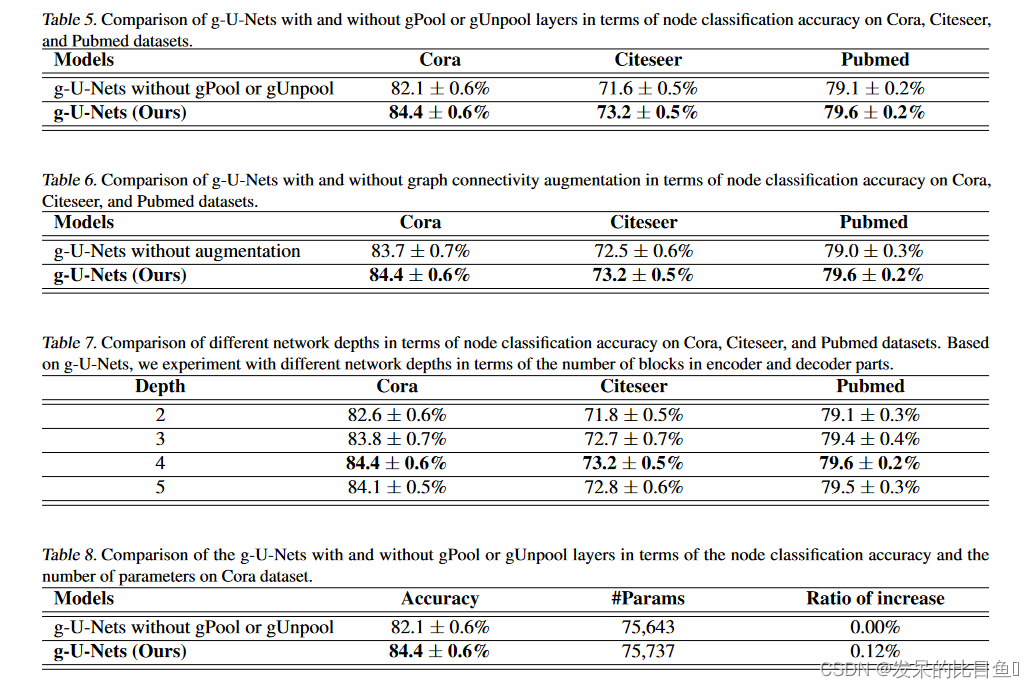
使用Scikit-learn进行文本分类pipeline
- 1. 基线模型
- 2. 基线模型,改进的数据
- 3. Pipeline改进
- 4. 基于字符的pipeline
- 5. 调试HashingVectorizer
- 参考资料
scikit-learn文档提供了一个很好的文本分类教程。确保先阅读它。 本文中,我们将做类似的事情,同时更详细地研究分类器权重和预测结果。
1. 基线模型
首先,让加载 20 个新闻组数据,只保留 4 个类别:
from sklearn.datasets import fetch_20newsgroups
categories = ['alt.atheism', 'soc.religion.christian',
'comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups(
subset='train',
categories=categories,
shuffle=True,
random_state=42
)
twenty_test = fetch_20newsgroups(
subset='test',
categories=categories,
shuffle=True,
random_state=42
)
一个基本的文本处理pipeline——bag of words特征和Logistic Regression作为分类器:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import make_pipeline
vec = CountVectorizer()
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target);
这里使用 LogisticRegressionCV 来自动调整正则化参数 C。 它允许比较不同的向量化器——最佳 C 值对于不同的输入特征可能不同(例如,对于双字母组或字符级输入)。 另一种方法是使用 GridSearchCV 或 RandomizedSearchCV。
让我们检查一下这条管道的质量:
from sklearn import metrics
def print_report(pipe):
y_test = twenty_test.target
y_pred = pipe.predict(twenty_test.data)
report = metrics.classification_report(y_test, y_pred,
target_names=twenty_test.target_names)
print(report)
print("accuracy: {:0.3f}".format(metrics.accuracy_score(y_test, y_pred)))
print_report(pipe)
precision recall f1-score support
alt.atheism 0.91 0.81 0.86 319
comp.graphics 0.86 0.94 0.90 389
sci.med 0.92 0.81 0.86 396
soc.religion.christian 0.88 0.98 0.93 398
accuracy 0.89 1502
macro avg 0.89 0.89 0.89 1502
weighted avg 0.89 0.89 0.89 1502
accuracy: 0.889
不错。 可以尝试其他分类器和预处理方法,但先检查模型使用eli5.show_weights() 函数学到了什么:
import eli5
eli5.show_weights(clf, top=10)
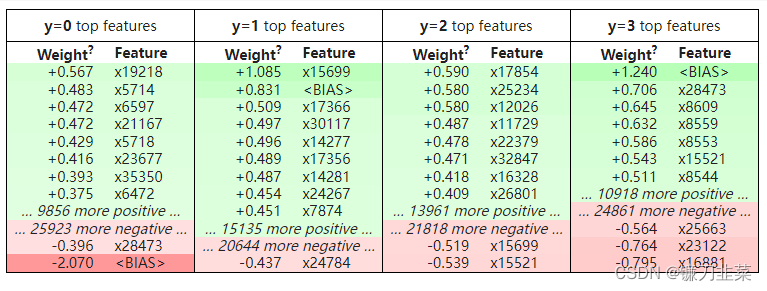
上表没有任何意义; 问题是eli5无法单独从分类器对象中获取特征和类名。 可以明确提供功能和目标名称:
eli5.show_weights(clf,feature_names=vec.get_feature_names(),target_names=twenty_test.target_names)
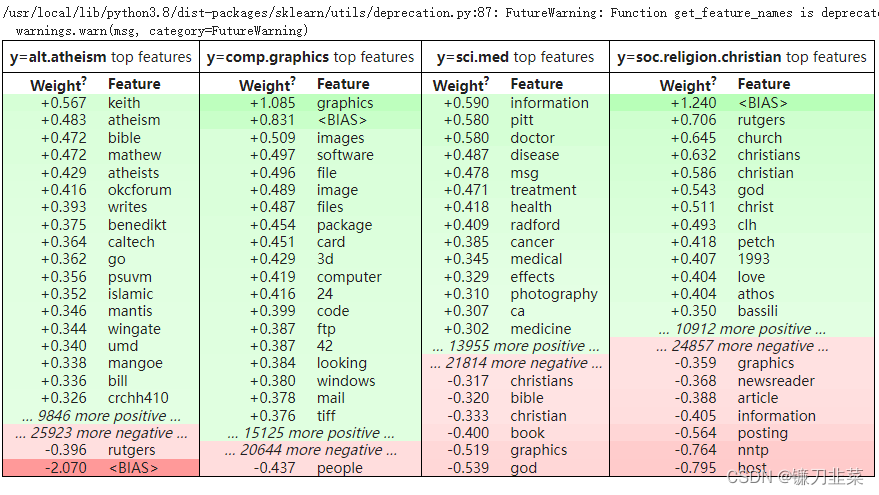
上面的代码有效,但更好的方法是提供vectorizer,让eli5自动计算细节:
eli5.show_weights(clf, vec=vec, top=10, target_names=twenty_test.target_names)
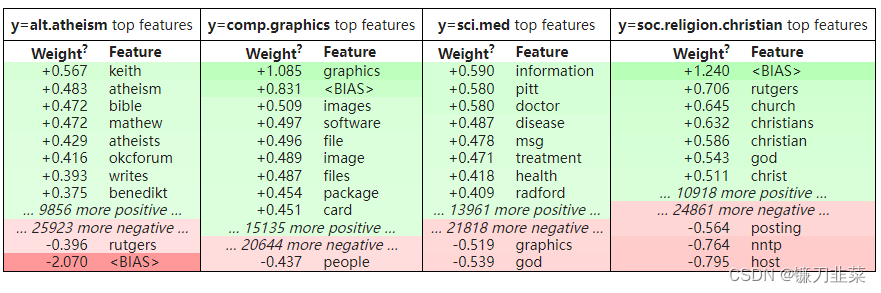
这开始变得更有意义了。 Columns 是目标类。 在每一列中都有特征及其权重。 Intercept (偏差)特征在同一张表中显示为 <BIAS>。 我们可以检查特征和权重,因为我们使用的是词袋向量化器和线性分类器(因此单个词和分类器系数之间存在直接映射)。 对于其他分类器,特征可能更难检查。
有些功能看起来不错,但有些则不然。 不过,模型似乎学习了一些特定于数据集的名称(电子邮件部分等),而不是学习特定主题的单词。 让我们检查一个例子的预测结果:
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names)

可以在文本中突出显示内容。 还有一个单独的表格用于无法在文本中突出显示的功能 - 在本例中为<BIAS>。 如果将鼠标悬停在突出显示的词上,它会显示该词在标题中的权重。 单词根据其权重着色。
2. 基线模型,改进的数据
从上面的突出显示可以看出分类器确实学到了一些不感兴趣的东西,例如 它记住了部分电子邮件地址。 我们可能应该首先清理数据以使其更有趣; 改进模型(尝试不同的分类器等)在这一点上没有意义——它可能只是学会更好地利用这些电子邮件地址。
实际上,我们必须自己清理数据; 在此示例中,20 个新闻组数据集提供了一个选项,用于从消息中删除页脚和标题。让我们清理数据并重新训练分类器。
twenty_train = fetch_20newsgroups(
subset='train',
categories=categories,
shuffle=True,
random_state=42,
remove=['headers', 'footers'],
)
twenty_test = fetch_20newsgroups(
subset='test',
categories=categories,
shuffle=True,
random_state=42,
remove=['headers', 'footers'],
)
vec = CountVectorizer()
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target);
我们只是让分类器的任务变得更难、更现实。
print_report(pipe)
precision recall f1-score support
alt.atheism 0.81 0.76 0.79 319
comp.graphics 0.82 0.93 0.87 389
sci.med 0.87 0.78 0.82 396
soc.religion.christian 0.86 0.88 0.87 398
accuracy 0.84 1502
macro avg 0.84 0.84 0.84 1502
weighted avg 0.84 0.84 0.84 1502
accuracy: 0.840
一个很好的结果——我们只是让质量变差了! 这是否意味着管道现在更糟? 不,可能它对看不见的消息有更好的质量。 现在是比较公正的评价。 检查分类器使用的特征让我们注意到数据的问题并做出了很好的改变,尽管数字告诉我们不要这样做。
我们可以直接改进评估设置,而不是删除页眉和页脚,例如使用 来自 scikit-learn 的 GroupKFold。 那么旧模型的质量就会下降,我们可以删除页眉/页脚并提高准确性,所以数字会告诉我们删除页眉和页脚。 但是,如何拆分数据以及使用 GroupKFold 的哪些组并不明显。
那么,更新后的分类器学到了什么? (输出不那么冗长,因为只显示了类的一个子集 - 请参阅“targets”参数):
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names, targets=['sci.med'])

它不再使用电子邮件地址,但它看起来仍然不太好:分类器将高权重分配给看似无关的词,如“do”或“my”。 这些词出现在许多文本中,因此分类器可能将它们用作偏差的代理。 或者也许其中一些在某些类别中更常见。
3. Pipeline改进
为了帮助分类器,我们可以过滤掉停用词:
vec = CountVectorizer(stop_words='english')
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.86 0.76 0.81 319
comp.graphics 0.85 0.94 0.89 389
sci.med 0.92 0.85 0.88 396
soc.religion.christian 0.86 0.89 0.87 398
accuracy 0.87 1502
macro avg 0.87 0.86 0.86 1502
weighted avg 0.87 0.87 0.87 1502
accuracy: 0.868
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names, targets=['sci.med'])

从结果上看起来更好了。
或者,可以使用 TF*IDF 方案; 它应该会产生类似的效果。
请注意,在这里交叉验证LogisticRegression正则化参数,就像在其他示例中一样(LogisticRegressionCV,而不是LogisticRegression)。 TF*IDF值不同于单词计数值,因此最佳C值可能不同。 如果使用具有固定正则化强度的分类器,我们可能会得出错误的结论——所选择的C值可能对一种数据更有效。
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.89 0.81 0.85 319
comp.graphics 0.87 0.95 0.91 389
sci.med 0.94 0.88 0.91 396
soc.religion.christian 0.89 0.92 0.90 398
accuracy 0.89 1502
macro avg 0.90 0.89 0.89 1502
weighted avg 0.90 0.89 0.89 1502
accuracy: 0.895
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names, targets=['sci.med'])

它有所帮助,但没有完全相同的效果。 为什么不两者都做?
vec = TfidfVectorizer(stop_words='english')
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.92 0.80 0.86 319
comp.graphics 0.90 0.96 0.93 389
sci.med 0.95 0.92 0.93 396
soc.religion.christian 0.89 0.94 0.91 398
accuracy 0.91 1502
macro avg 0.91 0.91 0.91 1502
weighted avg 0.91 0.91 0.91 1502
accuracy: 0.911
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names, targets=['sci.med'])

这开始看起来不错!
4. 基于字符的pipeline
也许可以通过选择不同的分类器来获得更好的质量,但我们暂时跳过它。 让我们试试其他分析器——使用 char n-grams 代替单词:
vec = TfidfVectorizer(stop_words='english', analyzer='char',
ngram_range=(3,5))
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.91 0.80 0.85 319
comp.graphics 0.86 0.96 0.90 389
sci.med 0.93 0.88 0.91 396
soc.religion.christian 0.89 0.92 0.91 398
accuracy 0.89 1502
macro avg 0.90 0.89 0.89 1502
weighted avg 0.90 0.89 0.89 1502
accuracy: 0.895
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names)

它有效,但质量有点差。 此外,训练需要很长时间。
看起来stop_words现在没有效果——事实上,这在scikit-learn文档中有记录,所以我们的stop_words=‘english’ 没有用。 但至少现在更明显的是文本对于基于char ngram的分类器的样子。 稍等片刻,看看char_wb长什么样:
vec = TfidfVectorizer(analyzer='char_wb', ngram_range=(3,5))
clf = LogisticRegressionCV()
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.92 0.79 0.85 319
comp.graphics 0.89 0.96 0.92 389
sci.med 0.92 0.89 0.91 396
soc.religion.christian 0.88 0.93 0.91 398
accuracy 0.90 1502
macro avg 0.90 0.90 0.90 1502
weighted avg 0.90 0.90 0.90 1502
accuracy: 0.900
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names)

结果是相似的,有一些小的变化。 质量更好,原因不明; 也许交叉词依赖并不那么重要。
5. 调试HashingVectorizer
为了检查我们是否可以尝试拟合word n-gram 而不是 char n-gram。 但让我们首先处理效率问题。 为了处理大词汇表,我们可以使用scikit-learn中的HashingVectorizer; 为了加快训练速度,我们可以使用SGDCLassifier:
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import SGDClassifier
vec = HashingVectorizer(stop_words='english', ngram_range=(1,2))
clf = SGDClassifier(max_iter=10, random_state=42)
pipe = make_pipeline(vec, clf)
pipe.fit(twenty_train.data, twenty_train.target)
print_report(pipe)
precision recall f1-score support
alt.atheism 0.90 0.80 0.85 319
comp.graphics 0.87 0.96 0.91 389
sci.med 0.93 0.89 0.91 396
soc.religion.christian 0.89 0.92 0.90 398
accuracy 0.90 1502
macro avg 0.90 0.89 0.89 1502
weighted avg 0.90 0.90 0.90 1502
accuracy: 0.897
超级快! 不过,我们没有使用交叉验证来选择正则化参数。 让我们检查一下模型学到了什么:
eli5.show_prediction(clf, twenty_test.data[0], vec=vec, target_names=twenty_test.target_names, targets=['sci.med'])

结果看起来类似于CountVectorizer。 但是使用HashingVectorizer我们甚至没有词汇! 为什么它有效?
eli5.show_weights(clf, vec=vec, top=10, target_names=twenty_test.target_names)
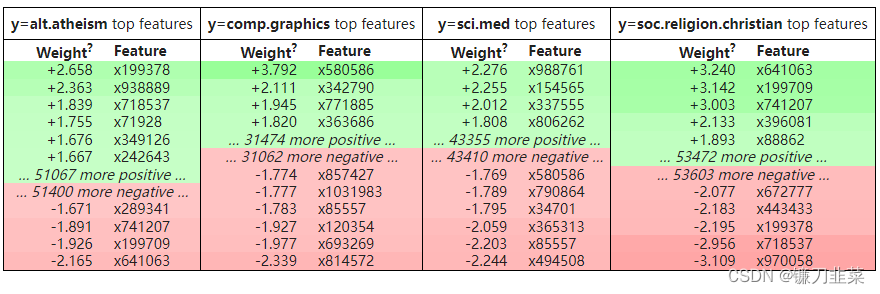
好的,我们没有词汇表,所以我们没有特征名称。 我们运气不好吗? 不,eli5 有一个答案:InvertableHashingVectorizer。 它可用于获取 HahshingVectorizer 的特征名称,而无需使用大量词汇。 它仍然需要一些数据来学习单词 -> 哈希映射; 我们可以使用随机数据子集来拟合它。
from eli5.sklearn import InvertableHashingVectorizer
import numpy as np
ivec = InvertableHashingVectorizer(vec)
sample_size = len(twenty_train.data) // 10
X_sample = np.random.choice(twenty_train.data, size=sample_size)
ivec.fit(X_sample);
eli5.show_weights(clf, vec=ivec, top=20, target_names=twenty_test.target_names)
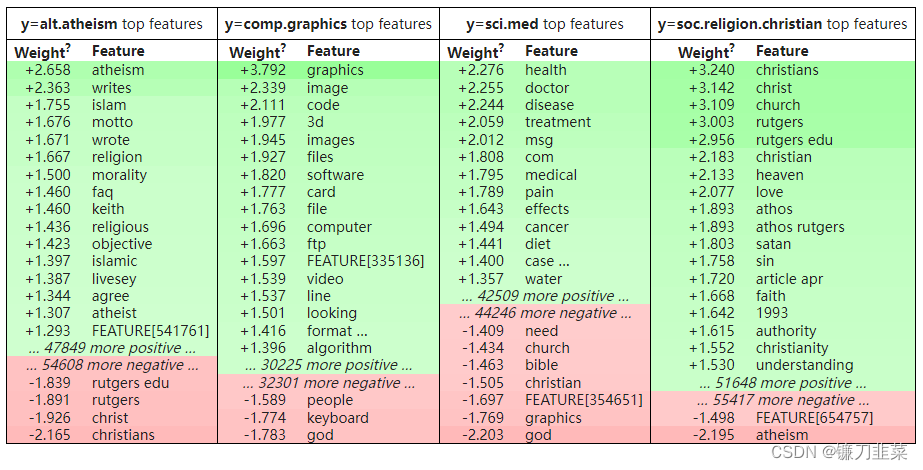
存在collisions (将鼠标悬停在带有“…”的特征上),并且存在随机样本中未看到的重要特征(FEATURE[…]),但总体而言它看起来不错。
“rutgers edu”的二元组特征很可疑,它看起来像是 URL 的一部分。
rutgers_example = [x for x in twenty_train.data if 'rutgers' in x.lower()][0]
print(rutgers_example)
In article <Apr.8.00.57.41.1993.28246@athos.rutgers.edu> REXLEX@fnal.gov writes:
>In article <Apr.7.01.56.56.1993.22824@athos.rutgers.edu> shrum@hpfcso.fc.hp.com
>Matt. 22:9-14 'Go therefore to the main highways, and as many as you find
>there, invite to the wedding feast.'...
>hmmmmmm. Sounds like your theology and Christ's are at odds. Which one am I
>to believe?
是的,看起来模型学习了这个地址,而不是学习了一些有用的东西。
eli5.show_prediction(clf, rutgers_example, vec=vec, target_names=twenty_test.target_names, targets=['soc.religion.christian'])

引用的文本使模型很容易对某些消息进行分类; 这不会推广到新消息。 因此,为了改进模型,下一步可能是进一步处理数据,例如 删除引用的文本或用特殊标记替换电子邮件地址。
查看特征有助于理解分类器的工作原理。 也许更重要的是,它有助于注意到预处理错误、数据泄漏、任务规范问题——所有这些你在现实世界中遇到的讨厌问题。
参考资料
[1] [Debugging scikit-learn text classification pipeline](Debugging scikit-learn text classification pipeline)