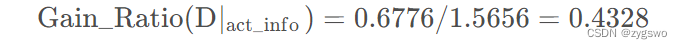一、redis是什么?
在认识redis之前,我们先说一下什么是NoSQL?
1. NoSQL
NoSQL,顾名思义就是不仅仅是SQL,泛指非关系数据库。
2. NoSQL的四大分类
(1)键值(key-value)存储数据库。我们今天所学的redis就是属于这个类型。
(2)列存储数据库
(3)文档型数据库。MongoDB
(4)图形数据库
3. redis的概念
redis是开源的,遵循BSD,基于内存数据存储,常被作为数据库、缓存、消息中间件。
总结:redis是一个内存型数据库。
4. redis的特点
reids是一个高性能的key-value内存型数据库,它支持丰富的数据类型,支持持久化,他是单线程、单进程。
二、reids的安装和设置
1.安装Redis依赖
yum install -y gcc tcl2. 上传安装包并解压
上传到/usr/local目录下,直接拖入即可。
解压缩:
tar -xzf redis-6.2.6.tar.gz进入redis目录:
cd redis-6.2.6运行编译命令:
make && make install启动:安装完成后,在任意目录输入redis-server命令即可启动Redis:
redis-server
出现上图说明启动成功。
这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
2.指定配置启动
1. 如果要让Redis以后台方式启动,则必须修改Redis配置文件,就在我们之前解压的redis安装包下(/usr/local/redis-6.2.6),名字叫redis.conf:
我们先将这个配置文件备份一份,当配置文件错误时可以使用
cp redis.conf redis.conf.bak然后我们修改redis.conf文件中的一些配置:
通过 /对应的词,可以找到位置,进行修改
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 123321启动Redis:
# 进入redis安装目录
cd /usr/local/bin
# 启动
./redis-server /usr/local/redis-6.2.6/redis.conf三、Redis的数据类型
他有五种基本数据类型和三种特殊数据类型。
我们主要学习五种基本数据类型,特殊数据类型知道即可。
redis在存储数据的时候是以键值对存在的。
key一般是String类型,不过value的类型多种多样,
1. String类型
常用于存储验证码
常用方法:
| 命令 | 说明 |
| set | 设置一个key/value |
| get | 根据key获得对应的value |
| setex | 设置一个key存活的有效期(秒) |
| decr | 进行数值类型的-1操作 |
| incr | 进行数值类型的+1操作 |
2. List类型
常用于商品列表
常用方法:
| 命令 | 说明 |
| lpush | 将某个值加入到一个key列表头部 |
| rpush | 将某个值加入到一个key列表末尾 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
| lrange | 获取某一个下标区间内的元素,从0开始 |
| llen | 获取列表元素个数 |
| lrem | 删除重复元素 |
| lindex | 获取某一个指定索引位置的元素 |
3. Set类型
常用于实现可能认识的人、共同好友
常用命令:
| 命令 | 说明 |
|---|---|
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素 无序 |
| scard | 返回集合中元素的个数 |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| sdiff | 求差集 |
| sinter | 求交集 |
| sunion | 求和集 |
4. ZSet类型
常用于实现排行榜
常用方法:
| 命令 | 说明 |
|---|---|
| zadd | 添加一个有序集合元素 |
| zcard | 返回集合的元素个数 |
| zrange 升序 zrevrange 降序 | 返回一个范围内的元素 |
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
| zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
5. Hash类型
他是key{ key value },无序的
常用方法:
| 命令 | 说明 |
|---|---|
| hset | 设置一个key/value对 |
| hget | 获得一个key对应的value |
| hdel | 删除某一个key/value对 |
| hexists | 判断一个key是否存在 |
| hkeys | 获得所有的key |
| hvals | 获得所有的value |
| hincrby | 为value进行加法运算 |
| hincrbyfloat | 为value加入浮点值 |
6. 特殊数据类型
GEO BitMap HyperLog
四、持久化机制
1. RDB(快照):快照生成有两种方式,
第一种是客户端通过BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork来创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求。
第二种是客户端通过SAVE命令来创建快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应任何其他的命令。这个命令不常用,因为使用SAVE命令在创建快照完毕之前,redis处于阻塞状态,无法对外服务。
当服务器接收到关闭服务器的请求时,redis会执行一次save命令,阻塞所有客户端,不再执行客户端发送的任何命令,并且在save命令执行完毕之后关闭服务器。
2. AOF(只追加日志文件)
它可以将所有客户端执行的写的命令记录到日志文件中,AOF持久化会将被执行的写命令写到AOF的文件末尾,以此来记录数据发生的变化,因此只要redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集.
日志追加频率: everysec:让redis每秒对AOF文件进行同步;这样可以保证即使系统崩溃,用户最多丢失一秒以内的数据。但这样也会有一个问题,那就是持久化文件会变得越来越大,其中也有很多重复的操作,为了减少AOF文件的体积,就有了AOF重写机制,
2.1 AOF重写机制
他就是将整个内存中的数据库内容用命令的方式重写成一个新的aof文件,来替换原来的文件,之后的写命令就开始往新的aof文件中追加。
五、主从复制
为了解决数据的冗余备份,读写分离。他就是将主节点中所有数据都备份给子节点,之后主节点每执行一次写操作,然后将写的数据都发送给子节点,让子节点读取数据,以保证数据的一致性。
六、哨兵机制
在主从模式的情况下,如果主节点发生意外宕机或者处理速率降低,哨兵节点就可以对这种情况进行监控,如果发送这种情况,他就会在从节点中推举出一个从节点去当新的主节点,而其他从节点就会成为新主节点的从节点。当旧主节点恢复时,他也会成为新主节点的从节点。
推举制度:首先是看配置的replica-priority,参数越小,优先级越高,然后选偏移量越大(同步数据越多),最后run id小的。
七、延迟双删
他是为了保证在进行修改或者删除时,redis中的数据和数据库数据保持一致。当用户进行修改或者删除操作时,先将redis中的缓存删除,再进入数据库进行对应操作,这时候如果有其他用户进来读取了这条信息,那么这条信息就会重新加载到redis缓存中。所以当数据库操作完之后,需要再进行一次对缓存的删除。从而保证数据库和缓存的一致性。
八、redis缓存问题
1.缓存穿透
客户端请求的数据,在数据库和redis中都不存在,这样缓存永远都不会生效,请求最终都到了数据库上。
解决方法:
-
当在数据库查询的结果也不存在的时候,可以返回null值给redis,并且设置TTL
- 布隆过滤器是一种数据结构,底层是位数组,通过将集合中的元素多次hash得到的结果保存到布隆过滤器中。主要作用就是可以快速判断一个元素是否在集合里面,但是因为算法的原因,也有一定概率的错误。
2. 缓存击穿
也叫热点key问题,一个被高并发访问且业务复杂的key突然失效了,无数的请求瞬间给数据库带来的巨大冲击
解决方法:
互斥锁 逻辑过期
3. 缓存雪崩
同一时间段内,大量的缓存key失效或者redis宕机,到时大量的请求到达数据库,带来巨大的压力。
解决方法:
- 给key设置随机的TTL
-
集群方案防止宕机不可用