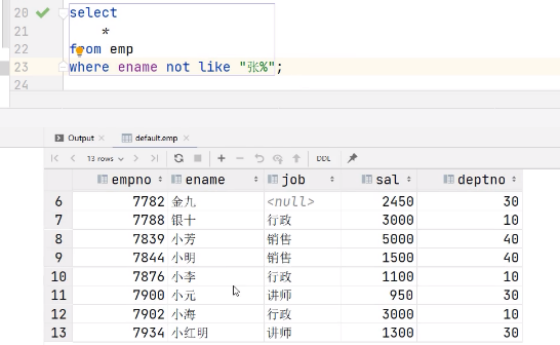
06-25 15:10:53.821 7449 7450 D dalvikvm: threadid=2: sending two SIGSTKFLTs to threadid=135 (tid=8021) to cause debuggerd dump
SIGSTKFLT 是 Dalvik 虚拟机特有的一个信号。当虚拟机发生了 ANR 或者需要做 GC 的时候,就需要挂起所有 RUNNING 状态的线程,如果此时 Dalvik 虚拟机等待了足够长时间,线程仍旧无法被挂起,就会调用dvmNukeThread函数发送 SIGSTKFLT 信号给相应线程,从而杀死 APP。
具体代码如下:
static void waitForThreadSuspend(Thread* self, Thread* thread)
{
constint kMaxRetries = 10;
… …
while (thread->status == THREAD_RUNNING) {
… …
if (retryCount++ == kMaxRetries) {
ALOGE(“Fatal spin-on-suspend, dumping threads”);
dvmDumpAllThreads(false);
/* log this after – long traces will scroll off log */
=> ALOGE(“threadid=%d: stuck on threadid=%d, giving up”,
self->threadId, thread->threadId);
/* try to get a debuggerd dump from the spinning thread */
=> dvmNukeThread(thread);
/* abort the VM */
dvmAbort();
… …
}
而从堆栈我们看出,杀死进程的时候,我们正调用DexFile.loadDex,这个方法最后会调用到dvmRawDexFileOpen里面,执行 write 操作。而这个 write 涉及 I/O 操作,是比较耗时的。所以,当线程在做 dexopt,长时间无法响应虚拟机的挂起请求时,就会触发这个问题。
一般来说,虚拟机在执行 Java 代码的时候,都会是 RUNNING 状态。而只要调用了 JNI 方法,在执行到 C/C++ 代码的时候,就会切换为 NATIVE 状态。而虚拟机只会在 RUNNING 状态下会挂起线程,如果是在 NATIVE 状态下,虚拟机是不会要求线程必须挂起的。
不过,这里有一个特殊之处。虽然DexFile.loadDex方法最终也走到了 JNI 里面调用dvmRawDexFileOpen函数,但由于DexFile类是虚拟机的内部类,Dalvik 虚拟机不会在内部类执行 JNI 方法的时候将线程切换为 NATIVE 状态,仍然会保持原来的 RUNNING 状态。于是,在 RUNNING 状态下,做 OPT 的线程就会被要求挂起。而此时由于正在执行耗时的 write 操作,无法响应挂起请求,便出现了如上的崩溃。
当然,可能有人会想到在 Native 代码中,用CallStaticObjectMethod来触发DexFile.loadDex,不过这种方式是不可行的。因为CallStaticObjectMethod调用 Java 方法DexFile.loadDex时,会使得状态再次切换为 RUNNING。
具体来看下 CallStatciXXXMethod 方法的定义处:
static _ctype CallStatic##_jname##Method(JNIEnv* env, jclass jclazz, \
jmethodID methodID, …) \
{ \
UNUSED_PARAMETER(jclazz); \
ScopedJniThreadState ts(env); \
JValue result; \
va_list args; \
va_start(args, methodID); \
dvmCallMethodV(ts.self(), (Method*)methodID, NULL, true, &result, args);\
va_end(args); \
if (_isref && !dvmCheckException(ts.self())) \
result.l = (Object*)addLocalReference(ts.self(), result.l); \
return _retok; \
}
关键在于 ScopedJniThreadState:
explicit ScopedJniThreadState(JNIEnv* env) {
mSelf = ((JNIEnvExt*) env)->self;
… …
CHECK_STACK_SUM(mSelf);
dvmChangeStatus(mSelf, THREAD_RUNNING);
}
~ScopedJniThreadState() {
dvmChangeStatus(mSelf, THREAD_NATIVE);
COMPUTE_STACK_SUM(mSelf);
}
在使用dvmCallMethodV调用 Java 方法前,会先切换状态为THREAD_RUNNING,执行完毕后,ScopedJniThreadState析构,再切换回THREAD_NATIVE。这样,JNI 执行DexFile.loadDex就和直接执行 Java 代码一样,状态会有问题。不只是CallStaticXXXMethod,所有使用CallXXXMethod函数在 Native 下调用 Java 方法的情况都是如此。
好在,我们想到了另一个办法:既然 Dalvik 不会对内部类的 JNI 调用做切换,我们就自己写一个 JNI 调用,使其走到 Native 代码中,这样线程就会变为 Native 状态,然后 直接调用虚拟机内部函数 做 dexopt 即可。这样在做 dexopt 的时候,始终会处于 NATIVE 的状态,不会切为 RUNNING,也不会被要求挂起,也就能避免这个问题。
这个虚拟机内部函数就是dvmRawDexFileOpen,我们先来看下它的代码说明:
/*
-
Open a raw “.dex” file, optimize it, and load it.
-
On success, returns 0 and sets “*ppDexFile” to a newly-allocated DexFile.
-
On failure, returns a meaningful error code [currently just -1].
*/
int dvmRawDexFileOpen(const char* fileName, const char* odexOutputName,
RawDexFile** ppDexFile, bool isBootstrap);
这个函数可以用来打开原始 DEX 文件,并且对它做优化和加载。对应到 libdvm.so 中的符号是_Z17dvmRawDexFileOpenPKcS0_PP10RawDexFileb,我们只需要用 dlsym 在 libdvm.so 里面找到它,就可以直接调用了,完整代码如下:
using func = int ()(constchar fileName, constchar* odexOutputName, void* ppRawDexFile, bool isBootstrap);
void* handler = dlopen(“libdvm.so”, RTLD_NOW);
dvmRawDexFileOpen = (func) dl
sym(handler, “_Z17dvmRawDexFileOpenPKcS0_PP10RawDexFileb”);
dvmRawDexFileOpen(file_path, opt_file_path, &arg, false);
这样,我们自己写一个 JNI 调用,在 Native 状态下执行上述代码,就能达到完成 ODEX 的目的,从而根本上杜绝这个异常了。
另外,我们把 dexopt 操作放到了单独进程执行,由此可以避免 ODEX 操作对主进程造成其他性能影响。此外,由于设备情况多种多样,运行环境十分复杂,还可能会有一些厂商魔改,导致的 dlsym 找不到_Z17dvmRawDexFileOpenPKcS0_PP10RawDexFileb符号,虽然这种情况极为罕见,但理论上仍有可能发生。单独进程里面由于环境比较纯粹,基本很少发生 ANR 和 GC 事件,挂起的情况就很少,也能最大程度规避这个问题。
我们发现,相比于官方 MultiDex 加载 ZIP 形态的 DEX 文件,非 ZIP 方式的 DEX(也就是直接对 DEX 文件做 ODEX,而不用先把 DEX 压缩进 ZIP 里面)对于整体时间也有一定程度的优化,因为这种非 ZIP 方式避免了原先的两个耗时:
-
把原始 DEX 压缩为 ZIP 格式的时间;
-
ODEX 优化的时候从 ZIP 中解压出原始 DEX 的时间。
非 ZIP 的方式相比于 ZIP 方式,整体耗时会减少 40% 左右,但是 DEX 文件磁盘占用空间比原先 ZIP 文件的方式增加一倍多。因此我们可以只在磁盘空间充裕的时候,优先使用非 ZIP 方式加载。
而我们openDexFile_bytearray加载 DEX 的方式,需要的只是原始 DEX 文件的字节数组(byte[])。这个字节数组我们在首次冷启动的时候是直接从 APK 里面解压提取得到的。我们可以在这次启动提取完成后,先把这些字节数组落地为 DEX 文件。这样如果再次启动 APP 的时候,ODEX 没做完,就可以直接使用前面保存的 DEX 文件来得到字节数组了,从而避免了从 APK 解压的时间。
总体来看,我们整套方案中一共存在四种形态的 DEX:
-
从 APK 文件里面解压得到的 DEX 字节数组;
-
从落地的 DEX 文件里面得到的 DEX 字节数组;
-
从 DEX 文件优化得到的 ODEX 文件;
-
从 ZIP 文件优化得到的 ODEX 文件。
生成各个产物的时序图如下所示:
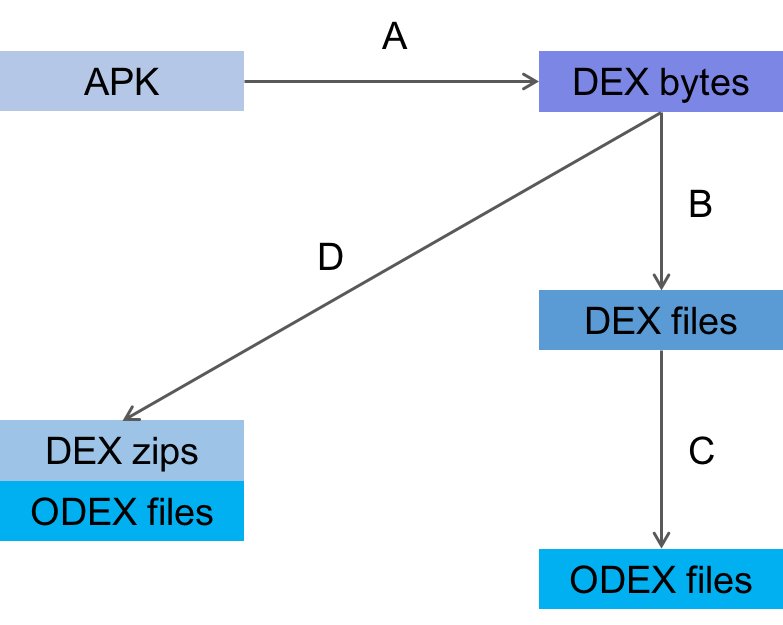
我们依次说明每一步:
-
A. 从 APK 里面直接解压得到 DEX 字节数组;
-
B. 将 DEX 数组保存为文件;
-
C. 用 DEX 文件生成 ODEX 文件;
-
D. 用 DEX 数组生成 ZIP 文件以及它对应的 ODEX 文件。
正常情况下,我们会依次按 A -> B -> C 的时序依次产生各个文件,如果中间有中断的情况,我们下次启动后会继续按照当前已有产物做对应操作。我们仅在磁盘空间不够,且所在系统不支持直接加载字节数组的情况下才会走 ZIP&ODEX 方式的 D 路径。这里不支持的情况主要是一些特殊机型,比如 4.4 却采用了 ART 虚拟机的机型、阿里 Yun OS 机型等。
接下来我们继续看下加载流程图:
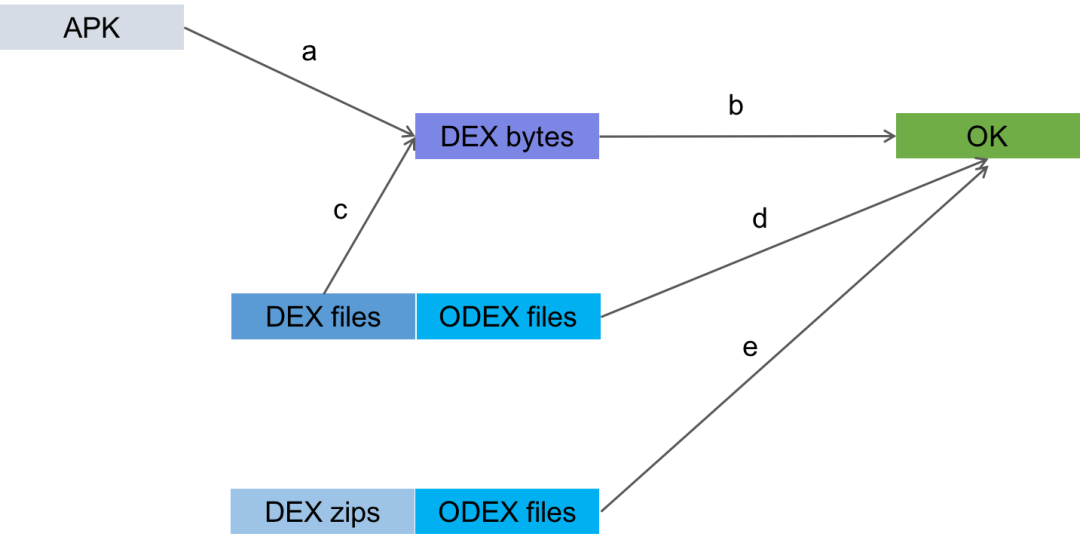
-
当 APP 首次启动的时候,如果会从 APK 里面解压 DEX 数组,因此会按照 a -> b 的路径执行;
-
当 APP 发现只有 DEX 文件,没有 ODEX 文件时,会把从 DEX 文件中取得 DEX 数组,按照 c -> b 路径执行;
-
当 APP 发现 DEX 文件和 ODEX 文件都存在的时候,会按照 ODEX 方式加载,按照 d 路径执行;
-
当 APP 发现有 ZIP 文件以及它所对应的 ODEX 的时候,会按照 e 路径执行。
这么一来,APP 就可以根据当前情况,选择最合适的方式执行加载 DEX 了。从而保证了任意时刻的最优性能。
前面提到,OPT 优化是在单独的进程里面执行的。单独进程除了可以减少前面的 SIGSTKFLT 问题,还能在做完 OPT 后及时终止后台进程,避免过多的资源占用。
然而,在单独进程处理 OPT 和其他进程执行 install 的时候,都涉及到 DEX 和 ODEX 文件的访问和生成,因此在这些进程之间涉及到文件访问和 OPT 时,都是加文件锁互斥执行的。这样可以避免加载的同时,另一个进程在操作 DEX 和 ODEX 文件导致的文件损坏。在官方的 MultiDex 中也是采用这种文件锁的方式来进行互斥访问的。
但这带来了另一个问题,如果 OPT 进程在长时间做 dexopt,而此时主进程(或者其他后台进程)需要再次启动,便会因为 OPT 进程持有互斥文件锁,而导致这些进程被阻塞住无法继续启动。可以看流程图来理解这一过程:

正如图中描绘的场景,用户第一次打开了 APP,然后运行一会之后因为一些情况杀死了 APP,这时,后台进程已经启动并正在做 OPT。如果此时用户想要再次打开,就会由于 OPT 进程互斥锁导致阻塞而黑屏。这显然是不可接受的。
因此,我们就需要采取更好的策略,使得在主进程能够正常地继续往下执行,而不至于被阻塞住。
这个问题的关键在于,主进程需要依赖 OPT 进程的产物,才能继续往下执行,而 OPT 进程此时正在操作 DEX 文件,这个过程中的产物必定无法被主进程直接使用。
所以,如果想要主进程不再因 OPT 操作阻塞,我们很容易想到可以无视 OPT 进程,不使用 DEX 文件,只从 APK 里面获取内存形式的 DEX 字节码就可以了。不过这种方式的主要问题在于,如果 OPT 时间非常长,在这段时间内就不得不一直使用内存方式的 DEX 启动 APP,这样性能就会处于比较差的水平。
因此我们采用的是另一种方案。在主进程退出而再次启动的时候,先中止 OPT 进程,直接取得现有 DEX 产物进行加载,然后再唤起 OPT 进程。
如下图所示:
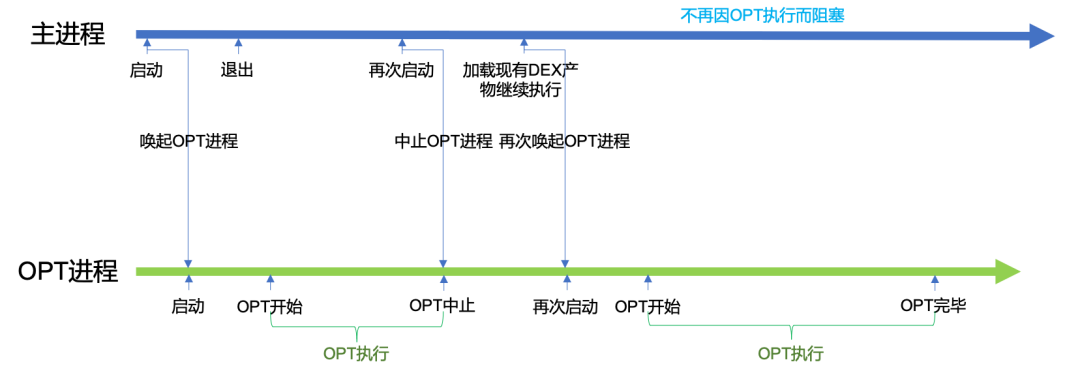
这里关键点在于如何中止进程。当然,我们可以直接在主进程发信号杀死 OPT 进程,不过这种方式过于粗暴,很可能导致 DEX 文件损坏。而且 kill 信号的方式没有回调,我们无法得知是否进程确实地退出了。
因此,我们采取的方式是用两个文件锁来做同步,保证进程启动和退出的信息可以在多个进程之间传达。
第一个文件锁就是单纯用来作为互斥锁,保证处理 DEX 和加载 DEX 的过程是互斥发生的。第二个文件锁用来表示进程即将获取互斥锁,我们称之为准备锁,它可以用来通知 OPT 进程:此时有其他进程正需要加载 DEX 产物。
对于 OPT 进程而言,获取文件锁的步骤如下:
-
获取互斥锁;
-
执行 OPT;
-
非阻塞地尝试获取准备锁;
-
如果没有获取到准备锁,表示此时有其他进程已经持有准备锁,则释放互斥锁,并退出 OPT 进程;
-
如果获取到了准备锁,表示此时没有其他进程正常持有准备锁,则再次执行第 2 步,做下个文件的 OPT;
-
完成所有 DEX 文件的 OPT 操作,释放互斥锁,退出。
对于主进程(或其他非 OPT 进程)而言,获取文件锁的步骤如下:
-
阻塞等待获取准备锁;
-
阻塞等待获取互斥锁;
-
释放准备锁;
-
完成 DEX 加载;
-
释放互斥锁;
-
继续往下执行业务代码。
具体情形见下图:
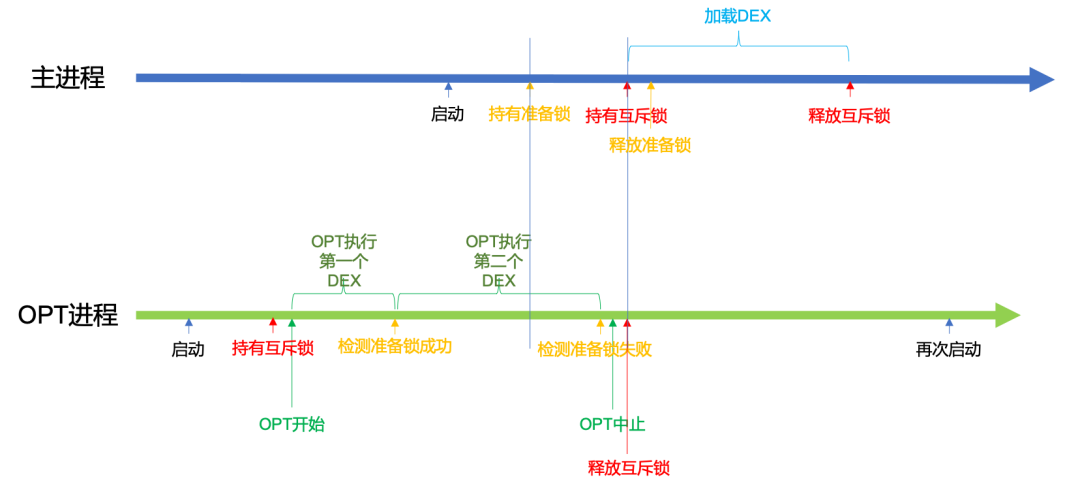
首先,OPT 进程开始执行,会获取到互斥锁,然后做 DEX 处理。OPT 进程在处理完第一个 DEX 文件后,由于没有其他进程持有准备锁,因此 OPT 进程获取准备锁成功,然后释放准备锁,继续做下一个 DEX 优化。
这时候,主进程(或其他非 OPT 进程)启动,先成功地获取准备锁。然后继续阻塞地获取互斥锁,此时由于 OPT 进程已经在前一步获取到了互斥锁,因此只能等待其释放。
OPT 进程在处理完第二个 DEX 后,检测到准备锁已经被其他进程持有了,因此获取失败,从而停止继续做 OPT,释放互斥锁并退出。
此时主进程就可以成功地获取到互斥锁,并且立即释放准备锁,以便其他进程可以获取。接着,在完成 DEX 加载后,释放互斥锁,继续执行后续业务流程。最后再唤起 OPT 进程接着做完原先的 DEX 处理。
总体看来,在这种模式下,OPT 进程可以主动发现有其他进程需要加载 DEX,从而中断 DEX 处理,并释放互斥锁。主进程便不需要等待整个 DEX 处理完成,只需要等 OPT 进程完成最近一个 DEX 文件的处理就可以继续执行了。
我们本地选取了几台 4.4 及以下的设备,对它们首次启动的 DEX 加载时间进行了对比:
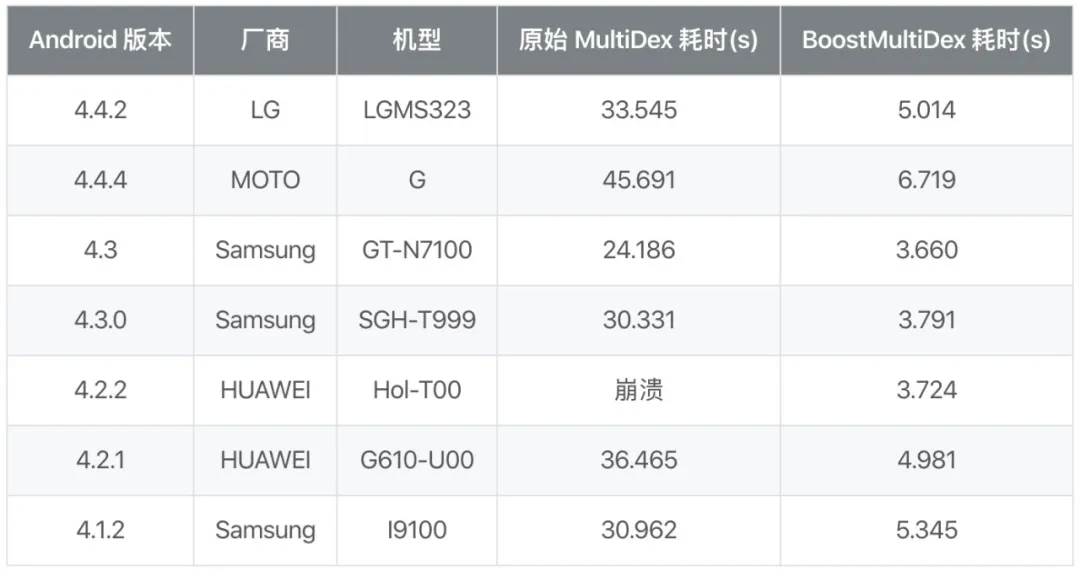
以上是在抖音上测得的实际数据,APK 中共有 6 个 Secondary DEX,显而易见,BoostMultiDex 方案相比官方 MultiDex 方案,其耗时有着本质上的优化,基本都只到原先的 11%~17% 之间。也就是说 BoostMultiDex 减少了原先过程 80% 以上的耗时。 另外我们看到,其中有一个机型,在官方 MultiDex 下是直接崩溃,无法启动的。使用 BoostMultiDex 也将使得这些机型可以焕发新生。另外,我们在线上采取了对半分的方式,也就是 BoostMultiDex 和原始 MultiDex 随机各自选取一半线上设备,对比二者的耗时。
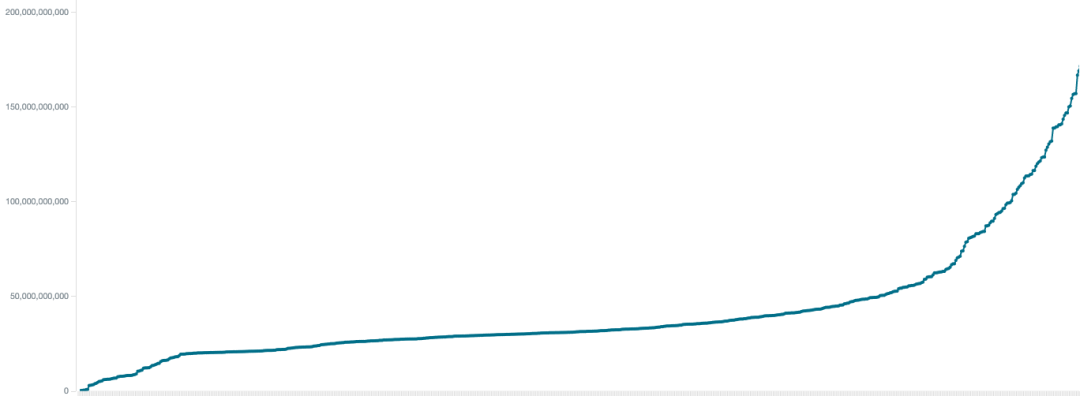
我们先以设备维度来看,这里随机选取了 15 分钟的线上数据,图中横轴为每个 Android 版本 4.4 及以下的设备,纵轴为首次启动加载 DEX 的耗时,按耗时升序排列,单位为纳秒。
BoostMultiDex 下的设备耗时:

MultiDex 下的设备耗时:
最后
小编这些年深知大多数初中级Android工程师,想要提升自己,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此我收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-sKQLAN9j-1718986063192)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
资料⬅专栏获取
g.cn/img_convert/729b6aec0e17eac0793f00f85d9d5229.png)
MultiDex 下的设备耗时:
最后
小编这些年深知大多数初中级Android工程师,想要提升自己,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此我收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-sKQLAN9j-1718986063192)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
资料⬅专栏获取