1.主题
基于人类偏好微调语言模型(Fine-Tuning Language Models from Human Preferences)
出处: Fine-Tuning Language Models from Human Preferences、
2.摘要
奖励学习使得强化学习(RL)可以应用于那些通过人类判断来定义奖励【1. 关键词是什么】 的任务,通过向人类提问来建立奖励模型。大多数关于奖励学习的研究使用了模拟环境,但复杂的价值信息通常以自然语言表达【2. 对比】,我们认为将奖励学习应用于语言是使RL在实际任务中实用且安全的关键。在本文中,我们基于生成预训练语言模型的进展,将奖励学习应用于四个自然语言任务:继续生成正面情感文本或物理描述性语言,以及TL;DR和CNN/Daily Mail数据集上的摘要任务【3. 任务】。对于风格化续写任务,我们仅通过5000次人类比较就取得了良好结果。对于摘要任务,通过60,000次人类比较训练的模型能够复制整句话但跳过不相关的前言;这导致合理的ROUGE分数和人类标签者的优异表现,但可能利用了标签者依赖简单启发式的事实 【4. 实验结果】。
1. 奖励学习: 通过人类的反馈来定义奖励,从而指导强化学习(RL)。
2. 模拟环境: 之前的研究主要在虚拟环境中进行,但这些环境往往过于简单,无法反映现实世界的复杂性。【比如选择最短的路径通关游戏,相比于自然语言,复杂度相差甚远】
4. 主要任务: 奖励模型使得强化学习在处理任务更有效【指的是自然语言那类任务】
5. 实验结果:
风格化续写:仅通过5000次人类比较就取得了良好结果,这表明人类反馈在指导模型生成方面非常有效。摘要任务:通过60,000次人类比较训练的模型能够生成合理的摘要,尽管这种方法可能依赖了人类标签者使用简单启发式的事实。
3.引言
我们希望将强化学习应用于那些仅通过人类判断来定义的复杂任务,在这些任务中,只有通过询问人类才能判断结果的好坏【1. 目的】。为此,我们可以首先使用人类标签来训练一个奖励模型,然后优化该模型。尽管有大量通过与人类互动来学习此类模型的研究,但这些研究直到最近才被应用于现代深度学习,并且即便如此,也仅应用于相对简单的模拟环境(Christiano等,2017;Ibarz等,2018;Bahdanau等,2018)。相比之下,在现实世界中,人类需要向AI代理指定复杂目标,这可能涉及并需要自然语言,这是表达价值观念的丰富媒介。当代理必须与人类进行交流以提供更准确的监督信号时,自然语言尤为重要(Irving等,2018;Christiano等,2018;Leike等,2018)。
自然语言处理最近取得了显著进展。一种成功的方法是先在无监督数据集上预训练一个大型生成语言模型,然后对该模型进行监督任务的微调【2.做法与对比】(Dai和Le,2015;Peters等,2018;Radford等,2018;Khandelwal等,2019)。这种方法通常显著优于从头开始训练监督数据集,并且一个单一的预训练语言模型通常可以通过微调在许多不同的监督数据集上达到最先进的性能【3. 做法的优势】(Howard和Ruder,2018)。在某些情况下,不需要微调:Radford等(2019)发现,经过生成训练的模型在无需额外训练的情况下(零样本)在NLP任务上表现良好。
将强化学习应用于自然语言任务有着悠久的历史。许多这方面的工作使用算法定义的奖励函数,例如翻译的BLEU(Ranzato等,2015;Wu等,2016)、摘要的ROUGE(Ranzato等,2015;Paulus等,2017;Wu和Hu,2018;Gao等,2019b)、基于音乐理论的奖励(Jaques等,2017)或故事生成的事件检测器(Tambwekar等,2018)。Nguyen等(2017)在BLEU上使用了RL,但应用了几个错误模型来模拟人类行为。Wu和Hu(2018)和Cho等(2019)从现有文本中学习连贯性模型,并将其用作摘要和长文生成的RL奖励。Gao等(2019a)通过将奖励学习应用于一篇文章一次构建了一个交互式摘要工具。使用人类评价作为奖励的实验包括Kreutzer等(2018),他们使用离线策略奖励学习进行翻译,以及Jaques等(2019),他们将Jaques等(2017)的修改版Q学习方法应用于对话中的隐式人类偏好。Yi等(2019)从人类那里学习奖励以微调对话模型,但对奖励进行了平滑处理以允许监督学习。我们参考Luketina等(2019)对涉及语言作为组件的RL任务和使用迁移学习进行RL结果的调查。
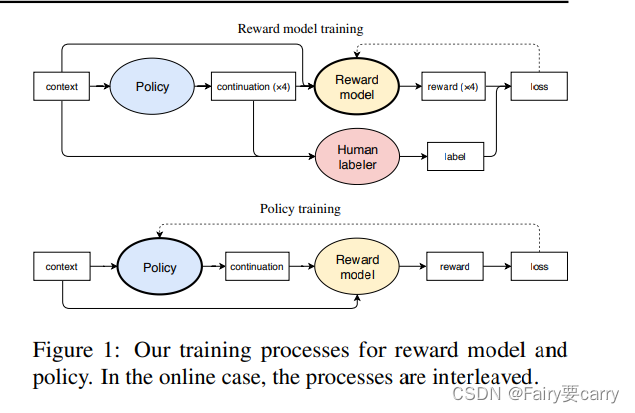
在本文中,我们结合了自然语言处理中的预训练进展和人类偏好学习。我们使用从人类偏好中训练的奖励模型,通过强化学习而不是监督学习来微调预训练的语言模型。根据Jaques等(2017;2019)的研究,我们使用KL约束来防止微调模型偏离预训练模型。我们将我们的方法应用于两类任务:以匹配目标风格(如正面情感或生动描述性语言)的方式继续文本,以及对CNN/Daily Mail或TL;DR数据集(Hermann等,2015;Völske等,2017)中的文本进行摘要。我们的动机是处理那些没有或不足的监督数据集的NLP任务,以及那些程序化奖励函数是我们真实目标的糟糕代理的任务。
对于风格化续写任务,我们使用5,000个人类比较(每次选择4个续写中的最佳一个)进行微调,使得微调后的模型在86%的情况下被人类更喜欢,而对比零样本学习为77%,对比监督学习的情感网络为77%【体现出无监督预训练+微调的效果更好】。对于摘要任务,我们使用60,000个人类样本来训练模型,这些模型可以大致描述为“智能复制器”:它们通常从输入中复制整句话,但会跳过不相关的开头。这种复制行为自然地从数据收集和训练过程中出现;我们没有使用任何显式的复制机制(如See等,2017;Gehrmann等,2018)。一种解释是,复制是一种容易准确的方式,因为我们没有指示标签者惩罚复制,而是指示他们惩罚不准确。它还可能反映了一些标签者检查复制作为快速确保摘要准确性的一种启发式方法。确实,人类标签者显著更喜欢我们的模型而不是监督微调的基线,甚至比人类编写的参考摘要还要喜欢,但不如复制前三句话的基线 【好处:这种行为(跳过不相干部分)并不是通过显式的复制机制实现的,而是在数据收集和训练过程中自然出现的】。
对于摘要任务,我们继续收集额外数据,并在策略改进时重新训练我们的奖励模型(在线数据收集)。我们还测试了离线数据收集,使用原始语言模型的数据来训练奖励模型;离线数据收集显著降低了训练过程的复杂性。对于TL;DR数据集,人类标签者71%的时间更喜欢在线数据收集训练的策略,而在定性评估中,离线模型通常提供不准确的摘要。相比之下,对于风格化续写任务,我们发现离线数据收集效果同样好。这可能与风格任务所需的数据非常少有关;Radford等(2017)显示,生成训练的模型可以从很少的标签样本中学习分类情感。
在并行工作中,Böhm等(2019)也使用人类评估来学习摘要的奖励函数,并使用RL优化该奖励函数。他们的工作更详细地调查了CNN/Daily
Mail数据集上学习的策略和奖励函数,而我们更广泛地探索了从人类反馈中学习,并在更大的计算规模上进行探索。因此,我们考虑了几个额外的任务,探索了在线奖励模型训练和更多数据的效果,并对大规模语言模型进行了奖励建模和RL微调。
1. 奖励模型增强强化学习对任务处理的过程:
-
奖励模型训练
1.Context(上下文):从上下文开始,这里指输入的一段文字或语境。
2. Policy(策略):基于上下文生成多个(例如四个)可能的续写(continuation)。
3. Human Labeler(人类标签者):这些生成的续写被送给人类标签者,人类根据自己的判断对这些续写进行评分或选择最好的续写。
4. Reward Model(奖励模型):人类标签者的选择结果被用于训练奖励模型。奖励模型根据人类的反馈生成对应的奖励信号。
5. Loss(损失):奖励模型根据生成的奖励信号计算损失,并通过优化过程不断改进自身。 -
策略训练
1. Context(上下文):同样从上下文开始。
2. Policy(策略):基于上下文生成续写。
3. Reward Model(奖励模型):使用训练好的奖励模型对生成的续写进行评估,生成奖励信号。
4. Loss(损失):策略模型根据奖励信号计算损失,并通过优化过程不断改进策略。
在在线情况下,这两个过程是交替进行的,也就是说,奖励模型和策略会不断地互相优化,形成一个循环。【优化点】
2. 好处: 奖励模型和策略模型在互相优化的过程中,策略模型会逐渐生成更符合人类偏好的回答,奖励模型也会越来越准确地评估这些回答。【不断优化回答,使其适应上下文环境进行有效反馈】
3. 举例:
-
奖励模型训练
1. Context(上下文):输入:“你好!今天的天气怎么样?”
2. Policy(策略):生成四个可能的续写:
续写1:“天气很好,适合外出。”
续写2:“我不知道,你可以看看天气预报。”
续写3:“今天天气晴朗,温度适中。”
续写4:“今天可能会下雨,记得带伞。”
3. Human Labeler(人类标签者):人类标签者选择最好的续写。假设他们选择续写3:“今天天气晴朗,温度适中。”
4. Reward Model(奖励模型):人类标签者的选择结果(续写3)用于训练奖励模型。奖励模型根据这个选择生成对应的奖励信号,例如给续写3一个高分。
5. Loss(损失):奖励模型计算生成的奖励信号与实际选择的偏差,并通过优化过程不断改进自身。 -
策略训练
1. Context(上下文):再次输入:“你好!今天的天气怎么样?”
2. Policy(策略):策略模型基于上下文生成一个续写。例如,生成:“今天天气晴朗,适合外出。”
3. Reward Model(奖励模型):使用训练好的奖励模型对生成的续写进行评估,假设奖励模型给这个续写打了高分,因为它符合之前人类选择的标准。
4. Loss(损失):策略模型根据奖励信号计算损失,并通过优化过程改进策略,使其更倾向于生成高质量的续写。
4. 引言核心内容:
1. 研究动机:希望将强化学习应用于复杂任务 【自然语言】,这些任务仅通过人类判断来定义,且需要自然语言来表达复杂的价值概念。
2. 现状分析:虽然之前有大量研究通过与人类互动来学习模型,但这些研究主要应用于简单的模拟环境。现代深度学习下的奖励学习仍然主要集中在相对简单的环境中 【自然语言和模拟环境经过奖励学习的比较】。
3. 自然语言处理的进展:预训练大型生成语言模型,然后对其进行监督任务的微调,这种方法在许多监督数据集上表现优异,甚至在某些情况下无需微调即可在NLP任务中表现良好。
4. 强化学习在自然语言任务中的应用:过去的工作主要使用算法定义的奖励函数,但本文结合了自然语言处理中的预训练进展和人类偏好学习,通过奖励模型进行强化学习微调。
总的来说, 提出了一种新的方法,将人类偏好与预训练语言模型相结合,通过强化学习进行微调,以解决自然语言处理中的复杂任务。这种方法特别适用于没有或不足的监督数据集,以及那些程序化奖励函数不充分的任务。




![[数据集][图像分类]瑜伽动作分类数据集1238张5类别](https://img-blog.csdnimg.cn/direct/27483b7bacf94ec98c1f250b8975b0c4.png)