自监督学习
本文基于清华大学《深度学习》第12节《Beyond Supervised Learning》的内容撰写,既是课堂笔记,亦是作者的一些理解。
在深度学习领域,传统的监督学习(Supervised Learning)的形式是给你输入 x x x和标签 y y y,你需要训练一个基于参数 θ \theta θ的神经网络 f θ ( x ) f_\theta(x) fθ(x)使其能够预测 y y y,即 f θ ( x ) ≈ y f_\theta(x)\approx y fθ(x)≈y.
- 例如:给你一些猫猫狗狗的图片,在训练数据中你能够知道一些图片对应的是猫还是狗,模型需要基于训练数据进行训练,并在遇到一个新的图片 x x x时返回是猫还是狗。
在监督学习中,最为重要的就是高质量的带标注的数据,数据的质量往往直接影响模型的性能,然而带人工标注的数据往往十分昂贵、很难获取。如何获得带标注的数据也是传统监督学习最为重要的问题之一。
为了能够在缺乏数据标注的情况下训练模型,无监督学习(Unsupervised Learning)应运而生。无监督学习的核心思想在于通过人为地引入一些先验知识指导模型进行学习(下文会更详细地讲解)。本篇文章就将简单梳理在无监督学习方向人们做出的努力。
1 表征学习 Representation Learning
无监督学习本质上是在学习表征(Representation)。什么是表征呢?
- 现实世界中的数据往往具有很高的维度以及特定的结构,例如一张图片的像素是 1024 × 1024 1024\times1024 1024×1024。尽管一张图片的规模过于庞大( 1024 × 1024 1024\times1024 1024×1024维),但一张有意义的图片并不需要那么多维表示(可以想象,你逐像素地随机一张 1024 × 1024 1024\times 1024 1024×1024的图片,几乎没有任何意义,而有意义的图片往往只有极其少数)。
- 因此,我们可以在一个低维空间找到高维数据的抽象表示,使得模型能够从这个抽象表示中还原出原本的数据,这个低维空间的向量就被称作一个数据的表征(Representation)。
在无监督学习的任务之下,给模型一堆不具有标签的数据,模型需要学习出这些数据之间潜藏的内在关联。而在深度学习中主要的无监督模型就是生成模型(Generative Model):
- 任务:你需要学习数据的分布,生成与训练数据相似的新数据
- 例如:给你一堆猫猫狗狗的图片,你需要生成一张新的猫猫狗狗的图片。
- 方法:在生成模型(Generative Model)中,我们可以通过编码器(Encoder)将图片编码为一个低维向量(表征),再通过解码器(Decoder)将图片从低维向量中还原。
- 这里的编码器和解码器都是一个神经网络,可以看作可训练的黑盒子。
- 事实上,有很多种类的生成模型:EBM,VAE,FLOW,GAN…
在这个过程中,由于我们能够从表征中还原数据,因此表征某种意义上也代表了一个数据。如果我们有一个好的表征,我们期望在表征空间中能够涌现更多能力。
- 例如在生成图片的时候,一个好的表征方式会使得同一类的图片对应的表征比较接近,从而给予了模型“分类”的能力。
2 自监督学习 Self-Supervised Learning
在无监督学习中,我们的任务是学习给定的数据内在的联系。更进一步的,我们能不能人为构造一些任务,使得模型能够学到更好的表征呢?这就是自监督学习(Self-Supervised Learning).
在自监督学习的板块,我将介绍两种不同的思路,分别是构造标签(Prediction-Based Supervised Learning)和对比学习(Contrastive Learning)。
2.1 构造标签
既然无监督学习的任务中不具有数据标签(Label),那么我们能不能自己构造一些标签将无监督学习转化为有监督学习呢?这便是自监督学习早期的思路:
- 通过数据增广(Data Augmentation)构造判别式的任务,再通过任务生成好的表征。
- 最终的目的仍然是生成好的表征(representation)以支持下游任务。
由于这个方法实际上将无监督学习转化为了有监督学习,模型的输出仍然是”预测“一个标签,因此也称这种方法为Prediction-Based Supervised Learning.
接下来将简单介绍一些自监督学习的模型以及其任务的构造方式。
2.1.1 Word2Vec
在自然语言处理(NLP)领域中最为重要的工作就是2013年由Google的Tomas Mikolov团队提出的Word2Vec[1]。Word2Vec基于大规模的语料库学习了每个词的表征,即学习了每个word对应的vector。
- 任务:对于语料库的每一句话,挖掉其中的一个单词,再令模型通过上下文预测这个单词。
2.1.2 Bert
更进一步的,Google在2018年提出了一种基于Transformer架构的预训练语言模型BERT[2]. BERT通过Transformer编码器同样能够将单词序列转化为向量表征。相比Word2Vec,BERT能够更好地关注全局上下文的信息。
- 任务:对于语料库的每一句话,挖掉其中的部分单词(Mask机制),再令模型通过上下文预测这些单词。
2.1.3 Context Prediction
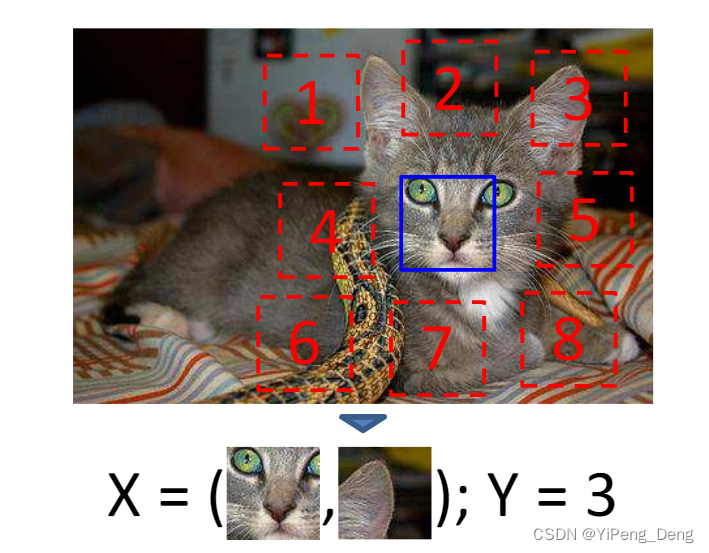
在图像处理领域,Pathak在2015年提出了Context Prediction[3]。该方法通过预测图块的相对位置来训练神经网络,从而在无标签数据中学习有用的图像表征。通过这种方式训练出的模型具备一定的拼图能力。
- 任务:将每张图片分割为很多小patch,输入两个patch,模型需要预测这两个patch的相对位置,从而使模型能够很好地学到每个patch的表征。如下图所示:
2.1.4 Inpainting
更进一步的,Pathak在2016年提出了自监督任务Inpainting[4],即通过随机图像修补的任务提高了GAN修补图像 的质量。
- 任务:随机挖掉一个patch的图片,让GAN去重新画,希望画的离原先的比较近。
2.1.5 Image Colorization
给你一张灰白图片,人往往能够想象出它真正的颜色是什么。因此将色彩作为任务也能够学到好的表征。Richard Zhang在2016年提出了一种自动图像上色的方法**[5]**,使用卷积神经网络(CNN)来为灰度图像生成彩色版本,实现了高质量的图像上色。
- 任务:输入灰度图像预测彩色图像+输入彩色图像预测灰度图像。如下图所示。

2.1.6 Rotation Prediction
人在看东西的时候总是有方向性的,同一个物体在不同方向上感觉并不一样。如果一个人能够认识某个物体,那么他一定能够认识这个物体的方向。带着这个“先验知识”我们可以给所有图片一个“方向”的标签,这就是Rotation Prediction[6]. 通过下图的Attention Map(越亮表示模型越关注这个地方),可以发现通过这种方式训练出来的模型能够对图片的关键点有更好地把握。
- 任务:将数据集的图片进行0、90、180、270度的旋转,让模型预测旋转了多少度。

2.2 对比学习 Contrastive Learning
除了构造任务预测标签以外,另一种重要的自监督学习方式是对比学习(Contrastive Learning)。
对比学习,顾名思义就是在训练集中同时存在正例与负例,模型的训练目标在于提高正例、抑制负例。
在自监督学习中,对比学习的关键在于构造正例与负例。
2.2.1 Contrastive Predictive Coding
将对比学习应用在时序预测就得到了对比预测编码(Contrastive Predictive Coding,CPC)[7]。具体来说,对于一段音频信息,CPC将过去的音频编码为潜在表征,而后用潜在表征预测未来的音频。
CPC引入了Contrastive Loss:
L
N
=
−
E
X
[
log
f
k
(
x
t
+
k
,
c
t
)
∑
x
j
∈
X
f
k
(
x
j
,
c
t
)
]
L_N=-\mathbb{E}_X\left[\log\frac{f_k(x_{t+k},c_t)}{\sum_{x_j\in X} f_k(x_j,c_t)}\right]
LN=−EX[log∑xj∈Xfk(xj,ct)fk(xt+k,ct)]
- 这里 c t c_t ct就是过去的音频编码的潜在表征( t t t为时间), x t + k x_{t+k} xt+k是正例, X X X中其他的 x j x_j xj都是负例, f ( x j , c t ) f(x_j,c_t) f(xj,ct)是 x j x_j xj和 c t c_t ct的响应强度(例如:点积)。
- 因此Contrastive Loss的目标在于将正例的响应强度在所有例子中占比尽量大。
在CPC中,负例随机选取于其他的mini-batch或其他时间节点( x j ∣ j ≠ t + k x_j|_{j\neq t+k} xj∣j=t+k)
更进一步的,CPCv2[8] 基于patch的预测使得CPC能够作用在图像生成上,即通过之前的patch的表征预测生成下一个patch的图像。
2.2.2 Momentum Contrastive Learning
与CPC的对比学习的思路类似,Kaiming在2020年提出了动量对比学习(Momentum Contrastive Learning, MoCo)[9]。
- MoCo中将Contrastive Loss的响应强度当做了查询向量 q q q和键值向量 k k k的点积。即
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 K exp ( q ⋅ k i / τ ) L_q=-\log\frac{\exp(q\cdot k_+/\tau)}{\sum_{i=0}^K\exp(q\cdot k_i/\tau)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
- MoCo在CPC的基础上将所有负例的键值 k i k_i ki丢到了一个队列中,每次负例都是从队列中取,保证了采样负例的效率.
- 由于所有的键值是直接从队列中取的,为了保证过去已经存在队列中的 k i k_i ki与实际当前神经网络计算出的 k i k_i ki差别不要太大,MoCo引入了动量(momentum)来更新计算 k i k_i ki的网络。这使得计算键值的网络更新的比较慢,从而使得队列中的键值更加稳定。
2.2.3 SimCLR
SimCLR[10] 是一个简单的对比学习框架,用于学习图像的视觉表征。
-
SimCLR首先将图片做不同的变换(裁剪、高斯噪声、变色…),如下图所示。
-
根源相同的图片之间为正例,根源不同的图片之间为负例。
-
相比此前的所有做法,SimCLR并不需要单独采样一堆负例,仅仅需要对于同一个mini-batch中根源不同的图片计算代价即可。即对于一个mini-batch中根源相同的一对图片 i , j i,j i,j,它们的Contrastive Loss为:
L i , j = − log exp ( v i ⊤ v j / τ ) ∑ k ≠ i exp ( v i ⊤ v k / τ ) L_{i,j}=-\log\frac{\exp (v_i^\top v_j/\tau)}{\sum_{k\neq i}\exp(v_i^\top v_k/\tau)} Li,j=−log∑k=iexp(vi⊤vk/τ)exp(vi⊤vj/τ)

在SimCLR后MoCo也采用了类似的负例采样方式提高了性能,并通过一些改进相继提出了MoCo-v2,MoCo-v3.
此后Kaiming于2021年通过ViT的编码器架构提出了Masked AutoEncoder(MAE)[11],不过这属于自监督学习而非对比学习的范畴了。
2.2.4 Multi-Modal Contrastive Learning
在互联网上,许多图片都带着一些文本标注,尽管这些文本并不能指示出特定的类别,但也与图片有着直接的联系。利用好文本与图片的多模态(Multi-Modal)数据能够大大提高模型的性能。相当于是模型不但会看图还会读书,阅历与知识大大提高了。
在多模态模型中最为重要的是OpenAI在2021年发布的CLIP[12]。CLIP通过分别编码图像和文本,通过Contrastive Loss最大化匹配的图像和文本的相似性使得相似的图像和文本在表征空间中接近,不相似的图像和文本则远离。
如下图左侧,对比学习最大化了对角线上图像与文本表征的点积 I i ⋅ T i I_i\cdot T_i Ii⋅Ti,降低了不相干的图像文本的点积。
CLIP提出了一个新颖的对比学习框架,通过自然语言监督对齐图像和文本的表示。广泛的下游任务验证了模型的有效性,包括图像分类、对象检测、图像生成等。此后的风靡的图像生成模型Dall-E 2&3也是基于CLIP的架构。

3 总结
本文首先介绍了表征学习(Representation Learning)在无监督学习领域的重要性,而后大致介绍了自监督学习领域的一系列重要模型,主要由2类构成:
- 基于预测的自监督框架:即人工设计数据的标签。
- 对比学习框架:将匹配好的数据作为正样例,其他的数据作为负样例,扩大正样例的响应占比,从而在特征空间中学习到好的表征。
无论是基于预测的模型还是对比学习的自监督方法,本质上都是在于人为应用一些先验知识创造“监督信号”,例如:
-
图片旋转、剪切、加噪声后应该差不多
-
网络上的图片和备注的文本应该有关系
-
…
自监督学习应用广泛未经标注的数据提高了模型的表征学习能力和泛化性能,如今已经在计算机视觉、自然语言处理等领域取得了瞩目的成就,未来也有着十分广泛的发展空间。
Reference
[1]Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781.
[2]Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT).
[3]Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. (2015). Context prediction for unsupervised learning with data augmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) (pp. 1422-1430).
[4]Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. (2016). Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 2536-2544).
[5]Zhang, R., Isola, P., & Efros, A. A. (2016). Colorful Image Colorization. In European Conference on Computer Vision (ECCV) (pp. 649-666).
[6]Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised Representation Learning by Predicting Image Rotations. In International Conference on Learning Representations (ICLR).
[7]Van den Oord, A., Li, Y., & Vinyals, O. (2018). Representation Learning with Contrastive Predictive Coding. arXiv preprint arXiv:1807.03748.
[8]Van den Oord, A., Li, Y., & Vinyals, O. (2020). Representation Learning with Contrastive Predictive Coding. In International Conference on Machine Learning (ICML).
[9]He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[10]Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A Simple Framework for Contrastive Learning of Visual Representations. In International Conference on Machine Learning (ICML).
[11]He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2021). Masked Autoencoders Are Scalable Vision Learners. arXiv preprint arXiv:2111.06377.
[12]Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020.