如果要使用大型语言模型 ()LLMs 实现生成式 AI 解决方案,则应考虑使用检索增强生成 (RAG) 的策略来生成上下文感知提示LLM。在启用 LLM RAG 的预生产管道中发生的一个重要过程是删除文档文本,以便仅将文档中最相关的部分与用户查询匹配并发送到用户查询以生成内容。LLM这就是 Open-Parse 可以提供帮助的地方。Open-Parse 超越了朴素的文本拆分,以确保相似的文本不会被拆分为两个单独的块。在这篇文章中,我将展示如何从 MinIO 存储桶中获取原始形式的文档,使用 Open-Parse 将它们分块,然后将它们保存到另一个可用于馈送向量数据库的存储桶中。可以在此处找到包含本文中显示的所有代码的 Jupyter 笔记本。
在介绍 Open-Parse 处理文档的功能之前,让我们先看一下 RAG 推理管道。请特别注意如何使用文档块来提高生成对用户查询的响应时的LLMs性能。
RAG 推理管道
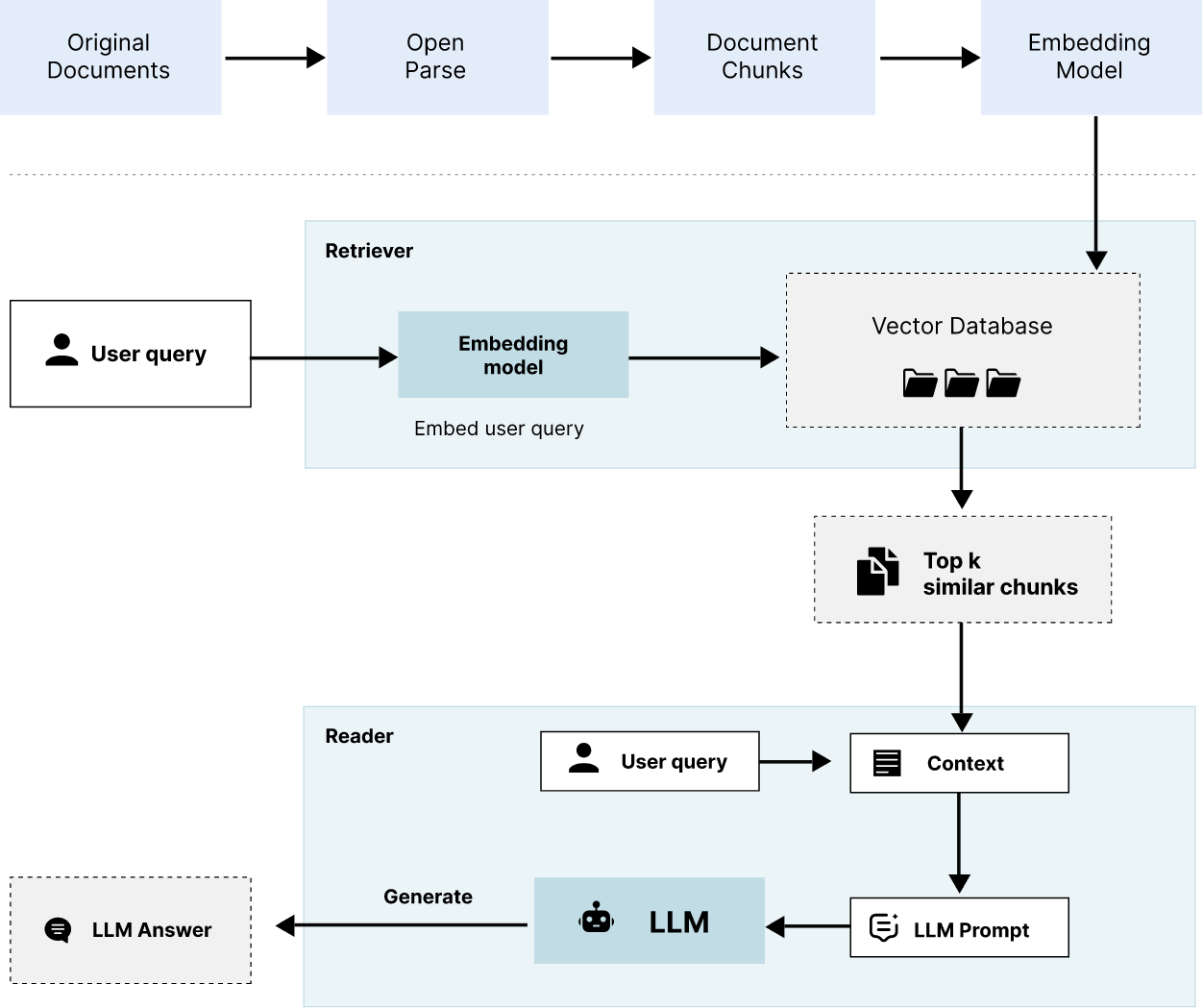
下图显示了 RAG 推理管道。它还显示了文档处理管道,这将在后面的章节中讨论。
检索增强生成 (RAG) 是一种技术,它从用户请求(通常是问题)开始,使用向量数据库将请求与其他数据结合在一起,然后将请求和数据传递给 LLM an 以进行内容创建。使用 RAG,不需要任何培训,因为我们LLM通过从自定义文档语料库发送相关文本块来对其进行教育。如下图所示。它的工作原理是这样的,使用问答任务:用户在应用程序的用户界面中提出问题。您的应用程序将接受问题 - 特别是其中的单词 - 并使用向量数据库搜索与上下文相关的文本块。这些块和原始问题被发送到 LLM.整个包 - 问题加块(上下文)被称为提示。将LLM使用此信息来生成您的答案。这似乎是一件愚蠢的事情 - 如果您已经知道答案(片段),为什么还要为?LLM请记住,这是实时发生的,目标是生成文本 - 您可以复制并粘贴到您的研究中。您需要创建LLM包含自定义语料库中信息的文本。使用 RAG,可以实现用户授权,因为在推理时从向量数据库中选择文档(或文档片段)。文档中的信息永远不会成为模型参数参数的一部分。下面列出了RAG的主要优点。
优势
-
从您的自定义语料库LLM中获取直接知识。
-
可解释性是可能的。
-
无需微调。
-
幻觉显着减少,可以通过检查向量数据库查询的结果来控制。
-
可以实现文档级授权。
文档处理管道
显然,RAG 的一个重要部分是在通过嵌入模型运行文档并将嵌入保存到向量数据库之前发生的文档处理。如果您有二进制格式的复杂文档,例如 PDF,这并非易事。例如,文档通常包含表格、图形、注释、编辑文本和对其他文档的引用。此外,LLMs对可以使用原始查询发送的上下文的大小进行限制。因此,发送整个文档不是一种选择。即使您可以发送整个文档,也可能无法产生最佳结果。来自多个文档的代码段集合可能是特定用户查询的最佳上下文。为了解决这个问题,许多解析库会根据所需的块长度拆分文档。一种暴力的方法是仅使用块长度来拆分文本。更好的方法是在句子或段落边界上拆分,该边界仍将块保持在限制范围内。虽然这样更好,但它可以将节标题放在它们自己的块和块表中,将它们拆分为几个块。
Open-Parse 是一个用于拆分 PDF 文件的开源库,它超越了朴素的文本拆分。它的设计灵活且易于使用。它通过分析布局和基于简单的启发式创建块来对文档进行分块,这些分块将相关文本保留在同一块中。下面是一个流程图,显示了 Open-Parse 逻辑。注意:文本节点将转换为 Markdown,而表节点将转换为 HTML。
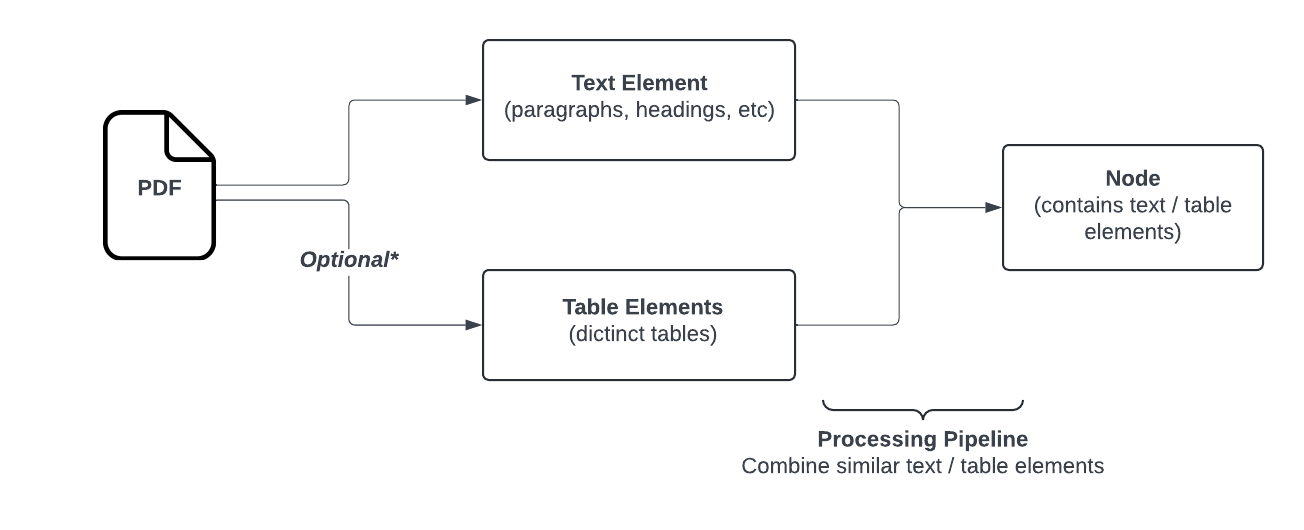
来源: https://filimoa.github.io/open-parse/processing/overview/
让我们看几个简单的例子,看看这到底意味着什么。
使用 Open-Parse 对文档进行分块
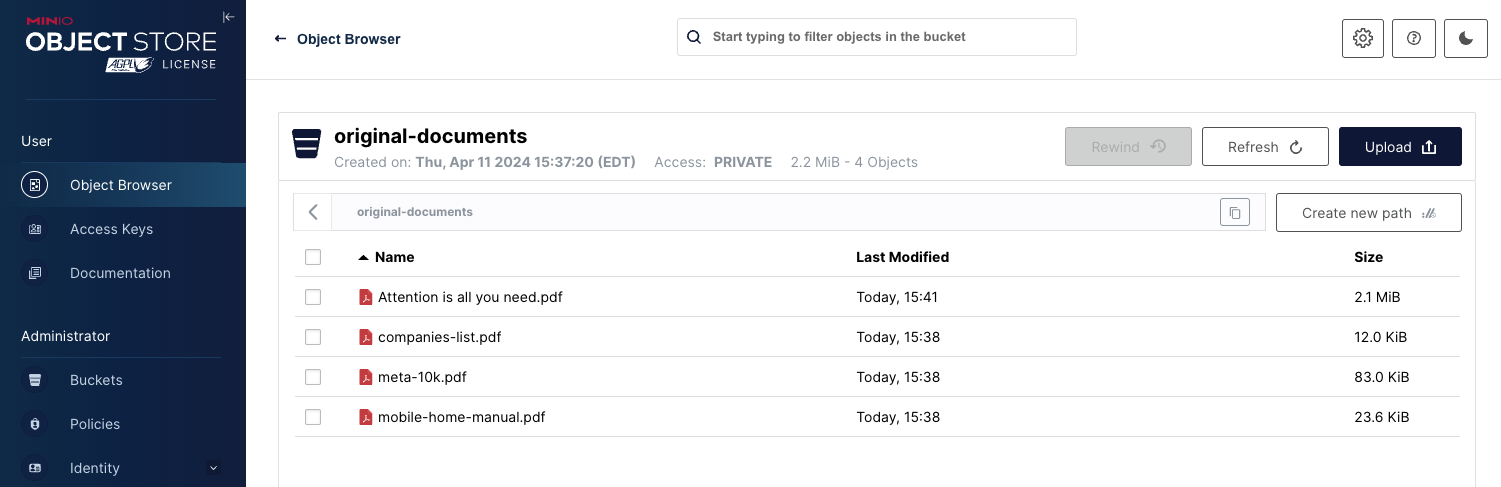
在生产环境中,您需要将原始 PDF 和分块对象存储在具有性能和扩展能力的存储解决方案中。这就是 MinIO 的用武之地。本节中的代码假定您设置了两个存储桶,如下所示。
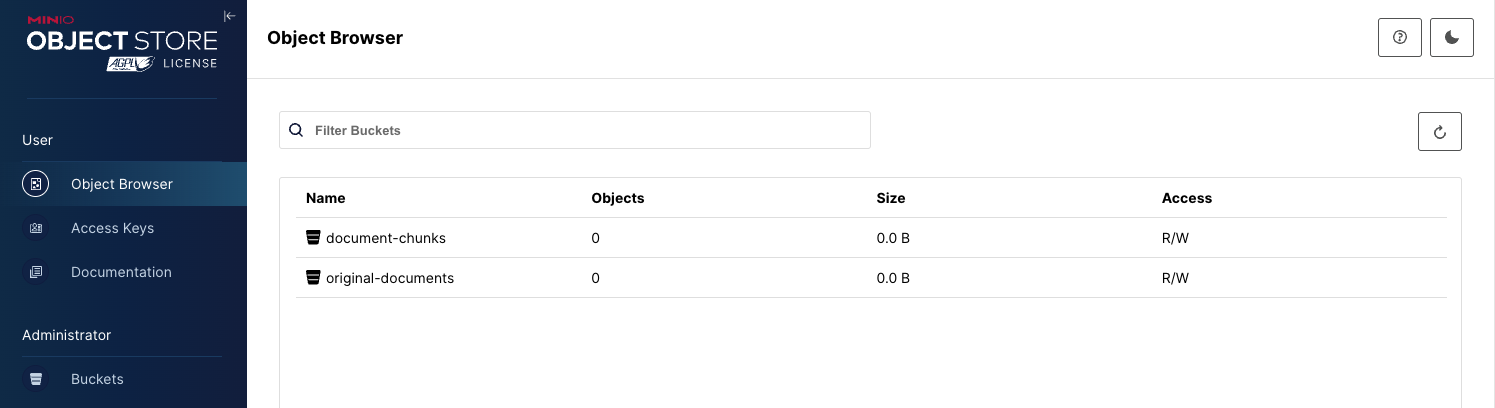
我已将 Open-Parse 存储库中说明书使用的一些示例文档上传到 original-corpus 存储桶。我还上传了我最喜欢的白皮书。
我们需要的第一件事是一个实用程序函数,用于将文件下载到临时目录,以便 open-parse 可以处理它。以下功能将连接到 MinIO,并将 PDF 下载到系统的临时文件夹。
import os
from dotenv import load_dotenv
load_dotenv()
MINIO_URL = os.environ['MINIO_URL']
MINIO_ACCESS_KEY = os.environ['MINIO_ACCESS_KEY']
MINIO_SECRET_KEY = os.environ['MINIO_SECRET_KEY']
if os.environ['MINIO_SECURE']=='true': MINIO_SECURE = True
else: MINIO_SECURE = False
import tempfile
from minio import Minio
from minio.error import S3Error
def get_pdf_from_minio(bucket_name: str, object_name: str) -> str:
'''
Retrieves an object from MinIO, saves it in a temp file and retiurns the
path to the temp file.
'''
try:
# Create client with access and secret key
client = Minio(MINIO_URL,
MINIO_ACCESS_KEY,
MINIO_SECRET_KEY,
secure=MINIO_SECURE)
# Generate a temp file.
temp_dir = tempfile.gettempdir()
temp_file = os.path.join(temp_dir, object_name)
# Save object to file.
client.fget_object(bucket_name, object_name, temp_file)
except S3Error as s3_err:
raise s3_err
except Exception as err:
raise err
return temp_file
使用下面的代码片段运行此函数后,我们将在当前系统的临时目录中有一个文件。
original_corpus_bucket_name = 'original-documents'
chunked_corpus_bucket_name = 'document-chunks'
object_name = 'Attention is all you need.pdf'
temp_file = get_pdf_from_minio(original_corpus_bucket_name, object_name)
接下来,让我们拆分 PDF。这就像几行代码一样简单。拆分文档后,可以显示节点。如下所示。
import openparse
parser = openparse.DocumentParser()
parsed_basic_doc = parser.parse(temp_file)
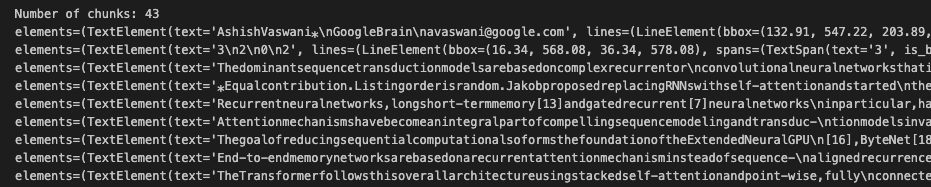
print('Number of chunks:', len(parsed_basic_doc.nodes))
for node in parsed_basic_doc.nodes:
print(node)
每个节点都包含一个文本块和有关该块来源的其他信息。下面的屏幕截图显示了上述片段的输出,其中的信息相当丰富。
使用此显示技术有助于了解用于表示文档的基础对象模型。然而,Open-Parse 特别好的是它的可视化工具,它可以在原始文档上绘制一个边界框,显示每个块的来源。这只需两行代码即可完成。
pdf = openparse.Pdf(temp_file)
pdf.display_with_bboxes(parsed_basic_doc.nodes[0:4])
在此代码中,我要求 Open-Parse 绘制原始 PDF 以及围绕前四个文本块的边界框。显示如下。请注意,即使文本采用类似网格的格式,作者也被放置在一个块中。Open-Parse 还找出了页面左侧的垂直文本。

如果我们通过类似的代码运行另一个原始文档,我们可以看到 Open-Parse 如何处理部分标题和项目符号文本。

将块保存到 MinIO
一旦我们将文档分块,下一步就是将每个块保存到 MinIO。为此,我们将使用上面屏幕截图中所示的 document-chunks 存储桶。以下函数会将文件保存到 MinIO 存储桶中。我们将使用此函数将每个块保存为单独的对象。
def save_chunk_to_minio(bucket_name: str, object_name: str,
file_path: str, metadata: dict) -> None:
'''
Saves a doument chunk to MinIO.
'''
try:
# Create client with access and secret key
client = Minio(MINIO_URL, # host.docker.internal
MINIO_ACCESS_KEY,
MINIO_SECRET_KEY,
secure=MINIO_SECURE)
client.fput_object(bucket_name, object_name, file_path, metadata=metadata)
except S3Error as s3_err:
raise s3_err
except Exception as err:
raise err
Open-Parse 提供了一种model_dump方法,用于将分块文档序列化为字典。下面的代码片段调用此方法并打印一些附加信息,以便您了解此字典的形成方式。
import json
chunks = parsed_basic_doc.model_dump_json()
chunks = json.loads(chunks)
print(chunks.keys())
print(chunks['nodes'][0])
print(type(chunks['nodes'][0]))
chunks
输出如下所示。
dict_keys(['nodes', 'filename', 'num_pages', 'coordinate_system', 'table_parsing_kwargs'])
{'variant': {'text'}, 'tokens': 140, 'bbox': [{'page': 0, 'page_height': 792.0, 'page_width': 612.0, 'x0': 116.68, 'y0': 436.19, 'x1': 497.21, 'y1': 558.54}], 'text': '...'}
<class 'dict'>
{'nodes': [{'variant': {'text'},
'tokens': 140,
'bbox': [{'page': 0,
'page_height': 792.0,
'page_width': 612.0,
'x0': 116.68,
'y0': 436.19,
'x1': 497.21,
'y1': 558.54}],
'Text': ...
字典可以拆开,每个块都可以发送到 MinIO。如下所示。此代码还会将有关原始文档的元数据添加到每个对象。 将原始文件名与每个块一起保存有助于 Rag 推理管道中的可解释性。可解释性允许使用启用LLM的 RAG 的应用程序显示指向用于构建提示上下文的所有文档的链接。对于致力于提高推理管道性能的最终用户和工程师来说,这是一项强大的功能。
import json
temp_dir = tempfile.gettempdir()
temp_file = os.path.join(temp_dir, 'tmp.json')
print(temp_file)
metadata = {}
metadata['filename'] = chunks['filename']
metadata['num_pages'] = chunks['num_pages']
metadata['coordinate_system'] = chunks['coordinate_system']
metadata['table_parsing_kwargs'] = chunks['table_parsing_kwargs']
print(metadata)
chunk_num = 0
for node in chunks['nodes']:
with open(temp_file, 'w') as f:
f.write(json.dumps(node))
#pickle.dump(node, f) # Serialize the node.
chunk_name = os.path.splitext(object_name)[0]
save_chunk_to_minio(chunked_corpus_bucket_name, f'{chunk_num} - {chunk_name}.json',
temp_file, metadata)
chunk_num += 1
请注意,我们无法将数据转储到 JSON 文件。包含所有块的字典使用 Python “set” 对象,该对象无法序列化为 JSON。对于这种情况,Python pickle 格式工作得很好。完成上述代码后,我们的 document-chunks 存储桶将如下所示。
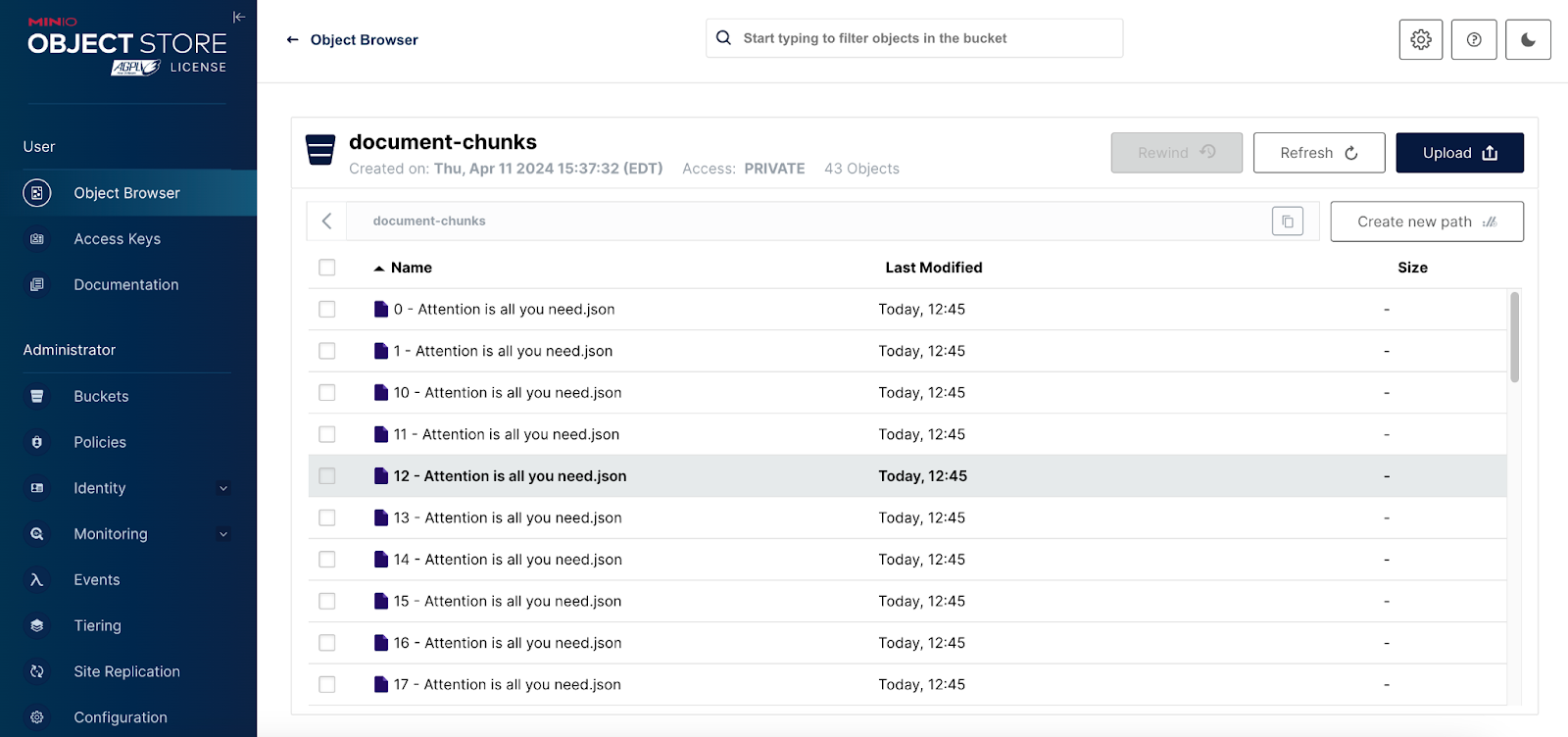
后续步骤
这篇文章介绍了 Open-Parse 的核心功能。但是,它还具有一些高级功能,在构建生产级推理管道之前应探索这些功能。
-
解析表可能很棘手。如果默认功能在处理表时遇到问题,请在此处查看高级表解析功能。
-
RAG的主要优势之一是可解释性。它允许用户查看用于生成答案的所有文档的链接。使用 Open-Parse,这是通过与每个文档块一起保留的元数据实现的。当收集语义相关的块时,可以确定使用的所有文档,并且可以与生成的文本一起显示指向这些文档的链接。可以在此处观看此功能的简短视频演示。
-
语义分块是一种高级技术,如果节点(块)在语义上相似,则它们会组合在一起。点击此处了解详情。
-
如果希望进一步处理提取的数据,可以向 DocumentParser 类添加自定义处理函数。点击此处了解详情。