元学习:训练训练神经网络的神经网络
本文基于清华大学《深度学习》第12节《Beyond Supervised Learning》的内容撰写,既是课堂笔记,亦是作者的一些理解。
1 Meta-Learning
在经典监督学习中,给定训练数据 { ( x i , y i ) } i \{(x_i,y_i)\}_i {(xi,yi)}i,我们需要训练一个神经网络 f f f使得 f ( x i ) = y i f(x_i)=y_i f(xi)=yi,而在测试的时候给一组新的 { x i } i \{x_i\}_i {xi}i,我们需要准确预测这组 { x i } i \{x_i\}_i {xi}i对应的 y y y.
在元学习中,问题变得不太一样。
训练数据 D \mathcal{D} D是一个任务 T T T的集合
- 其中 T = { S T , B T } = { ( x i S , y i S ) i , ( x j B , y j B ) j } T=\{S_T,B_T\}=\{(x_i^S,y_i^S)_i,(x_j^B,y_j^B)_j\} T={ST,BT}={(xiS,yiS)i,(xjB,yjB)j}。
- T T T由 S T S_T ST和 B T B_T BT组成, S T = { ( x i S , y i S ) } i S_T=\{(x_i^S,y_i^S)\}_i ST={(xiS,yiS)}i是一些训练样例, B T = { ( x j B , y j B ) } j B_T=\{(x_j^B,y_j^B)\}_j BT={(xjB,yjB)}j是测试样例。
- 也就是说训练数据中的每个任务是一个独立的问题,这个问题由一些训练样例和测试样例刻画。
在测试的时候,模型将会获得一个任务 T T T的 S T S_T ST,并希望回答 B T B_T BT中的问题,即返回 y j B y_j^B yjB给定 x j B x_j^B xjB。我们希望训练一个模型使得它能够快速地通过 S T S_T ST中的几个样例回答 B T B_T BT的问题,尽管测试时的 T T T和训练时的 T T T可能不太一样。
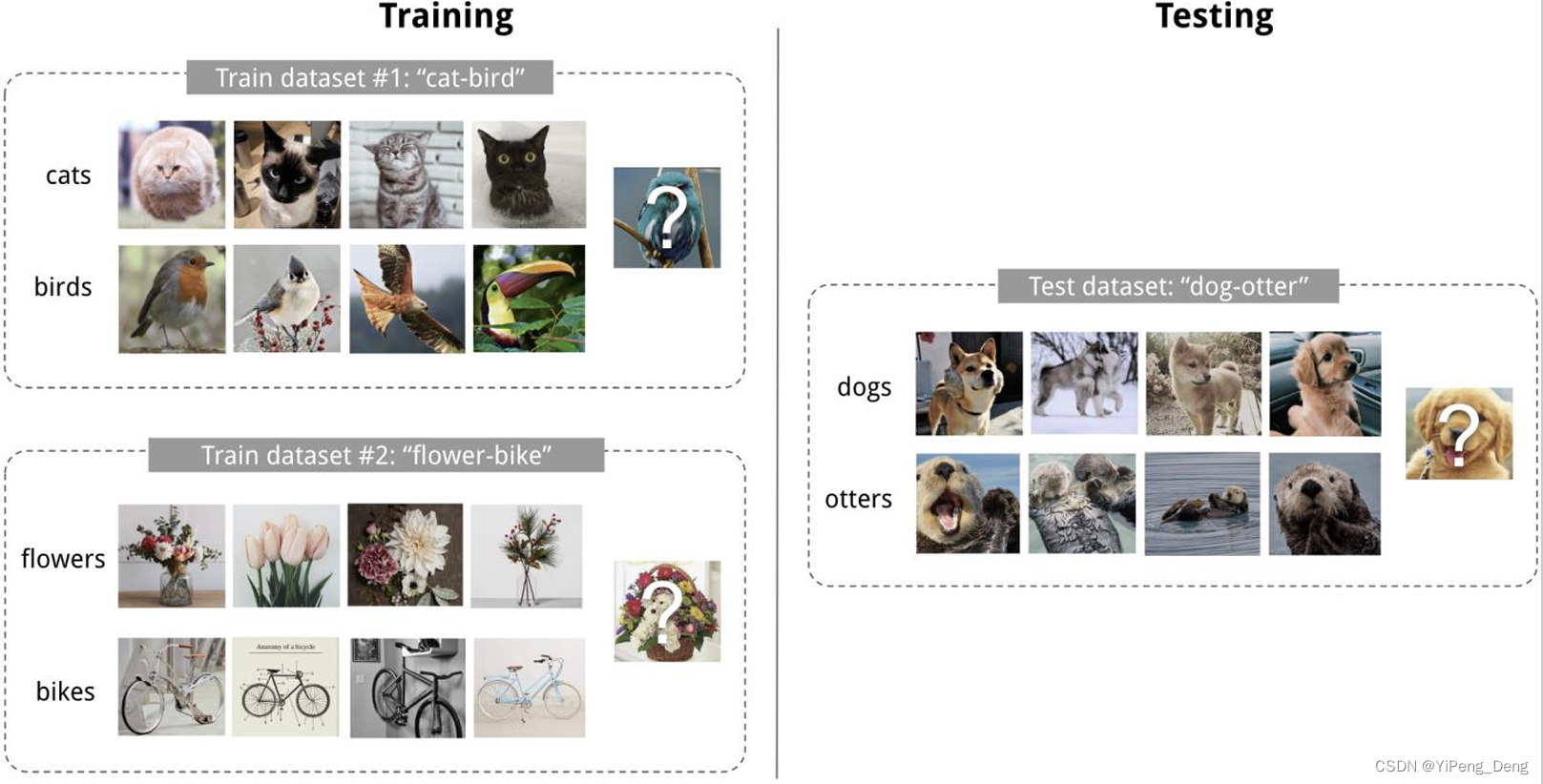
- 举个例子,如下图所示,在训练的时候一个任务是分辨猫和鸟,一个任务是分辨花和单车,而在测试的时候任务就变成了分辨狗和水獭。这要求模型学会在非常有限的样例中学会回答问题。
- 又比如:你有很多门考试,你需要强化自己的能力使得你在一门新的科目上只需要看几张考卷就能够回答问题。
这就是元学习(Meta Learning)。这种少样本的泛化能力也被称作Few-shot Learning.
接下来将介绍几个元学习的模型。
1.1 度量学习 Metric Learning
度量学习(Metric Learning)是使用最近邻居分类(Nearest Neighbor Classifier)来完成上述的问题。
- 最近邻居分类:对于一个测试样例,在训练数据中找到与它最“像”的样例,输出这个最“像”的样例的标签。
- 例如:在猫和鸟的分类中,给一张图片,看看在训练数据中与它最像的图片是猫还是鸟。
如何评判最“像”?学习一个度量(Metric) D ( x , x ′ ) D(x,x') D(x,x′).
- 例如:欧几里得距离(越小代表 x x x和 x ′ x' x′越像)
Siamese Nerual Network[1] 在2015年就使用了度量学习以解决少样本图像分类的问题:
- 度量被定义为 f ( x , y ) = σ ( W ∣ ϕ ( x ) − ϕ ( y ) ∣ ) f(x,y)=\sigma(W|\phi(x)-\phi(y)|) f(x,y)=σ(W∣ϕ(x)−ϕ(y)∣)
- 这里 ϕ ( x ) \phi(x) ϕ(x)将原图映射到了表征空间中,过了一个权重矩阵 W W W后经过sigmoid输出 x , y x,y x,y标签相同的概率。
- 在一个任务中,定义 ( x i S , y i ) (x_i^S,y_i) (xiS,yi)为第 i i i个训练样例,对于测试样例 x x x,它将被分类为 y = y arg max i f ( x , x i S ) y=y_{\arg\max_if(x,x_i^S)} y=yargmaxif(x,xiS).
Matching Network[2] 在2016年引入了注意力机制(Attention)将最近邻居分类进行了加权:
- 与上一个网络类似,对于测试样例 x x x和训练样例 x i S x_i^S xiS,分别计算它们的表征向量(embedding) f θ ( x ) f_\theta(x) fθ(x)和 g θ ( x i S ) g_\theta(x_i^S) gθ(xiS)。
- 在分类的时候不是直接 arg max \arg\max argmax,而是根据 α i = s o f t m a x ( g i ⊤ f ) \alpha_i=\mathrm{softmax}(g_i^\top f) αi=softmax(gi⊤f)计算 x i S x_i^S xiS的权重,最终分类结果为 y = ∑ i α i y i y=\sum_{i}\alpha_iy_i y=∑iαiyi(这里可以简单假设 y i ∈ [ 0 , 1 ] y_i\in[0,1] yi∈[0,1]为二分类问题)。
- 可以将 f θ f_\theta fθ用LSTM模型计算,即 f θ = f θ ( x , S ) = L S T M θ ( S , x ) f_\theta=f_\theta(x,S)=LSTM_\theta(S,x) fθ=fθ(x,S)=LSTMθ(S,x),这样可以使 f θ f_\theta fθ对于不同的任务有不一样的结果(增强了表达能力)。对 g θ g_\theta gθ同理。
1.2 贝叶斯推断 Bayesian Inference
贝叶斯推断(Bayesian Inference)的核心思路在于学习一个概率模型 P θ ( x , y ) P_\theta(x,y) Pθ(x,y)表示 x x x(输入样例)和 y y y(样例的标签)的联合分布。 P θ ( x , y ) P_\theta(x,y) Pθ(x,y)具有一些简单的结构使得我们能够在上面计算一些概率(例如:一个有向无环图,每个节点是一个事件,每个边上表示一些条件概率)。
在训练的时候希望最大化 ∑ i log P θ ( x i S , y i S ) \sum_i\log P_\theta(x^S_i,y^S_i) ∑ilogPθ(xiS,yiS)。在测试的时候找到满足后验概率 P θ ( y ∣ x , S ) P_\theta(y|x,S) Pθ(y∣x,S)最大的 y y y。
构建贝叶斯模型的通用方法是Probabilistic Programming(如:Church)。
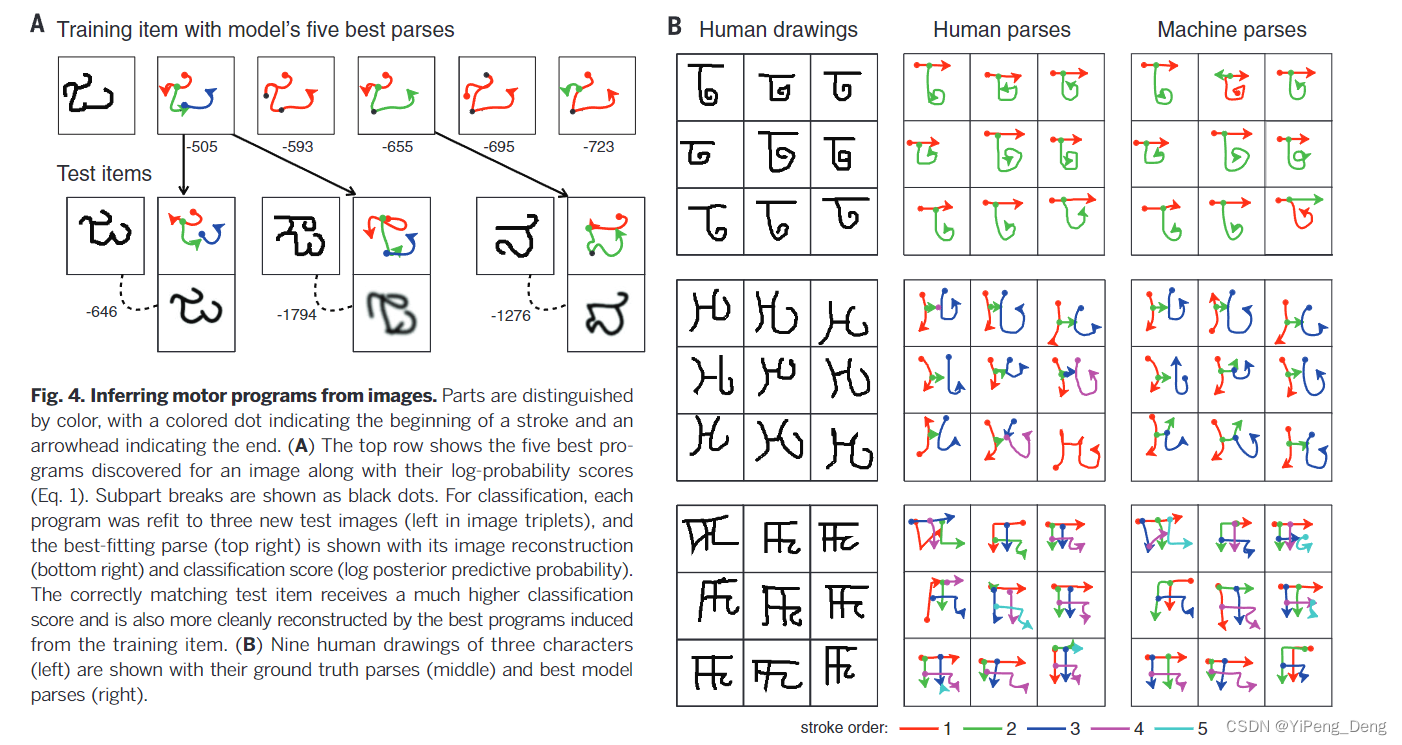
例如在Lake在2015年的 一篇工作[3] 就使用概率模型实现了人类水平的概念学习。以手写字符作为例子(如下图所示),简单来说:
-
每个字符可以分解成一些基本部件(如线条、曲线)
-
每个部件组合成字符的不同部分(如数字"3"由两个向右的半圆组成)
-
不同部件之间有连接关系(如写数字"3"的时候先写上面的半圆、再写下面的半圆)
-
概率模型就是通过建模这个写字的过程一步步地"写"出了一个字
1.3 序列模型 Sequence Model
一个简单的想法是直接把所有的训练数据排成一个序列丢给递归神经网络(Recurrent Nerual Network),然后直接输出测试样例的标签,即学习
f
θ
(
x
∣
S
)
=
L
S
T
M
(
x
1
S
,
y
1
S
,
.
.
.
,
x
N
S
,
y
N
S
,
x
)
f_\theta(x|S)=LSTM(x_1^S,y_1^S,...,x_N^S,y_N^S,x)
fθ(x∣S)=LSTM(x1S,y1S,...,xNS,yNS,x)
最早由Memory-Augmented Neural Networks (DeepMind, ICML 2016)[4] 提出了这种模型。
事实上,将训练数据排成序列的方法也能够直接应用在GPT等大语言模型(同时也是序列模型),这使得大语言模型具备一定的少样本学习的能力。
1.4 梯度下降 Gradient Descent
在模型训练的时候我们都要使用梯度下降,但在少样本学习的时候训练数据太少,仅仅基于很少的样本难以训练一个模型。
如果我们想基于新任务非常有限的样本进行梯度下降,初始的网络就非常关键。我们希望先在很多任务上训一个好的神经网络,在新的少样本任务中只需要进行很少的梯度下降(即微调)就能够达到很好的效果。
- 这就像一个人已经见过很多的任务、学到很多知识了。此时他面对新的任务时只需要再稍微学习一下就可以了。
模型无关元学习(Model-Agnostic Meta-Learning, MAML)[5] 首次提出了基于一个好的初始参数,在新的任务下再进行梯度下降以微调的方法。
- 在训练的时候,如何才能找到一个好的初始化参数呢?
- 答:找到一个参数使得所有任务经过几步梯度下降就能有好的结果。
- 多步随机梯度下降(SGD)太难计算了,怎么求导?
- 答:只进行一步随机梯度下降,这样模型的计算就是固定的了。
2020年,Sun进一步提出了测试时训练(Test Time Training)[6] 的方法:
- 在过去的任务中,模型仅仅通过在训练任务上进行训练,然后固定参数再完成测试任务。
- 在这个工作中提出了在完成测试任务的时候进行自监督学习以加强模型能力的方法。
- 打个比方:
- 过去的模型先是做了很多科目的考试,然后再去做另一个科目的测试,但是在测试的时候会忘记每一道刚刚回答的题目。
- 而现在的模型在做新的科目的测试时,它将每一道题的题面也加入到了训练中,相当于是它能够从考卷中也学习到东西(尽管没有标准答案,也能通过自监督学习的方式“自己考自己”),这样模型就变得更强了。
2 Learning to Learn
在元学习中另一个有趣的话题是如何Learn to learn,即通过神经网络来学习如何学习一个神经网络(套娃),例如学一个网络的结构、学一些超参数等等。
2.1 学习梯度下降
《Learning to learn by gradient descent by gradient descent》[7]首次提出了用一个神经网络(元优化器)来学习如何优化另一个神经网络(任务网络)的参数。元优化器通过观察任务网络的梯度信息来调整其参数,从而实现更高效的学习和收敛。具体来说:
- 学了一个LSTM模型的优化器(optimizer)
m
ϕ
(
∇
θ
)
m_\phi(\nabla _\theta)
mϕ(∇θ)负责更新
θ
\theta
θ:
- θ k + 1 = θ k + m ϕ ( ∇ θ ) , ∇ θ = ∂ L ( X , Y , θ ) ∂ θ \theta^{k+1}=\theta^k+m_\phi(\nabla_\theta),\nabla _\theta=\frac{\partial L(X,Y,\theta)}{\partial \theta} θk+1=θk+mϕ(∇θ),∇θ=∂θ∂L(X,Y,θ)
Google Brain于2017年在《Learned Optimizers that Scale and Generalize》[8] 进一步优化了基于神经网络的优化器的架构。
Quoc Le于2017年在《Neural Optimizer Search with Reinforcement Learning》[9]中将强化学习应用在优化器上,在自然语言处理任务与图像识别任务上表现很好。
2.2 学习损失函数
我们甚至可以使用强化学习来学习损失函数。
- RL^2(OpenAI, 2017)[10] 使用LSTM来评估当前状态、调整策略,使内层强化学习代理能够在新任务上快速适应和学习。
- Evolved Policy Gradient (OpenAI, 2018)[11] 使用进化算法来学习强化学习的损失函数,损失函数通过神经网络表示。
- Meta-Gradient Reinforcement Learning (DeepMind 2020)[12] 提出了一种元梯度强化学习(Meta-Gradient Reinforcement Learning, MGRL)的方法,该方法通过优化元参数(meta-parameters)来提高强化学习算法的表现。
2.3 学习数据集
我们甚至可以学习数据集!
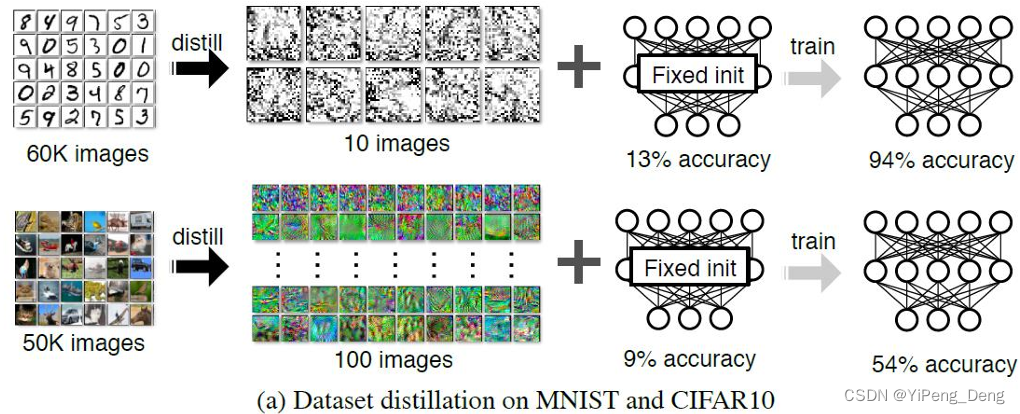
Dataset Distillation (Wang et al, MIT & Berkeley, 2018)[13] 提出了基于梯度下降的数据蒸馏的框架:
- 对于一个很大的数据集和一个模型,我们可以基于这个数据集训练出一个很小的数据集,使得这个很小的数据集和很大的数据集在这个模型上的效果差不多。这有利于加快模型的训练。
- 如下图所示,我们可以从MNIST数据集中合成出10张图片就可以训练出
94
%
94\%
94%正确率的模型
- 尽管合成的数据“看起来”并没有什么意义。
2.4 学习神经网络结构
我们还可以通过神经网络学习神经网络的架构!
NAS-RL(Zoph and Le, ICLR 2017)[14] 提出了一种基于强化学习(Reinforcement Learning, RL)的神经架构搜索(Neural Architecture Search, NAS)方法。该方法通过训练一个RNN控制器来自动生成神经网络架构,并使用强化学习算法优化控制器,使其生成的架构在目标任务上表现最佳。
3 总结
本文简单介绍了两类与Learn to Learn有关的问题
- 元学习(Meta-Learning)或少样本学习(Few-Shot Learning)
- 少样本学习在大模型强大的Few-Shot能力下已经成为主流,在很多下游任务上大放异彩。
- Learn to learn nerual network by nerual network:即通过神经网络来优化训练神经网络的过程
- 由于效率不高,再套一层娃(Learn to learn to learn) 的效果也并不好。
- 由于Learn to learn复杂的结构和极高的算力要求,如今主流的神经网络并没有采用此类的方法。
Reference
[1]Koch, G., Zemel, R., & Salakhutdinov, R. (2015). Siamese Neural Networks for One-shot Image Recognition. In Proceedings of the 32nd International Conference on Machine Learning (ICML).
[2]Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., & Wierstra, D. (2016). Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems (NIPS).
[3]Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266), 1332-1338.
[4]Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., & Lillicrap, T. (2016). Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML).
[5]Finn, C., Abbeel, P., & Levine, S. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML).
[6]Sun, Y., Liu, X., Harada, T. (2020). Test-Time Training with Self-Supervised Learning. In Proceedings of the 37th International Conference on Machine Learning (ICML).
[7]Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M. W., Pfau, D., Schaul, T., … & de Freitas, N. (2016). Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems (NIPS).
[8]Wichrowska, O., Maheswaranathan, N., Hoffman, M. W., Colmenarejo, S. G., Denil, M., Freitas, N. D., & Sohl-Dickstein, J. (2017). Learned Optimizers that Scale and Generalize. In Proceedings of the 34th International Conference on Machine Learning (ICML).
[9]Bello, I., Pham, H., Le, Q. V., Norouzi, M., & Bengio, S. (2017). Neural Optimizer Search with Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning (ICML).
[10]Duan, Y., Schulman, J., Chen, X., Bartlett, P., Sutskever, I., & Abbeel, P. (2017). RL^2: Fast Reinforcement Learning via Slow Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning (ICML).
[11]Houthooft, R., Chen, X., Duan, Y., Schulman, J., De Turck, F., & Abbeel, P. (2018). Evolved Policy Gradients. In Proceedings of the 35th International Conference on Machine Learning (ICML).
[12]Xu, Z., van Hasselt, H., & Silver, D. (2020). Meta-Gradient Reinforcement Learning. In Advances in Neural Information Processing Systems (NeurIPS).
[13]Wang, T., Zhu, J.-Y., Torralba, A., & Efros, A. A. (2018). Dataset Distillation. In Proceedings of the 35th International Conference on Machine Learning (ICML).
[14]Zoph, B., & Le, Q. V. (2017). Neural Architecture Search with Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations (ICLR).