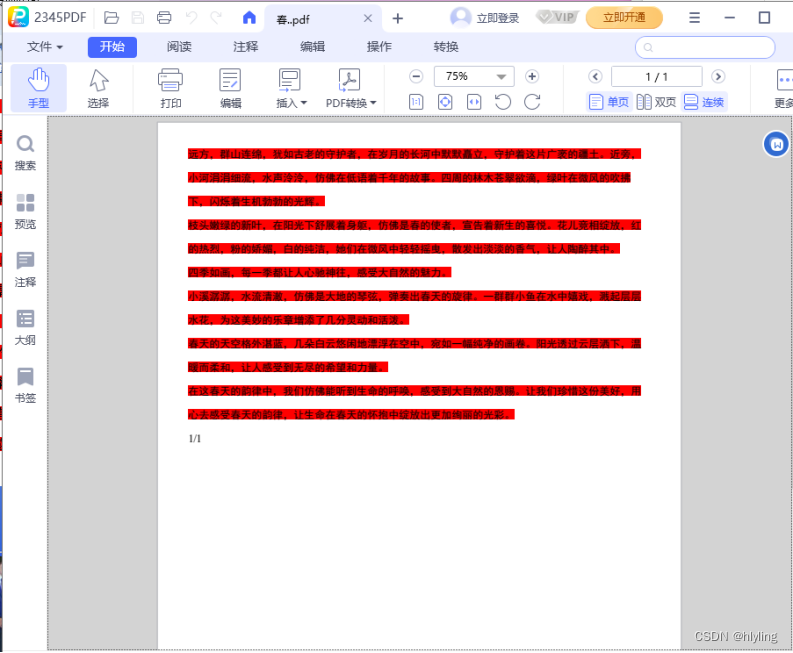
解锁PDF处理新境界:轻松调整字体,让你的文档焕然一新!
数字化时代,PDF文件已经成为我们日常办公和学习中不可或缺的一部分。它们为我们提供了方便的阅读体验,同时也保证了文档内容的完整性和格式的统一性。然而,有时候我们可能会遇到一个问题:如何轻松调整PDF文件中的字体,…

2024年能源电力行业CRM研究报告
中国能源电力行业属于大制造业的重要组成部分,在国民经济中的地位举足轻重。据统计,近十年来能源电力行业的整体投资呈现出增长趋势,尤其是“十四五”期间增长显著,2022年全国主要电力企业共完成投资12470亿元,同比增长…

炸裂!Claude 3.5 正式发布!超越 GPT-4o!
Anthropic 又憋了个大招!推出了 Claude 3.5 Sonnet!速度是 Claude 3 的两倍!而且数学和编码能力已经超过了 GPT-4o! 官方声称:这是我们迄今为止最智能的模型。 直接看测评图,很多指标都吊打 GPT-4o…
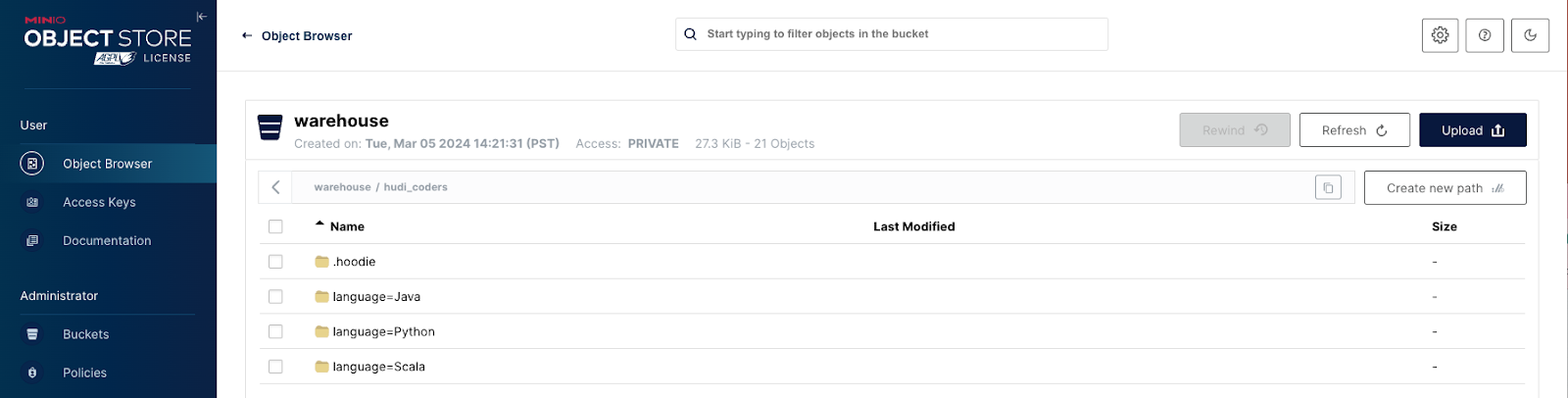
具有 Hudi、MinIO 和 HMS 的现代数据湖
Apache Hudi 已成为管理现代数据湖的领先开放表格式之一,直接在现代数据湖中提供核心仓库和数据库功能。这在很大程度上要归功于 Hudi 提供了表、事务、更新/删除、高级索引、流式摄取服务、数据聚类/压缩优化和并发控制等高级功能。
我们已经探讨了 MinIO 和 Hudi…

CentOS7在2024.6.30停止维护后,可替代的Linux操作系统
背景 Linux的发行版本可以大体分为两类,一类是商业公司维护的发行版本,一类是社区组织维护的发行版本,前者以著名的Redhat(RHEL)为代表,后者以Debian为代表。国内占有率最多的却是Centos,这是由…