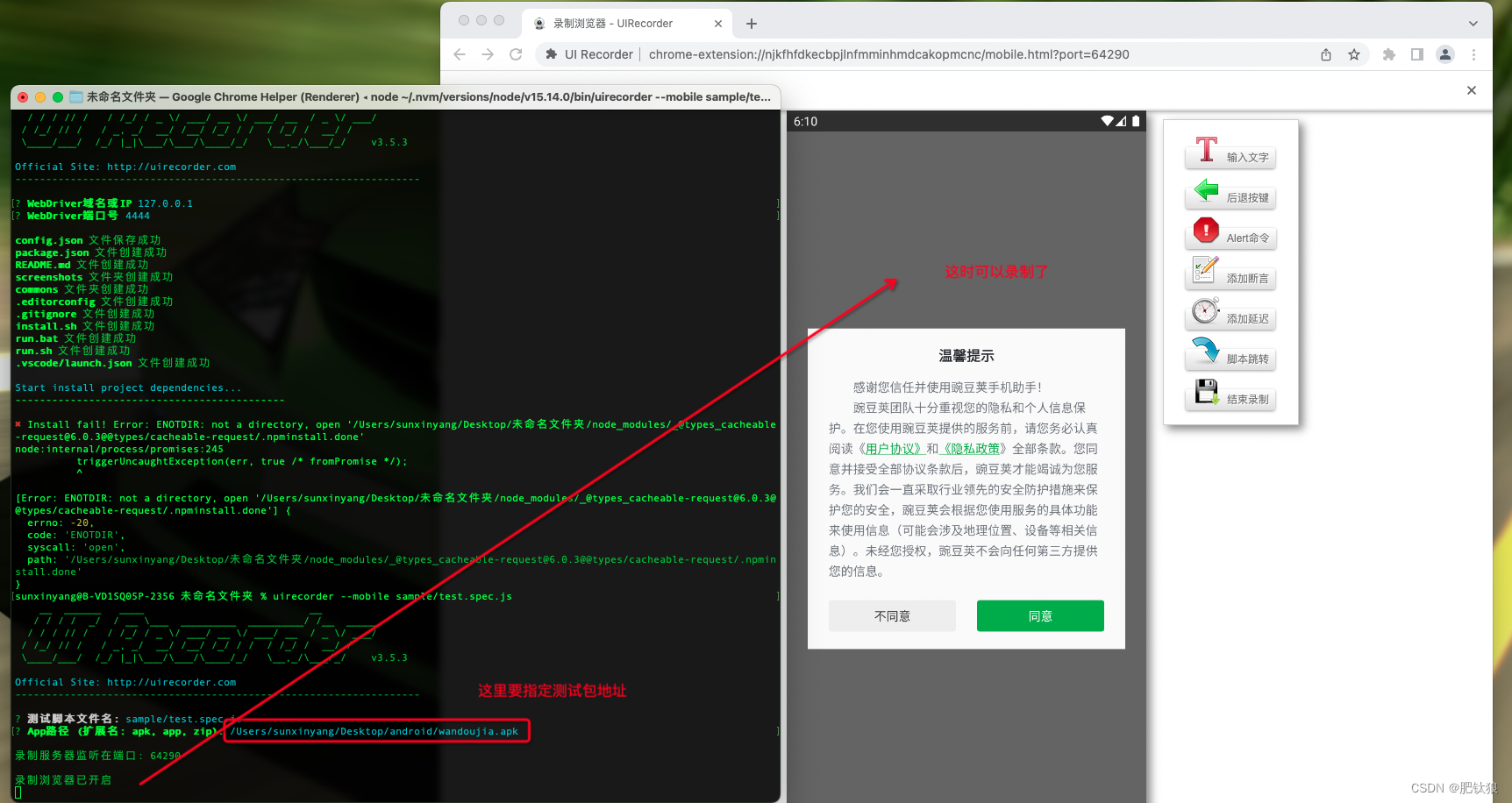
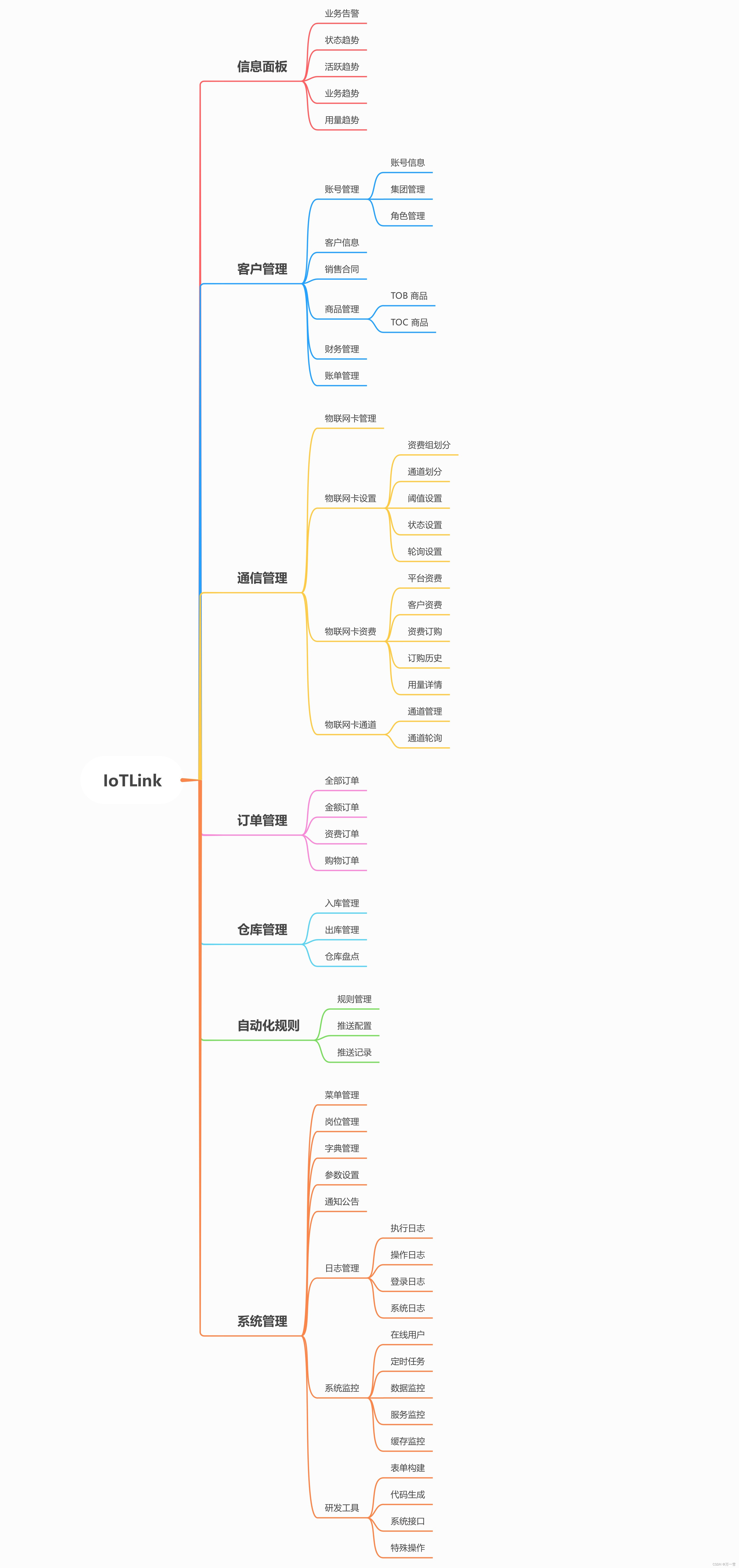
参考书目:


堆和方法区中的数据是可以被共享的
堆中的数据是被栈中的变量所持用的,栈是线程隔离的,每个线程私有一个栈,所以栈中的数据不共享
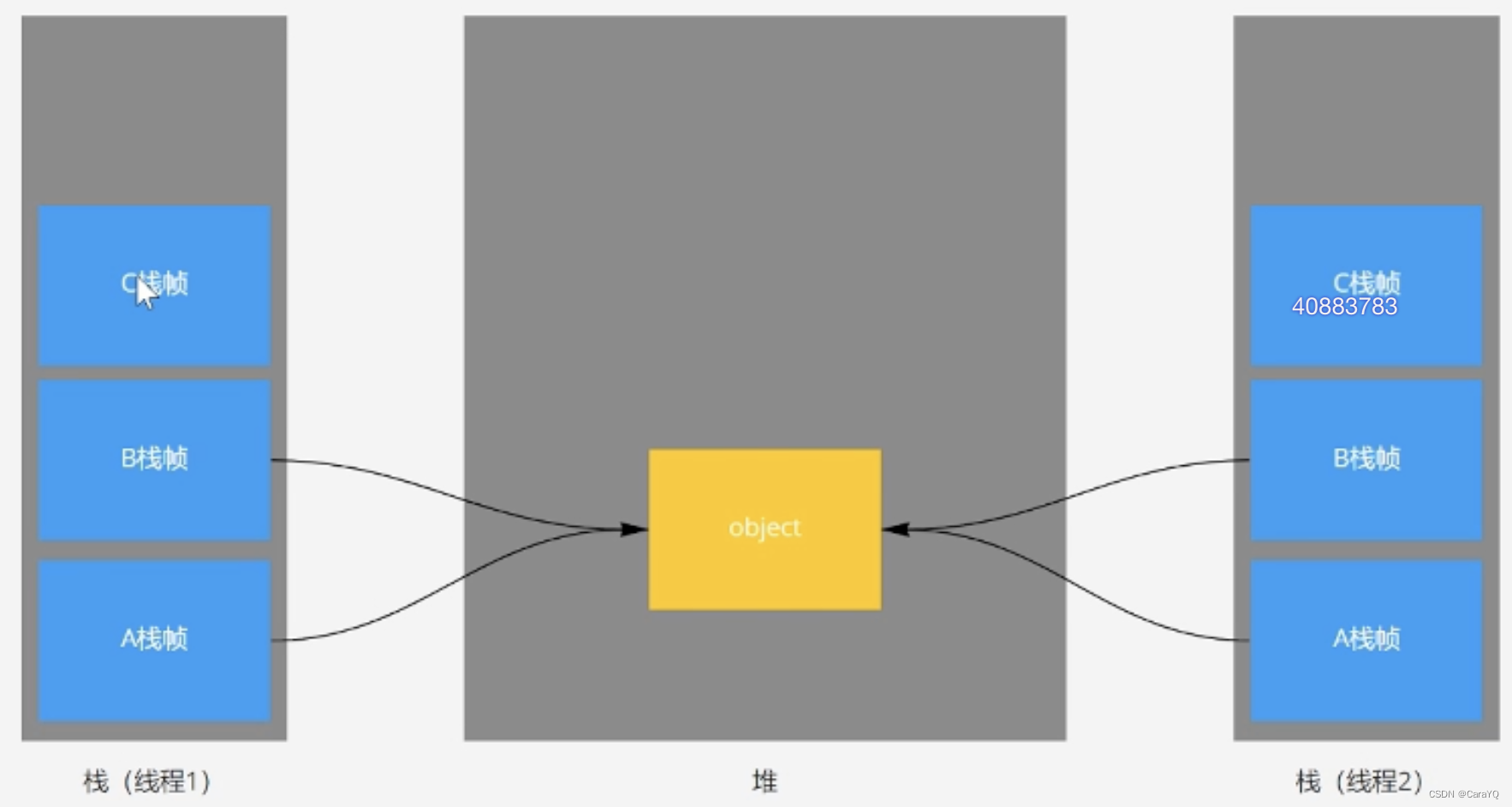
调用a方法时,jvm会给a方法创建一块内存区,让其入栈,这块区域被称为a的栈帧,调用b方法、c方法时,同理
如果多个线程访问同一个成员变量,需要加锁,但是如果在方法内定义了一个局部变量,局部变量时是线程私有的,没必要加锁,除非这个局部连量指向了成员变量,即堆中的数据,产生了共享,才需要对局部变量加锁

执行n++这条语句,cpu会将高级语言转换成机器语言,在底层执行时,会先将n加载到寄存器并初始化为0,再进行n++,再将值写入内存,执行完(以上三步的)任意一步都可能进行线程切换,这就是原子性问题
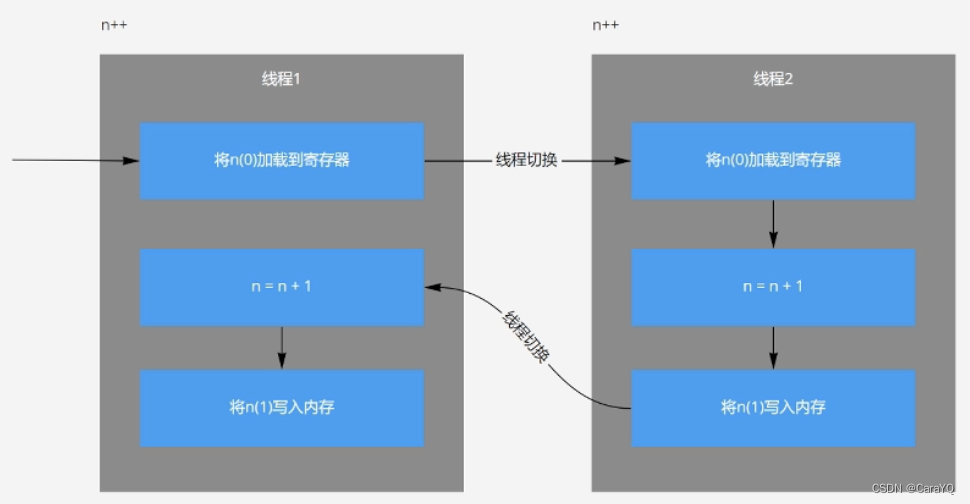
假如操作系统是单核的,在并发时,先将线程1的n加载到寄存器并初始化为0,此时线程切换了,(执行线程2的n++语句),将线程2的n加载到寄存器并初始化为0,然后执行线程2的n=n+1,然后将线程2的n=1写入内存,此时线程切换了,继续执行线程1,将线程1的n=n+1,因为线程1的n为初始值0,所以此时n=1,接下来将n=1写入内存。问题:执行了两次n++,但结果是n=1。
在操作系统中,并发是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。

cpu与内存通过缓存交互,内存与硬盘的交互也是类似的,因为内存比硬盘快,缓存比内存快
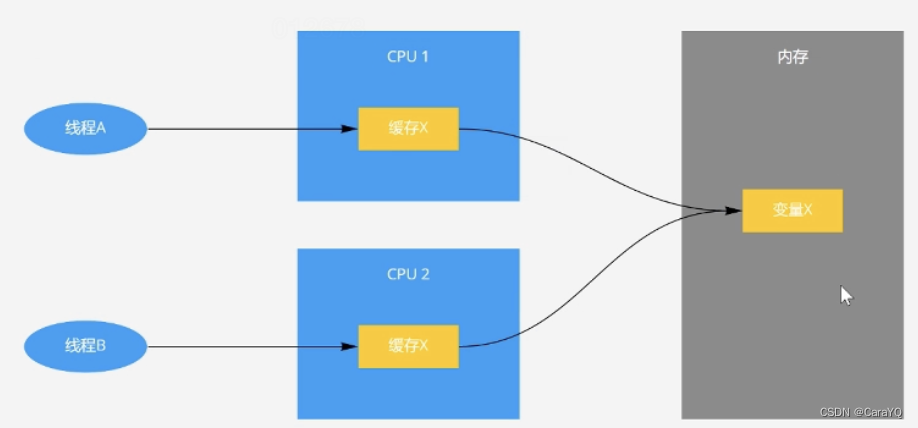
假如操作系统是双核的,有两个cpu,内存中有一个变量x,cpu1的线程a要修改x:将x加载进缓存,线程a在缓存中修改,改完了将x同步回内存,cpu2的线程b要修改x也是这个逻辑,假如两个线程同时修改x,同时同步回内存,会发生冲突,这就是可见性问题

以执行下述代码为例:
// 创建一个单例对象
if(instance == null){
instance = new Singleton();
}
代码执行顺序应该是:判断instance == null,如果为true,则在内存中分配一块空间R,R中存放Singleton实例对象,然后把R的地址给instance变量,但是为了提高性能,编译器和处理器会对指令重排序,可能在内存中分配完空间R,就将R的地址给instance变量了,然后再往R中存放Singleton实例对象,如果是按照这个顺序的话,执行完R的地址给instance变量之后,线程切换了,线程b从头开始执行这段代码,判断结果肯定是false,于是他直接返回instance,但是此时的instance中并没有Singleton实例对象,于是出问题了。


共享内存:一个线程把数据放在共享的内存中,另一个线程去取
消息传递:一个线程给另一个线程发送消息

假如线程a与线程b进行通信,线程a将数据写入本地内存a,然后本地内存a将数据刷到主内存中,线程b将数据读取到本地内存b中,线程b就可以访问数据了,由jmm控制两个线程的读写顺序
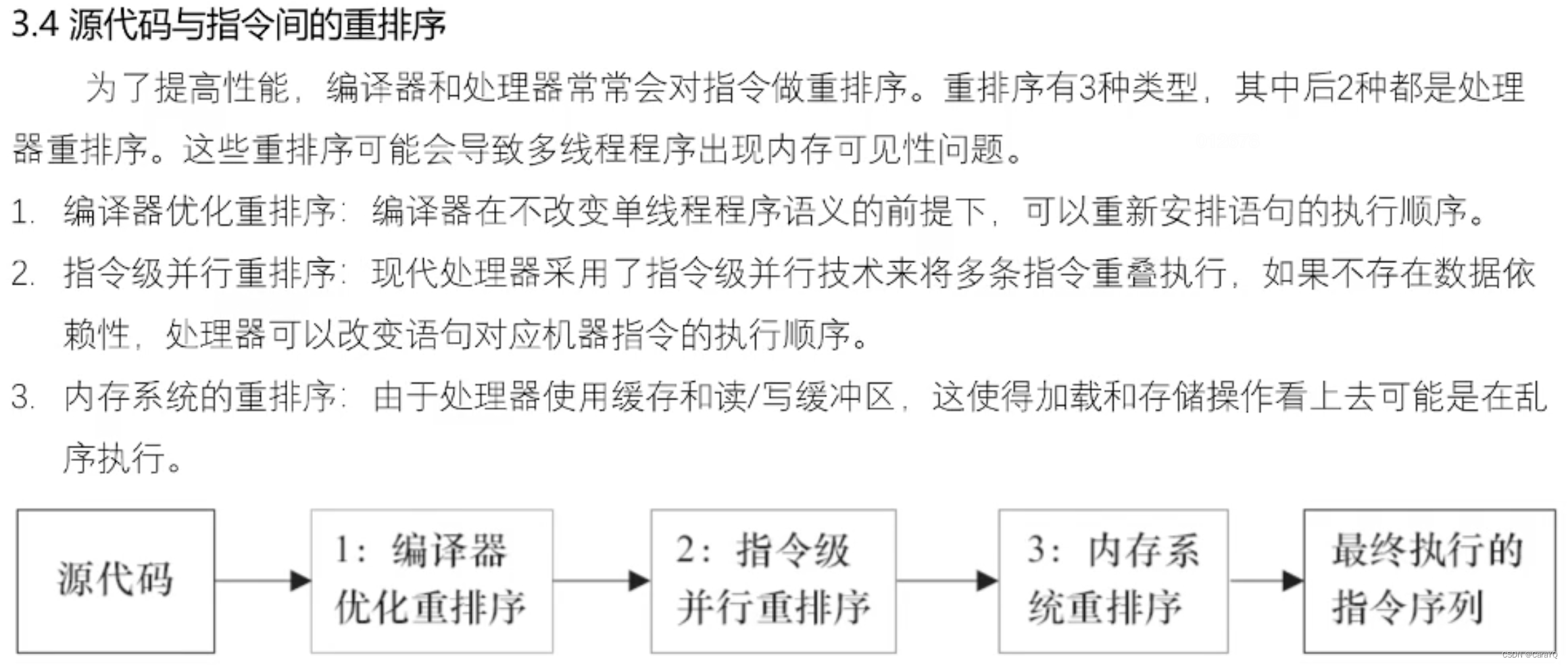
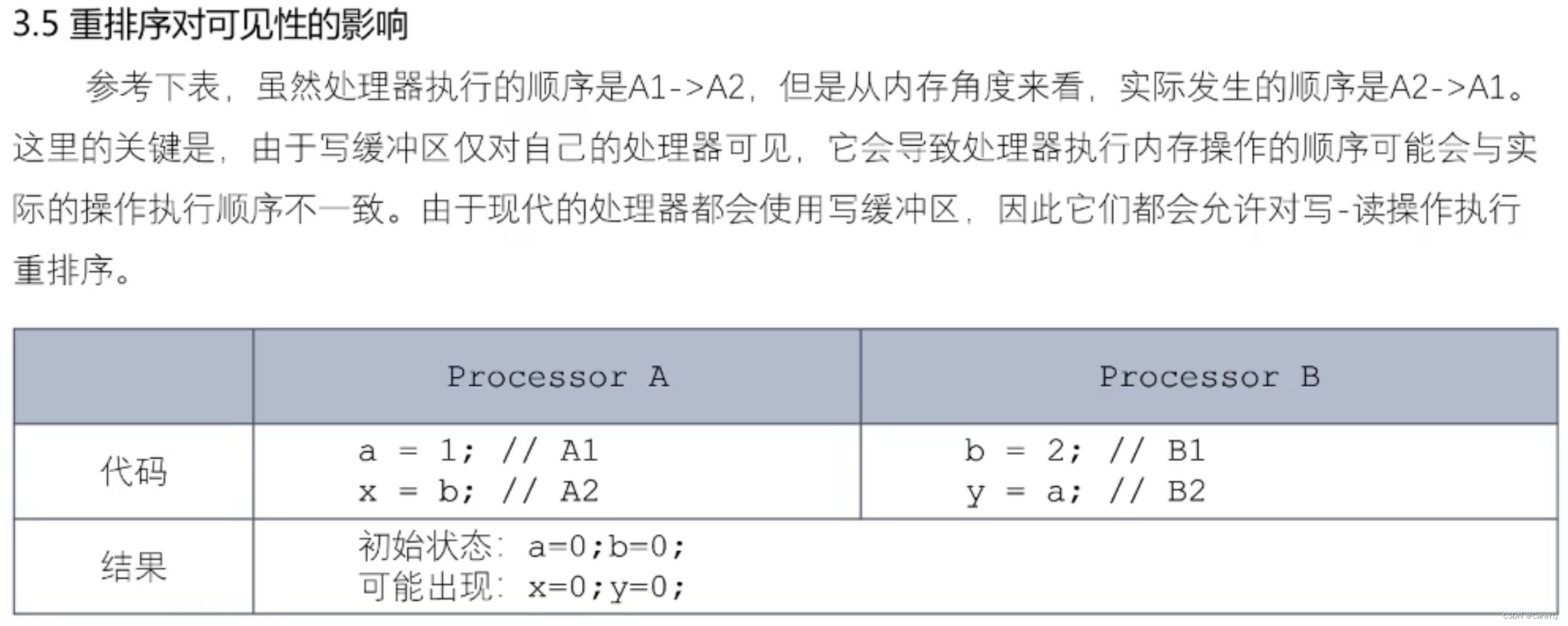
这是内存重排序的例子,执行线程a时,先执行A1,将数据刷到缓冲区A中,假如现在还没有将缓冲区A的内容同步到内存,然后执行A2,因为b是线程b的,所以需要去内存中取(线程A可能将b读到缓冲区A中,然后再去缓冲区A中取,但是不管怎么说都是去内存中取),然后将缓冲区A的内容同步到内存,此时从内存的角度来看,先执行A2再执行A1,因为A3是A1的延续,所以会出现x=0的情况,同理,y=0
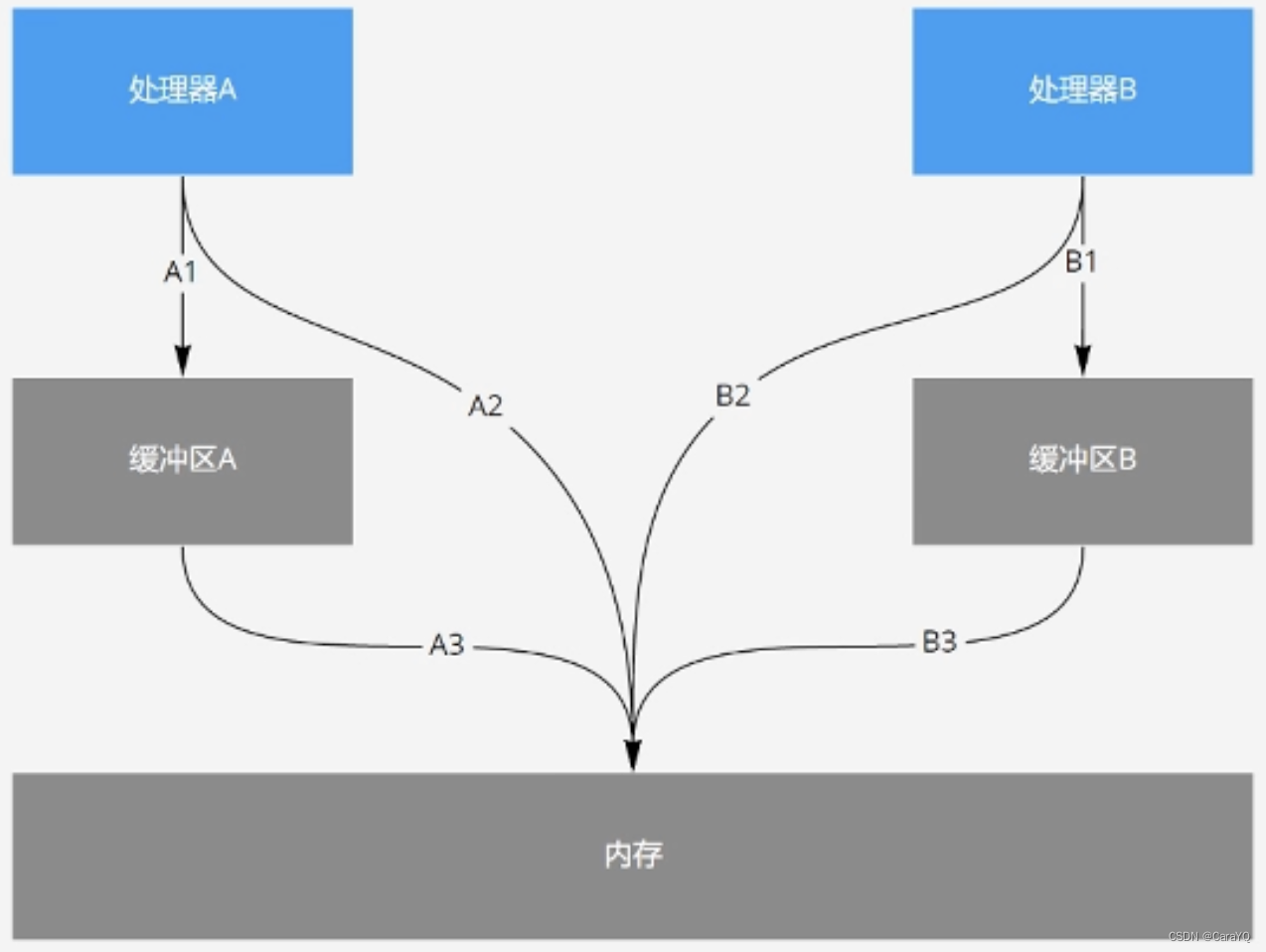



JMM可以解决内存可见性问题及编译器重排序问题:happens-before,
如果是cpu导致的重排序,通过内存屏障解决,如果是编译器导致的重排序,通过规则、JMM解决

总结:
- 并发编程的目标:解决通信同步的问题
- Java采用的并发编程模型是共享内存模型,该模型被称为JMM
- JMM解决了内存可见性问题,内存可见性问题就是两个线程谁先访问谁后访问的问题,即访问顺序问题
- 重排序有三种:编译器重排序、cpu重排序、内存系统重排序
- 如果是cpu导致的重排序,通过插入内存屏障解决,代码在unsafe类中,编译时插入内存屏障代码
- 如果是编译器导致的重排序,通过happens-before规则解决(6点)

写内存时,是立刻讲缓存中的数据刷新到主内存,读内存时,是直接从主内存中读

volatile只保证可见性不保证原子性,他只保证对单个变量读写的可见性(顺序/原子性)

可见性、有序性解决了,原子性也解决了