如果您觉得这篇文章有帮助的话!给个点赞和评论支持下吧,感谢~
作者:前端小王hs
阿里云社区博客专家/清华大学出版社签约作者/csdn百万访问前端博主/B站千粉前端up主
此篇文章是博主于2022年学习《Vue.js设计与实现》时的笔记整理而来
书籍:《Vue.js设计与实现》 作者:霍春阳
本篇博文将在书第4.8节的基础上进一步解析,附加了测试的代码运行示例,以及对书籍中提到的ES6中的数据结构及其特点进行阐述,方便正在学习Vue3或想分析Vue3源码的朋友快速阅读
如有帮助,不胜荣幸
前置章节:
- 深入理解Vue3.js响应式系统基础逻辑
- 深入理解Vue3.js响应式系统设计之栈结构和循环问题
- 深入理解Vue3.js响应式系统设计之调度执行

懒执行lazy的effect
经过前置的章节的学习,可以发现设计的effect都是立即执行的,而在4.8节的开始,作者向我们设计了一个可以按意愿时间节点执行的effect,其设计逻辑非常简单,就是在传递effect的options形参时添加内置lazy属性,然后再在effect函数内部进行判断,如果存在lazy,则返回effectFn给调用者。那么何时何地执行effectFn的决定权就到了调用者的手上
传递lazy代码如下:
effect(
// 指定了 lazy 选项,这个函数不会立即执行
() => {
console.log(obj.foo)
},
// options
{
lazy: true
}
)
完善判断lazy的effect代码如下:
function effect(fn, options = {}) {
const effectFn = () => {
cleanup(effectFn)
activeEffect = effectFn
effectStack.push(effectFn)
fn()
effectStack.pop()
activeEffect = effectStack[effectStack.length - 1]
}
effectFn.options = options
effectFn.deps = []
// 只有非 lazy 的时候,才执行
if (!options.lazy) {
// 执行副作用函数
effectFn()
}
// 将副作用函数作为返回值返回
return effectFn
}
那么现在,就可以使用一个变量去接收返回的effectFn,代码如下:
const effectFn = effect(() => {
console.log(obj.foo)
}, { lazy: true })
// 手动执行副作用函数
effectFn()
对于手动执行,我们可以使用res去接收调用函数的返回值,那么就需要在effect内return res,代码又得继续完善:
function effect(fn, options = {}) {
const effectFn = () => {
cleanup(effectFn)
activeEffect = effectFn
effectStack.push(effectFn)
// 将 fn 的执行结果存储到 res 中
const res = fn() // 新增
effectStack.pop()
activeEffect = effectStack[effectStack.length - 1]
// 将 res 作为 effectFn 的返回值
return res // 新增
}
effectFn.options = options
effectFn.deps = []
if (!options.lazy) {
effectFn()
}
return effectFn
}
那么重点来了,lazy和本节要实现的computed的关系在哪?(建议看完整篇再回过来看这个问题)
原因在于computed内部使用lazy去封装了getter,什么是getter?我们接着继续看
getter
从实现层面上看,getter是computed接收的实参的昵称,代码如下:
function computed(getter) {...}
MDN的定义是:get 语法将对象属性绑定到查询该属性时将被调用的函数,有点抽象是不是?我们看文档中例子就行,代码如下:
const obj = {
log: ['a', 'b', 'c'],
get latest() {
return this.log[this.log.length - 1];
},
};
console.log(obj.latest);
// Expected output: "c"
可以看到,在obj中使用了get functonName(){}的写法,那么这个作用是什么呢?答案是可以利用obj.functionName去返回动态计算值的属性,特别是不想以显示的方式返回的时候
当然,我们会可能会想,这种方式好像跟直接写函数差不太多,即下列代码所示:
const obj = {
log: ['a', 'b', 'c'],
latest() {
return this.log[this.log.length - 1];
},
};
console.log(obj.latest());
// Expected output: "c"
区别在于使用get在调用时无需加(),使其看起来像调用一个属性,这样更简洁和更具有语义性,且要执行的逻辑只是计算内部的属性值,这就是使用get去计算的意义
实现computed
computed是Vue响应式的核心API,用于声明计算属性,计算属性是依赖于其他的属性依赖而存在的,如果其他的属性依赖变化了,那么就会触发computed进行重新计算,进而得到最新的计算属性,我们可以看下书中的示例,代码如下:
const sumRes = computed(() => obj.foo + obj.bar);
effect(() => {
// 在该副作用函数中读取 sumRes.value
console.log(sumRes.value);
});
// 修改 obj.foo 的值
obj.foo++;
在这段示例代码中,sumRes就是声明的计算属性,其依赖于obj.foo和obj.bar两个属性依赖,当obj.foo++执行后,会触发computed进而得到新的sumRes
需要注意的是,computed还具有缓存,即如果属于依赖不变的情况下,无论执行多少次,都不会触发computed的重新计算
那么computed是如何设计的呢?
其实读到这里,聪明的读者应该有个思路,就是sumRes就是getter所对应的obj,而sumRes.value就是触发了obj.getter,只不过这个getter是get value(){},也就是:
const sumRes = {
get value(){
return ...
}
}
初次实现computed
我们直接来看书中的源码是如何实现满足缓存的,代码如下:
function computed(getter) {
// value 用来缓存上一次计算的值
let value;
// dirty 标志,用来标识是否需要重新计算值,为 true 则意味着“脏”,需要计算
let dirty = true;
const effectFn = effect(getter, {
lazy: true
});
const obj = {
get value() {
// 只有“脏”时才计算值,并将得到的值缓存到 value 中
if (dirty) {
value = effectFn();
// 将 dirty 设置为 false,下一次访问直接使用缓存到 value 中的值
dirty = false;
}
return value;
}
};
return obj;
}
可以看到是添加了一个value变量存储getter计算过后的值,并设置了一个开关dirty,第一次为true即产生计算,而计算过后就会置为false,下一次读取时就不会重新计算
但现在又出现了一个问题,如果下次读取时obj.foo或obj.bar发生了变化呢?在哪里将dirty置为true?
别忘了我们还可以在effect中传入schedular,也就是在调度器中置为true,代码如下:
const effectFn = effect(getter, {
lazy: true,
// 添加调度器,在调度器中将 dirty 重置为 true
scheduler() {
dirty = true;
}
});
执行的逻辑(简化)是怎么样的?
- 读取
sumRes.value,触发getter getter执行时触发读取obj.foo和obj.bar- 此时
activeEffect栈顶的是封装了gettet的effectFn obj.foo和obj.bar与effectFn关联,执行完返回sumRes.value- 当触发
obj.foo改变时,取出封装了gettet的effectFn的执行 - 在
trigger中取出schedular执行,将ditry置为true
但现在,并不会重新输出sumRes.value的值
原因在于obj.foo和obj.bar关联的effect是封装了gettet的effectFn,也就是:
effect(() => obj.foo + obj.bar, {
lazy: true,
// 添加调度器,在调度器中将 dirty 重置为 true
scheduler() {
dirty = true;
}
});
只会重新执行() => obj.foo + obj.bar,而不是console.log(sumRes.value),所以下一步是要解决如何修改完obj.foo后能够重新执行console.log(sumRes.value)的问题
完善computed
其实设计的关键在于schedular,我们知道在trigger中,如果存在schedular会执行schedular而不是effectFn,所以可以在schedular中执行console.log(sumRes.value),但真正执行的其实是执行封装其的effectFn
那该如何拿到这个console.log(sumRes.value)呢?可以设计一个关联,就是obj.value与封装console.log(sumRes.value)这个effectFn的关联
我们知道,在执行完获取sumRes.value之后,此时此时activeEffect栈顶的是封装了console.log(sumRes.value)的effectFn,那么就可以在执行完获取sumRes.value之后调用track,代码如下:
const obj = {
get value() {
if (dirty) {
value = effectFn()
dirty = false
}
// 当读取 value 时,手动调用 track 函数进行追踪
track(obj, 'value')
return value
}
}
然后再在scheduler中,调用trigger,取出effectFn执行,代码如下:
// computed内
const effectFn = effect(getter, {
lazy: true,
scheduler() {
dirty = true;
trigger(obj, 'value')
},
});
那么现在,当obj.foo++时,就会重新执行console.log(sumRes.value),也就实现了当obj.foo或obj.bar变化时,会重新执行console.log(sumRes.value)这个effect的效果,具体的逻辑可看下图:
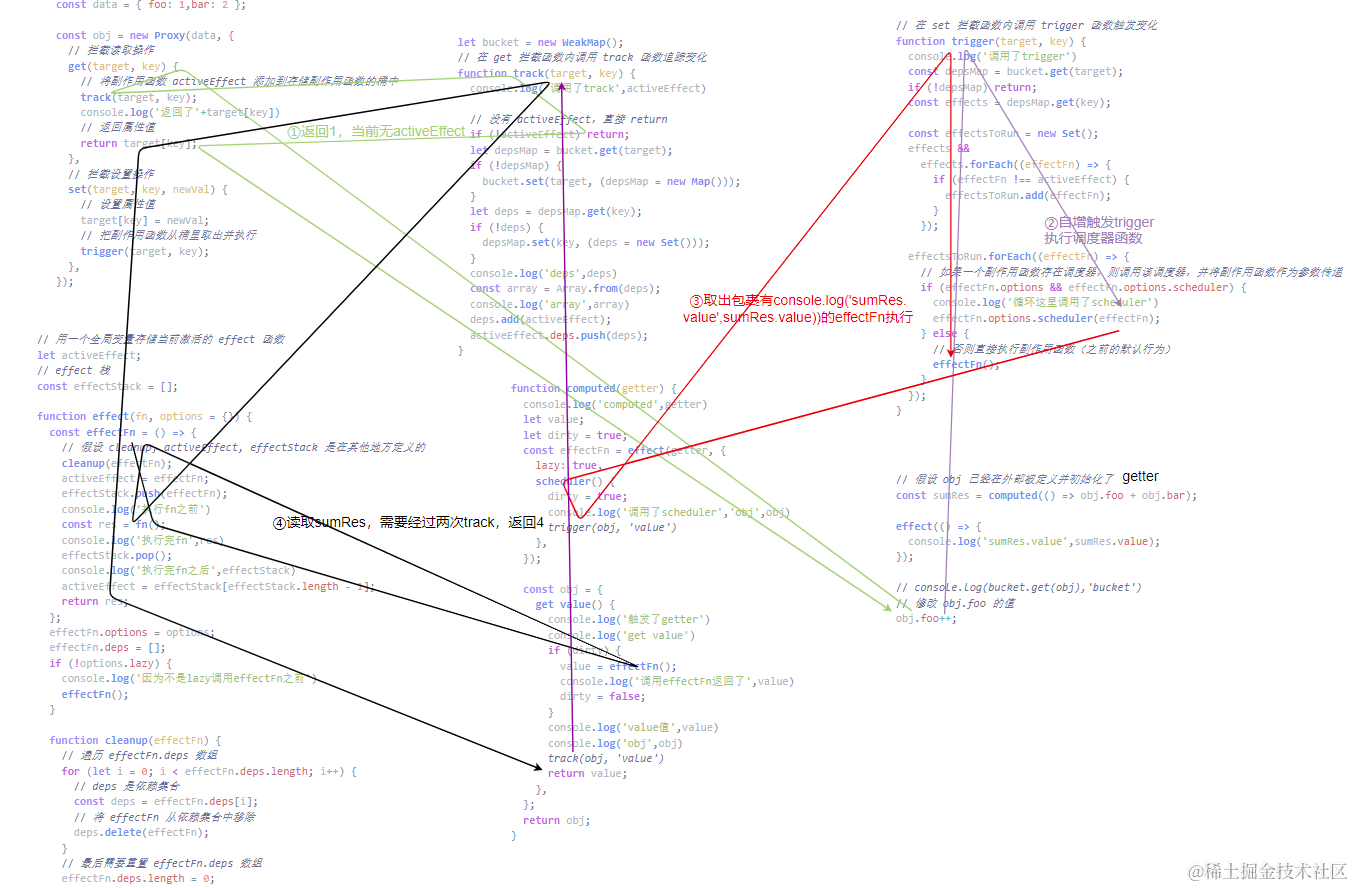
这就是整个computed的实现原理
小记
这是写的第四篇关于vue3.js响应式设计的内容了,但发现看的人还是比较少的,不管是评论还是收藏数都几乎为
0,不知道是写的不好还是其他的原因
写的初衷还是如同开头说的那般,书中即使讲的明白,但如果缺少一定的基础,在逻辑上还是比较难梳理的,写出来一方面是方便我自己复习,另一方面也是希望能够帮助到想了解或者进阶学习Vue的同学
关于这篇,如果认真阅读了,最起码可以达到以下效果
- 学会如何去实现懒执行函数
- 了解和学习什么是
getter - 知道Vue团队是如何设计和实现
computed的 - 响应式系统在
computed的实现逻辑 - 面试时问到上述也会答得出
- 其他…
谢谢大家的阅读,如有错误的地方请私信笔者
笔者会在近期整理后续章节的笔记发布至博客中,希望大家能多多关注前端小王hs!